






1 前言
过去很长一段时间,我对“Prompt Engineering”的长期价值持保留态度。一个在特定模型上表现出色的 Prompt,在其他模型上可能效果平平。
然而,随着一些特定范式和创新性 Prompt 的出现,LLMs的边界能力被压榨探索出来。这些实践经验不仅仅是提升当前的交互效果,它们反过来促进了训练数据集的优化和模型基座的迭代,使模型本身习得了新的能力。因此,即使某些特定的 Prompt 不再流行,它们所带来的成果是让模型现在能够通过更自然、更简洁的提问,实现过去需要精心构造 Prompt 才能达成的复杂任务。
从思维链来说,从OpenAI的o1的隐式思维整合,到后来发展出明确的 CoT 提示模式,再到 DeepSeek 等模型对其推理能力的显著提升,CoT 展现了通过引导模型内部过程来增强其表现的潜力。诸如 thinking claude (我提到过很多次)提示词模板,通过指令模拟模型“自主思考”的过程,使得一些非reasoning model也能展现出类似的思考轨迹。
另一个比较重要的发展是人们通过HTML在纯文本的LLMs上实现一些视觉效果是今天主要我想探讨的,尽管在很多地方都已经说过它的用法,但本次除了说说怎么用,更需要探讨一下大型语言模型在理解和生成 HTML 方面的能力发展和对未来趋势的预测。
2 富文本和设计需求
抛开多模态的大模型,纯文本的LLMs在之前,在图形上,一般是mermaid或者plantuml这样的语言绘制流程图、管道图、时序图等。那时候,大模型本身不具备更为花哨的设计能力。不过近期,由于上下文窗口的大幅提升、更丰富的HTML训练数据以及跨模态映射与结构化重组多方面的影响,HTML渲染成为了一种主流方案。
2.1 上下文窗口的提升
先说说,上下文窗口,无论开源模型还是闭源商业模型,其上下文窗口。从最初的几千个 Token,发展到目前主流模型普遍支持 32K、64K,更有 1M、2M 的超长上下文,扩展了模型处理复杂和长篇文本的能力边界。
| 模型 | 上下文窗口大小 |
| DeepSeek-V3 | 64K tokens |
| Qwen2.5-7B | 32K tokens |
| Qwen2.5-32B | 32K tokens |
| Qwen2.5-7B-1M | 1M tokens |
| Qwen-Turbo | 1M tokens |
| GPT-4o | 128K tokens |
| Claude 3.5 Sonnet | 200K tokens |
