






更多2024最新AI大模型-LLm八股合集可以拉到文末!!!
相对位置编码
相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。对于相对位置编码来说,它的灵活性更大,更加体现出了研究人员的“天马行空”。
(1)经典式
相对位置编码起源于Google的论文《Self-Attention with Relative Position Representations》,华为开源的NEZHA模型也用到了这种位置编码,后面各种相对位置编码变体基本也是依葫芦画瓢的简单修改。
一般认为,相对位置编码是由绝对位置编码启发而来,考虑一般的带绝对位置编码的Attention:
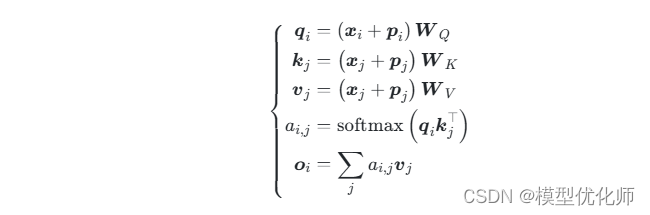

(2)XLNET式

(3)T5式
T5模型出自文章《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,里边用到了一种更简单的相对位置编码。思路依然源自qikjTq_ik^T_jqikjT展开式,如果非要分析每一项的含义,那么可以分别理解为“输入-输入”、“输入-位置”、“位置-输入”、“位置-位置”四项注意力的组合。如果我们认为输入信息与位置信息应该是独立(解耦)的,那么它们就不应该有过多的交互,所以“输入-位置”、“位置-输入”两项Attention可以删掉,而piWQWK⊤pj⊤\boldsymbol{p}{i} \boldsymbol{W}{Q} \boldsymbol{W}{K}^{\top} \boldsymbol{p}{j}^{\top}piWQWK⊤pj⊤实际上只是一个只依赖于(i,j)(i,j)(i,j)的标量,我们可以直接将它作为参数训练出来,即简化为:

