






一夜之间,CV被大模型“解决”了(狗头)。
万物皆可吉卜力之后,GPT-4o原生多模态图像生成更多玩法被开发出来。
一个男友回头表情包,可以秒变语义分割图。
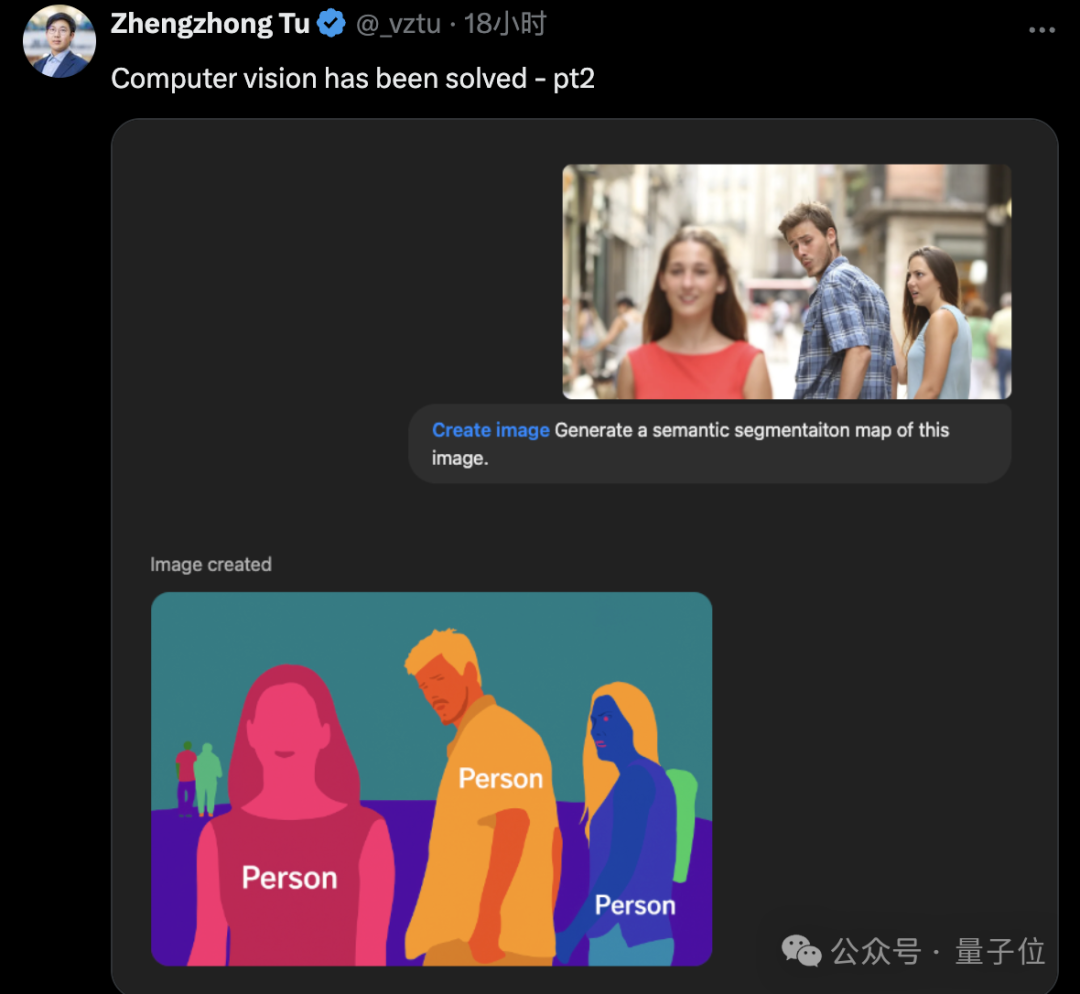
也可以秒变深度图。
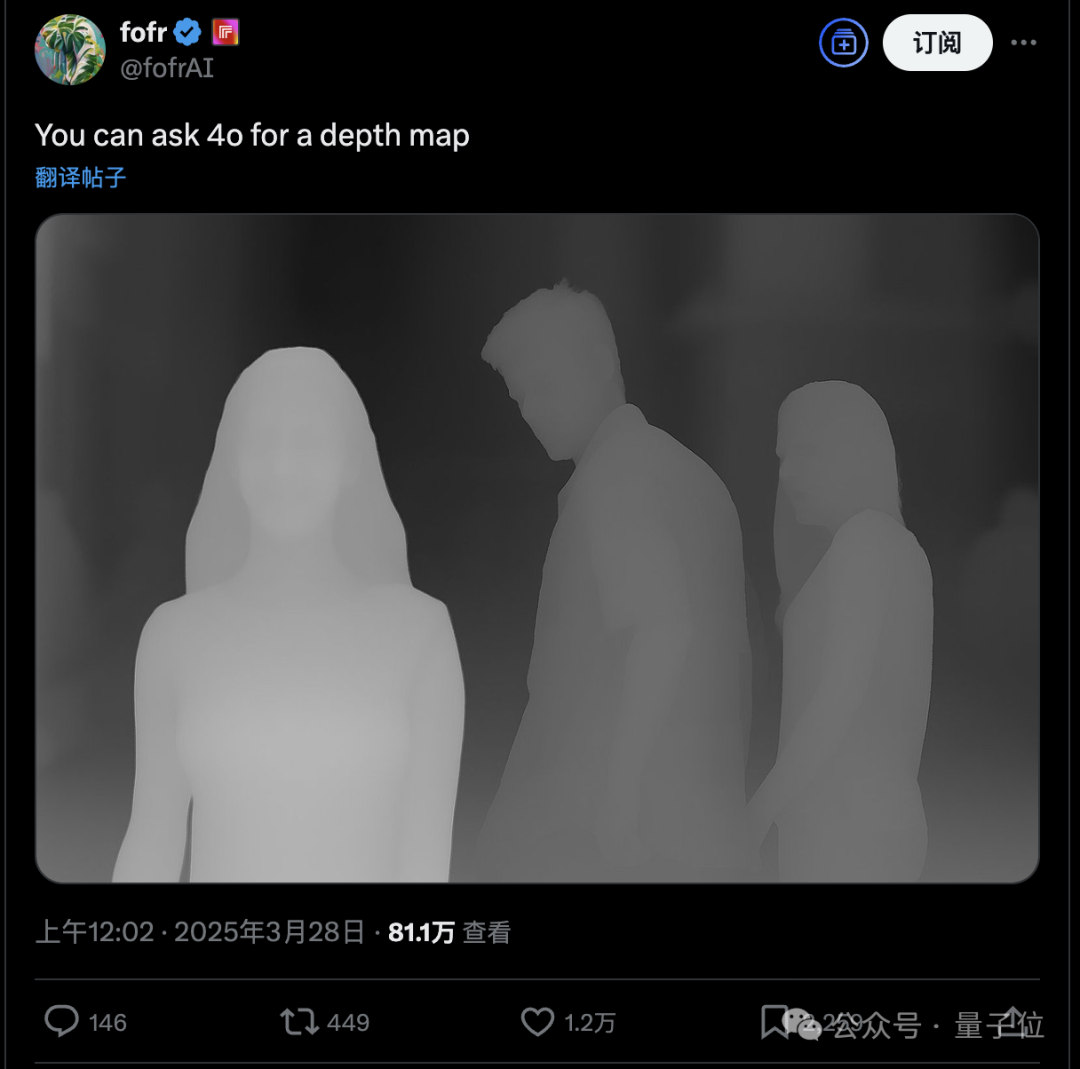
这下不光上一代AI画图工具和设计师,计算机视觉研究员也哭晕在厕所了。

这是NASA前工程师测试特斯拉自动驾驶系统的伪装“隐形墙”,在GPT-4o面前也无所遁形。

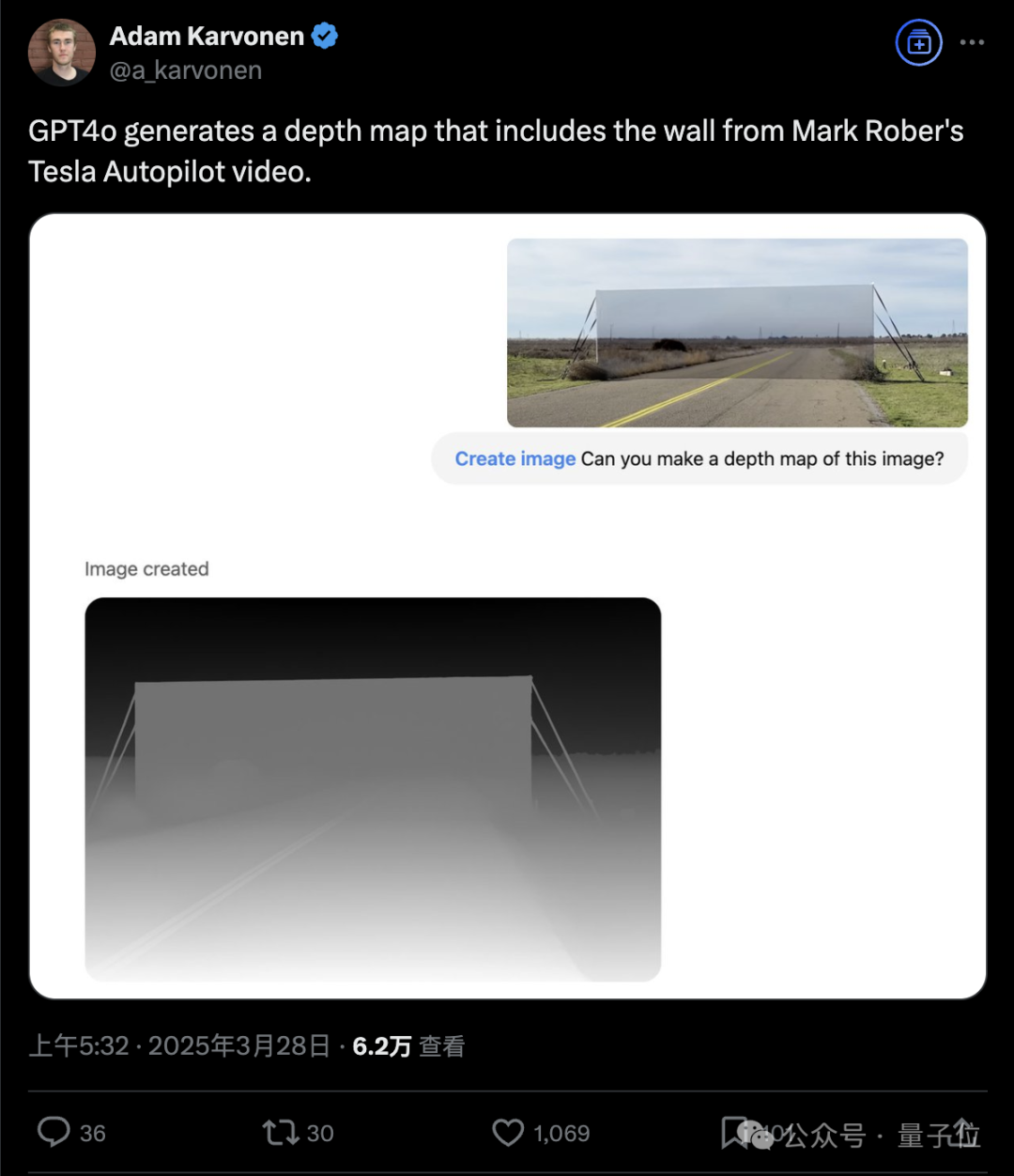
这下OpenAI应用研究主管Boris Power已经把脑筋动到了自动驾驶,称只需要训练最强大的基础模型,然后微调。

3D渲染领域也惨遭毒手,GPT-4o可以生成PBR材质(基于物理渲染的材质),纹理、法线贴图等直接来一套。
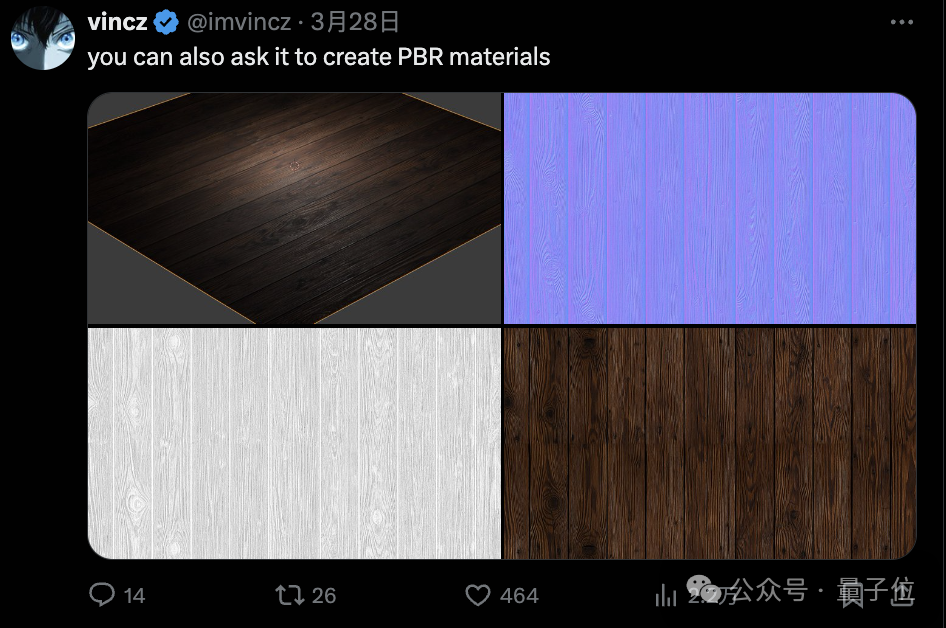