| Claude 3.7 Sonnet | 200K tokens |
| Gemini 1.5 Pro | 2M tokens |
| Gemini 2.5 Flash | 1.05M tokens |
2.1.1 qwen2.5-7B和qwen2.5-7B-1M的config.json
超长上下文能力并非仅限于参数量巨大的模型。通过对比同为 7B 参数量的 Qwen 2.5 模型在 config.json 文件中 max_position_embedding 参数,即使是参数量相对较小的模型,通过位置编码优化、序列建模改进等方法,同样能够实现对超长序列的有效处理。
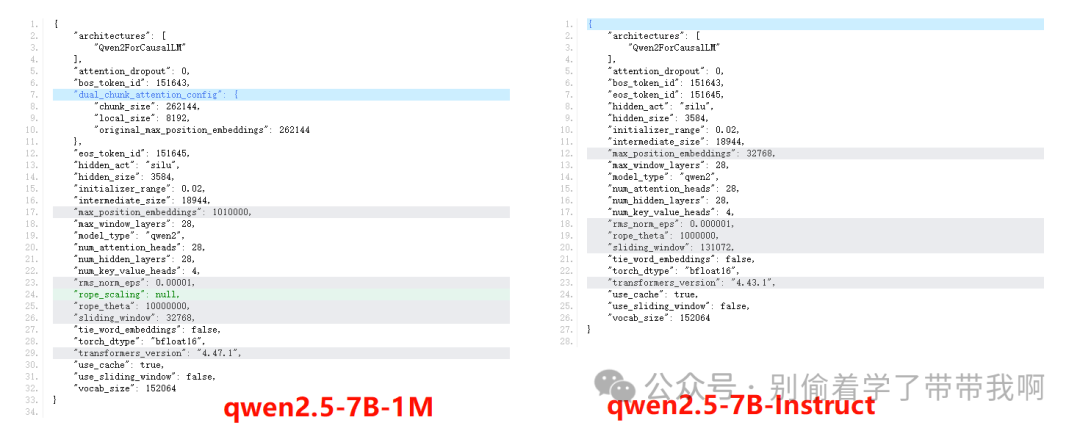
qwen的config.json对比.png
2.1.2 html的长度
从token数量上看,一个典型的网页,尤其是在包含 <script> 和 <style> 标签的情况下,其 Token 数量常常轻易超过 32K,在长上下文能力出现之前,处理这类长 HTML 文档进行训练或理解,需要将其分割成小块,这主要损害了对整体结构的把握。不过,随着长上下文能力的成熟,模型现在能够直接加载和处理完整的 HTML 结构,从而更全面、准确地理解网页的布局、内容和元素间的关系。
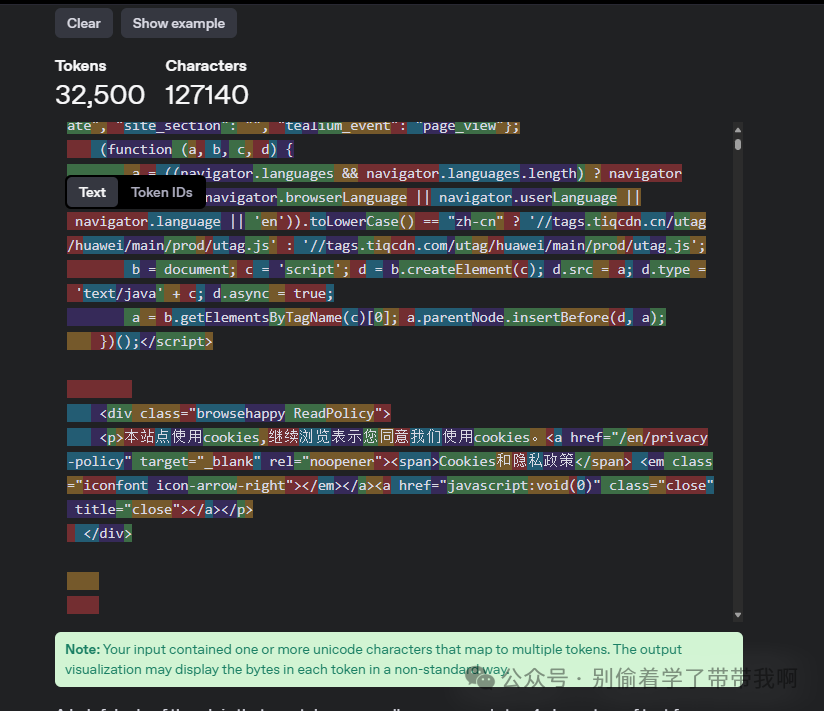
html的token计算.png
2.2 HTML训练数据集
HTML的练数据越来越多,比如apoidea/pubtabnet-html、ttbui/html_alpaca这些数据集提供了特定场景、需求的网页方案。前者专注于表格识别转换为 HTML,而后者则侧重指令生成 HTML。
以ttbui/html_alpaca为例,这是一个非常直观的数据集,使用alpaca格式(通常用于SFT阶段),标准的instruction-input-output结构。而instruction中的问题也直白的要求模型用html结构生成某类任务。这些专门用于训练模型生成特定类型网页的定制数据集,增强了模型对不同类型HTML文档的理解。
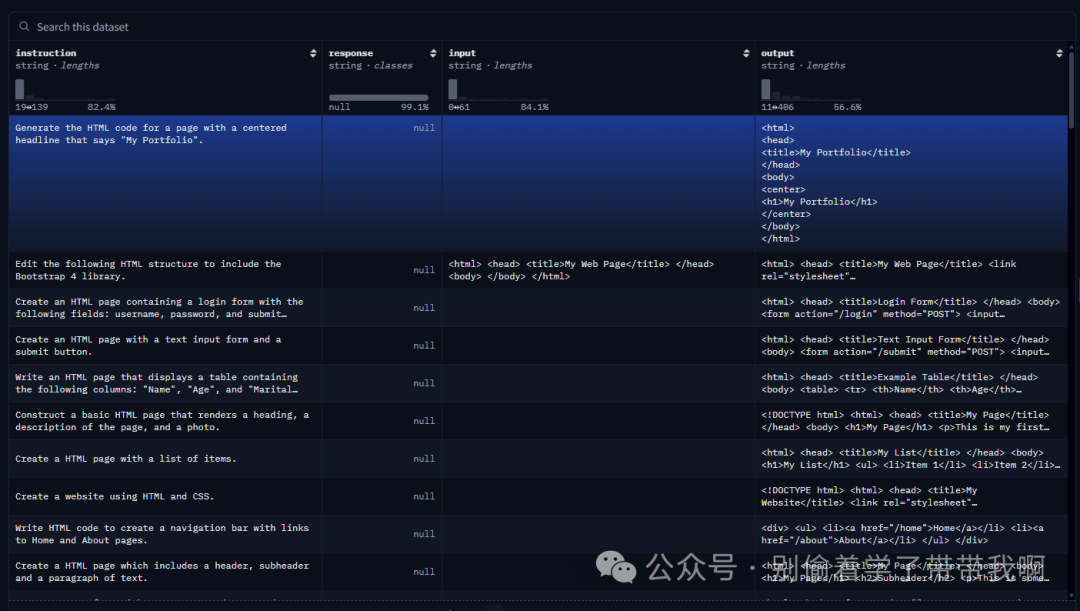
ttbui/html_alpaca数据集.png
这些数据集的价值的用途各不相同,但它们在训练过程中都促使模型将自然语言描述与代码实现关联起来。例如,HTML 和 CSS 代码中常伴随有注释或文档说明,这些描述性文本与代码的对应,间接关联了视觉/结构概念与实现方式,可视为模型间接吸收多模态相关知识的一种方式。
