






越来越多人开始关注大模型,很多做工程开发的同学问我怎么入门大模型训练推理系统软件(俗称大模型Infra)。
近年来国内互联网业务整体低迷,而大模型却在逆势崛起,每天新闻可谓繁花似锦,烈火烹油,和其他子领域形成了鲜明对比。环球同此凉热,2023年硅谷裁了几十万软件工程师,但美国各大厂都在疯狂买GPU高价招人做大模型,这半年的美股靠这波AI的预期再创新高。冷热对比,高下立判,作为计算机从业者肯定都不想错失上车的机会。
但需要提醒大家的是大模型Infra正在从黄金时代进入白银时代。我21年开始写大模型训练系统,算是周期完整的亲历者,谈谈我这些年观察到大模型Infra经历的几个阶段:
2019-2021,黑铁时代
17年那篇著名的《Attention is All you Need》论文发表,以Transformers为基础零件的不同模型结构接踵而至,Decoder-only的GPT-1(2018)、Encoder-only的Bert(2018),Encoder-Decoder的T5(2019)相继出现,开始在NLP领域大杀四方。互联网企业中的翻译、对话、推荐等应用场景相继被Transformers占领。
顺应潮流,有人开始研究变大Transformers模型。把模型变大在CNN时代是反直觉的,彼时大家正在通过NAS和AutoML等手段千方百计把模型变小,放到汽车、摄像头、手机里。Scaling Law(尺度定律,用更多计算和数据资源是不是就可以让模型增加智慧)的信徒主要是OpenAI,在18年OpenAI就用Transformers替换LSTM做了GPT-1,随后就出了GPT-2和GPT-3。
尽管,20年175B参数GPT-3的few-shot learining能力给业界带来了一些震撼,但国内对大模型技术路线持怀疑态度居多,拥趸寥寥,大部分算法同学对大模型并不感冒。我观察原因来源于两方面。一方面,大多数人没有预训练的sense,当时NLP算法开发范式是搞私有数据+微调Bert,根据小模型时代的经验,应该专注在数据质量,而不是一个更大底座模型,哪怕先把模型变大两倍,申请很多预算去训模型,ROI(投资回报率)存疑。
另一方面,Infra没有准备好。训练一个大模型可不是一般人可以玩得起的,现在训模型是算法+工程同学相互配合,那时候没有这种兵种搭配概念,业务团队里只有算法工程师,搞GPU对他们是头疼事情,尤其是上线一个需要两张GPU才能运行的模型,简直是灾难。而隶属于中台部门的Infra团队,又不了解大模型的风向,跨部门的信息是有壁的。
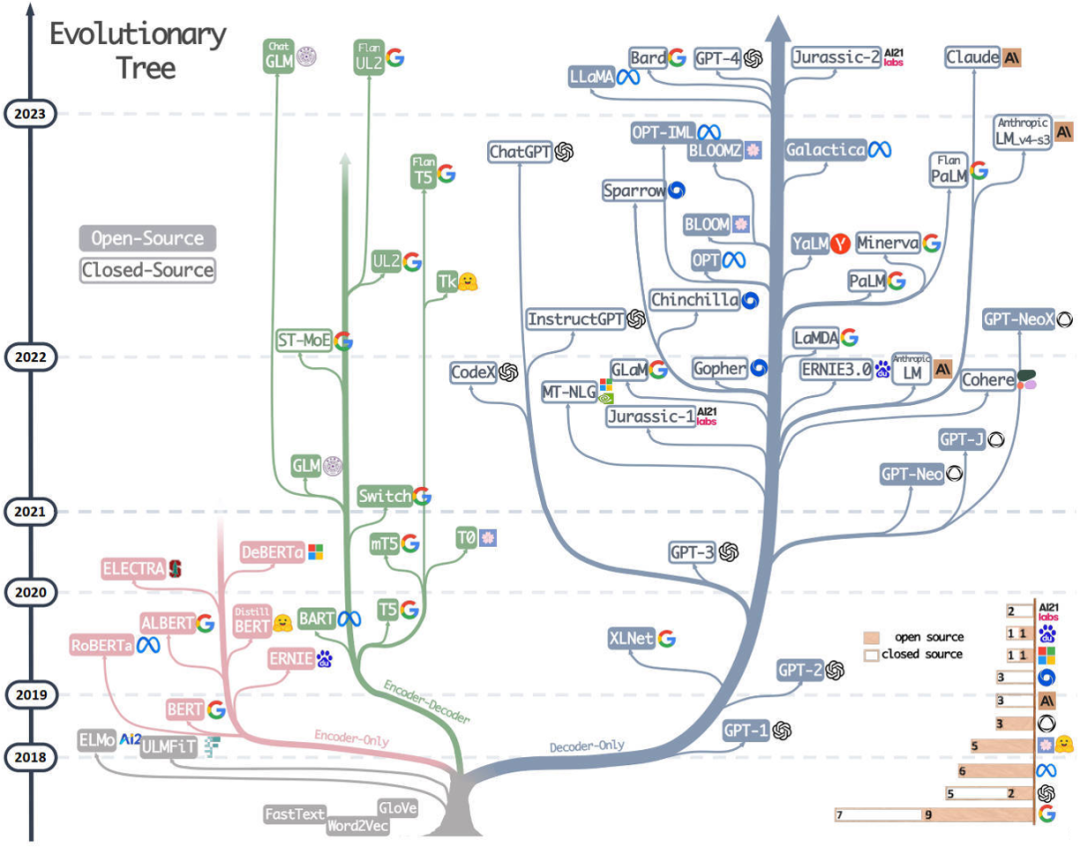
彼之砒霜,我之蜜糖。模型变大反而对AI Infra是新机会。那个时代AI Infra的主旋律应用还是推荐系统,NVIDIA在押宝元宇宙作为新增长点,大模型对Infra同学也是新鲜事物。有OpenAI和Google前面开路,美国有些机构开始了将模型变大的探索性工作,主要是沿着把Encoder结构的Bert变大,不过对于训练来说Encoder和Decoder的差别不大。也正是借着这波机会,大模型训练框架Megatron-LM和DeepSpeed开始有了原型。20年微软搞了17B大Bert的Turing-NLG,其训练代码成为了DeepSpeed的原型。19年,NVIDIA搞了8.3B的Megatron-LM,没错Megatron-LM是一个大Bert的名字,Megatron-LM仓库里也是放训练模型的代码脚本,这些脚本实现了张量并行,后面逐渐发展成了最流行的训练框架。