对于这些能力,也有人认为没什么大不了的,Stable Diffusion + ControlNet就可以全部实现。
但不可否认,靠扩大基础模型规模就能做到,也是令人意想不到的。
然而,OpenAI 一向并不 Open,这次也不例外。他们只是发布一份 GPT-4o 系统卡附录(增补文件),其中也主要是论述了评估、安全和治理方面的内容。

image.png
地址:https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
对于技术,在这份长达 13 页的附录文件中,也仅在最开始时提到了一句:「不同于基于扩散模型的 DALL・E,4o 图像生成是一个嵌入在 ChatGPT 中的自回归模型。」
OpenAI 对技术保密,也抵挡不住大家对 GPT-4o 工作方式的热情,现在网络上已经出现了各种猜测、逆向工程。
比如谷歌 DeepMind 研究者 Jon Barron 根据 4o 出图的过程猜测其可能是组合使用了某种多尺度技术与自回归。
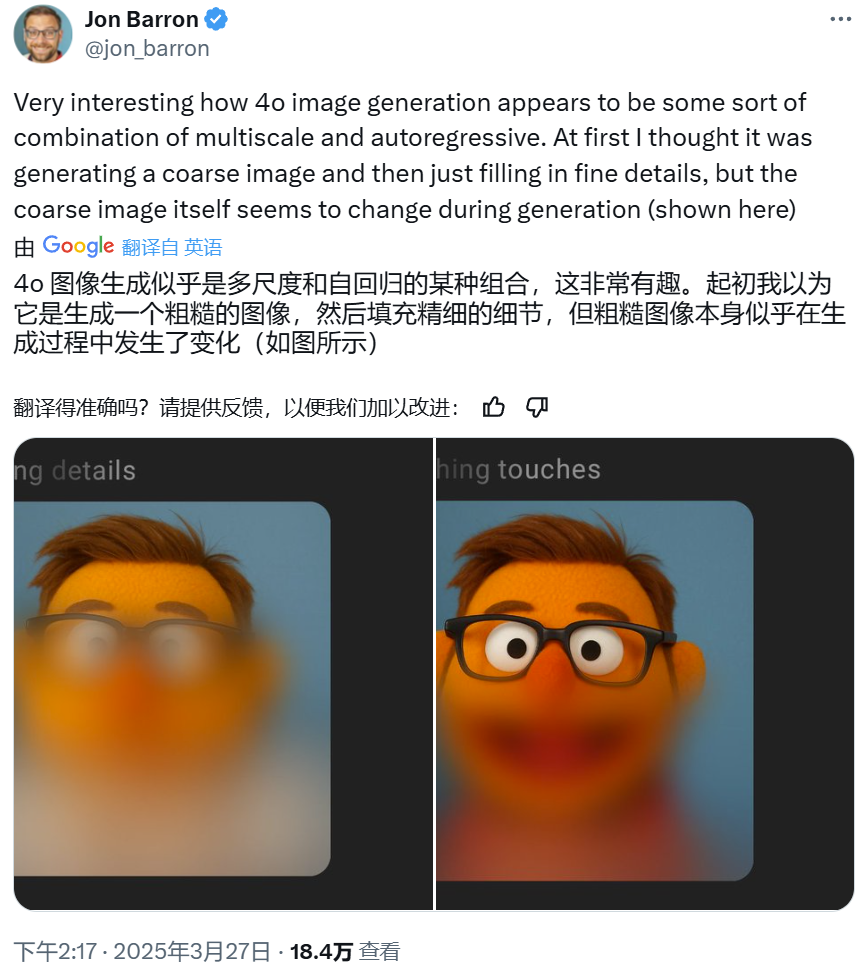
image.png