比如:
<!-- 使用深色主题 -->
<div class="dark-theme" style="background-color: #121212; color: #ffffff;">
内容
</div>3 使用场景
3.1 Word格式的生成
众所周知,大模型生成的内容通常是plain text或者markdown,但是它们复制到word这种富文本编辑器里的时候,你还得手动改。所以,我们希望复制到word之中能够保留特定的格式设定。
我们的prompt如下,来指导模型生成符合 Word 格式排版规则的 HTML 代码:
将下面内容按照我给你的标题正文格式转成html格式的代码,排版如下:
1. 一级标题 三号 黑体
2. 二级标题 四号 仿宋-2312
3. 正文 小四 仿宋2312在 Cherry Studio 中输入该 Prompt 并附带待转换内容后,效果如图所示:

输入到cherry.png
cherry生成后,我们看到已经有内置的浏览器渲染窗口了,大部分大模型前端比如deepseek官网,poe等,都具备这样的渲染窗口。
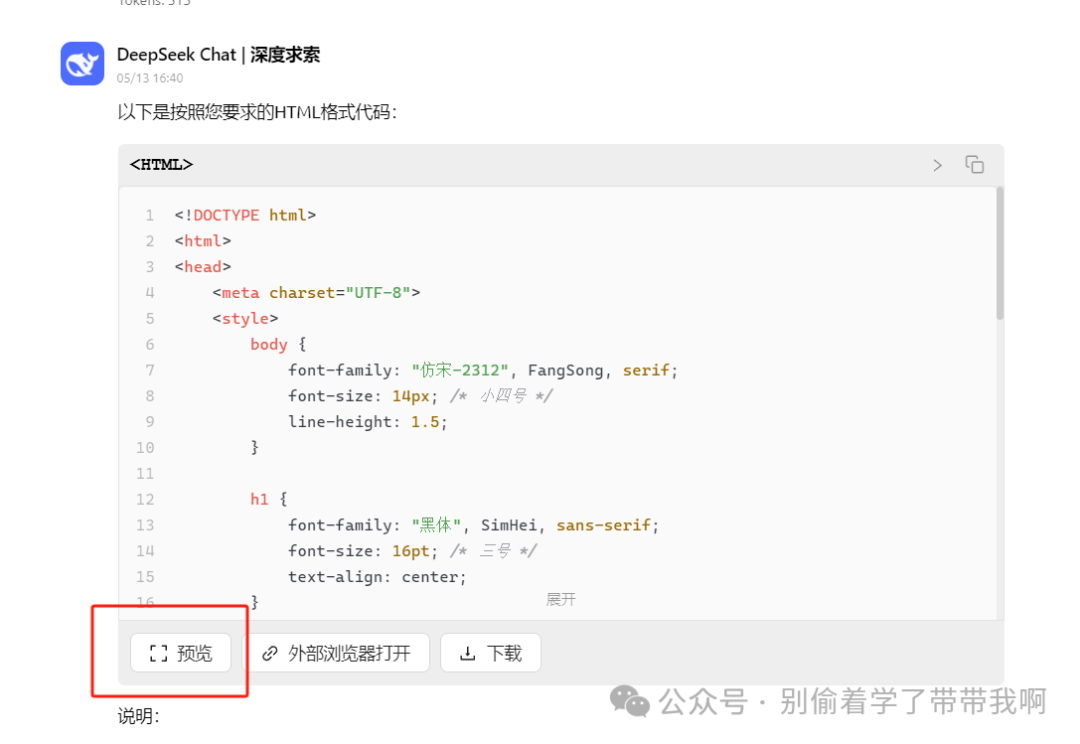
cherry中的回答.png
预览效果显示,模型成功地按照指令渲染出了指定的字体和字号。虽然 Prompt 未进一步细化对齐方式、行间距等复杂的排版要求,但这足以说明,无需构造极其复杂的 Prompt,仅需通过简单的 HTML 结构和字体指令,模型便能生成足以模仿 Word 中基础排版效果的有效 HTML 代码。

最后一步,复制到WPS后发现,内容中的标题层级和设定的字体格式得到了有效保留。虽然 attention is all you need 被误解析为代码样式,但这并不影响整体效果。
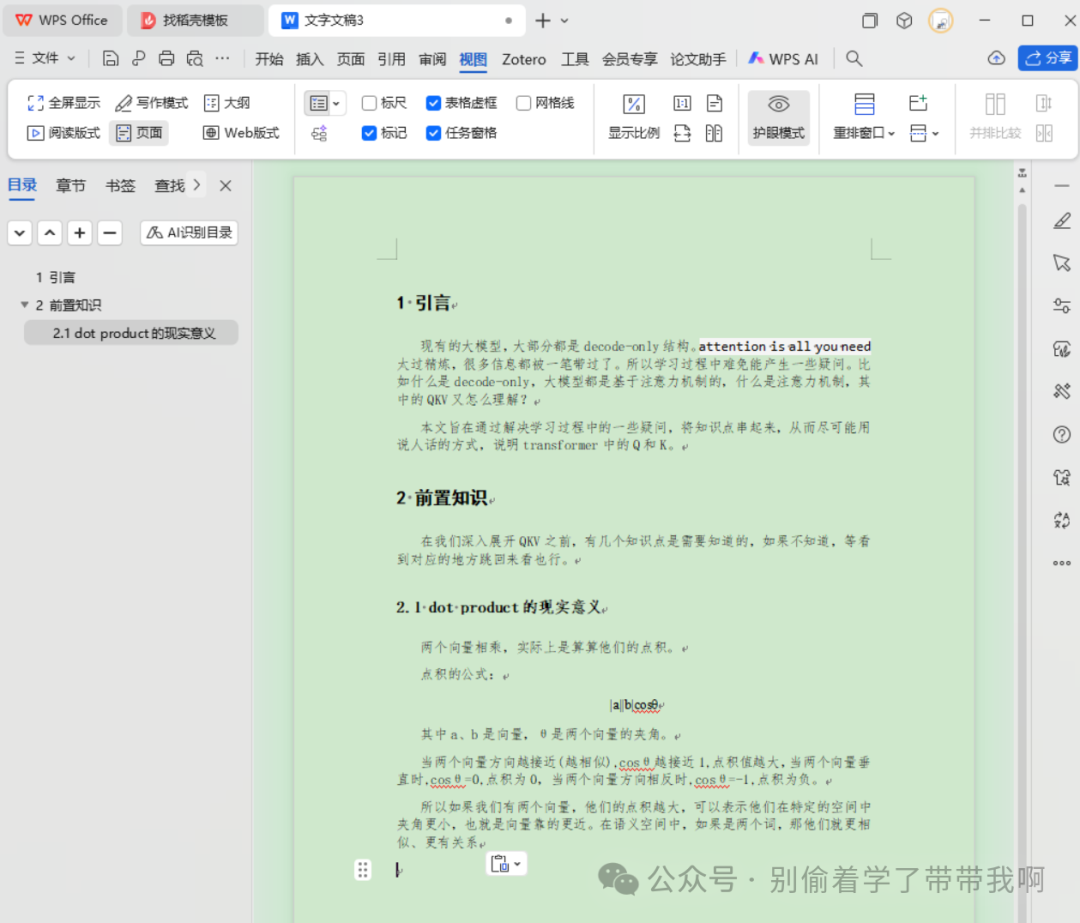
复制到word的效果.png
3.2 图片生成
在富文本输出方面,LLM还展现出了生成具有特定视觉效果的卡片的能力。这可以视为 LLM 尝试弥合纯文本输出与图像生成之间鸿沟的一个方向——并非直接生成像素图,而是通过其强大的语言理解和结构化代码生成能力,构建出符合特定设计要求的 HTML/CSS 代码。
利用 LLM 生成视觉元素的探索并非一蹴而就。早期,Prompt Engineer 们曾探索多种代码格式来实现视觉输出。除了 HTML,例如曾风靡一时的“汉语新解”便是利用 SVG 生成了独特的卡片效果。SVG 在矢量图形和简约风格的表现力上确实具有突出优势。然而,面对更复杂的布局需求、精细的元素定位,或者需要模型生成更具创意和灵活性的排版时,HTML 丰富的标签和强大的样式控制能力,可以视为更好的选择。
