






更多2024最新AI大模型-LLm八股合集可以拉到文末!!!
Flash Attention
论文名称:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Flash Attention的主要目的是加速和节省内存,主要贡献包括:
计算softmax时候不需要全量input数据,可以分段计算;
反向传播的时候,不存储attention matrix (N^2的矩阵),而是只存储softmax归一化的系数。
5.1 动机
不同硬件模块之间的带宽和存储空间有明显差异,例如下图中左边的三角图,最顶端的是GPU种的SRAM,它的容量非常小但是带宽非常大,以A100 GPU为例,它有108个流式多核处理器,每个处理器上的片上SRAM大小只有192KB,因此A100总共的SRAM大小是192KB×108=20MB192KB\times 108 = 20MB192KB×108=20MB,但是其吞吐量能高达19TB/s。而A100 GPU HBM(High Bandwidth Memory也就是我们常说的GPU显存大小)大小在40GB~80GB左右,但是带宽只与1.5TB/s。

下图给出了标准的注意力机制的实现流程,可以看到因为HBM的大小更大,我们平时写pytorch代码的时候最常用到的就是HBM,所以对于HBM的读写操作非常频繁,而SRAM利用率反而不高。

FlashAttention的主要动机就是希望把SRAM利用起来,但是难点就在于SRAM太小了,一个普通的矩阵乘法都放不下去。FlashAttention的解决思路就是将计算模块进行分解,拆成一个个小的计算任务。
5.2 Softmax Tiling
在介绍具体的计算算法前,我们首先需要了解一下Softmax Tiling。
(1)数值稳定
Softmax包含指数函数,所以为了避免数值溢出问题,可以将每个元素都减去最大值,如下图示,最后计算结果和原来的Softmax是一致的。
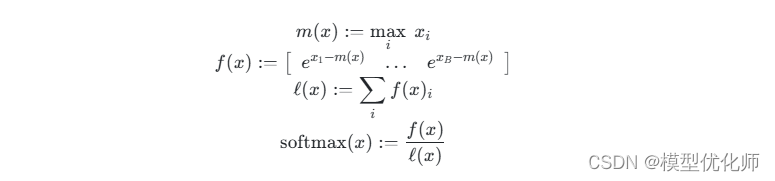
(2)分块计算softmax
因为Softmax都是按行计算的,所以我们考虑一行切分成两部分的情况,即原本的一行数据x∈R2B=[x(1),x(2)]x \in \mathbb{R}^{2 B}=\left[x^{(1)}, x^{(2)}\right]x∈R2B=[x(1),x(2)]
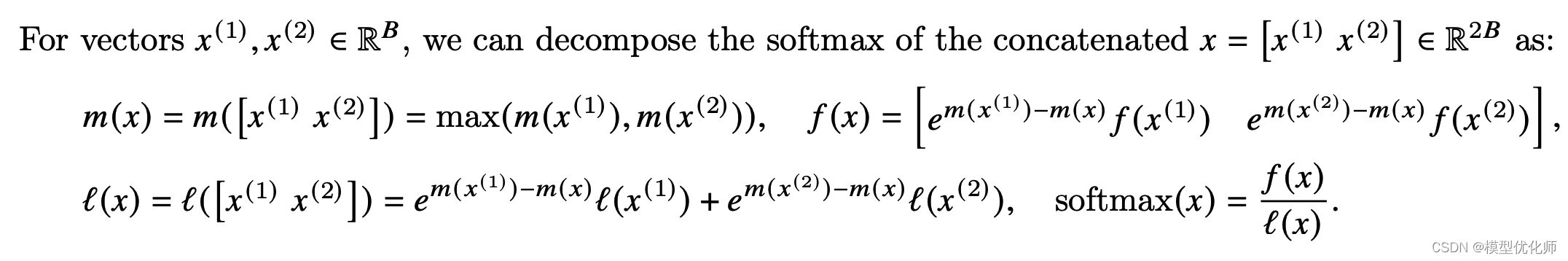
可以看到计算不同块的f(x)f(x)f(x)值时,乘上的系数是不同的,但是最后化简后的结果都是指数函数减去了整行的最大值。以x(1)x^{(1)}x(1) 为例,
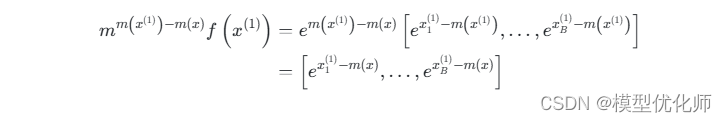
5.3 算法流程
FlashAttention旨在避免从 HBM(High Bandwidth Memory)中读取和写入注意力矩阵,这需要做到:
目标一:在不访问整个输入的情况下计算softmax函数的缩减;
将输入分割成块,并在输入块上进行多次传递,从而以增量方式执行softmax缩减
。
目标二:在后向传播中不能存储中间注意力矩阵。标准Attention算法的实现需要将计算过程中的S、P写入到HBM中,而这些中间矩阵的大小与输入的序列长度有关且为二次型,因此
Flash Attention就提出了不使用中间注意力矩阵,通过存储归一化因子来减少HBM内存的消耗
。
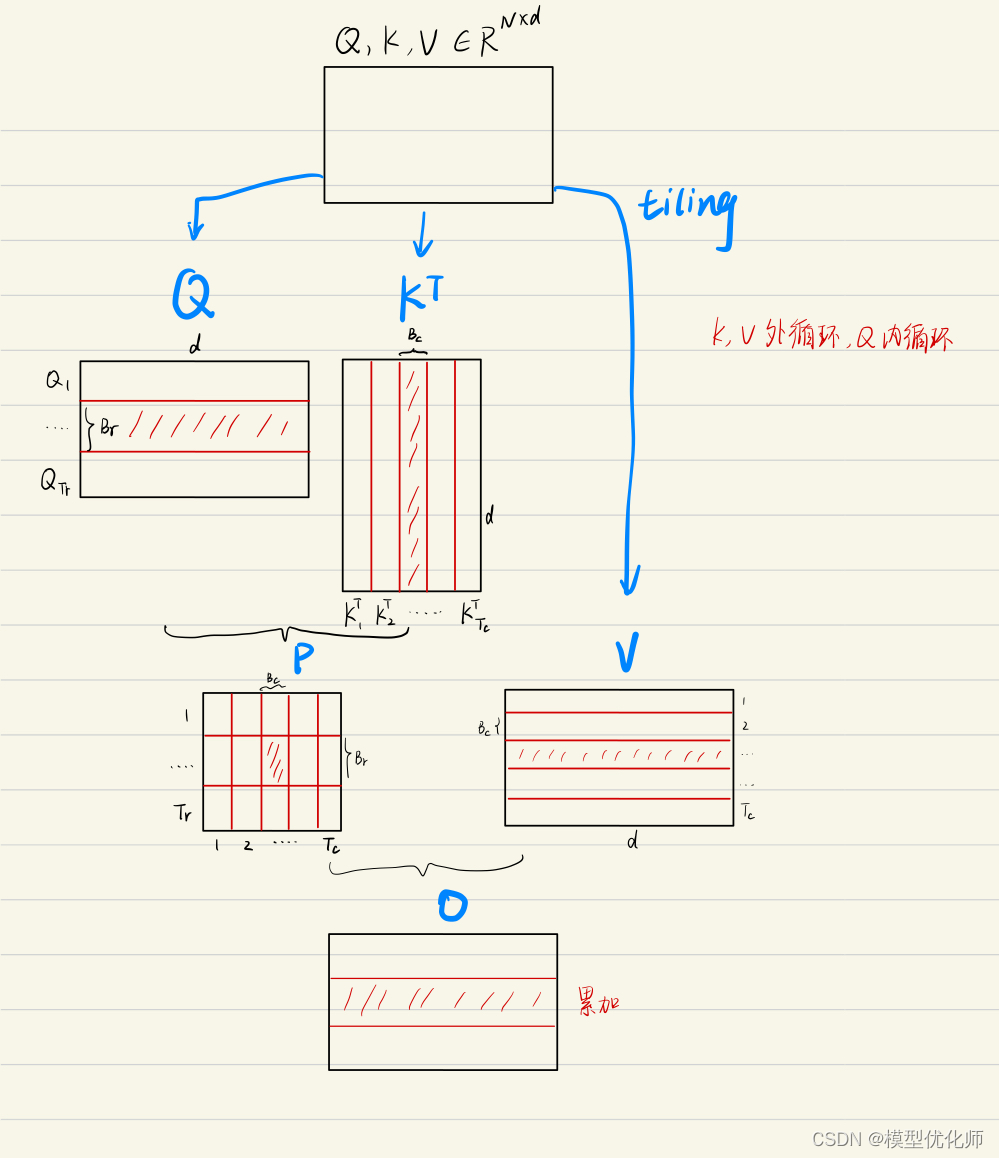
FlashAttention算法流程如下图所示:

为方便理解,下图将FlashAttention的计算流程可视化出来了,简单理解就是每一次只计算一个block的值,通过多轮的双for循环完成整个注意力的计算。
6.Transformer常见问题
6.1 Transformer和RNN