不过,值得一提的是,香港中文大学博士生刘杰(Jie Liu)在研究 GPT-4o 的前端时发现,用户在生成图像时看到的逐行生成图像的效果其实只是浏览器上的前端动画效果,并不能准确真实地反映其图像生成的具体过程。实际上,在每次生成过程中,OpenAI 的服务器只会向用户端发送 5 张中间图像。您甚至可以在控制台手动调整模糊函数的高度来改变生成图像的模糊范围!

image.png
因此,在推断 GPT-4o 的工作原理时,其生成时的前端展示效果可能并不是一个好依据。
尽管如此,还是让我们来看看各路研究者都做出了怎样的猜测。整体来说,对 GPT-4o 原生图像生成能力的推断主要集中在两个方向:自回归 + 扩散生成、非扩散的自回归生成。下面我们详细盘点一下相关猜想,并会简单介绍网友们猜想关联的一些相关论文。
猜想一:自回归 + 扩散
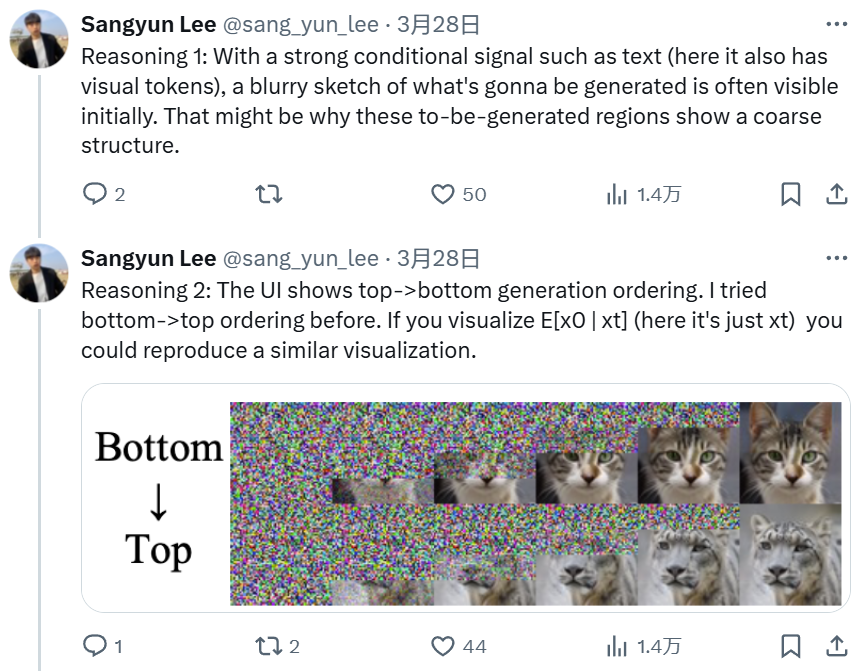
很多网友猜想 GPT-4o 的图像生成采用了「自回归 + 扩散」的范式。比如 CMU 博士生 Sangyun Lee 在该功能发布后不久就发推猜想 GPT-4o 会先生成视觉 token,再由扩散模型将其解码到像素空间。