






本文是深度学习入门: 基于Python的实现、神经网络与深度学习(NNDL)以及动手学深度学习的读书笔记。本文将介绍基于Numpy的卷积神经网络(Convolutional Networks,CNN)的实现,本文主要重在理解原理和底层实现。
一、概述
1.1 卷积神经网络(CNN)
卷积神经网络(CNN)是一种具有局部连接、权重共享和平移不变特性的深层前馈神经网络。
CNN利用了可学习的kernel卷积核(filter滤波器)来提取图像中的模式(局部和全局)。传统图像处理会手动设计卷积核(例如高斯核,来提取边缘信息),而CNN则是数据驱动的。
在数学上,针对一维序列数据,卷积运算可以被理解为一种移动平均(利用历史信号对当前时刻信息进行平滑等处理,换句话说就是考虑当前时刻信息和以前时刻信息的按一定比例延迟的叠加)。而二维卷积运算,通常在图像处理中用于平滑信号达到滤波(例如高斯平滑,削峰填谷)或提取特征等。
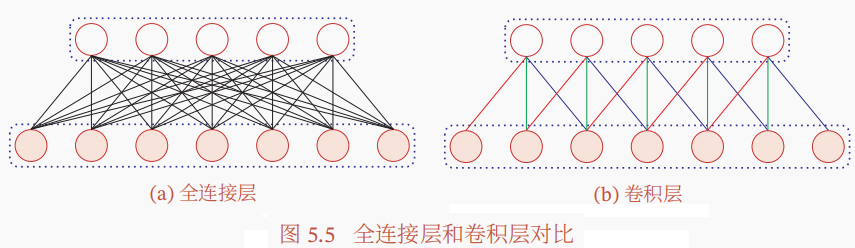
CNN解决了MLP在处理图像时面临的两个问题:(1) 参数过多,(2) 缺乏局部不变性:自然图像中的物体都具有局部不变性特征,比如尺度缩放、平移、旋转等操作不影响其语义信息.而MLP很难提取这些局部不变性特征。换句话说,MLP会忽视图像的形状(像素之间的空间信息),将图像展开为一维的输入数据来处理,所以无法利用与形状相关的信息,而CNN则不会改变形状(引入了归纳偏置)。
目前的CNN一般是由卷积层、汇聚层和全连接层堆叠而成。其中卷积和汇聚层可以视为用滑动窗口来提取特征。CNN的滑动窗口带来的优势:1)局部(稀疏)连接,2)参数共享(复用),3)平移不变。接下将介绍CNN的卷积和池化操作。
1.2 卷积层
1.2.1 卷积运算
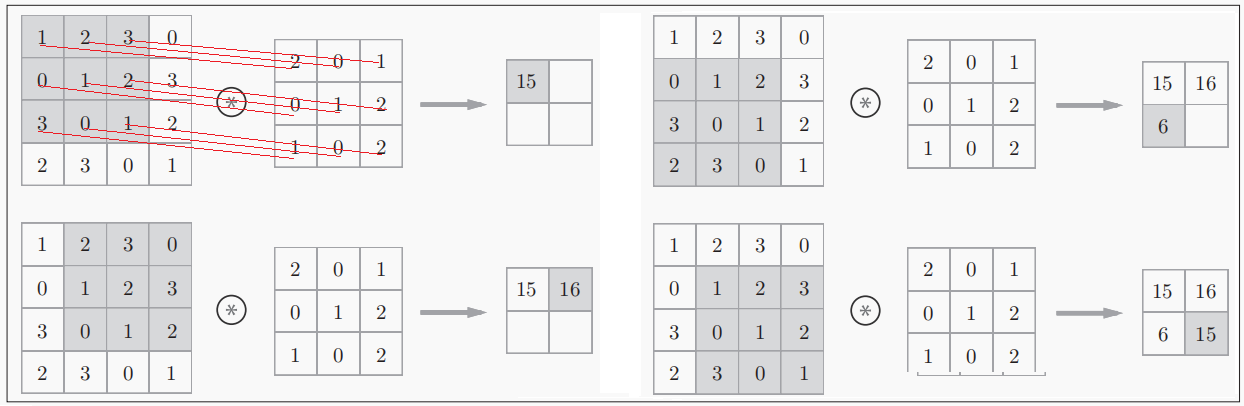
令输入数据(图片)的形状为(H, W),其中H为图片的高height, W为图片的宽width,卷积核(滤波器Filter)的形状为(FH, FW),其中FH代表Filter Height,FW代表Filter Width。
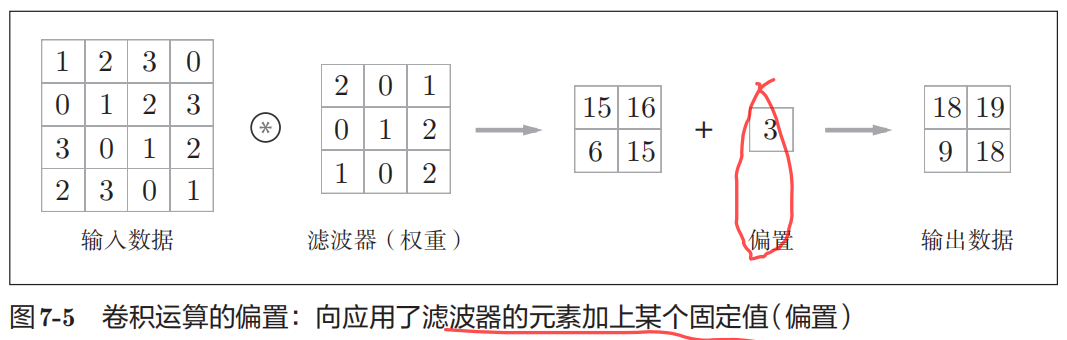
卷积运算将在输入数据上,以一定间隔(Stride步长或步幅)整体地滑动滤波器的窗口并将滤波器各个位置上的权重值和输入数据的对应元素相乘。 然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都做一遍,就能得到卷积运算的输出。此外,在卷积后,通常会在每个位置的数据上加偏置项。
1.2.2 填充和步幅
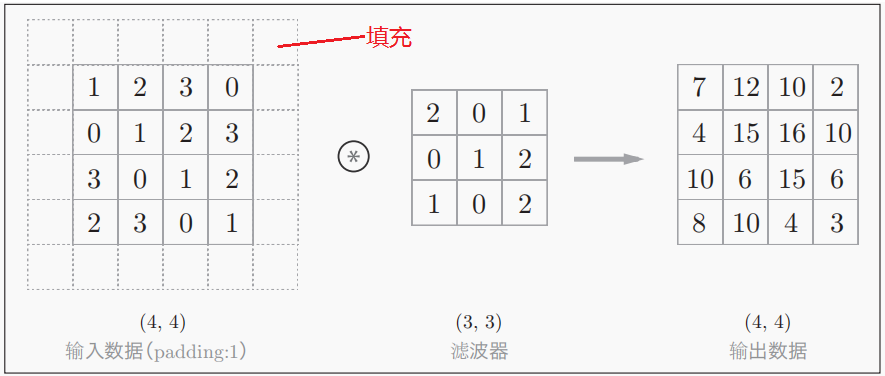
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(例如0等)以确保输出数据(特征图,Feature Map)的大小,这称为填充(padding),是卷积运算中经常会用到的处理。填充也被应用于反卷积中(进行较大范围的填充,使输出数据的形状变大,完成上采样)。
“幅度为1的填充”是指用幅度为1像素的0填充周围。很容易得知,形状为的(H, W)输入数据在进行幅度P的填充后,其形状将变为(H+2P, W+2P)。
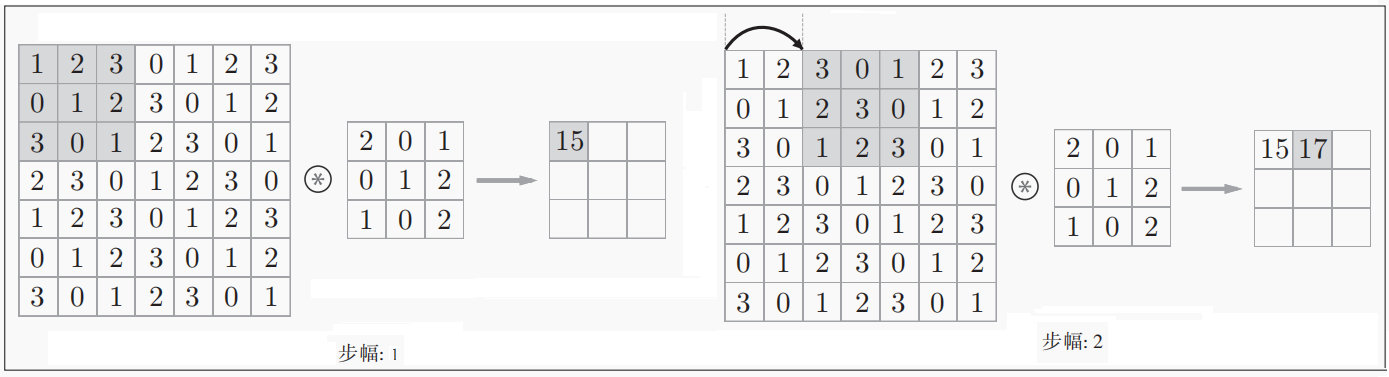
应用滤波器的位置间隔称为步幅(stride)。如上图所示,之前的例子中步幅S都是1,如果将步幅S设为2,应用滤波器的窗口的间隔变为2个元素。综上,增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。对于填充和步幅,输出大小的关系如下式所示:

1.2.3 通道
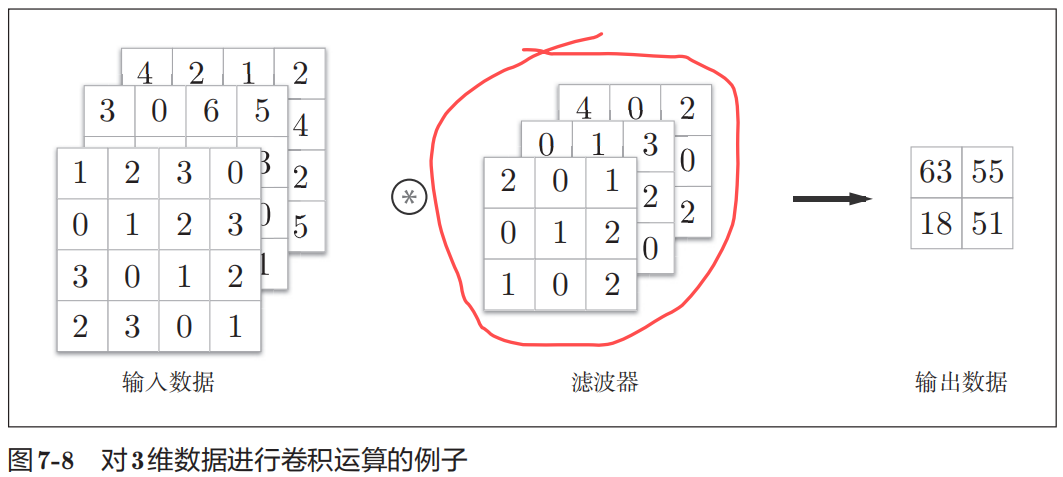
之前的卷积运算的例子都是以有高、长方向的2维形状为对象的。但是,图像是3维数据,除了高、长方向之外,还需要处理通道方向(例如,RGB)。上图以3通道的数据为例,展示了卷积运算的结果。和处理2维数据时相比,可以发现纵深方向(通道方向)上特征图增加了。通道方向上有多个特征图时,可以按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。不同通道的Kernel大小应该一致。
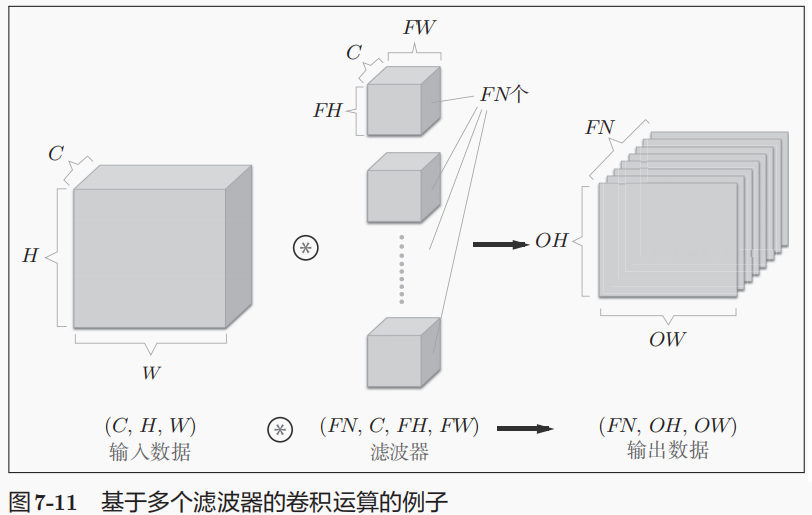
**为了便于理解3维数据的卷积运算,我们这里将数据和滤波器结合长方体的方块来考虑。**方块是上图所示的3维长方体。把3维数据表示为多维数组时,书写顺序为(channel, height, width)。比如,通道数为C、高度为H、长度为W的数据的形状可以写成(C, H, W)。滤波器也一样,要对应顺序书写。比如,通道数为C、滤波器高度为FH、长度为FW时,可以写成(C, FH, FW)。若使用FN个滤波器,输出特征图也将有FN个。如果将这FN个特征图汇集在一起,就得到了形状为(FN, OH, OW)的方块。
卷积运算中(和全连接层一样)存在偏置。如果进一步追加偏置的加法运算处理,要对滤波器的输出结果(FN, OH, OW)按通道加上相同的偏置值。
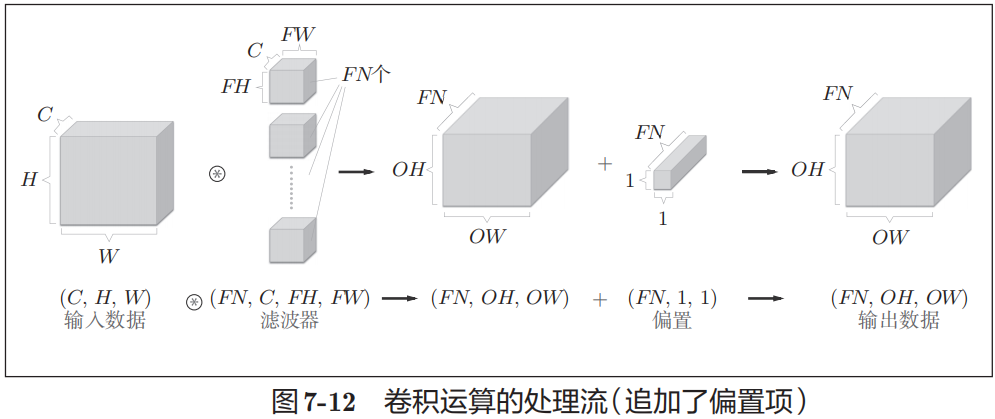
当前只是一个输入(单个3通道图像),还可以输入N个图像,构成一个Batch,以矩阵乘法加速。
1.3 池化层
池化层(汇聚层,Pooling Layer)也叫子采样层(Subsampling Layer),**其作用是进行特征选择,降低特征数量,从而减少参数数量。**具体来说,**池化是缩小高、长方向上的空间的运算(多变少)。**在卷积层之后加上一个汇聚层,可以降低特征维数,避免过拟合。
池化层的特性:
1)没有要学习的参数
池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数
2) 通道数不发生变化
经过池化运算,输入数据和输出数据的通道数不会发生变化
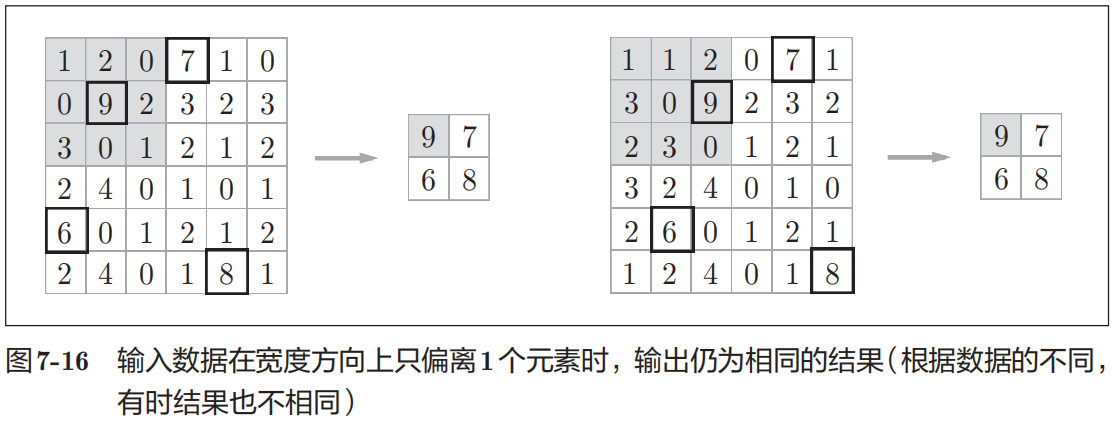
3) 对微小的位置变化具有鲁棒性(健壮,容噪)
当输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性
目前,卷积网络的整体结构趋向于使用更小的卷积核(比如 1 × 1 和 3 × 3)以及更深的结构(比如层数大于 50).此外,由于卷积的操作性越来越灵活(比如不同的步长),汇聚层的作用也变得越来越小,因此目前比较流行的卷积网络中,汇聚层的比例正在逐渐降低,趋向于全卷积网络。
二、CNN实现
卷积层和池化层的实现看起来很复杂,但实际上可通过使用技巧来简化实现。本节将介绍先im2col技巧,然后再进行卷积层的实现。
2.1 Im2col技巧
如前所述,CNN中各层间传递的数据是4维数据。所谓4维数据,比如数据的形状是(10, 1, 28, 28),则它对应10个高为28、长为28、通道为1的数据。对于这样的4维数据此卷积运算的实现看上去会很复杂,但是通过使用下面要介绍的im2col(Image to column)技巧,问题将变得很简单。
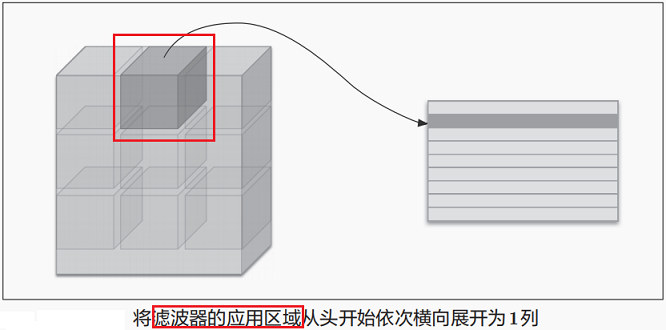
如果老老实实地实现卷积运算需要多重循环,这样做不仅实现复杂且速度较慢。为避免这一问题,我们引入了im2col函数。im2col是一个将输入数据展开以适合滤波器(权重)的函数****。如上图所示,对3维的输入数据应用im2col后,im2col会把输入数据展开以适合滤波器(权重)。具体地说,对于输入数据,将应用滤波器的区域(3维方块)横向展开为1列(转置后为一行)。im2col会在所有应用滤波器的地方进行展开处理。
上图为便于观察,将步幅设置得很大,以使滤波器的应用区域不重叠。而在实际的卷积运算中,滤波器的应用区域几乎都是重叠的。在滤波器的应用区域重叠的情况下,使用im2col展开后,展开后的元素个数会多于原方块的。因此,使用im2col比普通实现消耗更多内存。但是,汇总成一个大矩阵可减少计算耗时。
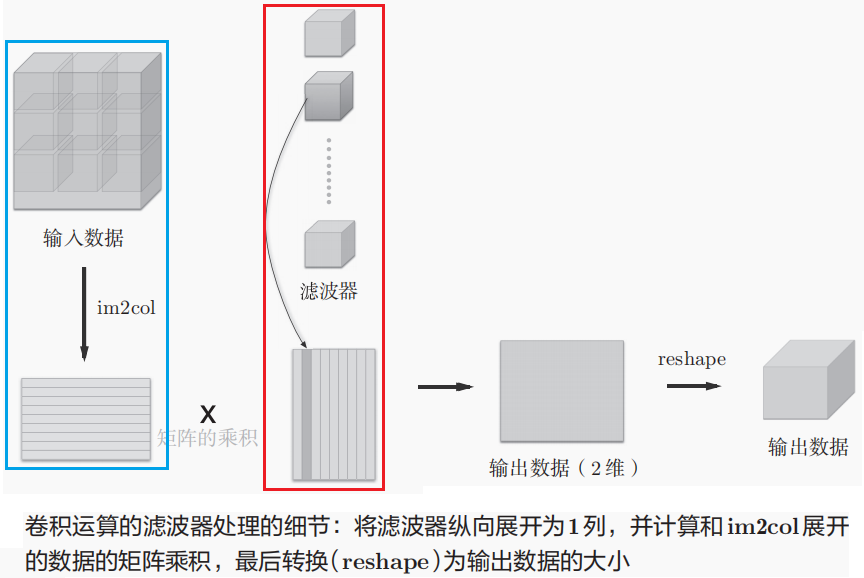
实际上,im2col函数就是将输入数据中所有滤波器需要处理的局部数据(即滑动窗口对应的数据)事先拿出来,展开为矩阵形式(每一行对应一个数据),然后将卷积核也展开为列向量,随后就可将两者做矩阵乘法运算来加速卷积操作(本质上,卷积核和对应数据的卷积运算就是在做内积)。这和全连接层的Affine层进行的处理基本相同(滤波器本质上仍是权重矩阵)。
此外,对于大小相同的一批数据,由于卷积层的滤波器没变,_所以只需将数据按行拼接,计算后再reshape即可。_im2col的实现如下,就是按卷积核来滑动窗口预先取出并展开数据:
1 def im2col(input\_data, filter\_h, filter\_w, stride=1, pad=0):
2 """
3 把对应卷积核的数据部分拿出来,reshape为向量,进一步拼为矩阵
4 Parameters:
5 input\_data (tensor): 由(数据量, 通道, 高, 宽)的4维张量构成的输入数据
6 filter\_h (int): 滤波器的高
7 filter\_w (int): 滤波器的宽
8 stride (int): 步幅
9 pad (int): 填充
10
11 Returns:
12 col (tensor): 2维数组
