






自LLM进入Agent时代,如何处理人机交互的历史信息和状态,一直是学术前沿思考的核心问题。因此,记忆模块(Memory)也就成为了研究重点。
以往研究的缺憾在于:
- 关注记忆在特定任务中的应用。如:记忆存储、检索或基于记忆的生成,却忽视了记忆动态变化背后的原子操作。
- 如何通过记忆增强模型的上下文理解能力。未深入研究记忆如何在不同时间尺度上进行整合、更新和遗忘,导致无法全面理解记忆在复杂交互中的作用机制。
- 缺乏对记忆操作的统一和全面视角。如长文本建模、长期记忆、个性化或知识编辑,未能将这些分散的研究成果整合到一个系统性的记忆架构中。
因此,作者提出一个全面的AI记忆研究框架,来解决上面这些问题。
Memory统一框架
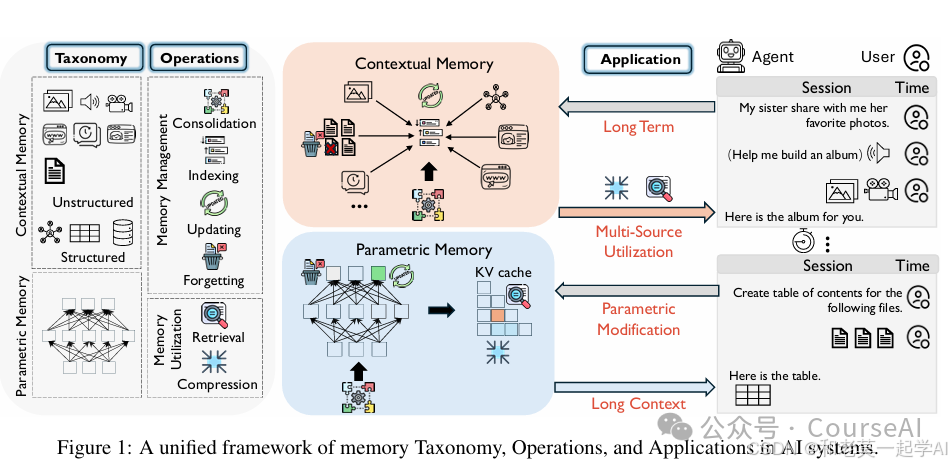
- 首先,文章对记忆表示进行了分类,将其分为:
- 参数记忆(Parametric Memory)
- 上下文结构化记忆(Contextual Structured Memory)
- 上下文非结构化记忆(Contextual Unstructured Memory)
- 并从时间跨度的角度进一步区分短期记忆和长期记忆。
- 其次,文章引入了六种基本记忆操作:
- 巩固(Consolidation)
- 更新(Updating)
- 索引(Indexing)
- 遗忘(Forgetting)
- 检索(Retrieval)
- 压缩(Compression)
- 最后,系统地将这些操作映射到长期记忆、长期上下文、参数修改和多源记忆等上去。
记忆的分类
- 参数记忆(Parametric Memory)
- 参数记忆是指:模型内部参数中隐式存储的知识。
- 这些知识在预训练或后训练过程中获得,并在推理时通过前馈计算访问。
- 参数记忆是一种即时的、长期的、持久的记忆,能够快速、无上下文地检索事实和常识知识。
- 然而,它缺乏透明度,难以根据新体验或特定任务上下文选择性地更新。
- 在需要快速访问通用知识的场景中,参数记忆发挥重要作用。
- 例如,在多轮对话中,模型可以利用参数记忆快速生成与常识相关的回答,而无需每次都从外部记忆中检索。
- 上下文非结构化记忆(Contextual Unstructured Memory)
- 这是一种显式的、模态通用的记忆系统,能够存储和检索跨异构输入(如文本、图像、音频和视频)的信息。
- 它使Agent能够基于感知信号进行推理,并整合多模态上下文。
- 根据时间范围,它进一步分为短期记忆(如当前对话会话上下文)和长期记忆(如跨会话对话记录和持久的个人知识)。
- 在多模态交互场景中,例如:智能助手需要根据用户的语音指令和当前环境图像生成回答时,上下文非结构化记忆能够提供丰富的上下文信息,帮助生成更准确、更自然的响应。
- 上下文结构化记忆(Contextual Structured Memory)
- 这种记忆被组织成预定义的、可解释的格式或模式。
- 如:知识图谱、关系表或本体论,同时保持易于查询。这些结构支持符号推理和精确查询,通常补充预训练语言模型的关联能力。
- 结构化记忆可以是短期的(在推理时构建用于局部推理)或长期的(跨会话存储策划的知识)。
- 在需要进行复杂推理和知识查询的场景中,如智能问答系统,结构化记。
记忆的操作

记忆管理(Memory Management)
- 巩固(Consolidation)
- 将短期记忆转化为长期记忆,通常通过总结对话历史等方式实现。
- 例如,MemoryBank系统通过总结对话历史,将关键信息编码为持久记忆,支持长期对话。