而且他认为,GPT-4o 使用的扩散方法是类似于 Rolling Diffusion 的分组扩散解码器,会以从上到下的顺序进行解码。

image.png
他进一步给出了自己得出如此猜想的依据。
sp_250329_104009.png
-
理由 1:如果有一个强大的条件信号(如文本,也可能有视觉 token),用户通常会先看到将要生成的内容的模糊草图。因此,那些待生成区域会显示粗糙的结构。
-
理由 2:其 UI 表明,图像是从顶部到底部生成的。Sangyun Lee 曾在自己的研究中尝试过底部到顶部的顺序。
Sangyun Lee 猜想到,这样的分组模式下,高 NFE(函数评估数量)区域的 FID 会更好一些。但在他研究发现这一点时,他只是认为这是个 bug,而非特性。但现在情况不一样了,人们都在研究测试时计算。
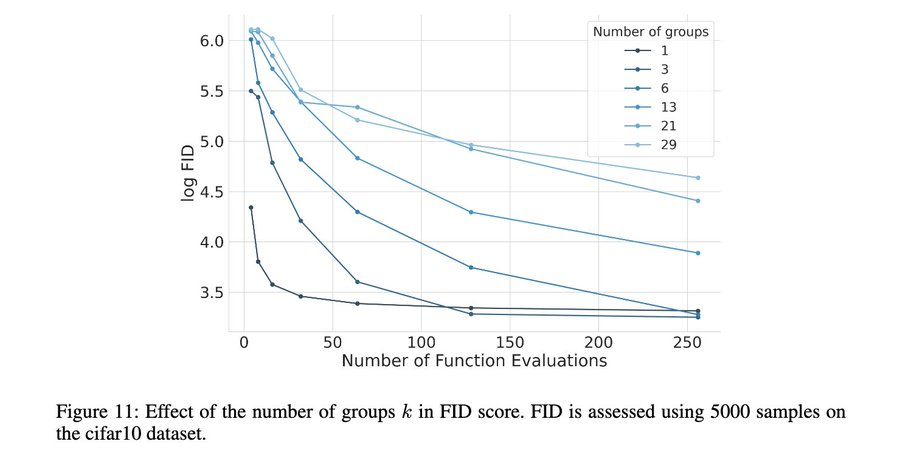
image.png