13 """
14 N, C, H, W = input\_data.shape
15 out\_h = (H + 2\*pad - filter\_h)//stride + 1
16 out\_w = (W + 2\*pad - filter\_w)//stride + 1
17
18 img = np.pad(input\_data, \[(0,0), (0,0), (pad, pad), (pad, pad)\], 'constant')
19 col = np.zeros((N, C, filter\_h, filter\_w, out\_h, out\_w))
20
21 for y in range(filter\_h):
22 y\_max = y + stride\*out\_h
23 for x in range(filter\_w):
24 x\_max = x + stride\*out\_w
25 col\[:, :, y, x, :, :\] = img\[:, :, y:y\_max:stride, x:x\_max:stride\]
26
27 col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N\*out\_h\*out\_w, -1)
28 return col
此外,给出其逆操作,以便实现梯度反向传播:
1 def col2im(col, input\_shape, filter\_h, filter\_w, stride=1, pad=0):
2 """
3 im2col的逆处理,将展开后的数据还原回原始输入数据形式
4 Parameters:
5 col (tensor): 2维数组
6 input\_shape (int): 输入数据的形状(例:(10, 1, 28, 28))
7 filter\_h (int): 滤波器的高
8 filter\_w (int): 滤波器的宽
9 stride (int): 步幅
10 pad (int): 填充
11 Returns:
12 """
13 N, C, H, W = input\_shape
14 out\_h = (H + 2\*pad - filter\_h)//stride + 1
15 out\_w = (W + 2\*pad - filter\_w)//stride + 1
16 col = col.reshape(N, out\_h, out\_w, C, filter\_h, filter\_w).transpose(0, 3, 4, 5, 1, 2)
17 img = np.zeros((N, C, H + 2\*pad + stride - 1, W + 2\*pad + stride - 1))
18
19 for y in range(filter\_h):
20 y\_max = y + stride\*out\_h
21 for x in range(filter\_w):
22 x\_max = x + stride\*out\_w
23 img\[:, :, y:y\_max:stride, x:x\_max:stride\] += col\[:, :, y, x, :, :\]
24 return img\[:, :, pad:H + pad, pad:W + pad\]
2.2 卷积层的实现
卷积层将被实现为名为Convolution的类。卷积层的初始化方法将滤波器(权重)、偏置、步幅、填充作为参数接收。滤波器是 (FN, C, FH, FW)的 4 维形状。另外,FN、C、FH、FW分别是 FilterNumber(滤波器数量)、Channel、Filter Height、Filter Width的缩写。
在forward的实现中,先用im2col展开输入数据,并用reshape将滤波器展开为2维数组。然后,计算展开后的矩阵的乘积。最后会将输出大小转换为合适的形状。通过使用im2col进行展开,基本上可以像实现全连接层的Affine层一样来实现。
接下来是卷积层的反向传播的实现,因为和Affine层的实现有很多共通的地方,所以就不再介绍。但需注意的是,在进行卷积层的反向传播时,必须进行im2col的逆处理(卷积核参数的梯度容易获取,关键是如何获取输入数据关于损失函数的梯度,以便回传)。除了使用col2im这一点,卷积层的反向传播和Affine层的实现方式都一样。
1 class Convolution: 2 def \_\_init\_\_(self, W, b, stride=1, pad=0):
3 # 卷积层的初始化方法将滤波器(权重)、偏置、步幅、填充作为参数
4 # 滤波器是 (FN, C, FH, FW), Filter Number滤波器数量、Channel、Filter Height、Filter Width
5 self.W = W # 每一个Filter(原本为3维tensor权重)将reshape为权重向量 \[(C\*FH\*FW) X 1\], 列向量
6 self.b = b # C一个Filter将拼接为为卷积核权重矩阵 \[(C\*FH\*FW) X FN\]
7 self.stride = stride 8 self.pad = pad 9 # 中间数据(backward时使用)
10 self.x = None
11 self.col = None
12 self.col\_W = None
13 # 权重和偏置参数的梯度
14 self.dW = None
15 self.db = None
16
17 def forward(self, x):
18 FN, C, FH, FW = self.W.shape
19 N, C, H, W = x.shape
20 out\_h = 1 + int((H + 2\*self.pad - FH) / self.stride)
21 out\_w = 1 + int((W + 2\*self.pad - FW) / self.stride)
22 # 用im2col展开输入数据x,并用reshape将滤波器权重展开为2维数组。
23 col = im2col(x, FH, FW, self.stride, self.pad)
24 col\_W = self.W.reshape(FN, -1).T
25 out = np.dot(col, col\_W) + self.b # 计算展开后的矩阵的乘积
26 out = out.reshape(N, out\_h, out\_w, -1).transpose(0, 3, 1, 2) # (N, C, H, W)
27
28 self.x = x
29 self.col = col
30 self.col\_W = col\_W
31 return out
32
33 def backward(self, dout):
34 FN, C, FH, FW = self.W.shape
35 dout = dout.transpose(0,2,3,1).reshape(-1, FN)
36 self.db = np.sum(dout, axis=0)
37 self.dW = np.dot(self.col.T, dout) # 类似于Affine Transformation的参数梯度的计算
38 self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
39
40 dcol = np.dot(dout, self.col\_W.T)
41 dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
42 return dx # 回传的梯度
2.3 池化层的实现
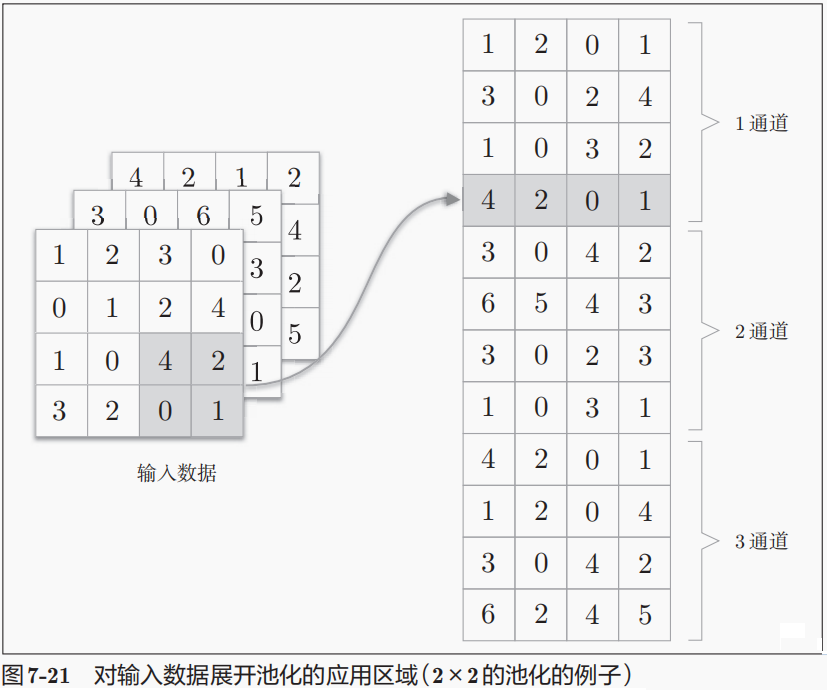

池化层的实现和卷积层相同,都使用im2col展开输入数据。不过,池化的情况下,在通道方向上是独立的。具体地讲,如图上所示,池化的应用区域按通道单独展开。****像这样展开之后,只需对展开的矩阵求各行的最大值,并转换为合适的形状即可(池化无参数)**。**池化操作的反向传播计算过程和Relu非常类似,它仅仅回传池化后的元素的梯度。
1 class Pooling: 2 def \_\_init\_\_(self, pool\_h, pool\_w, stride=1, pad=0):
3 # 池化层的实现和卷积层相同,都使用im2col展开输入数据
4 self.pool\_h = pool\_h 5 self.pool\_w = pool\_w 6 self.stride = stride 7 self.pad = pad 8 self.x = None 9 self.arg\_max = None
10
11 def forward(self, x):
12 N, C, H, W = x.shape
13 out\_h = int(1 + (H - self.pool\_h) / self.stride)
14 out\_w = int(1 + (W - self.pool\_w) / self.stride)
15 col = im2col(x, self.pool\_h, self.pool\_w, self.stride, self.pad)
16 col = col.reshape(-1, self.pool\_h\*self.pool\_w)