- 例如,识别对话中的关键实体和事件,并将其组织成知识图谱形式,以便长期存储和检索。
- 索引(Indexing)
- 通过构建结构化的索引,使记忆能够被高效、准确地检索。
- 例如,HippoRAG系统受海马体理论启发,构建轻量级知识图谱,明确揭示不同知识片段之间的连接。
- 将记忆表示为节点和边的集合,其中节点表示实体或概念,边表示它们之间的关系。
- 通过为每个节点添加时间戳、关键词等属性,支持基于时间顺序和内容相关性的检索。
- 更新(Updating)
- 根据新信息对现有记忆进行更新,以保持记忆的时效性和一致性。
- 例如,NLI-transfer系统通过选择性编辑,管理记忆中的过时信息。
- 对于参数记忆:采用定位和编辑机制,直接修改模型参数中与特定知识相关的部分。
- 对于上下文记忆:通过总结、修剪或提炼等技术,对记忆内容进行重组或替换。
- 例如,识别对话中的新信息,并将其与现有记忆进行对比,对过时或错误的信息进行修正。
- 遗忘(Forgetting)
- 选择性地删除不再相关或有害的记忆内容,以保护隐私、安全或符合合规要求。
- 例如,FLOW-RAG系统通过基于RAG的遗忘技术,从知识库中删除特定信息。
- 在参数记忆中,通过修改模型参数,擦除特定知识。
- 在上下文记忆中,通过基于时间的删除或语义过滤,丢弃不再相关的内容。
- 例如,通过设置记忆的过期时间或根据隐私政策的要求,删除用户不希望被记住的信息。
记忆利用(Memory Utilization)
-
检索(Retrieval)
- 基于查询的检索(优化查询公式和适应性)
- 基于记忆的检索(增强记忆候选的组织和排名)
- 基于事件的检索(根据时序和因果结构检索记忆)
-
根据给定的查询,从记忆中选择最相关的记忆条目。
-
例如,LoCoMo系统通过基于事件的检索,根据时序和因果结构检索记忆。
检索的目标可以是单一查询、复杂的多轮对话上下文,也可以是纯文本输入、视觉内容或更多模态。
-
检索方法可以分为:
-
例如,采用多跳图遍历技术,通过图结构中的路径,逐步检索与查询相关的记忆。
-
例如,对于一个关于事件发展的问题,系统可以通过图中的时间线和因果关系链,逐步找到与问题相关的记忆片段。
-
压缩(Compression)
- 预输入压缩:在没有检索的长上下文模型中,对全上下文输入进行评分、过滤或总结以适应上下文限制
- 后检索压缩:在记忆访问后,通过上下文压缩或参数压缩将检索到的内容进行压缩)。
-
在有限的上下文窗口下,通过保留关键信息并丢弃冗余信息,优化上下文的使用。
-
压缩可以分为:
-
与记忆巩固(在记忆构建过程中总结信息)不同,压缩侧重于在推理时减少记忆。
-
例如,通过提取关键句子或段落,将长文本压缩为更短的摘要。
-
在处理长文本或大量信息时,压缩操作能够提高系统的效率。
-
例如,在文档摘要系统中,通过压缩长文档,系统能够快速生成简洁的摘要,方便用户快速了解文档的主要内容。
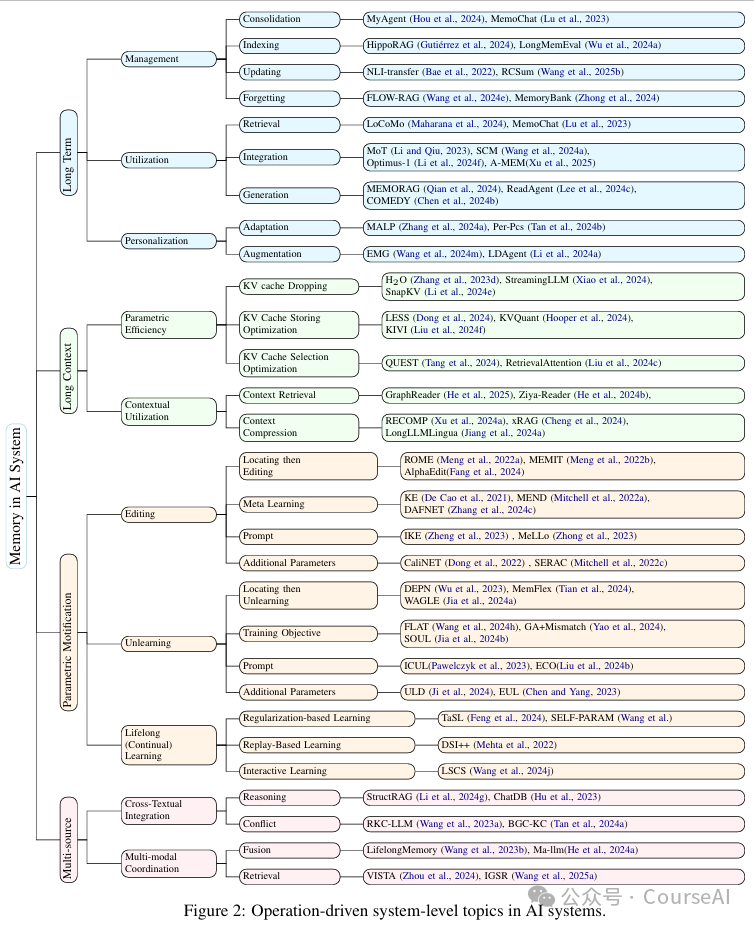

长期上下文(Long-context Memory)
长期上下文记忆涉及处理大量多源外部记忆的挑战,尤其是在对话搜索等场景中。
主要涉及两个方面:
- 参数效率(Parametric Efficiency)
- 上下文利用(Contextual Utilization)
参数效率(Parametric Efficiency)
- KV缓存丢弃(KV Cache Dropping)