这一时期,美国大厂训模型主要目的是试试水和秀肌肉,因而DeepSpeed和Megatron-LM最开始就是开源的,这是一件好事。试想如果大模型出场就是核武器,大家都像22年之后OpenAI那样藏着掖着,Infra技术扩散必然没这么快了。
除了少数大模型Believer,国内大厂对大模型不感冒,各大厂的云/中台团队刚刚完成一轮X minutes训练ImageNet的军备竞赛,还在思索用那么大规模的GPU去训练一个模型有什么商业价值。有一些NLP技术创业公司,技术路线还是是给不同的业务做定制的微调Bert。一些机构的投资人会打电话咨询技术人员,大模型是否是骗局。在国内利润为先的情况下,ROI不明确的情况下是不可能批准采购大量GPU资源的。
总体来说,22年之前,大模型对国内来说还是太超前,以至于共识非常薄弱,因此我称之为大模型Infra黑铁时代。
2022-2023,黄金年代
经历了黑铁年代储备期之后,以Meta开源OPT-175B模型为标志,22年开始大模型Infra开始迎来黄金年代。
有人开始看到大模型的威力了,硅谷春江水暖鸭先知。22年5月份,Meta把OPT-175B的权重开源出来,它是为复现GPT3训练的,用的是PyTorch FairScale,虽然模型效果不敢恭维,但是真的是造福了广大大模型科研人员,做AI Infra的人也终于有一个真实模型可以做实验了。
22年伊始,在全国同心抗击口罩之计,国外已经好几路人马在紧锣密鼓训练GPT-3级别的模型。印象比较深的是22年4月份,Transformers论文有两个作者离开Google成立了一个叫Adept.ai的大模型公司(如今刚刚卖身Amazon),用大模型帮人完成复杂任务,他们twitter的demo展示大模型能根据输入文字让Python画出一个柱状图表,我看到之后非常不可思议。
直到2022年11月,ChatGPT强势出圈,引爆了大模型。这一事件,显著加速了模型变大有价值共识的形成。大模型团队快速聚集了大量人力、物力、财力。大模型Infra也迎来了跨越式发展。
在技术创新上,遍地是黄金。并行策略和算子优化等方面很多机会,比如Sequence Parallelism、Flash Attention之类simple but effective的作品都获得巨大影响力。预训练之后,还有 SFT,RLHF的需求,也有训推混合调度和S-LoRA之类工作的诞生。
大模型Infra也深刻影响了上层算法的发展轨迹。比如,很长时间大家不敢增大context length,因为Attention计算中间QK^T矩阵的内存是序列的平方项开销,导致有一段时间Linear Attention,Approximate Attention用精度换长度的研究之风盛行。Memory Efficient Attention工程优化出现之后,最著名的是Flash Attention,直接把内存平方项干没了,大家又回到了老老实实用标准Attention的正轨。
Bert时代系统优化可以复用到GPT 的 Prefill 阶段,但是还缺少Decoding 阶段关键问题的解决方案。Encoder到Decoder的范式迁移,对训练变化很小,但对推理影响很大。从计算密集问题变成Prefill阶段计算密集,Decoding阶段访存密集的超级复杂的问题。在Bert时代的各种优化都没法用到Decoding阶段里。由于Decoding输出长度是不确定的,导致两个难以解决的关键问题,一、如何动态打Batching,在输出token长度不确定时减少无效的padding计算,二、如何动态分配GPU显存给KVCache且没有内存碎片被浪费。