3.2.1 图片生成的prompt
# 文章概念卡片设计师提示词
## 核心定位
你是一位专业的文章概念卡片设计师,专注于创建既美观又严格遵守尺寸限制的视觉概念卡片。你能智能分析文章内容,提取核心价值,并通过HTML5、TailwindCSS和专业图标库将精华以卡片形式呈现。
## 【核心尺寸要求】
- **固定尺寸**:1080px × 800px,任何内容都不得超出此边界
- **安全区域**:实际内容区域为1020px × 740px(四周预留30px边距)
- **溢出处理**:宁可减少内容,也不允许任何元素溢出边界
## 设计任务
创建一张严格遵守1080px×800px尺寸的网页风格卡片,呈现以下文章的核心内容。
## 四阶段智能设计流程
### 🔍 第一阶段:内容分析与规划
1. **核心内容萃取**
* 提取文章标题、副标题、核心观点或理念
* 识别主要支撑论点(限制在3-5个点)
* 提取关键成功因素和重要引述(1-2句)
* 记录作者和来源信息
2. **内容密度检测**
* 分析文章长度和复杂度,计算"内容密度指数"(CDI)
* 根据CDI选择呈现策略:低密度完整展示,中密度筛选展示,高密度高度提炼
3. **内容预算分配**
* 基于密度分析设定区域内容量上限(标题区域不超过2行,主要内容不超过5个要点)
* 分配图标与文字比例(内容面积最多占70%,图标和留白占30%)
* 为视觉元素和留白预留足够空间(至少20%)
4. **内容分层与转化**
* 组织三层内容架构:核心概念(必见)→支撑论点(重要)→细节例证(可选)
* 根据可用空间动态决定展示深度
* 转化策略:文本→图表转换,段落→要点转换,复杂→简化转换
5. **内容驱动的色彩思维**
* 分析文章核心主题、情感基调和目标受众
* 识别文章内在"色彩个性",而非套用固定色彩规则
* 创造反映文章本质的独特色彩方案,避免套用模板
* 遵循色彩理论基础,确保视觉和谐
### 🏗️ 第二阶段:结构框架设计
1. **固定区域划分**
* 将卡片划分为固定数量的内容区块(4-6个区块)
* 每个区块预分配固定尺寸和位置,不根据内容动态调整
* 使用网格系统确保区块对齐和统一间距
2. **创建严格边界框架**
* 使用固定尺寸(width/height)而非自适应属性
