






前言
本文我们介绍另外一种部署本地知识库的方案:
Ollama + MaxKB
相对来说,容易安装且功能较完善,30 分钟内即可上线基于本地大模型的知识库问答系统,并嵌入到第三方业务系统中。
缺点是如果你的电脑配置不高,问题回答响应时间较长。
下图为 MaxKB 的产品架构:
实现原理上,仍然是应用了 RAG 流程:
安装 MaxKB
首先我们通过 Docker 安装 MaxKB
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data cr2.fit2cloud.com/1panel/maxkb
注意这里镜像源是 china mainland,走代理的镜像会下载失败。
安装成功后访问:http://localhost:8080/ 登录,初始账号为:
用户名: admin 密码: MaxKB@123..
进入系统后是这样的:

配置模型
接下来我们进行最重要的模型配置
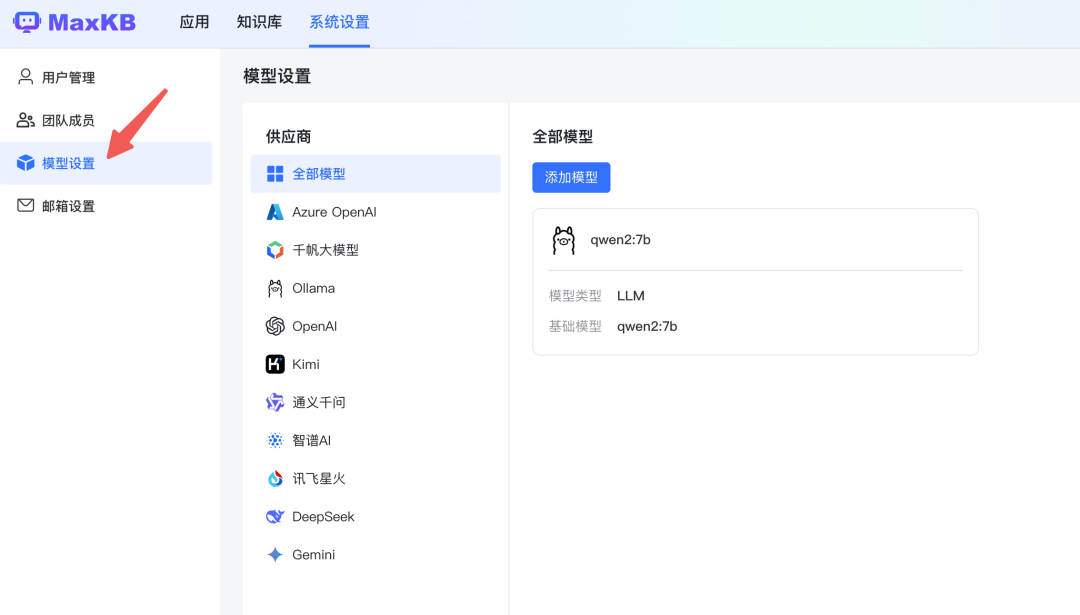
可以看到有许多模型的供应商,这里你可以通过 API key 在线去连接大模型
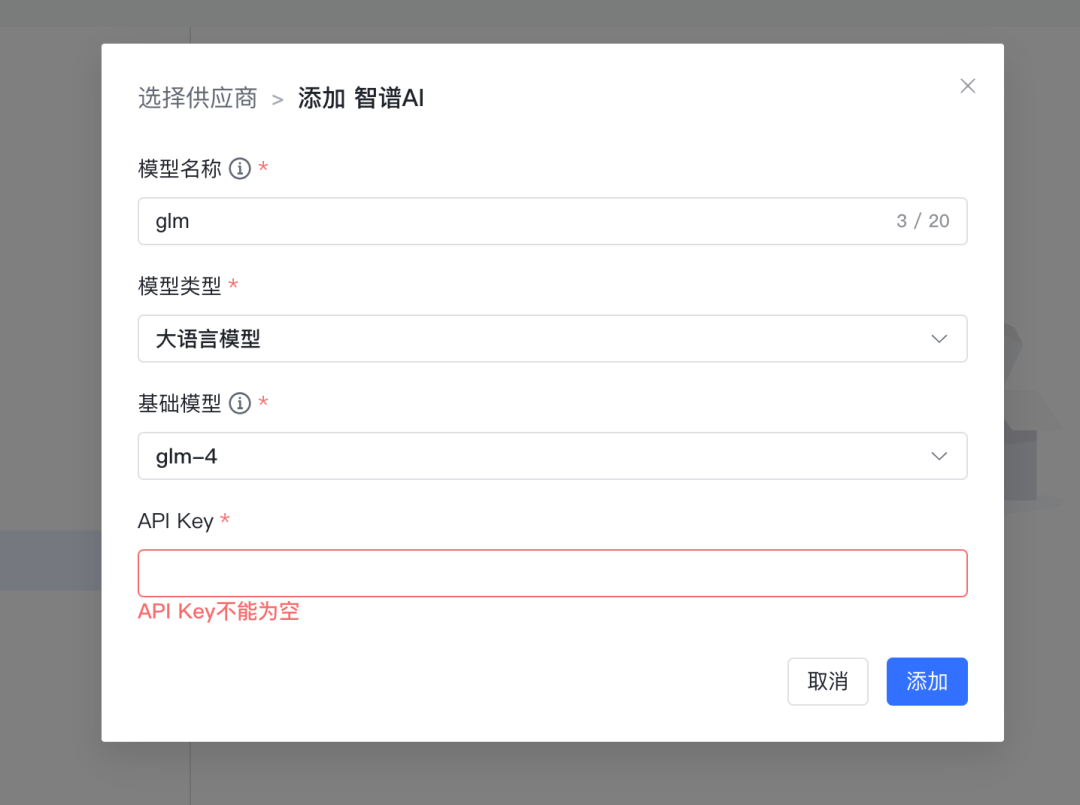
API key 不同的模型厂商有不同的申请地址,这种方式不是本文采用的方式,本文我们将把通过 Ollama 本地部署的 Qwen2 大模型配置到 MaxKB
所以,第一步我们添加模型选择 Ollama

