






「本文实现了基于微调TrOCR模型进行手写文本识别。」
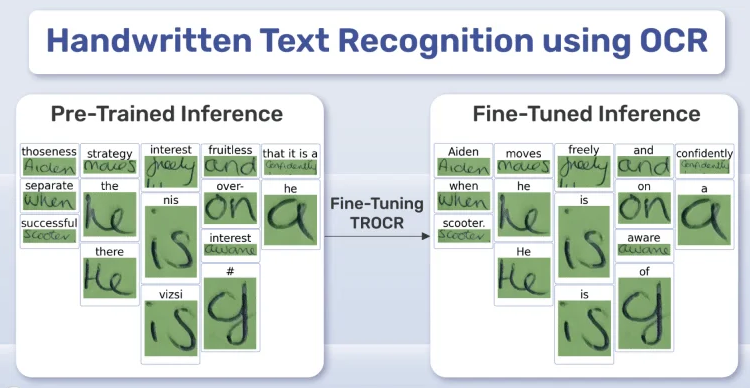
GNHK手写笔记数据集
GNHK(GoodNotes Handwriting Kollection)手写笔记数据集由GoodNotes提供,包含来自世界各地学生的数百份英文手写笔记。
下载数据集
访问GNHK数据集官方网站:
(https://www.goodnotes.com/gnhk),滚动到底部,同意使用条款和条件;点击第二个链接下载数据集。

下载后会得到两个文件:train_data.zip 和 test_data.zip。解压这两个文件后,数据集的目录结构如下:
├── test_data │ └── test │ ├── eng_AF_004.jpg │ ├── eng_AF_004.json │ ├── eng_AF_007.jpg │ ├── eng_AF_007.json │ ... │ ├── eng_NA_142.jpg │ └── eng_NA_142.json ├── train_data └── train ├── eng_AF_001.jpg ├── eng_AF_001.json ├── eng_AF_002.jpg ├── eng_AF_002.json ... ├── eng_NA_146.jpg └── eng_NA_146.json 4 directories, 1375 files
-
训练集:包含515个样本
-
测试集:包含172个样本
-
图像文件:从1080p到4K的高分辨率图像
-
标注文件:每个图像文件对应一个JSON文件,包含图像中每个单词的标注信息
以下是数据集中的一些手写笔记图像样本。

每个图像文件对应一个JSON文件,文件内容格式如下:
[ { "text": "%math%", "polygon": { "x0": 112, "y0": 556, "x1": 285, "y1": 563, "x2": 245, "y2": 776, "x3": 112, "y3": 783 }, "line_idx": 1, "type": "H" }, { "text": "%math%", "polygon": { "x0": 2365, "y0": 202, "x1": 2350, "y1": 509, "x2": 2588, "y2": 527, "x3": 2632, "y3": 195 }, "line_idx": 0, "type": "H" }, ... { "text": "ownership", "polygon": { "x0": 1347, "y0": 1606, "x1": 2238, "y1": 1574, "x2": 2170, "y2": 1884, "x3": 1300, "y3": 1747 }, "line_idx": 4, "type": "H" } ]
其中,
-
text:表示单词的内容。如果单词是数学符号、特殊字符或不可理解的内容(例如划线),则用%%符号包裹的特殊词表示。否则,text键包含实际的单词。
-
polygon:表示单词的多边形坐标,用于精确标注单词的位置。
-
line_idx:表示单词所在的行索引。
-
type:表示单词的类型,通常为"H"(手写)。
项目目录结构
├── input │ └── gnhk_dataset │ ├── test_data │ ├── test_processed │ ├── train_data │ ├── train_processed │ ├── test_processed.csv │ └── train_processed.csv ├── pretrained_model_inference [10066 entries exceeds filelimit, not opening dir] ├── trocr_handwritten │ ├── checkpoint-6093 │ │ ├── config.json │ │ ├── generation_config.json │ │ ├── model.safetensors │ │ ├── optimizer.pt │ │ ├── preprocessor_config.json │ │ ├── rng_state.pth │ │ ├── scheduler.pt │ │ ├── trainer_state.json │ │ └── training_args.bin │ ├── checkpoint-6770 │ │ ├── config.json │ │ ├── generation_config.json │ │ ├── model.safetensors │ │ ├── optimizer.pt │ │ ├── preprocessor_config.json │ │ ├── rng_state.pth │ │ ├── scheduler.pt │ │ ├── trainer_state.json │ │ └── training_args.bin │ └── runs │ └── Aug27_11-30-05_f57a2dab37c7 ├── Fine_Tune_TrOCR_Handwritten.ipynb ├── preprocess_gnhk_dataset.py └── Pretrained_Model_Inference.ipynb
「目录说明」
-
input/gnhk_dataset:包含下载并解压的数据集
-
pretrained_model_inference:包含使用预训练的TrOCR手写模型对验证数据集进行推理的结果。
-
trocr_handwritten:包含微调TrOCR模型后的结果。
-
Fine_Tune_TrOCR_Handwritten.ipynb:用于微调TrOCR模型的Jupyter Notebook
-
preprocess_gnhk_dataset.py:包含预处理GNHK数据集的Python脚本
-
Pretrained_Model_Inference.ipynb:用于使用预训练模型进行推理的Jupyter Notebook
安装依赖项
在继续进行数据预处理、推理和训练之前,我们需要安装以下依赖项。
pip install transformers pip install sentencepiece pip install jiwer pip install datasets pip install evaluate pip install -U accelerate pip install matplotlib pip install protobuf==3.20.1 pip install tensorboard
GNHK数据集预处理
预训练的TrOCR模型只能识别单个单词或单行句子,而GNHK数据集中的图像是整个文档的图像。因此需要对数据集进行预处理,以便模型能够更好地处理这些图像。
数据集预处理的关键步骤如下:
-
转换多边形坐标为四点边界框坐标。
-
裁剪每个单词并存储在单独的目录中。
-
创建两个 CSV 文件,一个用于训练集,一个用于测试集。这些文件将包含裁剪后的图像名称和标签文本。
代码实现:
import os import json import csv import cv2 import numpy as np from tqdm import tqdm def create_directories(): """ 创建必要的目录 """ dirs = [ 'input/gnhk_dataset/train_processed/images', 'input/gnhk_dataset/test_processed/images', ] for dir_path in dirs: os.makedirs(dir_path, exist_ok=True) def polygon_to_bbox(polygon): """ 将多边形坐标转换为四点边界框坐标 """ points = np.array([(polygon[f'x{i}'], polygon[f'y{i}']) for i in range(4)], dtype=np.int32) x, y, w, h = cv2.boundingRect(points) return x, y, w, h def process_dataset(input_folder, output_folder, csv_path): """ 处理数据集,裁剪图像并生成 CSV 文件 """ with open(csv_path, 'w', newline='') as csvfile: csv_writer = csv.writer(csvfile) csv_writer.writerow(['image_filename', 'text']) for filename in tqdm(os.listdir(input_folder), desc=f"Processing {os.path.basename(input_folder)}"): if filename.endswith('.json'): json_path = os.path.join(input_folder, filename) img_path = os.path.join(input_folder, filename.replace('.json', '.jpg')) with open(json_path, 'r') as f: data = json.load(f) img = cv2.imread(img_path) for idx, item in enumerate(data): text = item['text'] if text.startswith('%') and text.endswith('%'): text = 'SPECIAL_CHARACTER' x, y, w, h = polygon_to_bbox(item['polygon']) cropped_img = img[y:y+h, x:x+w] output_filename = f"{filename.replace('.json', '')}_{idx}.jpg" output_path = os.path.join(output_folder, output_filename) cv2.imwrite(output_path, cropped_img) csv_writer.writerow([output_filename, text]) def main(): """ 主函数,创建目录并处理数据集 """ create_directories() process_dataset( 'input/gnhk_dataset/train_data/train', 'input/gnhk_dataset/train_processed/images', 'input/gnhk_dataset/train_processed.csv' ) process_dataset( 'input/gnhk_dataset/test_data/test', 'input/gnhk_dataset/test_processed/images', 'input/gnhk_dataset/test_processed.csv' ) if __name__ == '__main__': main()
将上述代码保存为preprocess_gnhk_dataset.py文件。在终端中运行脚本。
python preprocess_gnhk_dataset.py
运行脚本后,将会在 input/gnhk_dataset 目录下创建以下子目录和文件:
- 子目录
-
train_processed/images:存储训练集的裁剪图像。
-
test_processed/images:存储测试集的裁剪图像。
- CSV 文件
-
train_processed.csv:包含训练集的图像文件名和对应的标签文本。
-
test_processed.csv:包含测试集的图像文件名和对应的标签文本。
以下是一些经过处理后的裁剪图像示例:

csv文件示例如下图所示。
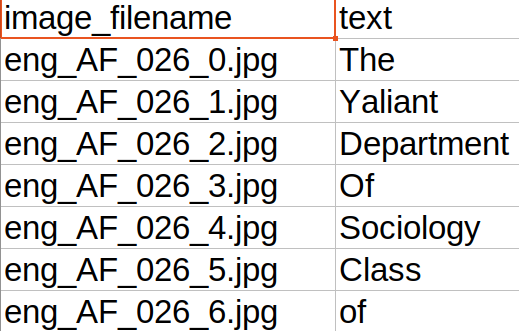
每个csv文件包括裁剪后的图像文件名和对应图像的标签文本。每一行表示一个裁剪后的图像及其对应的标签文本。
处理后的数据集包括:
-
训练集:32495张裁剪图像
-
测试集:10066张裁剪图像
微调TrOCR模型
首先,导入必要的库,并定义一些全局设置。
import os import torch import evaluate import numpy as np import pandas as pd import glob as glob import torch.optim as optim import matplotlib.pyplot as plt import torchvision.transforms as transforms from PIL import Image from tqdm.notebook import tqdm from dataclasses import dataclass from torch.utils.data import Dataset from transformers import ( VisionEncoderDecoderModel, TrOCRProcessor, Seq2SeqTrainer, Seq2SeqTrainingArguments, default_data_collator ) block_plot = False plt.rcParams['figure.figsize'] = (12, 9) os.environ["TOKENIZERS_PARALLELISM"] = 'false'
接着,为确保实验的可重复性,设置随机种子,并初始化计算设备。
def seed_everything(seed_value): np.random.seed(seed_value) torch.manual_seed(seed_value) torch.cuda.manual_seed_all(seed_value) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False seed_everything(42) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
定义一些重要的配置项,包括训练和数据集的路径。这里设置批次大小batch size为48,训练轮数10,基础学习率0.00005。