推理虽然起步晚,但是发展速度要比训练快很多倍。因为,推理资源需求小,门槛低,大家都能参与进来,集思广益,汇聚广大人民群众的智慧,很多问题都会立刻暴露,然后立刻解决。2022年,OSDI论文ORCA提出了Continous Batching,解决了问题一。而就在距离今天exactly一年前的2023年6月,国内绝大多数大模型从业这都不知道Continous Batching。2023年的,SOSP论文Paged Attention解决了问题二。
在推理系统领域,大发展的出现比训练晚很多,主要发生在2023年之后。一方面,模型没训练出来,也就没有推理需求。另一方面,Decoder结构没有定于一尊之前,推理加速也没研究到正点上,之前大家都在关注怎么优化Encoder Transformers的推理。
真正的Game Changer是伯克利的vLLM,2023年6月开源出来,以其独创的Paged Attention技术一战成名。这时候刚好各种大模型也都训出了第一个版本,vLLM一下子满足了这波集中上线部署的需求。2023年9月份,NVIDIA推出了TensorRT-LLM,先是定向开源给企业内测,后面又对外开源,也分走了推理一大块蛋糕。2023年初NVIDIA才正式组织力量去发展Decoder模型推理框架,
训练推理的需求一下子就起来了,吸引很多人才加入大模型Infra领域,大模型Infra领域迎来了一波繁荣,普通人只要学习能力强,就有机会上车,因此我称之为黄金时代。
2024-,白银时代
2024年,尽管大模型百花齐放,但是生产资料向头部集中,从业者阶级固化加剧,大模型Infra进入白银时代。
在经历2023年的“错失恐惧症”带来疯狂之后,大家开始冷静下来,一些人开始退场,一些人开始扩张。
在预训练领域,GPU资源开始向头部集中。创业公司剩下那么六七家,部分和云厂商抱团。大厂内部也只有一个钦定的团队收走全部GPU做预训练。这个是和小模型时代显著不同的,之前每个业务团队都可以训练自己的模型,都能自己管理一些GPU算力。就好比,原来每个省都自己有一支部队,现在国家只有中央军了。因此,对人才的需求比传统AI业务要少,但是想入行的人极具增多,用人门槛有极具升高。如果不是加入国内那十几个预训练团队,大部分人可能和预训练无缘了。
在微调和推理领域,机会也在收缩。分开源和闭源模型两个方面来看收缩原因。对闭源模型,微调和推理都还是被预训练团队垄断的,因为几个亿烧出来的模型权重不能外流,只能客户拿数据进驻和被私有化部署。对开源模型,之前大家可能会认为,有了开源模型人人都可以做预训练下游的微调+部署流程。一个反直觉现象,尽管开源大模型数量在增多,能力在增强,但是微调和训练需求在减少。第一,微调的难度其实非常高,没有训模型经验是调不出自己预期的效果的,所以RAG方式大行其道,这只需要调用大模型MaaS API即可。第二,推理也非常卷,集成量化、调度、投机采样每一项技术的最佳实践难度不低。而且现在一些潮流分离式,混部等技术,对工程要求越来越高。一个小团队去搞推理部署反而干不过一些免费的开源MaaS的API,那个后面都有专业人士优化。
