






在人工智能快速发展的今天,不论是从业者还是爱好者,都避不开一个关键的领域——提示工程。简单来说,提示工程就是一种方法,用来教导人工智能(特别是语言模型)如何更好地理解和回应我们的请求。
本篇文章从概念介绍以及常用策略实验等方面,详细地作了讲解。
Part1
什么是提示工程?
提示工程(Prompt Engineering)用于提升大型语言模型(Large Language Model, LLM)在处理复杂任务场景的能力,比如问答或推理计算能力。这是一门比较新的学科,随着AI应用的爆发性增长而进入大众视野。
提示工程在与大型模型交互、对接,以及理解大型模型预测能力等方面发挥着重要作用。我们熟知的ChatGPT就使用了提示工程来提高多轮对话的效果。
比较现实的是,工程师个人难以拥有深度学习所需的算力,无法提供模型训练和微调所需的资源,在某些特定场景下提示工程可能是门槛较低的优化大型模型方案之一。
提示词由四个要素组成:
**● 指令:**想要模型执行的任务
**● 上下文:**给模型提供一些额外的上下文信息,用于引导模型输出更优质的内容
**● 输入数据:**用户输入的内容或问题
**● 输出指示:**指定模型输出的类型或格式

大模型输出:
以下是⼀个简单的 Go 代码段,⽤于输出 “hello world”:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
上例示例中,指令或任务是“展示一段代码”,输出数据为“要求输出 ‘hello word’”,输出指示为“编程语言为 Go 语言”。上例示例中并没有包含**上下文,**但是大模型依然输出了我们期望的内容,可见提示词并非上述元素都是必须的。同时通过大模型的输出,我们可以发现“要求输出 ‘hello word’”,被大模型输出为 fmt.Println(“hello world”),模型矫正了单词错误。
在使用提示词时,一般工程师会通过 API 调用的方式或直接与大模型进行交互,在这个阶段可以通过配置一些参数用来优化输出结果。不同参数对于输出的结果非常重要,常见的一些参数设置:
● Temperature: 这个参数值越小,模型返回的结果越精确,这个参数越大,模型返回的随机性越大。在一些需要精确结果的应用场景下可以将这个值调小,反之在一些创造性强的场景下,例如生成诗歌、编一个故事……可以适当通过调高参数值以丰富模型输出。
● Max Length: 这个参数用于控制大模型 Token 输出,可以避免大模型生成冗长或无意义的响应。
**● Stop Sequences:**用来控制大模型输出的另一种方式,是一个 string 类型,设置可以控制列表输出项等。
● Frequency Penalty: 用来调整多轮对话中,某个词在模型输出中出现的次数,该参数越高,某个词再次出现的可能性就越小。
上例参数是大模型可调参数的一部分,具体可根据大模型相关文档(https://open.bigmodel.cn/dev/api#glm-4)进行阅读,本文所有示例基于 GLM-4,但不确保模型响应与本文示例保持一致。
在 OpenAI 官网提供的提示工程指南中提出了六个原则:
-
写出清晰的指令
-
提供参考文本
-
将复杂的任务拆分成简单的子任务
-
给模型“思考”的时间
-
使用外部工具
-
系统地测试变更
Part2
零样本提示和少样本提示
经过大训练出来的大模型已经能够执行零样本任务,即不提供任何示例,模型依然会输出相对符合期望的结果,这源于 RLHF 技术在深度学习时让模型更好地适应人类偏好。但在更复杂的场景或问题下,零样本下的大模型无法输出更优质的结果,这便衍生出少样本提示来引导模型。
零样本提示:

少样本提示:

我们通过上述例子可以观察到,“槑雷”这个人为臆造的词在零样本生成下可能词不达意,但是在少样本提示下,大模型通过示例已经学会了如何正确使用该词。
标签和格式也会对大模型的输出起作用:
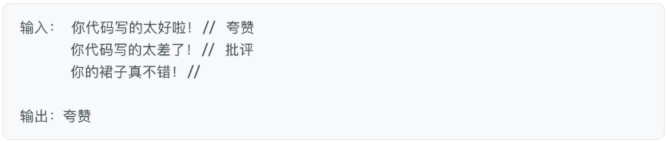
即使是随机标签也会对输出有帮助,毕竟有总比没有好。