17 # X展开之后,只需对展开的矩阵求各行的最大值,并转换为合适的形状
18 arg\_max = np.argmax(col, axis=1)
19 out = np.max(col, axis=1)
20 out = out.reshape(N, out\_h, out\_w, C).transpose(0, 3, 1, 2)
21
22 self.x = x
23 self.arg\_max = arg\_max # 仅对池化后的元素求梯度(相当于一个特殊的Relu,mask掉了其他元素)
24 return out
25
26 def backward(self, dout):
27 dout = dout.transpose(0, 2, 3, 1)
28 pool\_size = self.pool\_h \* self.pool\_w
29 dmax = np.zeros((dout.size, pool\_size)) # 只将dout赋予那些池化后的得到元素的位置,其余元素梯度置为0
30 dmax\[np.arange(self.arg\_max.size), self.arg\_max.flatten()\] = dout.flatten()
31 dmax = dmax.reshape(dout.shape + (pool\_size,))
32
33 dcol = dmax.reshape(dmax.shape\[0\] \* dmax.shape\[1\] \* dmax.shape\[2\], -1)
34 dx = col2im(dcol, self.x.shape, self.pool\_h, self.pool\_w, self.stride, self.pad)
35 return dx # 将column重新组织层图片输入形状,并回传梯度
2.4 CNN的实现
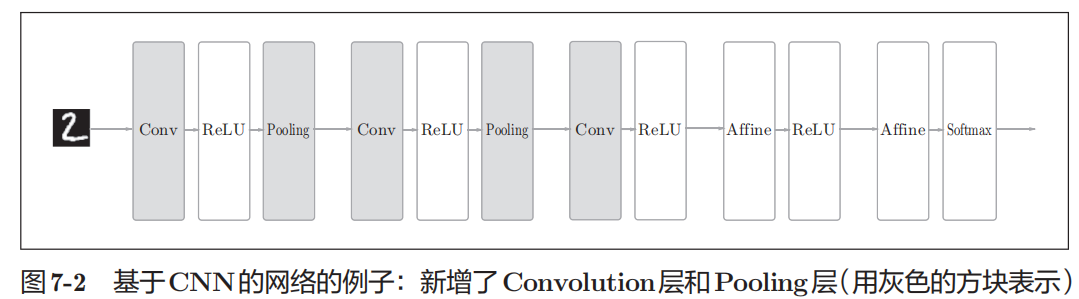
简单CNN分类网络由“Convolution - ReLU - Pooling -Affine -ReLU - Affine - Softmax”的构成,它被实现为SimpleConvNet。可以堆叠多个Convolution、Relu、Pooling等组件实现更复杂的卷积网络。
1 class SimpleConvNet: 2 """简单的ConvNet: conv - relu - pool - affine - relu - affine - softmax
3 Parameters:
4 input\_size : 输入大小(MNIST的情况下为784)
5 hidden\_size\_list : 隐藏层的神经元数量的列表(e.g. \[100, 100, 100\])
6 output\_size : 输出大小(MNIST的情况下为10)
7 activation : 'relu' or 'sigmoid'
8 weight\_init\_std : 指定权重的标准差(e.g. 0.01)
9 指定'relu'或'he'的情况下设定“He的初始值”
10 指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
11 """
12 def \_\_init\_\_(self, input\_dim=(1, 28, 28),
13 conv\_param={'filter\_num': 30, 'filter\_size': 5, 'pad': 0, 'stride': 1},
14 hidden\_size=100, output\_size=10, weight\_init\_std=0.01):
15 filter\_num = conv\_param\['filter\_num'\]
16 filter\_size = conv\_param\['filter\_size'\]
17 filter\_pad = conv\_param\['pad'\]
18 filter\_stride = conv\_param\['stride'\]
19 input\_size = input\_dim\[1\]
20 conv\_output\_size = (input\_size - filter\_size + 2 \* filter\_pad) / filter\_stride + 1
21 pool\_output\_size = int(filter\_num \* (conv\_output\_size / 2) \* (conv\_output\_size / 2))
22
23 # 初始化权重
24 self.params = {} 25 self.params\['W1'\] = weight\_init\_std \* \\ 26 np.random.randn(filter\_num, input\_dim\[0\], filter\_size, filter\_size)
27 self.params\['b1'\] = np.zeros(filter\_num) 28 self.params\['W2'\] = weight\_init\_std \* \\ 29 np.random.randn(pool\_output\_size, hidden\_size)
30 self.params\['b2'\] = np.zeros(hidden\_size) 31 self.params\['W3'\] = weight\_init\_std \* \\ 32 np.random.randn(hidden\_size, output\_size)
33 self.params\['b3'\] = np.zeros(output\_size) 34
35 # 生成层
36 self.layers = OrderedDict() 37 self.layers\['Conv1'\] = Convolution(self.params\['W1'\], self.params\['b1'\],
38 conv\_param\['stride'\], conv\_param\['pad'\])
39 self.layers\['Relu1'\] = Relu() 40 self.layers\['Pool1'\] = Pooling(pool\_h=2, pool\_w=2, stride=2)
41 self.layers\['Affine1'\] = Affine(self.params\['W2'\], self.params\['b2'\])
42 self.layers\['Relu2'\] = Relu() 43 self.layers\['Affine2'\] = Affine(self.params\['W3'\], self.params\['b3'\])
44
45 self.last\_layer = SoftmaxWithLoss() 46
47 def predict(self, x): 48 for layer in self.layers.values(): 49 x = layer.forward(x) 50
51 return x 52
53 def loss(self, x, t): 54 """求损失函数。参数x是输入数据、t是教师标签
55 """
56 y = self.predict(x) 57 return self.last\_layer.forward(y, t) 58
59 def gradient(self, x, t): 60 """求梯度(误差反向传播法)
61
62 Parameters:
63 x : 输入数据
64 t : 教师标签
65
66 Returns:
67 具有各层的梯度的字典变量
68 grads\['W1'\]、grads\['W2'\]、...是各层的权重
69 grads\['b1'\]、grads\['b2'\]、...是各层的偏置
70 """
71 # forward
72 self.loss(x, t)
73
74 # backward
75 dout = 1
76 dout = self.last\_layer.backward(dout) 77
78 layers = list(self.layers.values()) 79 layers.reverse()
80 for layer in layers: 81 dout = layer.backward(dout) 82
83 # 设定
84 grads = {} 85 grads\['W1'\], grads\['b1'\] = self.layers\['Conv1'\].dW, self.layers\['Conv1'\].db
86 grads\['W2'\], grads\['b2'\] = self.layers\['Affine1'\].dW, self.layers\['Affine1'\].db
87 grads\['W3'\], grads\['b3'\] = self.layers\['Affine2'\].dW, self.layers\['Affine2'\].db
88 return grads 89
90 def save\_params(self, file\_name="params.pkl"):