@dataclass(frozen=True) class TrainingConfig: BATCH_SIZE: int = 48 EPOCHS: int = 10 LEARNING_RATE: float = 0.00005 @dataclass(frozen=True) class DatasetConfig: DATA_ROOT: str = 'input/gnhk_dataset' @dataclass(frozen=True) class ModelConfig: MODEL_NAME: str = 'microsoft/trocr-small-handwritten'
可视化训练样本,以帮助我们验证路径、CSV文件准备和标签是否正确。
def visualize(dataset_path, df): all_images = df.image_filename all_labels = df.text plt.figure(figsize=(15, 3)) for i in range(15): plt.subplot(3, 5, i+1) image = plt.imread(f"{dataset_path}/test_processed/images/{all_images[i]}") label = all_labels[i] plt.imshow(image) plt.axis('off') plt.title(label) plt.show() sample_df = pd.read_csv( os.path.join(DatasetConfig.DATA_ROOT, 'test_processed.csv'), header=None, skiprows=1, names=['image_filename', 'text'], nrows=50 ) visualize(DatasetConfig.DATA_ROOT, sample_df)

GNHK手写文本识别数据集具有自定义的目录结构和CSV文件,我们需要编写自定义的数据集准备代码。
- 读取csv文件
train_df = pd.read_csv( os.path.join(DatasetConfig.DATA_ROOT, 'train_processed.csv'), header=None, skiprows=1, names=['image_filename', 'text'] ) test_df = pd.read_csv( os.path.join(DatasetConfig.DATA_ROOT, 'test_processed.csv'), header=None, skiprows=1, names=['image_filename', 'text'] )
- 为了减少过拟合,应用一些轻微的数据增强,主要包括颜色抖动和高斯模糊。
# 定义数据增强 train_transforms = transforms.Compose([ transforms.ColorJitter(brightness=0.5, hue=0.3), transforms.GaussianBlur(kernel_size=(3, 3), sigma=(0.1, 5)), ])
- 需要创建一个自定义的PyTorch数据集类。
class CustomOCRDataset(Dataset): def __init__(self, root_dir, df, processor, max_target_length=128): self.root_dir = root_dir self.df = df self.processor = processor self.max_target_length = max_target_length # 填充空值 self.df['text'] = self.df['text'].fillna('') def __len__(self): return len(self.df) def __getitem__(self, idx): # 图像文件名 file_name = self.df['image_filename'][idx] # 文本(标签) text = self.df['text'][idx] # 读取图像,应用数据增强,并获取转换后的像素值 image = Image.open(os.path.join(self.root_dir, file_name)).convert('RGB') image = train_transforms(image) pixel_values = self.processor(image, return_tensors='pt').pixel_values # 通过分词器对文本进行分词,并获取标签 labels = self.processor.tokenizer( text, padding='max_length', max_length=self.max_target_length ).input_ids # 使用 -100 作为填充标记 labels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels] encoding = { "pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels) } return encoding
- 初始化TrOCR处理器,并准备训练和验证数据集。
# 初始化处理器 processor = TrOCRProcessor.from_pretrained(ModelConfig['MODEL_NAME']) # 准备训练数据集 train_dataset = CustomOCRDataset( root_dir=os.path.join(DatasetConfig['DATA_ROOT'], 'train_processed/images/'), df=train_df, processor=processor ) # 准备验证数据集 valid_dataset = CustomOCRDataset( root_dir=os.path.join(DatasetConfig['DATA_ROOT'], 'test_processed/images/'), df=test_df, processor=processor )
初始化和配置模型,并统计模型的参数数量。
- 加载模型
# 初始化模型 model = VisionEncoderDecoderModel.from_pretrained(ModelConfig['MODEL_NAME']) model.to(device) print(model) # 统计总参数和可训练参数 total_params = sum(p.numel() for p in model.parameters()) print(f"{total_params:,} total parameters.") total_trainable_params = sum( p.numel() for p in model.parameters() if p.requires_grad ) print(f"{total_trainable_params:,} training parameters.")
