






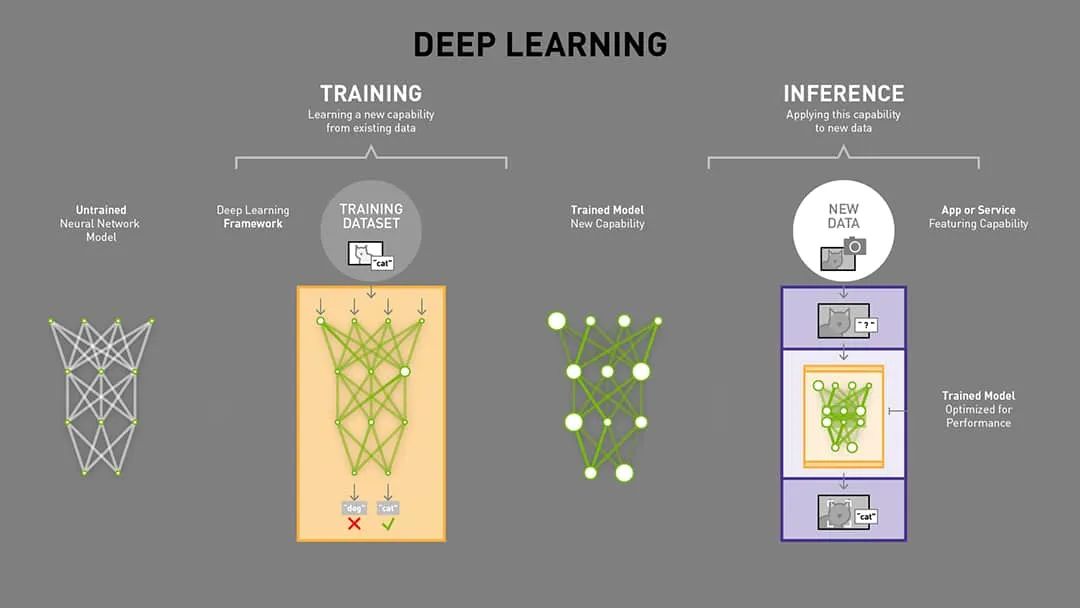
Training vs Inference
模型训练(Training) 是通过大量数据优化模型参数以学习数据特征的过程,而 模型推理(Inference) 则是利用训练好的模型对新数据进行高效准确的处理以得出结论的过程。
-
模型训练(Training):已知一系列(x, y)对,通过优化算法调整F的参数,使得F能够尽可能准确地映射x到y。
-
模型推理(Inference):已知训练好的函数F和新的输入x,使用F计算得到对应的输出y的预测值。
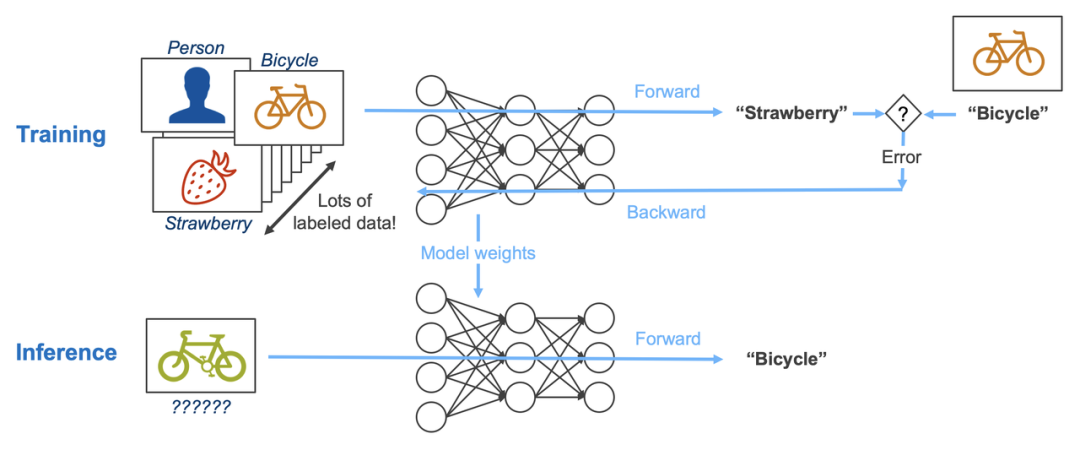
Training vs Inference
一、模型(Model)
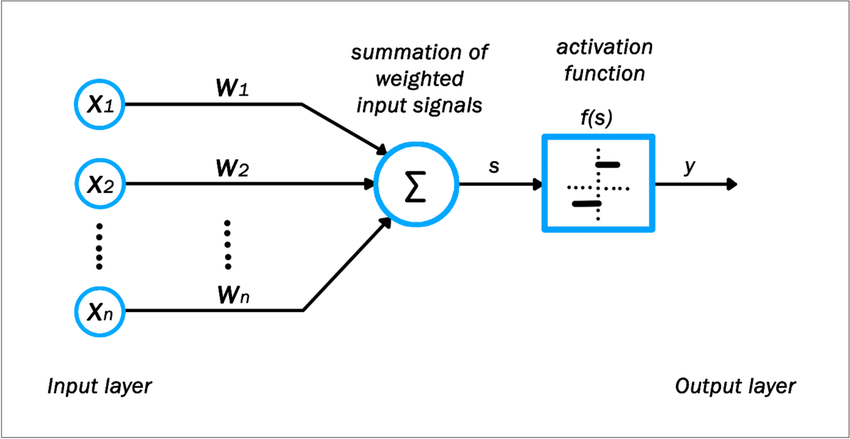
什么是模型?带有未知的参数(parameter)的函数称为模型(model)****。
**y = b + w ∗ x1,就是一个带有未知的参数的函数,特征(feature) x1 是这个函数里面已知的,它是来自于打标的数据,**而 w 跟 b 是未知的参数。w 称为权重(weight),b 称为偏置(bias)。
机器学习和深度学习模型的区别?机器学习模型依赖手工设计和提取特征,而深度学习模型则能自动从数据中学习并提取高级特征。
-