91 params = {} 92 for key, val in self.params.items(): 93 params\[key\] = val 94 with open(file\_name, 'wb') as f:
95 pickle.dump(params, f)
96
97 def load\_params(self, file\_name="params.pkl"):
98 with open(file\_name, 'rb') as f:
99 params = pickle.load(f)
100 for key, val in params.items():
101 self.params\[key\] = val
102
103 for i, key in enumerate(\['Conv1', 'Affine1', 'Affine2'\]):
104 self.layers\[key\].W = self.params\['W' + str(i+1)\]
105 self.layers\[key\].b = self.params\['b' + str(i+1)\]
三、典型的深度CNN
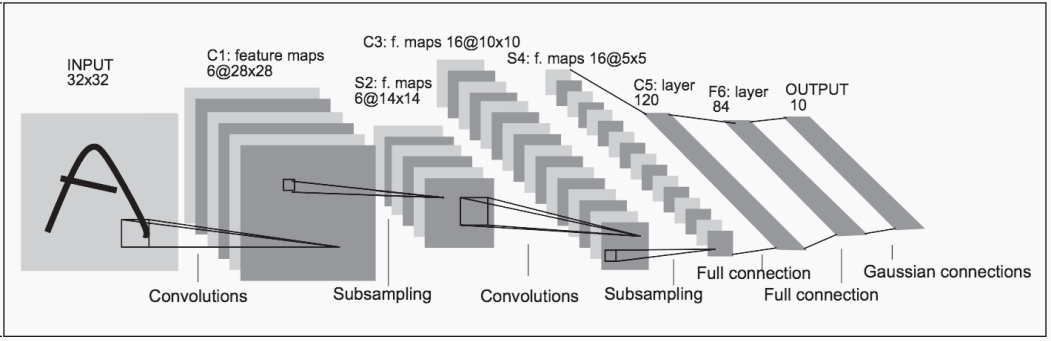
LeNet-5是由Yann LeCun提出的第一个也是非常经典的卷积神经网络模型。LeNet-5的网络结构如上图所示。LeNet-5共有7层,接受输入图像大小为32 × 32 = 1 024,输出对应10个类别的得分。LeNet中使用了sigmoid函数,而现在的CNN中主要使用ReLU函数。
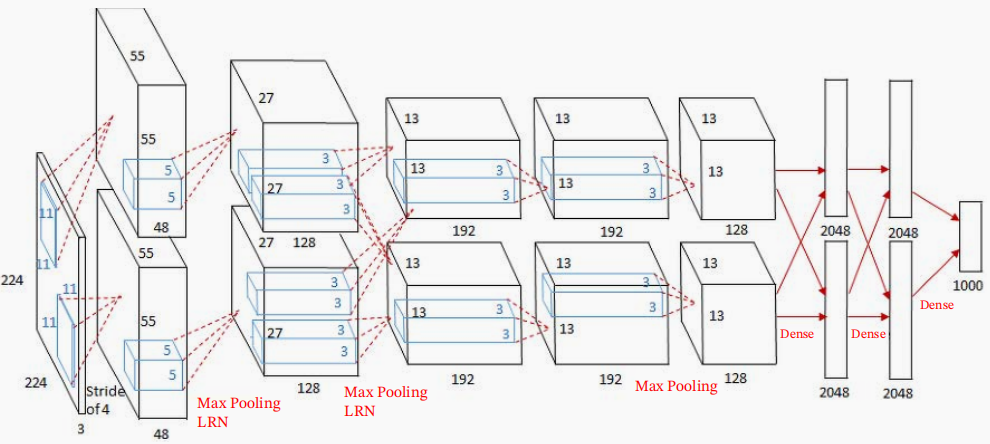
AlexNet堆叠了多个卷积层和池化层,最后经由全连接层输出结果。虽然结构上AlexNet和LeNet没有大的不同,但有以下几点差异。它的激活函数用了ReLU,应用了Dropout,并使用了局部正规化的LRN(Local Response Normalization)层来避免过拟合。
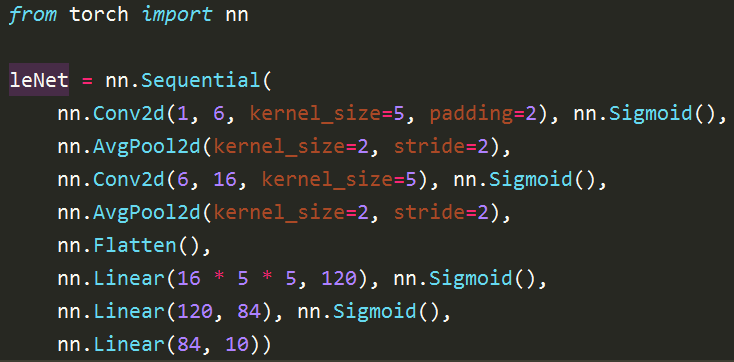
上述两个网络都可以用Numpy来实现,不过为了实现方便和避免重复造低效的轮子,可以直接用Pytorch或Tensorflow等框架来实现或使用现成的网络。例如, LeNet-5可以直接用如下几行pytorch代码实现:
至于更深的卷积神经网络, 就不在详细展开。**它们往往具有如下特点:**
• 引入残差或跳连接
• 激活函数是ReLU
• 基于小型滤波器的卷积层,例如3×3
• 使用He初始值作为权重初始值
• 使用BatchNormalizaiton归一化操作
• 全连接层的后面使用Dropout层
• 基于Adam的最优化
四、MINST训练CNN完整代码
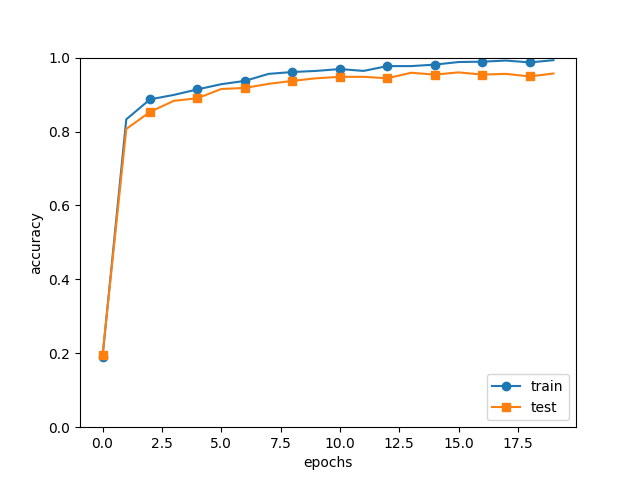
这里加入了数据加载、以及优化器和训练代码以及依赖的层和函数实现。
这里没有使用数据集全集进行训练。
部分训练损失变化
=== epoch:20, train acc:0.993, test acc:0.957 ===
train loss:0.012233594746587742
train loss:0.008365986258816209
train loss:0.02212213864855614
train loss:0.02711406676975275
train loss:0.0418349000312822
train loss:0.057708698769212516
train loss:0.015403229650386896
train loss:0.017599953533757498
train loss:0.015486894589432332
train loss:0.031158008798079506
train loss:0.054530107471154644
train loss:0.009704471774258436
train loss:0.010295140042204599
train loss:0.05049087595095596
train loss:0.010830895810426724
train loss:0.010738003713808189
=============== Final Test Accuracy ===============
test acc:0.955
Saved Network Parameters!
参数以嵌套字典的形式,存为了pickle文件。
# coding: utf-8
import urllib.request
import os.path
import gzip
import pickle
import numpy as np
import sys, os
from collections import OrderedDict
import numpy as np
import matplotlib.pyplot as plt
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
url\_base \= 'http://yann.lecun.com/exdb/mnist/'
key\_file \= {
'train\_img':'train-images-idx3-ubyte.gz',
'train\_label':'train-labels-idx1-ubyte.gz',
'test\_img':'t10k-images-idx3-ubyte.gz',
'test\_label':'t10k-labels-idx1-ubyte.gz'
}
dataset\_dir \= os.path.dirname(os.path.abspath(\_\_file\_\_))
save\_file \= dataset\_dir + "/mnist.pkl"
train\_num \= 60000
test\_num \= 10000
img\_dim \= (1, 28, 28)
img\_size \= 784
def \_download(file\_name):
file\_path \= dataset\_dir + "/" + file\_name
if os.path.exists(file\_path):
return
print("Downloading " + file\_name + " ... ")
urllib.request.urlretrieve(url\_base + file\_name, file\_path)
print("Done")
def download\_mnist():
for v in key\_file.values():
\_download(v)
def \_load\_label(file\_name):
file\_path \= dataset\_dir + "/" + file\_name
print("Converting " + file\_name + " to NumPy Array ...")
with gzip.open(file\_path, 'rb') as f:
labels \= np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def \_load\_img(file\_name):
file\_path \= dataset\_dir + "/" + file\_name
print("Converting " + file\_name + " to NumPy Array ...")
with gzip.open(file\_path, 'rb') as f:
data \= np.frombuffer(f.read(), np.uint8, offset=16)
data \= data.reshape(-1, img\_size)
print("Done")
return data
def \_convert\_numpy():
dataset \= {}
dataset\['train\_img'\] = \_load\_img(key\_file\['train\_img'\])
dataset\['train\_label'\] = \_load\_label(key\_file\['train\_label'\])
dataset\['test\_img'\] = \_load\_img(key\_file\['test\_img'\])
dataset\['test\_label'\] = \_load\_label(key\_file\['test\_label'\])
return dataset
def init\_mnist():
download\_mnist()
dataset \= \_convert\_numpy()
print("Creating pickle file ...")
with open(save\_file, 'wb') as f:
pickle.dump(dataset, f, \-1)
print("Done!")
def \_change\_one\_hot\_label(X):
T \= np.zeros((X.size, 10))
for idx, row in enumerate(T):