- 手动设置一些配置。
# 设置特殊 token 用于从标签创建 decoder_input_ids model.config.decoder_start_token_id = processor.tokenizer.cls_token_id model.config.pad_token_id = processor.tokenizer.pad_token_id # 设置正确的词汇表大小 model.config.vocab_size = model.config.decoder.vocab_size model.config.eos_token_id = processor.tokenizer.sep_token_id # 设置最大输出长度 model.config.max_length = 64 # 启用提前停止 model.config.early_stopping = True # 设置不重复 n-gram 的大小 model.config.no_repeat_ngram_size = 3 # 设置长度惩罚 model.config.length_penalty = 2.0 # 设置 beam search 的束宽 model.config.num_beams = 4 # 打印模型配置 print(model.config)
- 定义AdamW优化器,并配置学习率和权重衰减。
# 定义 AdamW 优化器 optimizer = optim.AdamW( model.parameters(), lr=TrainingConfig['LEARNING_RATE'], weight_decay=0.0005 )
使用字符错误率CER对模型进行评估。
cer_metric = evaluate.load('cer') def compute_cer(pred): # 提取标签的 ID labels_ids = pred.label_ids # 提取预测的 ID pred_ids = pred.predictions # 将预测的 ID 解码为字符串,跳过特殊 token pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True) # 将标签中的 -100 转换为 pad_token_id,以避免影响评估结果 labels_ids[labels_ids == -100] = processor.tokenizer. # 将标签的 ID 解码为字符串,跳过特殊 token label_str = processor.batch_decode(labels_ids, skip_special_tokens=True) # 使用 cer_metric 计算 CER cer = cer_metric.compute(predictions=pred_str, references=label_str) return {"cer": cer}
训练和验证模型。在开始训练之前,需要初始化训练参数和 Trainer API。
- 定义 Seq2SeqTrainingArguments 对象,设置训练和验证的相关参数。
# 初始化训练参数 training_args = Seq2SeqTrainingArguments( predict_with_generate=True, evaluation_strategy='epoch', per_device_train_batch_size=TrainingConfig['BATCH_SIZE'], per_device_eval_batch_size=TrainingConfig['BATCH_SIZE'], fp16=True, output_dir='trocr_handwritten/', logging_strategy='epoch', save_strategy='epoch', save_total_limit=2, report_to='tensorboard', num_train_epochs=TrainingConfig['EPOCHS'], dataloader_num_workers=8 )
- 使用 Seq2SeqTrainer API 初始化训练器。Seq2SeqTrainer 接受模型、处理器、训练参数、数据集和数据收集器作为参数。