手工设计和提取特征:**在机器学习模型中,通常需要人工参与到特征提取的过程中。**这意味着在将数据输入到机器学习算法之前,需要由专家或领域知识丰富的人员来设计和选择哪些特征对于模型来说是重要的,并将这些特征从原始数据中提取出来。这个过程称为特征工程,它对于机器学习模型的性能有着至关重要的影响。
-
自动学习特征:**与机器学习不同,深度学习模型能够自动从原始数据中学习并提取有用的特征,而无需人工干预。**深度学习模型通过构建多层神经网络,每一层都能够从前一层提取更高级别的特征。这种自动学习特征的能力使得深度学习在处理复杂、高维的数据(如图像、语音、文本等)时具有显著的优势。
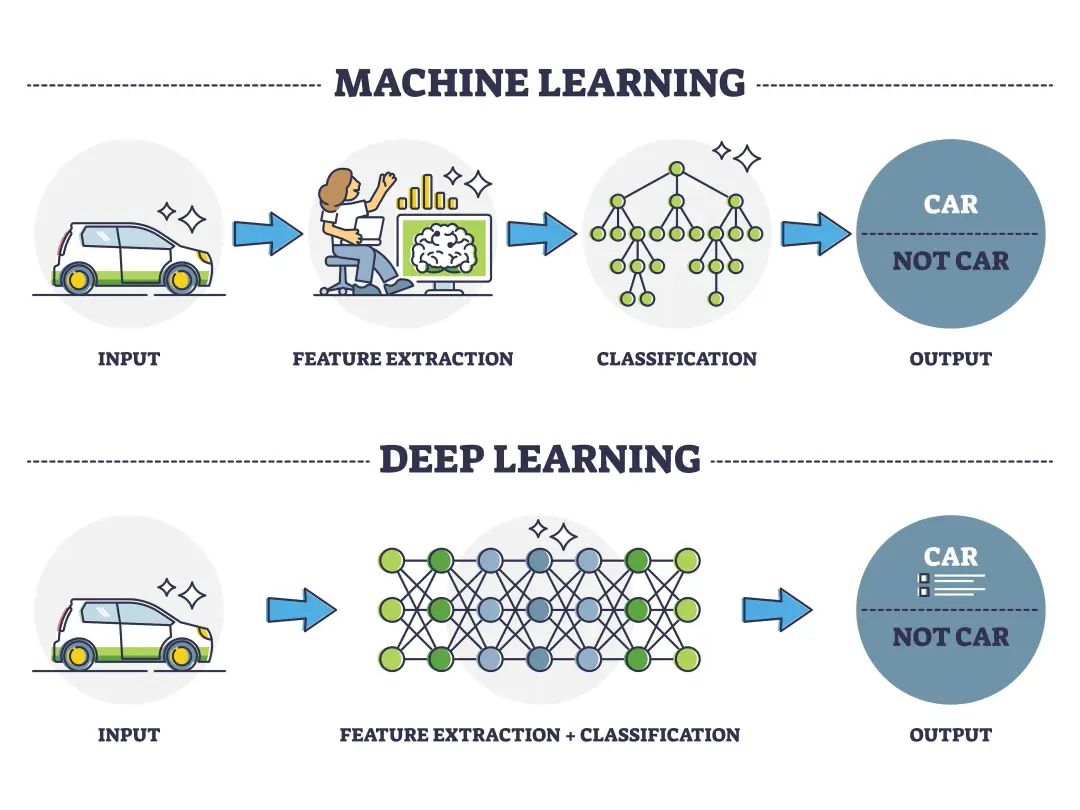
Machine Learning vs Deep Learning
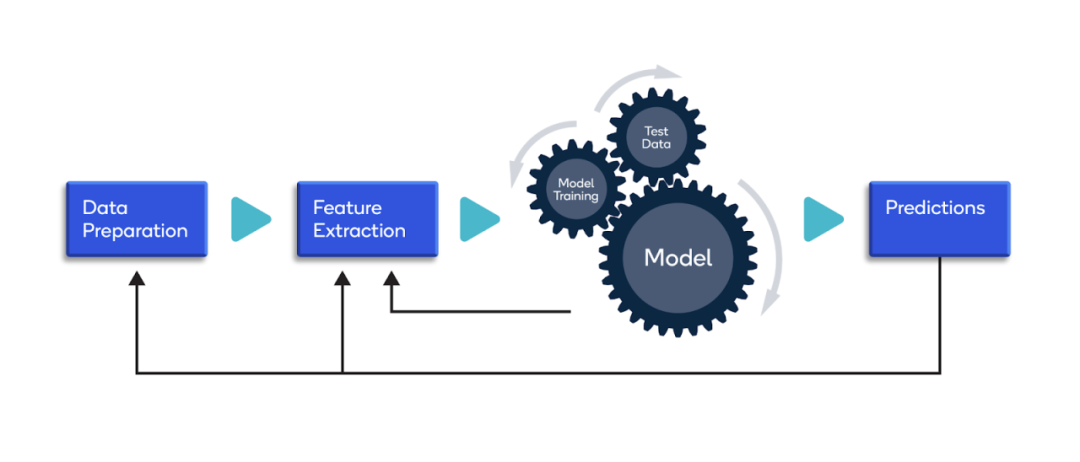
二、模型训练(Training)
什么是模型训练?使用一组已知的数据(称为训练数据)来训练(或学习)一个模型,以便该模型能够学习数据的内在模式和特征,从而能够准确地对新数据进行预测或分类。
Training
如何进行模型训练? 在模型训练过程中,算法会调整模型的参数(如神经网络中的权重和偏置),以最小化一个预先定义的目标函数(或损失函数)。
这个目标函数衡量了模型预测值与真实值之间的差异,训练的目标就是找到一组参数,使得这种差异最小。
Training
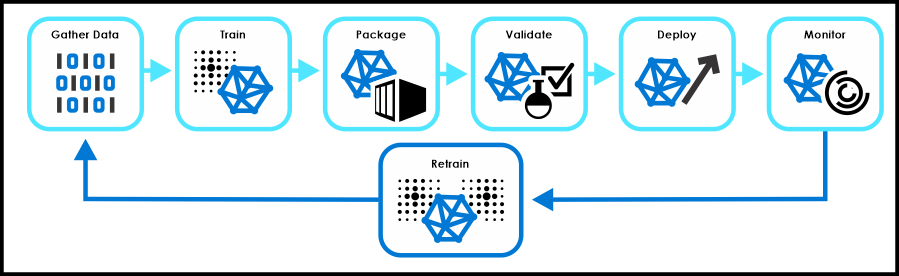
模型训练过程通常包括以下几个步骤:
-