row\[X\[idx\]\] \= 1
return T
def load\_mnist(normalize=True, flatten=True, one\_hot\_label=False):
"""读入MNIST数据集
params:
normalize : 将图像的像素值正规化为0.0~1.0
one\_hot\_label :
one\_hot\_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指\[0,0,1,0,0,0,0,0,0,0\]这样的数组
flatten : 是否将图像展开为一维数组
returns::
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save\_file):
init\_mnist()
with open(save\_file, 'rb') as f:
dataset \= pickle.load(f)
if normalize:
for key in ('train\_img', 'test\_img'):
dataset\[key\] \= dataset\[key\].astype(np.float32)
dataset\[key\] /= 255.0
if one\_hot\_label:
dataset\['train\_label'\] = \_change\_one\_hot\_label(dataset\['train\_label'\])
dataset\['test\_label'\] = \_change\_one\_hot\_label(dataset\['test\_label'\])
if not flatten:
for key in ('train\_img', 'test\_img'):
dataset\[key\] \= dataset\[key\].reshape(-1, 1, 28, 28)
return (dataset\['train\_img'\], dataset\['train\_label'\]), (dataset\['test\_img'\], dataset\['test\_label'\])
def softmax(x):
if x.ndim == 2:
x \= x.T
x \= x - np.max(x, axis=0)
y \= np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x \= x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
class Relu:
def \_\_init\_\_(self):
self.mask \= None
def forward(self, x):
self.mask \= (x <= 0)
out \= x.copy()
out\[self.mask\] \= 0
return out
def backward(self, dout):
dout\[self.mask\] \= 0
dx \= dout
return dx
class Sigmoid:
def \_\_init\_\_(self):
self.out \= None
def forward(self, x):
out \= sigmoid(x)
self.out \= out
return out
def backward(self, dout):
dx \= dout \* (1.0 - self.out) \* self.out
return dx
class Affine:
def \_\_init\_\_(self, W, b):
self.W \=W
self.b \= b
self.x \= None
self.original\_x\_shape \= None
# 权重和偏置参数的导数
self.dW = None
self.db \= None
def forward(self, x):
# 对应张量
self.original\_x\_shape = x.shape
x \= x.reshape(x.shape\[0\], -1)
self.x \= x
out \= np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx \= np.dot(dout, self.W.T)
self.dW \= np.dot(self.x.T, dout)
self.db \= np.sum(dout, axis=0)
dx \= dx.reshape(\*self.original\_x\_shape) # 还原输入数据的形状(对应张量)
return dx
class SoftmaxWithLoss:
def \_\_init\_\_(self):
self.loss \= None
self.y \= None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t \= t
self.y \= softmax(x)
self.loss \= cross\_entropy\_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch\_size \= self.t.shape\[0\]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch\_size
else:
dx \= self.y.copy()
dx\[np.arange(batch\_size), self.t\] \-= 1
dx \= dx / batch\_size
return dx
class Dropout:
"""http://arxiv.org/abs/1207.0580"""
def \_\_init\_\_(self, dropout\_ratio=0.5):
self.dropout\_ratio \= dropout\_ratio
self.mask \= None
def forward(self, x, train\_flg=True):
if train\_flg:
self.mask \= np.random.rand(\*x.shape) > self.dropout\_ratio
return x \* self.mask
else:
return x \* (1.0 - self.dropout\_ratio)
def backward(self, dout):
return dout \* self.mask
class BatchNormalization:
"""http://arxiv.org/abs/1502.03167"""
def \_\_init\_\_(self, gamma, beta, momentum=0.9, running\_mean=None, running\_var=None):
self.gamma \= gamma
self.beta \= beta
self.momentum \= momentum
self.input\_shape \= None # Conv层的情况下为4维,全连接层的情况下为2维
# 测试时使用的平均值和方差
self.running\_mean = running\_mean
self.running\_var \= running\_var
# backward时使用的中间数据
self.batch\_size = None
self.xc \= None
self.std \= None
self.dgamma \= None
self.dbeta \= None
def forward(self, x, train\_flg=True):
self.input\_shape \= x.shape
if x.ndim != 2:
N, C, H, W \= x.shape
x \= x.reshape(N, -1)
out \= self.\_\_forward(x, train\_flg)
return out.reshape(\*self.input\_shape)
def \_\_forward(self, x, train\_flg):
if self.running\_mean is None:
N, D \= x.shape
self.running\_mean \= np.zeros(D)
self.running\_var \= np.zeros(D)
if train\_flg:
mu \= x.mean(axis=0)
xc \= x - mu
var \= np.mean(xc\*\*2, axis=0)
std \= np.sqrt(var + 10e-7)
xn \= xc / std
self.batch\_size \= x.shape\[0\]
self.xc \= xc
self.xn \= xn
self.std \= std
self.running\_mean \= self.momentum \* self.running\_mean + (1-self.momentum) \* mu
self.running\_var \= self.momentum \* self.running\_var + (1-self.momentum) \* var
