







近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。而大模型压缩主要分为如下几类:
-
剪枝(Pruning)
-
知识蒸馏(Knowledge Distillation)
-
量化(Quantization)
-
低秩分解(Low-Rank Factorization)
本文将讲述大模型压缩部署最重要的技术模型量化的基本概念以及当前大模型量化相关的一些工作。
简介
模型量化是指以较低的推理精度损失将连续取值(通常为float32或者大量可能的离散值)的浮点型权重近似为有限多个离散值(通常为int8)的过程。通过以更少的位数表示浮点数据,模型量化可以减少模型尺寸,进而减少在推理时的内存消耗,并且在一些低精度运算较快的处理器上可以增加推理速度。具体如下图所示,[-T, T]是量化前的数据范围,[-127, 127]是量化后的数据范围。
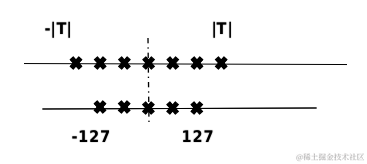
image.png
量化比特
计算机中不同数据类型的占用比特数及其表示的数据范围各不相同。可以根据实际业务需求将原模型量化成不同比特数的模型,一般深度神经网络的模型用单精度浮点数表示,如果能用有符号整数来近似原模型的参数,那么被量化的权重参数存储大小就可以降到原先的四分之一,用来量化的比特数越少,量化后的模型压缩率越高。
工业界目前最常用的量化位数是8比特,低于8比特的量化被称为低比特量化。1比特是模型压缩的极限,可以将模型压缩为1/32,在推理时也可以使用高效的XNOR和BitCount位运算来提升推理速度。
量化对象
模型量化的对象主要包括以下几个方面:
-
权重(weight):weight的量化是最常规也是最常见的。量化weight可达到减少模型大小内存和占用空间。
-
激活(activation):实际中activation往往是占内存使用的大头,因此量化activation不仅可以大大减少内存占用。更重要的是,结合weight的量化可以充分利用整数计算获得性能提升。
-
KV cache:量化 KV 缓存对于提高长序列生成的吞吐量至关重要。
-
梯度(Gradients):相对上面两者略微小众一些,因为主要用于训练。在训练深度学习模型时,梯度通常是浮点数,它主要作用是在分布式计算中减少通信开销,同时,也可以减少backward时的开销。
量化形式
另外,根据量化数据表示的原始数据范围是否均匀,还可以将量化方法分为线性量化和非线性量化。实际的深度神经网络的权重和激活值通常是不均匀的,因此理论上使用非线性量化导致的精度损失更小,但在实际推理中非线性量化的计算复杂度较高,通常使用线性量化。
下面着重介绍线性量化的原理。假设r表示量化前的浮点数,量化后的整数q可以表示为:
和分别表示取整和截断操作,和是量化后的最小值和最大值。是数据量化的间隔,是表示数据偏移的偏置,为0的量化被称为对称(Symmetric)量化,不为0的量化称为非对称(Asymmetric)量化。
对称量化可以避免量化算子在推理中计算z相关的部分,降低推理时的计算复杂度;非对称量化可以根据实际数据的分布确定最小值和最小值,可以更加充分的利用量化数据信息,使得量化导致的损失更低。
根据量化参数和的共享范围(即量化粒度),量化方法可以分为逐层量化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