最简单情况:没有残差连接、没有 layernorm、 attention 单头、没有投影。看和 RNN 区别
attention 对输入做一个加权和,加权和 进入 point-wise MLP。(画了多个红色方块 MLP, 是一个权重相同的 MLP)
point-wise MLP 对 每个输入的点 做计算,得到输出。
attention 作用:把整个序列里面的信息抓取出来,做一次汇聚 aggregation
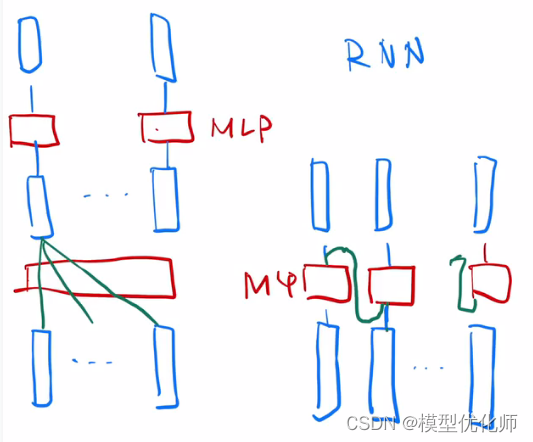
RNN 跟 transformer 异:如何传递序列的信息
RNN 是把上一个时刻的信息输出传入下一个时候做输入。Transformer 通过一个 attention 层,去全局的拿到整个序列里面信息,再用 MLP 做语义的转换。
RNN 跟 transformer 同:语义空间的转换 + 关注点
用一个线性层 or 一个 MLP 来做语义空间的转换。
关注点:怎么有效的去使用序列的信息。
6.2 一些细节
Transformer为何使用多头注意力机制?(为什么不使用一个头)
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以类比CNN中同时使用
多个滤波器
的作用,直观上讲,
多头的注意力
有助于网络捕捉到更丰富的特征/信息。
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
使用Q/K/V不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。
同时,由softmax函数的性质决定,实质做的是一个soft版本的arg max操作,得到的向量接近一个one-hot向量(接近程度根据这组数的数量级有所不同)。如果令Q=K,那么得到的模型大概率会得到一个类似单位矩阵的attention矩阵,
这样self-attention就退化成一个point-wise线性映射
。这样至少是违反了设计的初衷。
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale
那么至于为什么需要用维度开根号,假设向量q,k满足各分量独立同分布,均值为0,方差为1,那么qk点积均值为0,方差为dk,从统计学计算,若果让qk点积的方差控制在1,需要将其除以dk的平方根,是的softmax更加平滑
在计算attention score的时候如何对padding做mask操作?
padding位置置为负无穷(一般来说-1000就可以),再对attention score进行相加。对于这一点,涉及到batch_size之类的,具体的大家可以看一下实现的源代码,位置在这里:
padding位置置为负无穷而不是0,是因为后续在softmax时,
e0=1e^0=1e0=1
,不是0,计算会出现错误;而
e−∞=0e^{-\infty} = 0e−∞=0
,所以取负无穷
为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
将原有的
高维空间转化为多个低维空间
并再最后进行拼接,形成同样维度的输出,借此丰富特性信息
基本结构:Embedding + Position Embedding,Self-Attention,Add + LN,FN,Add + LN
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
简单介绍一下Transformer的位置编码?有什么意义和优缺点?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
你还了解哪些关于位置编码的技术,各自的优缺点是什么?(参考上一题)
相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
简单讲一下Transformer中的残差结构以及意义。