else:
xc \= x - self.running\_mean
xn \= xc / ((np.sqrt(self.running\_var + 10e-7)))
out \= self.gamma \* xn + self.beta
return out
def backward(self, dout):
if dout.ndim != 2:
N, C, H, W \= dout.shape
dout \= dout.reshape(N, -1)
dx \= self.\_\_backward(dout)
dx \= dx.reshape(\*self.input\_shape)
return dx
def \_\_backward(self, dout):
dbeta \= dout.sum(axis=0)
dgamma \= np.sum(self.xn \* dout, axis=0)
dxn \= self.gamma \* dout
dxc \= dxn / self.std
dstd \= -np.sum((dxn \* self.xc) / (self.std \* self.std), axis=0)
dvar \= 0.5 \* dstd / self.std
dxc += (2.0 / self.batch\_size) \* self.xc \* dvar
dmu \= np.sum(dxc, axis=0)
dx \= dxc - dmu / self.batch\_size
self.dgamma \= dgamma
self.dbeta \= dbeta
return dx
def im2col(input\_data, filter\_h, filter\_w, stride=1, pad=0):
N, C, H, W \= input\_data.shape
out\_h \= (H + 2\*pad - filter\_h)//stride + 1
out\_w \= (W + 2\*pad - filter\_w)//stride + 1
img \= np.pad(input\_data, \[(0,0), (0,0), (pad, pad), (pad, pad)\], 'constant')
col \= np.zeros((N, C, filter\_h, filter\_w, out\_h, out\_w))
for y in range(filter\_h):
y\_max \= y + stride\*out\_h
for x in range(filter\_w):
x\_max \= x + stride\*out\_w
col\[:, :, y, x, :, :\] \= img\[:, :, y:y\_max:stride, x:x\_max:stride\]
col \= col.transpose(0, 4, 5, 1, 2, 3).reshape(N\*out\_h\*out\_w, -1)
return col
def col2im(col, input\_shape, filter\_h, filter\_w, stride=1, pad=0):
N, C, H, W \= input\_shape
out\_h \= (H + 2\*pad - filter\_h)//stride + 1
out\_w \= (W + 2\*pad - filter\_w)//stride + 1
col \= col.reshape(N, out\_h, out\_w, C, filter\_h, filter\_w).transpose(0, 3, 4, 5, 1, 2)
img \= np.zeros((N, C, H + 2\*pad + stride - 1, W + 2\*pad + stride - 1))
for y in range(filter\_h):
y\_max \= y + stride\*out\_h
for x in range(filter\_w):
x\_max \= x + stride\*out\_w
img\[:, :, y:y\_max:stride, x:x\_max:stride\] += col\[:, :, y, x, :, :\]
return img\[:, :, pad:H + pad, pad:W + pad\]
class Convolution:
def \_\_init\_\_(self, W, b, stride=1, pad=0):
self.W \= W
self.b \= b
self.stride \= stride
self.pad \= pad
# 中间数据(backward时使用)
self.x = None
self.col \= None
self.col\_W \= None
# 权重和偏置参数的梯度
self.dW = None
self.db \= None
def forward(self, x):
FN, C, FH, FW \= self.W.shape
N, C, H, W \= x.shape
out\_h \= 1 + int((H + 2\*self.pad - FH) / self.stride)
out\_w \= 1 + int((W + 2\*self.pad - FW) / self.stride)
col \= im2col(x, FH, FW, self.stride, self.pad)
col\_W \= self.W.reshape(FN, -1).T
out \= np.dot(col, col\_W) + self.b
out \= out.reshape(N, out\_h, out\_w, -1).transpose(0, 3, 1, 2)
self.x \= x
self.col \= col
self.col\_W \= col\_W
return out
def backward(self, dout):
FN, C, FH, FW \= self.W.shape
dout \= dout.transpose(0,2,3,1).reshape(-1, FN)
self.db \= np.sum(dout, axis=0)
self.dW \= np.dot(self.col.T, dout)
self.dW \= self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol \= np.dot(dout, self.col\_W.T)
dx \= col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
class Pooling:
def \_\_init\_\_(self, pool\_h, pool\_w, stride=1, pad=0):
self.pool\_h \= pool\_h
self.pool\_w \= pool\_w
self.stride \= stride
self.pad \= pad
self.x \= None
self.arg\_max \= None
def forward(self, x):
N, C, H, W \= x.shape
out\_h \= int(1 + (H - self.pool\_h) / self.stride)
out\_w \= int(1 + (W - self.pool\_w) / self.stride)
col \= im2col(x, self.pool\_h, self.pool\_w, self.stride, self.pad)
col \= col.reshape(-1, self.pool\_h\*self.pool\_w)
arg\_max \= np.argmax(col, axis=1)
out \= np.max(col, axis=1)
out \= out.reshape(N, out\_h, out\_w, C).transpose(0, 3, 1, 2)
self.x \= x
self.arg\_max \= arg\_max
return out
def backward(self, dout):
dout \= dout.transpose(0, 2, 3, 1)
pool\_size \= self.pool\_h \* self.pool\_w
dmax \= np.zeros((dout.size, pool\_size))
dmax\[np.arange(self.arg\_max.size), self.arg\_max.flatten()\] \= dout.flatten()
dmax \= dmax.reshape(dout.shape + (pool\_size,))
dcol \= dmax.reshape(dmax.shape\[0\] \* dmax.shape\[1\] \* dmax.shape\[2\], -1)
dx \= col2im(dcol, self.x.shape, self.pool\_h, self.pool\_w, self.stride, self.pad)
return dx
class SimpleConvNet:
"""简单的ConvNet"""