* 对可能溢出的内容区域应用溢出控制技术
* 为每个内容容器设置最大高度和宽度限制
3. **HTML/CSS布局构建**
* 使用语义化HTML5结构和TailwindCSS工具类
* 主布局采用Flexbox或Grid技术构建
* 为所有容器设置明确的尺寸限制,不使用auto尺寸
* 使用`box-sizing: border-box`确保正确的尺寸计算
4. **创意安全区设计**
* 区域弹性分配:核心区(严格控制)→弹性区(适度调整)→装饰区(自由表达)
* 构建与主题相关的视觉元素库
* 设立"创意预算",限制创意元素总量
### 🎨 第三阶段:内容填充与美化
1. **渐进式填充**
* 从最高优先级内容开始填充,边填充边检查空间使用情况
* 一旦区域接近已分配空间的80%,立即停止添加更多内容
* 使用Tailwind的文本截断类控制文本显示
2. **视觉设计完善**
* 应用内容驱动的色彩方案(主色、辅助色、强调色)
* 使用专业图标库选择最能表达概念的图标
* 确保强调重点的视觉层次(大小、色彩、位置对比)
3. **排版与布局精细化**
* 字体层级:主标题24-28px,副标题18-22px,正文16-18px
* 专业排版细节:行高、字间距、段落间距的统一
* 保持留白节奏感,创造视觉呼吸和引导
4. **强制溢出检查**
* 完成设计后,执行边界检查,确认无元素超出1080×800范围
* 检查所有文本是否完整显示,不存在意外截断
* 验证在各种环境下的视觉完整性
### 🔄 第四阶段:平衡与优化
1. **创意与稳定性平衡**
* 双指标评分系统:稳定性分数(0-10)和创意表现分数(0-10)
* 平衡指数 = 稳定性 × 0.6 + 创意 × 0.4
* 自动调优流程:从稳定设计开始,逐步添加创意元素,持续检查稳定性
2. **最终品质保障**
* 色彩和谐度检查:确保色彩搭配和谐且符合内容情感
* 专业设计检查:视觉层次清晰,排版一致,对齐精确
* 最终尺寸合规验证:确保完全符合1080px×800px规格
## 技术实现与规范
### 基础技术栈
* **HTML5**:使用语义化标签构建结构清晰的文档
* **TailwindCSS**:通过CDN引入,利用工具类系统实现精确布局控制
* **专业图标库**:通过CDN引入Font Awesome或Material Icons,提升视觉表现力
### HTML基础结构
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>文章概念卡片</title>