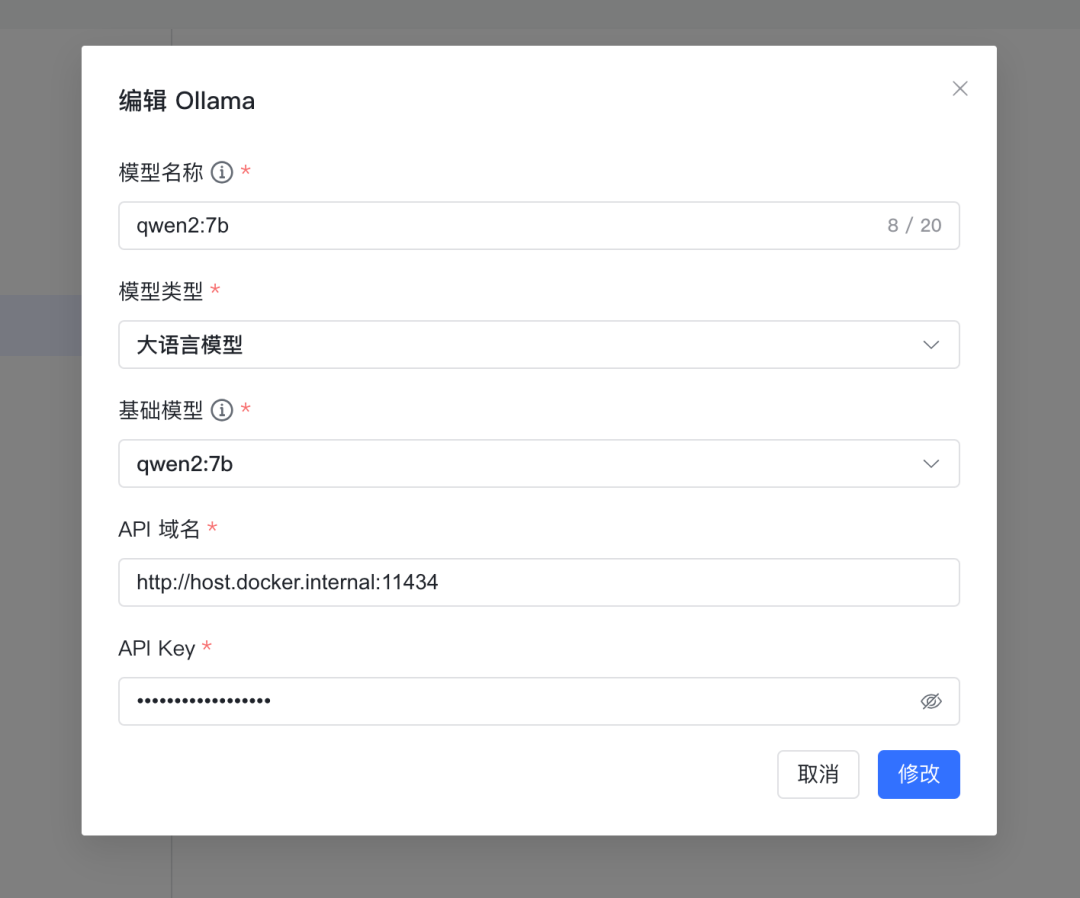
第二步配置模型,在模型添加界面有几个点要注意(下图是修改界面,和添加界面差不多)
-
模型名称和基础模型一定要和你在
ollama list中显示的一样,不然可能会导致没有必要的重复下载和连接失败
-
API 域名,因为 MaxKB 是 Docker 部署的,Ollama 是本机部署的,不在一个网络环境,所以要填 :http://host.docker.internal:11434
-
API Key 随便写什么都行
创建知识库
模型添加完成,就可以创建知识库了。
这个比较简单,通过界面功能自己就能搞定,我就不多说了
这里比较好的是,MaxKB 支持选择文件夹,这一点 AnythingLLM 就不行,不过一次上传文件数量有限:

“
支持格式:TXT、Markdown、PDF、DOCX、HTML 每次最多上传50个文件,每个文件不超过 100MB 若使用【高级分段】建议上传前规范文件的分段标识
创建应用
知识库创建完,就可以创建应用进行问答了

这里注意除了要为应用添加知识库外,还要进行一下参数设置

我选择的是第二项,因为我的知识库数据量较小

设置完成后点击演示

问答效果展示

这里不太好的是没有同时展示引文,更不用说引文的预览了,实际上这个功能基本上是企业应用上的 刚需
嵌入第三方应用
嵌入三方应用的需求也是比较常见的,比如你可以通过 iframe 或者 js 代码的形式嵌入到你现有的系统中,我们经常看到一些网站右下角的浮窗就是这种形式,在 MaxKB 中支持嵌入三方应用,需要在应用的 “概览” 中点击 “嵌入第三方”

剩下的你只需要把代码集成到你的其他应用中就可以了

思考
学习新知识,最好的方式就是直接去应用它,你可能从来都不知道什么是 RAG,但对相关知识有个大概了解后,通过实践,亲自搭建几个可以 run 起来的应用,那些架构里的结构、名词,逐渐全部都能对应得上了。
我笔记本的配置有限,如果所有的东西都部署在配置有性能强较的显卡的服务器上,那么就可以满足企业级应用的需求了,企业可以直接完成私有化部署并开始应用。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