数据准备:收集并准备训练数据,包括数据清洗、标注、归一化、分割成训练集和验证集(有时还有测试集)等。
-
模型选择:根据任务需求和数据特性选择合适的模型架构。这可能是一个简单的线性回归模型,也可能是一个复杂的深度神经网络。
-
参数初始化:为模型的参数(如权重和偏置)赋予初始值。这些初始值通常是随机生成的,但也可以是预先设计的。
-
前向传播:将训练数据输入到模型中,通过模型的各层进行计算,得到模型的预测输出。
-
损失计算:计算模型的预测输出与真实输出之间的差异,即损失值。
-
反向传播:根据损失值,使用梯度下降等优化算法计算模型中每个参数的梯度,并将这些梯度反向传播回模型的每一层。
-
参数更新:使用梯度来更新模型的参数,以减少损失值。
-
迭代训练:重复执行前向传播、损失计算、反向传播和参数更新的过程,直到满足某个停止条件(如损失值降低到一定阈值以下,或达到预设的训练轮次)。
Training
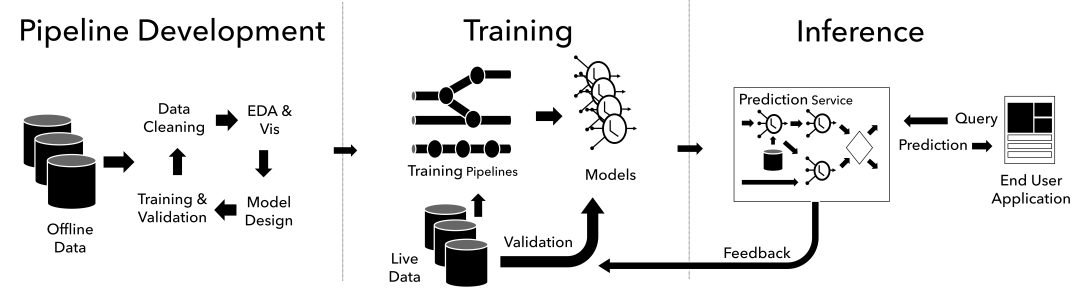
三、模型推理(Inference)
什么是模型推理? 在模型训练完成后,使用训练好的模型对新数据进行预测或生成的过程。
在模型训练阶段,模型通过大量数据的学习,掌握了某种特定的能力或模式。而在推理阶段,模型则利用这种能力对新的、未见过的数据进行处理,以产生预期的输出。
Inference
如何评估模型性能?模型评估(Evaluation)是指对训练完成的模型进行性能分析和测试的过程,以确定模型在新数据上的表现如何。

Evaluation