最后,他得出结论说:「因此,这是一种介于扩散和自回归模型之间的模型。事实上,通过设置 num_groups=num_pixels,你甚至可以恢复自回归!」
另外也有其他一些研究者给出了类似的判断:

image.png
如果你对这一猜想感兴趣,可以参看以下论文:
-
Rolling Diffusion Models,arXiv:2402.09470;
-
Sequential Data Generation with Groupwise Diffusion Process, arXiv:2310.01400
-
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model,arXiv:2408.11039
猜想二:非扩散的自回归生成
使用过 GPT-4o 的都知道,其在生成图像的过程中总是先出现上半部分,然后才生成完整的图像。
Moonpig 公司 AI 主管 Peter Gostev 认为,GPT-4o 是采用从图像的顶部流 token 开始生成图像的,就像文本生成方式一样。

image.png
来源:https://www.linkedin.com/feed/update/urn:li:activity:7311176227078172674/
Gostev 表示,与传统的图像生成模型相比,GPT-4o 图像生成的关键区别在于它是一个自回归模型。这意味着它会像生成文本一样,按顺序逐个流式传输图像 token。相比之下,基于扩散过程的模型(例如 Midjourney、DALL-E、Stable Diffusion)通常是从噪声到清晰图像一次性完成转换。

image.png
这种自回归模型的主要优势在于,模型不需要一次性生成整个全局图像。相反,它可以通过以下方式来生成图像:
-
利用其模型权重中嵌入的通用知识;
-
通过按顺序流式传输 token 来更连贯地生成图像。
更进一步的,Gostev 认为,如果你使用 ChatGPT 并点击检查(Inspect),然后在浏览器中导航到网络(Network)标签,就可以监控浏览器与服务器之间的流量。这让你能够查看 ChatGPT 在图像生成过程中发送的中间图像,从而获得一些有价值的线索。
Gostev 给出了一些初步的观察结果(可能并不完整):
-
图像是从上到下生成的;