就是ResNet的优点,解决梯度消失
为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
LN:针对每个样本序列进行Norm,没有样本间的依赖。对一个序列的不同特征维度进行Norm
CV使用BN是认为channel维度的信息对cv方面有重要意义,如果对channel维度也归一化会造成不同通道信息一定的损失。而同理nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
简答讲一下BatchNorm技术,以及它的优缺点。
优点:
第一个就是可以解决内部协变量偏移,简单来说训练过程中,各层分布不同,增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使
**损失平面更加的平滑**
,从而加快的收敛速度。
第二个优点就是缓解了
**梯度饱和问题**
(如果使用sigmoid激活函数的话),加快收敛。
缺点:
第一个,batch_size较小的时候,效果差。这一点很容易理解。BN的过程,使用 整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
第二个缺点就是 BN 在RNN中效果比较差。
简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
ReLU
FFN(x)=max(0, xW1+b1)W2+b2FFN(x)=max(0,~ xW_1+b_1)W_2+b_2FFN(x)=max(0, xW1+b1)W2+b2
Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
Cross Self-Attention,Decoder提供Q,Encoder提供K,V
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
让输入序列只看到过去的信息,不能让他看到未来的信息
Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
Encoder侧:模块之间是串行的,一个模块计算的结果做为下一个模块的输入,互相之前有依赖关系。从每个模块的角度来说,注意力层和前馈神经层这两个子模块单独来看都是可以并行的,不同单词之间是没有依赖关系的。
Decode引入sequence mask就是为了并行化训练,Decoder推理过程没有并行,只能一个一个的解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题),传统词tokenization方法不利于模型学习词缀之间的关系”
BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。
优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
Dropout测试的时候记得对输入整体呈上dropout的比率
引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系。
面试题笔记分享
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖Android所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
每一章节都是站在企业考察思维出发,作为招聘者角度回答。从考察问题延展到考察知识点,再到如何优雅回答一面俱全,可以说是求职面试的必备宝典,每一部分都有上百页内容,接下来具体展示,完整版可直接下方扫码领取。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
 ## 大模型(LLMs)基础面
## 大模型(LLMs)基础面
1.目前 主流的开源模型体系 有哪些?