分类任务常见的评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)等。
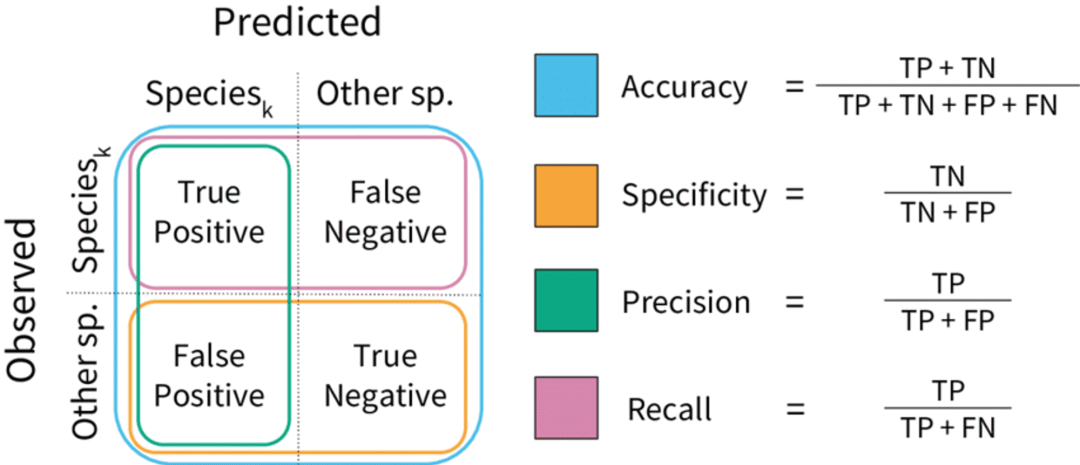
Evaluation
1. 准确率(Accuracy)
-
定义:准确率是最直观也最常被提及的评估指标之一,它衡量的是模型预测正确的样本数占总样本数的比例。
-
计算公式:准确率 = (真正例 + 真负例) / (真正例 + 假正例 + 真负例 + 假负例)
2. 精确率(Precision)
-
定义:精确率是指模型预测为正例中真正是正例的比例,它反映了模型预测为正例的结果的可信度。
-
计算公式:精确率 = 真正例 / (真正例 + 假正例)
3. 召回率(Recall)
-
定义:召回率,也称为灵敏度(Sensitivity)或真正例率(True Positive Rate),是指模型在所有实际为正类的样本中,被正确预测为正类的样本的比例。它反映了模型捕获正类样本的能力。
-
计算公式:召回率 = 真正例 / (真正例 + 假负例)
4. F1分数(F1 Score)
-
定义:F1分数是精确率和召回率的调和平均数,旨在综合两者的表现,提供一个平衡指标。
-
计算公式:F1分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)

最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