- 通过丢弃不必要的KV缓存来减少缓存大小。例如,StreamingLLM采用Λ形稀疏模式,动态丢弃KV缓存。
- 静态丢弃方法根据固定模式选择不必要的缓存,而动态丢弃方法则根据查询或模型行为(如注意力权重)在推理过程中决定丢弃哪些KV缓存。
- 例如,通过分析注意力权重,识别出对当前推理贡献较小的KV缓存,并将其丢弃。
- KV缓存存储优化(KV Cache Storing Optimization)
- 通过压缩技术,以更小的存储空间保留整个KV缓存。例如,LESS方法将不重要的缓存条目压缩为低秩表示。
- 采用动态量化技术,如KVQuant方法,对KV缓存进行量化,以减少内存分配。例如,通过将KV缓存中的浮点数量化为低位表示,显著降低存储需求。
- KV缓存选择(KV Cache Selection)
- 根据查询选择性地加载所需的KV缓存,以加速推理。例如,QUEST方法采用查询感知的KV缓存选择,检索关键的KV缓存以加速推理。
- 采用近似最近邻搜索技术,如RetrievalAttention方法,快速检索与查询最相关的KV缓存。例如,通过构建一个高效的索引结构,快速定位与当前查询最相似的KV缓存。
上下文利用(Contextual Utilization)
- 上下文检索(Context Retrieval)
- 增强LLMs从上下文记忆中识别和定位关键信息的能力。例如,GraphReader方法通过将文档分解为图结构,有效选择上下文。
- 采用基于图的检索技术,如CGSN方法,通过图结构中的路径和关系,快速定位与查询相关的上下文片段。
- 例如,通过构建一个文档的图表示,将句子作为节点,句子之间的关系作为边,通过图遍历技术检索与问题最相关的句子。
- 上下文压缩(Context Compression)
- 通过压缩技术优化上下文记忆的利用,减少输入序列长度。例如,xRAG方法通过将上下文文档编码为文档嵌入,实现软提示压缩。
- 采用硬提示压缩技术,如Lee等人提出的方法,直接将长输入片段压缩为更短的自然语言片段。例如,通过训练一个生成模型,将长文本压缩为简洁的摘要,以便在推理时快速使用。
参数记忆修改(Parametric Memory Modification)
修改参数记忆对于动态适应存储的知识至关重要。
主要关注:编辑(Editing)、遗忘(Unlearning)和持续学习(Continual Learning)三种方法。
编辑(Editing)
- 定位 - 编辑(Locating - then - Editing)
- 例如,ROME方法通过在单个MLP层的权重上执行秩一更新,实现知识编辑。
- 例如:MEMIT方法,通过优化一个松弛的最小二乘目标,实现高效的批量编辑。
- 例如,通过计算模型权重与目标权重之间的差异,找到需要修改的权重部分,并进行更新。
- 元学习(Meta Learning)
- 通过一个编辑器网络,预测目标权重的变化,实现快速和稳健的修正。
- 例如,MEND方法通过将梯度分解为秩一外积形式,实现更高效的编辑。
- 例如:KE方法,通过一个超网络学习如何修改梯度,实现对模型权重的动态调整。
- 提示(Prompt)
- 例如,IKE方法通过上下文学习(ICL),在不修改模型权重的情况下实现知识编辑。
- 例如:MeLLo方法通过将问题分解为多个子问题,并为每个子问题设计专门的提示,引导模型生成正确的答案。
- 附加参数(Additional Parameters)
- 例如,Larimar方法通过引入一个解耦的潜在记忆模块,在测试时条件化LLM解码器,而无需参数更新。