-
这个过程确实涉及流 token,与扩散方法截然不同;
-
从一开始,就可以看到图像的大致轮廓;
-
先前生成的像素在生成过程中可能会发生显著变化;
-
这可能表明模型采用了某种连贯性优化,尤其是在接近完成阶段时更加明显。
最后,Gostev 表示还有一些无法直接从图像中看到的额外观察结果:
-
对于简单的图像生成,GPT-4o 速度要快得多,通常只有一个中间图像,而不是多个。这可能暗示使用了推测解码或其他类似方法;
-
图像生成还具备背景移除功能,从目前的情况来说,最初 GPT-4o 生成图片会呈现一个假的棋盘格背景,直到最后才移除实际背景,这会略微降低图像质量。这似乎是一个额外的处理过程,而不是 GPT-4o 本身的功能。
开发者 @KeyTryer 也给出了自己的猜想。他说 4o 是一种自回归模型,通过多次通过来逐像素地生成图像,而不是像扩散模型那样执行去噪步骤。
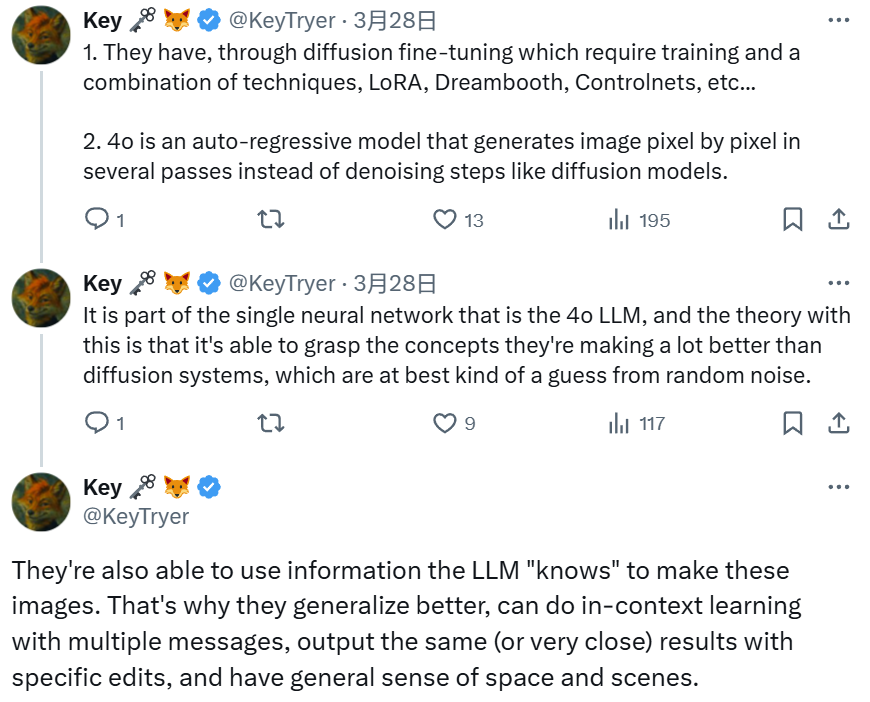
image.png
而这种能力本身就是 GPT-4o LLM 神经网络的一部分。理论上讲,它能够比扩散系统更好地掌握它们正在操作的概念,而扩散系统只是对随机噪声的一种猜测。