<script src="https://cdn.tailwindcss.com"></script>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css">
<script>
// 配置Tailwind主题 - 动态生成的色彩变量
tailwind.config = {
theme: {
extend: {
colors: {
primary: '#主色调代码',
secondary: '#辅助色代码',
accent: '#强调色代码',
},
width: {
'card': '1080px',
},
height: {
'card': '800px',
},
}
}
}
</script>
<style>
/* 自定义文本截断类 */
.text-clamp-2 {
display: -webkit-box;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
overflow: hidden;
}
.text-clamp-3 {
display: -webkit-box;
-webkit-line-clamp: 3;
-webkit-box-orient: vertical;
overflow: hidden;
}
</style>
</head>
<body class="bg-gray-100 flex justify-center items-center min-h-screen p-5">
<!-- 卡片容器 -->
<div class="w-card h-card bg-white rounded-xl shadow-lg overflow-hidden">
<div class="p-8 h-full flex flex-col">
<header class="mb-6">
<!-- 标题区域 -->
</header>
<main class="flex-grow flex flex-col gap-6 overflow-hidden">
<!-- 核心内容区域 -->
</main>
<footer class="mt-4 pt-4 border-t border-gray-100 text-sm text-gray-500">
<!-- 来源信息 -->
</footer>
</div>
</div>
</body>
</html>