def \_\_init\_\_(self, input\_dim=(1, 28, 28),
conv\_param\={'filter\_num':30, 'filter\_size':5, 'pad':0, 'stride':1},
hidden\_size\=100, output\_size=10, weight\_init\_std=0.01):
filter\_num \= conv\_param\['filter\_num'\]
filter\_size \= conv\_param\['filter\_size'\]
filter\_pad \= conv\_param\['pad'\]
filter\_stride \= conv\_param\['stride'\]
input\_size \= input\_dim\[1\]
conv\_output\_size \= (input\_size - filter\_size + 2\*filter\_pad) / filter\_stride + 1
pool\_output\_size \= int(filter\_num \* (conv\_output\_size/2) \* (conv\_output\_size/2))
# 初始化权重
self.params = {}
self.params\['W1'\] = weight\_init\_std \* \\
np.random.randn(filter\_num, input\_dim\[0\], filter\_size, filter\_size)
self.params\['b1'\] = np.zeros(filter\_num)
self.params\['W2'\] = weight\_init\_std \* \\
np.random.randn(pool\_output\_size, hidden\_size)
self.params\['b2'\] = np.zeros(hidden\_size)
self.params\['W3'\] = weight\_init\_std \* \\
np.random.randn(hidden\_size, output\_size)
self.params\['b3'\] = np.zeros(output\_size)
# 生成层
self.layers = OrderedDict()
self.layers\['Conv1'\] = Convolution(self.params\['W1'\], self.params\['b1'\],
conv\_param\['stride'\], conv\_param\['pad'\])
self.layers\['Relu1'\] = Relu()
self.layers\['Pool1'\] = Pooling(pool\_h=2, pool\_w=2, stride=2)
self.layers\['Affine1'\] = Affine(self.params\['W2'\], self.params\['b2'\])
self.layers\['Relu2'\] = Relu()
self.layers\['Affine2'\] = Affine(self.params\['W3'\], self.params\['b3'\])
self.last\_layer \= SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x \= layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数"""
y \= self.predict(x)
return self.last\_layer.forward(y, t)
def accuracy(self, x, t, batch\_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc \= 0.0
for i in range(int(x.shape\[0\] / batch\_size)):
tx \= x\[i\*batch\_size:(i+1)\*batch\_size\]
tt \= t\[i\*batch\_size:(i+1)\*batch\_size\]
y \= self.predict(tx)
y \= np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape\[0\]
def numerical\_gradient(self, x, t):
"""求梯度(数值微分) """
loss\_w \= lambda w: self.loss(x, t)
grads \= {}
for idx in (1, 2, 3):
grads\['W' + str(idx)\] = numerical\_gradient(loss\_w, self.params\['W' + str(idx)\])
grads\['b' + str(idx)\] = numerical\_gradient(loss\_w, self.params\['b' + str(idx)\])
return grads
def gradient(self, x, t):
"""求梯度(误差反向传播法 """
# forward
self.loss(x, t)
# backward
dout = 1
dout \= self.last\_layer.backward(dout)
layers \= list(self.layers.values())
layers.reverse()
for layer in layers:
dout \= layer.backward(dout)
# 设定
grads = {}
grads\['W1'\], grads\['b1'\] = self.layers\['Conv1'\].dW, self.layers\['Conv1'\].db
grads\['W2'\], grads\['b2'\] = self.layers\['Affine1'\].dW, self.layers\['Affine1'\].db
grads\['W3'\], grads\['b3'\] = self.layers\['Affine2'\].dW, self.layers\['Affine2'\].db
return grads
def save\_params(self, file\_name="params.pkl"):
params \= {}
for key, val in self.params.items():
params\[key\] \= val
with open(file\_name, 'wb') as f:
pickle.dump(params, f)
def load\_params(self, file\_name="params.pkl"):
with open(file\_name, 'rb') as f:
params \= pickle.load(f)
for key, val in params.items():
self.params\[key\] \= val
for i, key in enumerate(\['Conv1', 'Affine1', 'Affine2'\]):
self.layers\[key\].W \= self.params\['W' + str(i+1)\]
self.layers\[key\].b \= self.params\['b' + str(i+1)\]
def cross\_entropy\_error(y, t):
if y.ndim == 1:
t \= t.reshape(1, t.size)
y \= y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t \= t.argmax(axis=1)
batch\_size \= y.shape\[0\]
return -np.sum(np.log(y\[np.arange(batch\_size), t\] + 1e-7)) / batch\_size
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def \_\_init\_\_(self, lr=0.01):
self.lr \= lr
def update(self, params, grads):
for key in params.keys():
params\[key\] \-= self.lr \* grads\[key\]
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def \_\_init\_\_(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr \= lr
self.beta1 \= beta1
self.beta2 \= beta2
self.iter \= 0
self.m \= None
self.v \= None
def update(self, params, grads):
if self.m is None:
self.m, self.v \= {}, {}