2.prefix LM 和 causal LM 区别是什么?
3.涌现能力是啥原因?
4.大模型 LLM的架构介绍?
大模型(LLMs)进阶面
1.llama 输入句子长度理论上可以无限长吗?
2.什么是 LLMs 复读机问题?
3.为什么会出现 LLMs 复读机问题?
4.如何缓解 LLMs 复读机问题?
5.LLMs 复读机问题
6.lama 系列问题
7.什么情况用 Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?8.各个专业领域是否需要各自的大模型来服务?
9.如何让大模型处理更长的文本?
大模型(LLMs)微调面
1.如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
2.为什么 SFT之后感觉 LLM傻了?
3.SFT 指令微调数据 如何构建?
4.领域模型 Continue PreTrain 数据选取?5.领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
6.领域模型 Continue PreTrain ,如何 让模型在预训练过程中就学习到更多的知识?7.进行 SFT操作的时候,基座模型选用Chat还是 Base?
8.领域模型微调 指令&数据输入格式 要求?
9.领域模型微调 领域评测集 构建?
10.领域模型词表扩增是不是有必要的?
11.如何训练自己的大模型?
12.训练中文大模型有啥经验?
13.指令微调的好处?
14.预训练和微调哪个阶段注入知识的?15.想让模型学习某个领域或行业的知识,是
应该预训练还是应该微调?
16.多轮对话任务如何微调模型?
17.微调后的模型出现能力劣化,灾难性遗忘
是怎么回事?
大模型(LLMs)langchain面
1.基于 LLM+向量库的文档对话 基础面
2.基于 LLM+向量库的文档对话 优化面
3.LLMs 存在模型幻觉问题,请问如何处理?
4.基于 LLM+向量库的文档对话 思路是怎么样?
5.基于 LLM+向量库的文档对话 核心技术是什么?
6.基于 LLM+向量库的文档对话 prompt 模板如何构建?
7.痛点1:文档切分粒度不好把控,既担心噪声太多又担心语义信息丢失
2.痛点2:在基于垂直领域 表现不佳
3.痛点 3:langchain 内置 问答分句效果不佳问题
4.痛点 4:如何 尽可能召回与 query相关的Document 问题
5.痛点5:如何让 LLM基于 query和 context
得到高质量的response
6.什么是 LangChain?
7.LangChain 包含哪些 核心概念?
8.什么是 LangChain Agent?
9.如何使用 LangChain ?
10.LangChain 支持哪些功能?
11.什么是 LangChain model?
12.LangChain 包含哪些特点?
大模型(LLMs):参数高效微调(PEFT)面
1.LORA篇2.QLoRA篇
3.AdaLoRA篇
4.LORA权重是否可以合入原模型?
5.LORA 微调优点是什么?
6.LORA微调方法为啥能加速训练?
7.如何在已有 LORA模型上继续训练?
1.1 什么是 LORA?
1.2 LORA 的思路是什么?
1.3 LORA 的特点是什么?
2.1 QLORA 的思路是怎么样的?
2.2 QLORA 的特点是什么?
8.3.1 AdaLoRA 的思路是怎么样的?为什么需
要 提示学习(Prompting)?
9.什么是 提示学习(Prompting)?10.提示学习(Prompting)有什么优点?11.提示学习(Prompting)有哪些方法,能不能稍微介绍一下它们间?
4.4.1为什么需要 P-tuning v2?
4.4.2 P-tuning v2 思路是什么?
4.4.3 P-tuning v2 优点是什么?
4.4.4 P-tuning v2 缺点是什么?
4.3.1为什么需要 P-tuning?
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
## 大模型评测面(LLMs)三
大模型怎么评测?
大模型的 honest原则是如何实现的?模型如何判断回答的知识是训练过的已知的知识,怎么训练这种能力?大模型(LLMs)强化学习面奖励模型需要和基础模型一致吗?RLHF 在实践过程中存在哪些不足?如何解决 人工产生的偏好数据集成本较高很难量产问题?如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?如何解决 PPO 的训练过程同时存在4个模型(2训练,2推理),对计算资源的要求较高问题?















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