可以拿计算器试一下,大模型这方面是反直觉的,用户可能认为基础的计算应该是百无一失的,实际上 151 + 321 + 51 + 131 + 821 + 71 + 121 并不等于 1766 而是 1677,七个奇数相加怎么会得出偶数结果呢?这个结果与大模型后续输出的思考内容也是相悖的。
即使提供少样本提示也很难获得这种类型的推理问题的可靠响应。
Part3
思维连提示
当任务过于复杂,少样本提示无法起作用时,可以使用思维链(CoT)提示。有一个更简单的方式:

“让我们逐步思考”提示是一种自动化思维链展示,在没有太多的示例提供时它相当好用。假设你使用人工手动解析这一计算过程,也可能会输入错误信息(毕竟人类也会犯错,当然,现在大模型也会)而误导大模型。这种自动思维链的方式可以消除人工的方法,当然这种自动的过程也会出错,所以演示的多样性依旧重要:
Auto-CoT 两个阶段:
● 问题聚类:给问题划分为几个聚类
● 演示抽样,从每组数据中选出一个具有代表性的样本,并使用带有简单启发式的 Zero-Shot-CoT 生成其推理链。
简单的启发式方法可以是问题的长度(例如,60 个 tokens)和理由的步骤数(例如,5 个推理步骤)。这鼓励模型使用简单而准确的演示。
Part4
链式思考(CoT)提示
还记得最开始 OpenAI 推荐的六个原则吗?将复杂的任务拆解成简单的子任务。就像人类在面对上述计算题会将数字逐步拆分,在将多个结果整合后给出最终答案。所谓的链式提示就是将子任务的提示词给语言模型。

提示词:
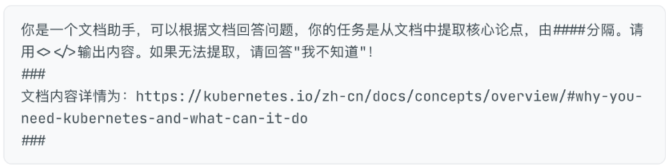
输出:

然后将第一次的输出以提示词的方式作为第二次提示的输入:

输出:

链式提示在构建 LLM 驱动的对话助手时特别有用,它能在多轮对话中不断优化输出性能,在这个过程中也会涉及到提示词技术中的“生成知识提示”,可以人为地将一部分知识作为提示词输入给模型,从而优化质量。
基于链式思考提示,也衍生出思维树(ToT)框架引导模型将思维当作中间步骤来解决一些通用问题,这有点回归到数学,通过广度优先搜索或深度优先搜索来对每一步思维进行抽样,然后以多轮对话搜索树的方式来增强大模型的能力。
ToT 提示词的例子如下(来源于 Hulbert:https://github.com/dave1010/tree-of-thought-prompting):

Part5
检索增强生成 (RAG)
通用语言模型仅仅通过微调就可以完成一部分常见任务。本文中使用的智谱 GLM-4 大模型在自我一致性和零样本提示下已经表现得超出预期,但是依旧无法完成复杂的知识密集型的任务。
检索增强生成 (Retrieval Augmented Generation, RAG) 用来优化这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起,可以简单理解为“给大模型联网”,以生成知识提示的方式来优化大模型的输出。同时 RAG 可以进行调整,而不需要对整个模型进行新训练,这不仅节约了算力/时间等资源,也节约了成本。
RAG 会先接受输入,按照输入检索出一组相关的资料文档,然后将这些文档作为上下文和输入的原始提示词结合,然后再输入给大模型得到最终输出。这样大模型不用重新训练也可以获取新的知识,这非常有效,同时也对传统的搜索引擎巨头提出挑战。有一些 AI 搜索的应用可以让用户提炼出更加准确的条目并且避免了广告。例如秘塔,必应等。
RAG 已经是一种可行的方案,在知识密集型任务中越来越流行。LangChain 文档中的 Quickstart(https://python.langchain.com/v0.1/docs/use_cases/question_answering/quickstart/)记录了如何帮助构建一个 RAG 应用。
Part6
后记
提示工程虽然是一门较新的学科,但其发展速度(论文发布速度)却让人咂舌。即使不做 AI 应用相关的开发,作者本人也推荐大家看一下提示工程相关的资料,这也有助于提高输入质量,能从 AI 产品中获取更准确、更有质量的输出。















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