GPT-4o 还能够使用 LLM「知道」的信息来生成图像。也因此,它们具有更好的泛化能力,能够使用多条消息进行上下文学习,通过特定的编辑输出相同(或非常接近)的结果,并且具有广义的空间和场景感。
芬兰赫尔辛基的大学副教授 Luigi Acerbi 也指出,GPT-4o 基本就只是使用 Transformer 来预测下一个 token,并且其原生图像生成能力一开始就有,只是一直以来都没有公开发布。
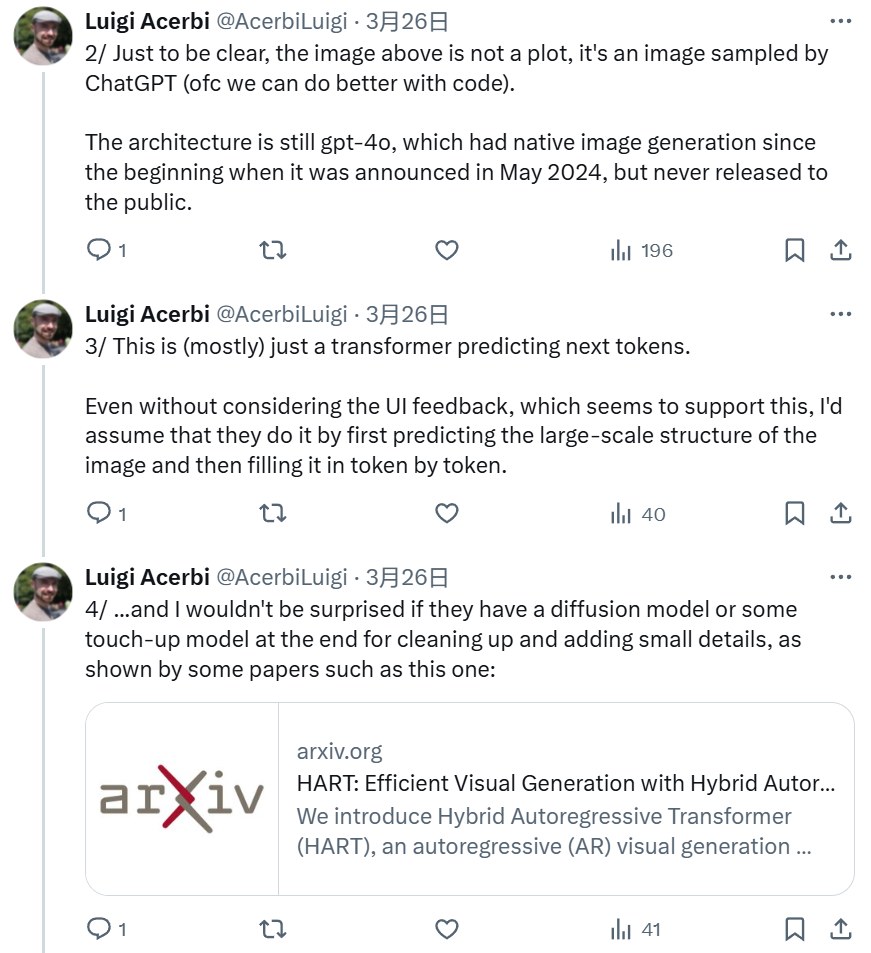
image.png
不过,Acerbi 教授也提到,OpenAI 可能使用了扩散模型或或一些修饰模型来为 GPT-4o 生成的图像执行一些清理或添加小细节。
GPT-4o 原生图像生成功能究竟是如何实现的?这一点终究还得等待 OpenAI 自己来揭秘。对此,你有什么自己的猜想呢?

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