# 初始化训练器 trainer = Seq2SeqTrainer( model=model, tokenizer=processor.feature_extractor, args=training_args, compute_metrics=compute_cer, train_dataset=train_dataset, eval_dataset=valid_dataset, data_collator=default_data_collator )
- 开始微调模型。
# 开始训练 trainer.train()
以下是训练10个epoch后的日志示例:
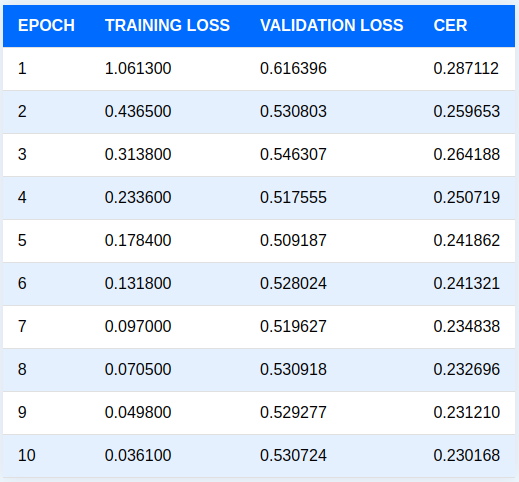
在训练完成后,我们得到了最佳的验证 CER 值。接下来,我们将使用最后一个epoch的检查点对验证集进行推理。
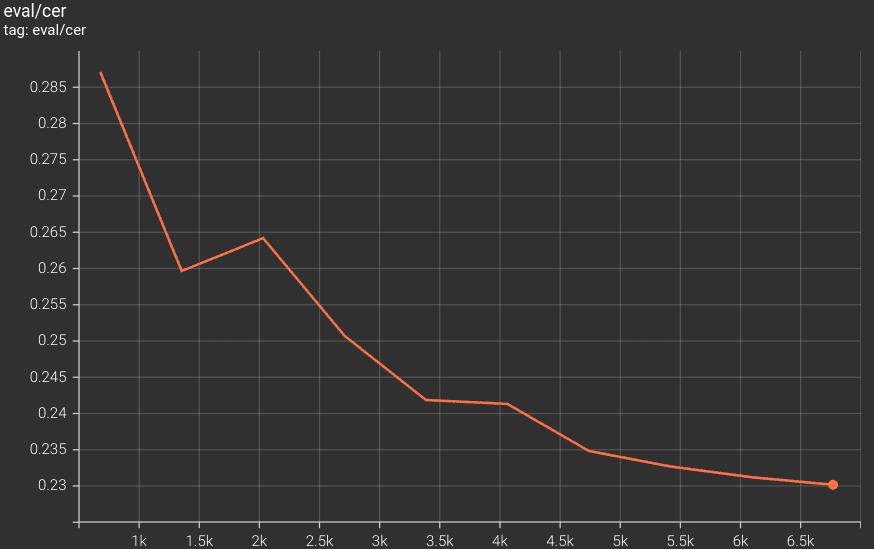
如图所示,验证CER图表在整个训练过程中持续下降,直到最后一个 epoch。这表明模型仍在学习,并且可能通过适当的学习率调度进一步训练几个 epoch 以获得更好的性能。
使用训练好的TrOCR模型推理
接下来,将使用训练好的trOCR模型对一组图像进行推理。
- 加载处理器和训练好的模型检查点。
# 定义模型和处理器 processor = TrOCRProcessor.from_pretrained(ModelConfig.MODEL_NAME) trained_model = VisionEncoderDecoderModel.from_pretrained('trocr_handwritten/checkpoint-'+str(res.global_step)).to(device)
2.定义一些辅助函数,用于读取图像、通过模型进行前向传播以及绘制结果。
def read_and_show(image_path): """ :param image_path: String, path to the input image. Returns: image: PIL Image. """ image = Image.open(image_path).convert('RGB') return image def ocr(image, processor, model): """ :param image: PIL Image. :param processor: Huggingface OCR processor. :param model: Huggingface OCR model. Returns: generated_text: the OCR'd text string. """ pixel_values = processor(image, return_tensors='pt').pixel_values.to(device) generated_ids = model.generate(pixel_values) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0] return generated_text def eval_new_data(data_path=None, num_samples=50, df=None): all_images = df.image_filename all_labels = df.text plt.figure(figsize=(15, 3)) for i in range(num_samples): plt.subplot(3, 5, i+1) image = read_and_show(os.path.join(data_path, all_images[i])) text = ocr(image, processor, trained_model) plt.imshow(image) plt.title(text) plt.axis('off') plt.show()
- 运行推理并可视化结果.
# 运行推理并可视化结果 eval_new_data( data_path=data_path, num_samples=num_samples, df=sample_df )
推理结果如下图所示。

由此可以看出,模型成功地正确预测了所有单词。这表明经过微调后,模型在验证集上的表现非常出色。
附录(完整代码)
链接:https://pan.baidu.com/s/1R5-JB7zKTeb1pJ0kS2Tmnw 提取码:d388
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 4075
4075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