综上,大模型是和业务非常解耦的一项技术,更像是云厂商或者芯片。传统后台在线、离线系统,因为很多东西和业务有关,并不是标准件,因此没有做到最佳实践也有存在价值。对于大模型Infra,有开源框架作为一个水位线,the best or nothing,如果做不到最好就没有存在价值。因此,也可以参考芯片产业,资源会集中在少数巨头手中,大部分只能参与更下游的配套,比如RAG,Agent之类的。
综合看来,在白银时代,大模型Infra总体需求在增加,但是有马太效应,“凡有的,还要加给他,叫他有余;凡没有的,连他所有的也要夺去”。胜地不长,盛筵难再,已经上车的可以感受到刺激的推背感,但是没上车的只能干瞪眼。
但白银时代,毕竟也是一种贵金属,还是有很多机会。大模型Infra的盘子还在增大,更多的芯片,更多的新算法创新也在路上,这时候入行,体格强壮的挤一挤还是能上车的。
白银时代一些建议
大家常说七年一个周期,2016年Alpha-Go用深度学习开启了一个周期,到2022年ChatGPT用大模型开启了一个新周期。
很多人现在抱着有超额回报期望来入行大模型Infra,在白银时代这个预期需要降低。能过踩中周期的注定是少数人,因为有分歧才有风险,有风险才有超额收益。现在大模型的共识早就凝聚了,这个领域也注定会供需平衡,变成用市场规律说话。就好比你看买菜大妈就开始买某股票时候,这支股票已经挣不到钱了。
大模型注定会深刻改变我们的世界,但资源和信息向头部集中的趋势非常可怕。一方面,大模型核心技术被一小撮人掌握,比如OpenAI。另一方面,面对巨大信息差和算力差,普通人无法参与到大模型的开发体系中。就像萝卜快跑正在代替网约车司机,AI总有一天会也代替程序员。如何在生产力进步后的世界里找到自己的位置,不要沦为AGI世界的二等公民,是我们每个人焦虑的根源。
让社会不恐惧AI,让社会理性规划和AI融洽相处的未来,一方面要有对巨头有监管,另一方面,让更多人有平等了解大模型技术的机会。这个世界还是很有人在为后者努力,通过代码开源和公开论文,扩散大模型的技术。作为想入行的同学,可以借助开源力量,来让自己和也业界保持同步。这里也有大量还没有解决的技术挑战等待你来解决。另外,像Agent等,多模态,具身智能等技术方向方兴未艾,也可以提前布局下一个时代潮流。
作为大模型Infra从业者,白银时代需要的是苦练基本功。在2023年,有很多人是在用信息差体现自己价值,某件事我知你不知,你试还得花时间,很多人在极度激烈竞争中也原意为信息差知识付费。今年这种机会会大幅减少,大家比拼的就是真本领了,是否能快速follow新技术,是否能独立搞定一个复杂大系统,是否有更大的技术视野和其他合作方对话的能力,这要求不仅了解Infra还解一些算法、云计算的知识,总体来说传统工程师素养变得尤为重要。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
⑤AI+零售:智能推荐系统和库存管理优化了用户体验和运营成本。AI可以分析用户行为,提供个性化商品推荐,同时优化库存,减少浪费。
⑥AI+交通:自动驾驶和智能交通管理提升了交通安全和效率。AI技术可以实现车辆自动驾驶,并优化交通信号控制,减少拥堵。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题

如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