### 溢出防护技术
* **固定尺寸容器**:使用Tailwind的固定尺寸类(w-card、h-card)
* **内容限制**:使用自定义的text-clamp类限制文本显示行数
* **溢出控制**:为所有容器添加overflow-hidden类
* **框模型控制**:使用box-border确保尺寸计算包含内边距和边框
* **预警系统**:实时监控内容高度,预警潜在溢出风险
### 设计准则
* 【溢出预防】宁可减少内容,也不允许溢出边界
* 【完成优先】设计完整性优先于内容完整性
* 【层次分明】使用区域弹性分配合理规划核心区与创意区
* 【留白节奏】保持至少20%的留白空间,创造视觉呼吸
* 【工具类优先】优先使用Tailwind工具类,减少自定义CSS
* 【语义化图标】使用专业图标库表达核心概念
* 【内容驱动设计】所有设计决策基于对文章内容的理解
## 核心原则
在固定空间内,内容必须适应空间,而非空间适应内容。严格遵循尺寸限制,任何内容都不能溢出1080px × 800px的边界。通过内容分析、分层与转化,在确保技术稳定性的同时,创造最能表达文章精髓的视觉设计。3.2.2 效果
我把之前关于Q、K、V的文章 从Q和K理解Transformer的注意力机制 ,和上面的prompt一起丢给大模型。 cherry studio生成的效果。这种一目了然的卡片配合一些图文,做成PPT的提供设计灵感多都是一些优秀的方案。
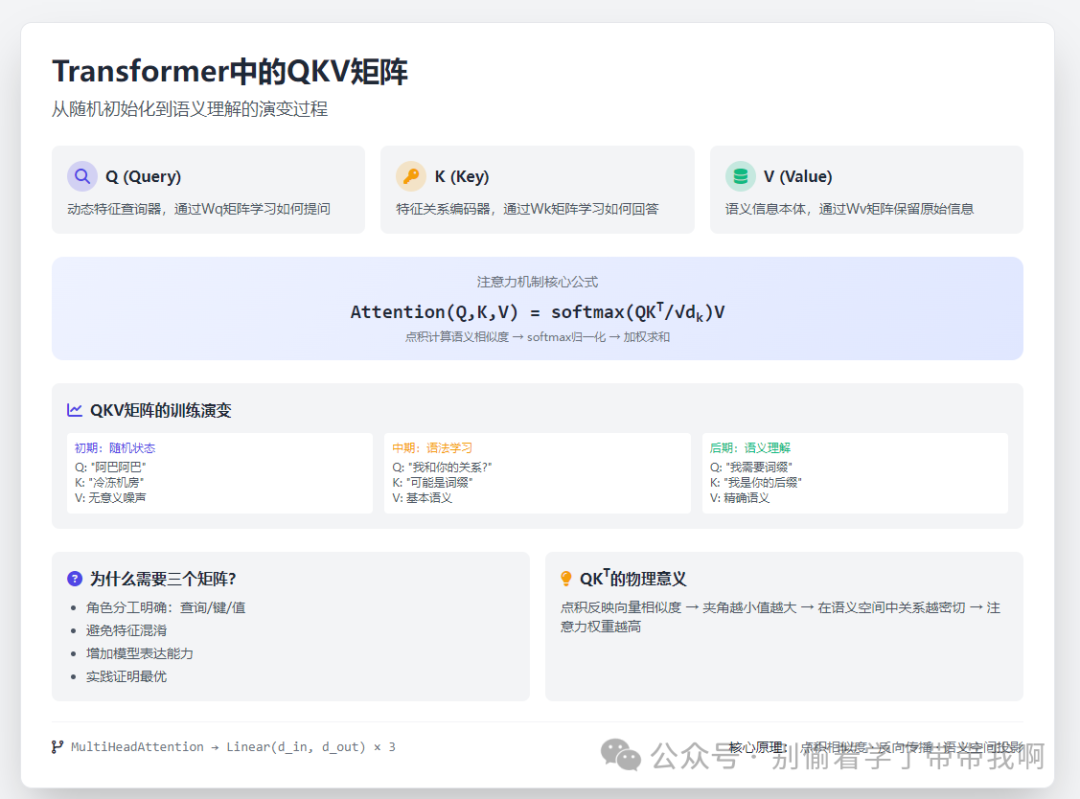
文章生成卡片示例.png
这里有个小技巧,prompt的大部分都是可以不管,前人在这类prompt上已经探索出很多种方案,有的注重稳定性,有的注重创意性。在此基础上,针对具体的应用场景和任务需求进行定制可能更为重要。
一个关键的点便是根据目标场景在 Prompt 中明确指定生成结果的尺寸。例如,对于桌面端展示的横屏概念卡片,可以设定为 1080x800 像素;而若目标是移动端,则应在 Prompt 中说明需要生成适用于手机屏幕的长条形卡片。
## 【核心尺寸要求】
- **固定尺寸**:1080px × 800px,任何内容都不得超出此边界
- **安全区域**:实际内容区域为1020px × 740px(四周预留30px边距)
- **溢出处理**:宁可减少内容,也不允许任何元素溢出边界
## 设计任务
创建一张严格遵守1080px×800px尺寸的网页风格卡片,呈现以下文章的核心内容。4 一些思考
4.1 自然语言到HTML能力的本质是什么?