for key, val in params.items():
self.m\[key\] \= np.zeros\_like(val)
self.v\[key\] \= np.zeros\_like(val)
self.iter += 1
lr\_t \= self.lr \* np.sqrt(1.0 - self.beta2\*\*self.iter) / (1.0 - self.beta1\*\*self.iter)
for key in params.keys():
self.m\[key\] += (1 - self.beta1) \* (grads\[key\] - self.m\[key\])
self.v\[key\] += (1 - self.beta2) \* (grads\[key\]\*\*2 - self.v\[key\])
params\[key\] \-= lr\_t \* self.m\[key\] / (np.sqrt(self.v\[key\]) + 1e-7)
class Trainer:
"""进行神经网络的训练的类
"""
def \_\_init\_\_(self, network, x\_train, t\_train, x\_test, t\_test,
epochs\=20, mini\_batch\_size=100,
optimizer\='SGD', optimizer\_param={'lr':0.01},
evaluate\_sample\_num\_per\_epoch\=None, verbose=True):
self.network \= network
self.verbose \= verbose
self.x\_train \= x\_train
self.t\_train \= t\_train
self.x\_test \= x\_test
self.t\_test \= t\_test
self.epochs \= epochs
self.batch\_size \= mini\_batch\_size
self.evaluate\_sample\_num\_per\_epoch \= evaluate\_sample\_num\_per\_epoch
# optimzer
optimizer\_class\_dict = {'sgd':SGD, 'adam':Adam}
self.optimizer \= optimizer\_class\_dict\[optimizer.lower()\](\*\*optimizer\_param)
self.train\_size \= x\_train.shape\[0\]
self.iter\_per\_epoch \= max(self.train\_size / mini\_batch\_size, 1)
self.max\_iter \= int(epochs \* self.iter\_per\_epoch)
self.current\_iter \= 0
self.current\_epoch \= 0
self.train\_loss\_list \= \[\]
self.train\_acc\_list \= \[\]
self.test\_acc\_list \= \[\]
def train\_step(self):
batch\_mask \= np.random.choice(self.train\_size, self.batch\_size)
x\_batch \= self.x\_train\[batch\_mask\]
t\_batch \= self.t\_train\[batch\_mask\]
grads \= self.network.gradient(x\_batch, t\_batch)
self.optimizer.update(self.network.params, grads)
loss \= self.network.loss(x\_batch, t\_batch)
self.train\_loss\_list.append(loss)
if self.verbose: print("train loss:" + str(loss))
if self.current\_iter % self.iter\_per\_epoch == 0:
self.current\_epoch += 1
x\_train\_sample, t\_train\_sample \= self.x\_train, self.t\_train
x\_test\_sample, t\_test\_sample \= self.x\_test, self.t\_test
if not self.evaluate\_sample\_num\_per\_epoch is None:
t \= self.evaluate\_sample\_num\_per\_epoch
x\_train\_sample, t\_train\_sample \= self.x\_train\[:t\], self.t\_train\[:t\]
x\_test\_sample, t\_test\_sample \= self.x\_test\[:t\], self.t\_test\[:t\]
train\_acc \= self.network.accuracy(x\_train\_sample, t\_train\_sample)
test\_acc \= self.network.accuracy(x\_test\_sample, t\_test\_sample)
self.train\_acc\_list.append(train\_acc)
self.test\_acc\_list.append(test\_acc)
if self.verbose: print("\=== epoch:" + str(self.current\_epoch) + ", train acc:" + str(train\_acc) + ", test acc:" + str(test\_acc) + " ===")
self.current\_iter += 1
def train(self):
for i in range(self.max\_iter):
self.train\_step()
test\_acc \= self.network.accuracy(self.x\_test, self.t\_test)
if self.verbose:
print("\=============== Final Test Accuracy ===============")
print("test acc:" + str(test\_acc))
# 读入数据
(x\_train, t\_train), (x\_test, t\_test) = load\_mnist(flatten=False)
# 处理花费时间较长的情况下减少数据
x\_train, t\_train = x\_train\[:5000\], t\_train\[:5000\]
x\_test, t\_test \= x\_test\[:1000\], t\_test\[:1000\]
max\_epochs \= 20
network \= SimpleConvNet(input\_dim=(1,28,28),
conv\_param \= {'filter\_num': 30, 'filter\_size': 5, 'pad': 0, 'stride': 1},
hidden\_size\=100, output\_size=10, weight\_init\_std=0.01)
trainer \= Trainer(network, x\_train, t\_train, x\_test, t\_test,
epochs\=max\_epochs, mini\_batch\_size=100,
optimizer\='Adam', optimizer\_param={'lr': 0.001},
evaluate\_sample\_num\_per\_epoch\=1000)
trainer.train()
# 保存参数
network.save\_params("params.pkl")
print("Saved Network Parameters!")
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x \= np.arange(max\_epochs)
plt.plot(x, trainer.train\_acc\_list, marker\='o', label='train', markevery=2)
plt.plot(x, trainer.test\_acc\_list, marker\='s', label='test', markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc\='lower right')
plt.show()
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 2575
2575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