说白了,它仅仅是在Attention矩阵的基础上加一个可训练的偏置项而已,而跟XLNET式一样,在vjv_jvj上的位置偏置则直接被去掉了。包含同样的思想的还有微软在ICLR 2021的论文《Rethinking Positional Encoding in Language Pre-training》中提出的TUPE位置编码。
比较“别致”的是,不同于常规位置编码对将βi,j\beta_{i, j}βi,j视为i−ji−ji−j的函数并进行截断的做法,T5对相对位置进行了一个“分桶”处理,即相对位置是i−ji−ji−j的位置实际上对应的是f(i−j)f(i−j)f(i−j)位置,映射关系如下:
| i−ji-ji−j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| f(i−j)f(i-j)f(i−j) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 8 | 8 | 8 | 9 | 9 | 9 | 9 |
| i−ji-ji−j | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | … |
| f(i−j)f(i-j)f(i−j) | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | … |
这个设计的思路其实也很直观,就是比较邻近的位置(0~7),需要比较得精细一些,所以给它们都分配一个独立的位置编码,至于稍远的位置(比如8~11),我们不用区分得太清楚,所以它们可以共用一个位置编码,距离越远,共用的范围就可以越大,直到达到指定范围再clip。
(4)DeBERTa式
DeBERTa也是微软搞的,去年6月就发出来了,论文为《DeBERTa: Decoding-enhanced BERT with Disentangled Attention》,最近又小小地火了一把,一是因为它正式中了ICLR 2021,二则是它登上SuperGLUE的榜首,成绩稍微超过了T5。
其实DeBERTa的主要改进也是在位置编码上,同样还是从qikjTq_ik^T_jqikjT展开式出发,T5是干脆去掉了第2、3项,只保留第4项并替换为相对位置编码,而DeBERTa则刚刚相反,它扔掉了第4项,保留第2、3项并且替换为相对位置编码(果然,科研就是枚举所有的排列组合看哪个最优):
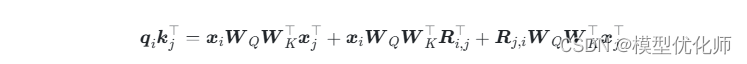
不过,DeBERTa比较有意思的地方,是提供了使用相对位置和绝对位置编码的一个新视角,它指出NLP的大多数任务可能都只需要相对位置信息,但确实有些场景下绝对位置信息更有帮助,于是它将整个模型分为两部分来理解。以Base版的MLM预训练模型为例,它一共有13层,前11层只是用相对位置编码,这部分称为Encoder,后面2层加入绝对位置信息,这部分它称之为Decoder,还弄了个简称EMD(Enhanced Mask Decoder);至于下游任务的微调截断,则是使用前11层的Encoder加上1层的Decoder来进行。
SuperGLUE上的成绩肯定了DeBERTa的价值,但是它论文的各种命名真的是让人觉得极度不适,比如它自称的“Encoder”、“Decoder”就很容易让人误解这是一个Seq2Seq模型,比如EMD这个简称也跟Earth Mover’s Distance重名。虽然有时候重名是不可避免的,但它重的名都是ML界大家都比较熟悉的对象,相当容易引起误解,真不知道作者是怎么想的…
面试题笔记分享
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖Android所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
每一章节都是站在企业考察思维出发,作为招聘者角度回答。从考察问题延展到考察知识点,再到如何优雅回答一面俱全,可以说是求职面试的必备宝典,每一部分都有上百页内容,接下来具体展示,完整版可直接下方扫码领取。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
 ## 大模型(LLMs)基础面
## 大模型(LLMs)基础面
1.目前 主流的开源模型体系 有哪些?
2.prefix LM 和 causal LM 区别是什么?
3.涌现能力是啥原因?
4.大模型 LLM的架构介绍?
大模型(LLMs)进阶面
1.llama 输入句子长度理论上可以无限长吗?
2.什么是 LLMs 复读机问题?
3.为什么会出现 LLMs 复读机问题?
4.如何缓解 LLMs 复读机问题?
5.LLMs 复读机问题
6.lama 系列问题
7.什么情况用 Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?8.各个专业领域是否需要各自的大模型来服务?
9.如何让大模型处理更长的文本?
大模型(LLMs)微调面
1.如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
2.为什么 SFT之后感觉 LLM傻了?
3.SFT 指令微调数据 如何构建?
4.领域模型 Continue PreTrain 数据选取?5.领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
6.领域模型 Continue PreTrain ,如何 让模型在预训练过程中就学习到更多的知识?7.进行 SFT操作的时候,基座模型选用Chat还是 Base?
8.领域模型微调 指令&数据输入格式 要求?
9.领域模型微调 领域评测集 构建?
10.领域模型词表扩增是不是有必要的?
11.如何训练自己的大模型?
12.训练中文大模型有啥经验?
13.指令微调的好处?
14.预训练和微调哪个阶段注入知识的?15.想让模型学习某个领域或行业的知识,是
应该预训练还是应该微调?
16.多轮对话任务如何微调模型?
17.微调后的模型出现能力劣化,灾难性遗忘
是怎么回事?
大模型(LLMs)langchain面
1.基于 LLM+向量库的文档对话 基础面
2.基于 LLM+向量库的文档对话 优化面
3.LLMs 存在模型幻觉问题,请问如何处理?
4.基于 LLM+向量库的文档对话 思路是怎么样?
5.基于 LLM+向量库的文档对话 核心技术是什么?
6.基于 LLM+向量库的文档对话 prompt 模板如何构建?
7.痛点1:文档切分粒度不好把控,既担心噪声太多又担心语义信息丢失
2.痛点2:在基于垂直领域 表现不佳
3.痛点 3:langchain 内置 问答分句效果不佳问题
4.痛点 4:如何 尽可能召回与 query相关的Document 问题
5.痛点5:如何让 LLM基于 query和 context
得到高质量的response
6.什么是 LangChain?
7.LangChain 包含哪些 核心概念?
8.什么是 LangChain Agent?
9.如何使用 LangChain ?
10.LangChain 支持哪些功能?
11.什么是 LangChain model?
12.LangChain 包含哪些特点?
大模型(LLMs):参数高效微调(PEFT)面
1.LORA篇2.QLoRA篇
3.AdaLoRA篇
4.LORA权重是否可以合入原模型?
5.LORA 微调优点是什么?
6.LORA微调方法为啥能加速训练?
7.如何在已有 LORA模型上继续训练?
1.1 什么是 LORA?
1.2 LORA 的思路是什么?
1.3 LORA 的特点是什么?
2.1 QLORA 的思路是怎么样的?
2.2 QLORA 的特点是什么?
8.3.1 AdaLoRA 的思路是怎么样的?为什么需
要 提示学习(Prompting)?
9.什么是 提示学习(Prompting)?10.提示学习(Prompting)有什么优点?11.提示学习(Prompting)有哪些方法,能不能稍微介绍一下它们间?
4.4.1为什么需要 P-tuning v2?
4.4.2 P-tuning v2 思路是什么?
4.4.3 P-tuning v2 优点是什么?
4.4.4 P-tuning v2 缺点是什么?
4.3.1为什么需要 P-tuning?
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
## 大模型评测面(LLMs)三
大模型怎么评测?
大模型的 honest原则是如何实现的?模型如何判断回答的知识是训练过的已知的知识,怎么训练这种能力?大模型(LLMs)强化学习面奖励模型需要和基础模型一致吗?RLHF 在实践过程中存在哪些不足?如何解决 人工产生的偏好数据集成本较高很难量产问题?如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?如何解决 PPO 的训练过程同时存在4个模型(2训练,2推理),对计算资源的要求较高问题?















 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