- 例如:MEMORYLLM方法,通过在冻结的LLM中引入一个固定大小的记忆池,逐步更新新知识。
遗忘(Unlearning)
- 定位 - 遗忘(Locating - then - Unlearning)
- 例如,WAGLE方法通过双层优化计算权重归因分数,指导选择性微调。
- 例如:ULD方法,通过计算目标和助手LLM之间的对数差异,推导出遗忘的LLM。
- 训练目标(Training Objective)
- 例如,FLAT方法通过最小化原始模型和目标模型预测之间的Kullback-Leibler(KL)散度,实现遗忘。
- 例如:SOUL方法,通过引入正则化项,约束模型在遗忘过程中保持其他知识的稳定性。通过在损失函数中加入一个惩罚项,防止模型在遗忘特定知识时影响其他知识的表示。
- 提示(Prompt)
- 例如,ICUL方法通过上下文学习实现模型的遗忘。
- ECO方法,通过破坏提示嵌入,实现遗忘。例如,通过设计一个特殊的提示,使模型在处理该提示时忘记特定的知识。
- 附加参数(Additional Parameters)
- 通过添加组件(如对数差异模块或遗忘层),在不重新训练整个模型的情况下调整记忆。例如,EUL方法通过引入遗忘层,实现序列遗忘。
- ULD方法,通过计算目标和助手LLM之间的对数差异,推导出遗忘的LLM。例如,通过设计一个独立的遗忘模块,存储与遗忘相关的参数,并在推理时将其与主模型结合。
持续学习(Continual Learning)
- 基于正则化的学习(Regularization - based Learning)
- 通过约束重要权重的更新,保护关键的参数记忆。例如,TaSL方法通过参数级任务技能定位和巩固,实现知识转移。
- 如EWC方法,通过在损失函数中加入一个惩罚项,限制对重要权重的更新。例如,通过计算权重的重要性分数,并在训练过程中对这些权重施加更大的惩罚,防止其被更新。
多源记忆(Multi-source Memory)
多源记忆涉及整合来自不同来源(包括文本、图像、视频等多模态数据)的记忆信息,以支持更复杂的推理和决策。
跨文本整合(Cross-textual Integration)
- 推理(Reasoning)
- 整合来自不同格式和来源的记忆,生成一致且准确的响应。例如,通过结合结构化符号记忆(如知识图谱)和非结构化文本记忆,生成更丰富的回答。
- 采用动态集成技术,如ChatDB系统,通过检索和融合来自不同领域的参数化记忆,支持更灵活的推理。
- 冲突(Conflict)
- 识别和解决来自异构记忆表示(如内部知识和外部知识)之间的事实或语义不一致性。
- 采用冲突检测和定位技术,如RKC-LLM框架,评估模型检测和定位上下文矛盾的能力。
多模态协调(Multi-modal Coordination)
- 融合(Fusion)
- 对齐和整合来自不同模态(如文本、图像、音频和视频)的信息。
- 采用统一语义投影技术,如UniTransSeR模型,将异构输入嵌入到共享表示空间中,支持跨模态检索和推理。
- 检索(Retrieval)
- 在多模态系统中,通过嵌入空间的相似性计算,访问跨模态的存储知识。
- 采用基于嵌入的检索技术,如QwenVL模型,通过将图像和文本映射到共享语义空间,支持跨模态检索。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 2512
2512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