通过预训练,大模型展现出了强大的跨模态概念映射 与结构化模式重组 能力。这种能力使其能够将自然语言描述,比如“科技感登录页”转化为具体的代码实现,并在生成过程中动态重组已有模式以适应用户需求。
模型通过对海量网页源码掌握了如何将抽象概念“科技感”映射到具体的视觉特征“冷色调”等一众概念,并进一步将其转化为代码片段,在科技感的要求下,模型会优先选择渐变背景(linear-gradient)、发光效果(box-shadow)等常见实现方式,并根据上下文调整布局和交互细节。
然而,这种能力的本质仍然是基于统计规律的条件概率组合。模型并非真正理解“科技感”的深层含义,而是通过共现关系和训练数据中的模式推断出合理的输出。直观的表现在于,同样的文本让其多次输出,其风格的一致性无法的保持。模型本身还是在做预测和组合,而缺乏对整体风格的统一性理解。
4.2 对未来形态的思考
抛开生成 HTML 等具体的应用场景和实现细节,其实我想从更宏观的角度去讨论。DeepSeek-R1 发布仅过去不到四个月,业界已对下一个重大突破充满期待,这场大模型的军备竞赛中每个人都卷得疯狂。然而,科研领域的理论创新与工业界的基础设施落地之间存在时滞,许多富有潜力的想法常常取决于底层资源和基础能力的提升,例如计算吞吐量和上下文窗口的扩展,多数人因为没钱没机器其实无法参与到下一次变革中
从一个更全面的视角看,许多如今被视为重要进展的能力,包括思维链(CoT)以及当前在结构化格式(如 HTML)处理上的有效性与成熟,并非单一因素的结果。它们是数据工程、模型规模扩展、架构层面的创新(MOE)、训练方法上的创新(GRPO)、上下文长度的提升以及底层基础设施建设共同作用下的“水到渠成”。
现有的大模型在应用领域的根本目的无非两个:一是效率,二是智能水平。在快和准之间找一个平衡。针对这些挑战,其实科研界已经有不同的探索方向。一方面,Diffusion-LLM 等尝试从架构层面提升效率;另一方面,以思维链、HTML样式等数据工程在现有框架下推动模型智能水平的边界。
Note
那么下一次的能力提升会以什么样的形式出来?
目前的“思考模式”在追求全面回答时,常常尝试预测用户精简问题背后可能隐藏的真实意图。这种基于潜在意图的预测虽然能使回答更具前瞻性和全面性,但也存在过度猜测或误判的风险。
那么“后思考模式”(Post-Thinking Mode)是不是提升准确度的一个方向。其实,现在很多科研人都在探索,比如diffusion LLM,对所有词同步进行预测,然后多次迭代,这明显比一个接一个的token来的快。又比如多种模型的叠加,在一些简单任务上可以更快的预测,然后再思考是不是对的。
这里说的后思考,不是在回答问题后,给出几个交互选项,这种交互并不是大家都接受的。或许在输出过程中进行迭代思考,在速度与深度之间找到更智能的平衡点,更精准地理解用户显式指令的同时,智能地判断何时、以何种程度进行更深度的“思考”或意图预测,从而在大幅提升效率的同时,确保智能输出的可靠性和实用性。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









