






你是否曾惊叹于 AI 聊天机器人的“魔法”——像gpt、claude 这样的大语言模型(LLM),是如何从一堆代码和数据中“觉醒”,变得能言善辩、无所不能的“语言大师”?在这个技术驱动的时代,LLM 已悄然融入我们的生活:回答问题、创作文章、翻译语言,甚至编写代码,实现智能体,宛如一位全能的“语言魔法师”。但你是否想过,这些智能的背后,究竟藏着怎样的秘密?绕过LLM训练过程的学习者,就像建楼不打地基!今天,我们就来掀开这层神秘的面纱,一步步带你走进大语言模型的开发世界,看看这些强大工具的“魔法”是如何炼成的!
一、LLM 是如何训练出来的?
大语言模型的训练可不是“一招鲜吃遍天”,不同的模型有不同的“修炼秘籍”。今天我们以 GPT 和 Llama 为例,聊聊它们的训练流程有啥异同。
| 阶段 | 目标 | 方法 | 特点 |
|---|---|---|---|
| 预训练 | 学会说话 | 自监督学习 | 数据量最大,最耗算力 |
| 有监督微调 | 学会干活 | 问答训练 | 教模型完成任务 |
| 奖励建模 | 给回答打分 | 人工评分 + 模型学习 | 构建“评委系统” |
| 强化学习优化 | 精益求精 | PPO / DPO | 最终打磨模型行为 |
1. GPT 的训练四部曲
GPT 系列(比如 OpenAI 的 GPT-3.5 和 GPT-4)的训练分为四个核心步骤:
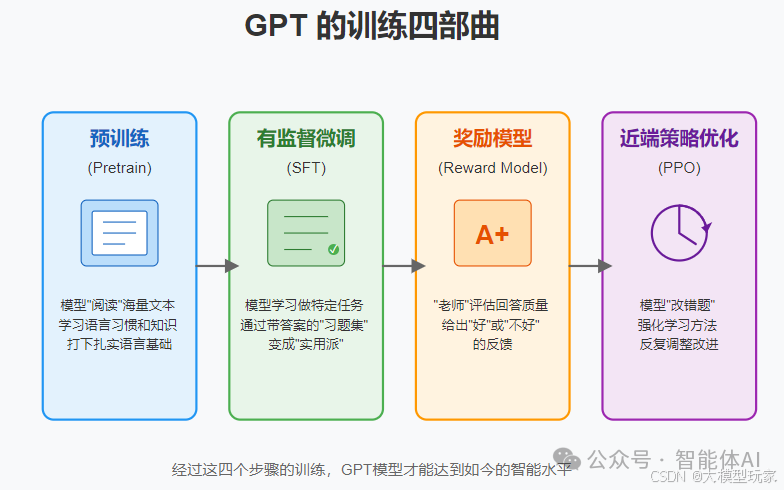
- 预训练(Pretrain) 想象一下,模型就像刚入学的小学生,面对一座“书山”。这个阶段,它会疯狂“阅读”海量文本,比如网页、书籍、论文,学习人类的语言习惯和知识,打下扎实的语言基础。
- 有监督微调(SFT) 光会读书还不够,得学会做题。SFT 就像给模型一本带答案的“习题集”,教它完成具体任务,比如聊天、分类或写文章,让它从“书呆子”变成“实用派”。
- 奖励模型(Reward Model) 想让模型知道自己做得好不好,得有个“老师”来评分。奖励模型就是这个“老师”,专门评估回答质量,给出“好”或“不好”的反馈。
- 近端策略优化(PPO) 有了评分,模型开始“改错题”。PPO 是一种强化学习方法,通过与奖励模型互动,模型反复调整自己,争取每次回答都更出色,循环几千次,精益求精。
小结: SFT、奖励模型和 PPO 合起来叫 RLHF(基于人类反馈的强化学习),是 GPT 的“秘密武器”,让它变得越来越聪明。
2. Llama 的训练五部曲
Llama 系列(比如 Meta 的 Llama 3)走的是另一条路,训练包括五个步骤:

- 预训练(Pretrain) 和 GPT 一样,先“读书”打基础,吸收语言和知识。
- 奖励模型(Reward Model) 也有个“评分老师”,但 Llama 的训练顺序和侧重点有所不同。
- 拒绝采样(Rejection Sampling) 模型会一次生成多个回答(比如 20 个),然后挑出最好的几个(比如 3 个),有点像“海选”出优质答案。
- 有监督微调(SFT) 和 GPT 类似,用标注数据调整模型,让它学会干活儿。
- 直接偏好优化(DPO) 这是一种更直接的优化方法,根据人类偏好调整模型,让回答更贴近预期。
小结: Llama 把第 2 到第 5 步循环 6 次,像“六道轮回”一样反复打磨,逐步提升性能。
3. GPT 和 Llama 有啥不一样?
-
GPT:靠PPO循环几千次,像个勤奋的学生反复做题,强化学习是它的杀手锏。
-
Llama:通过6轮多步骤优化,像个精明的工匠,反复雕琢作品,更注重整体协调。
二、预训练:打好语言地基
预训练是 LLM 开发的第一步,就像给模型上了一堂“语言通识课”。它会接触海量文本,比如网络文章、维基百科、小说、代码库甚至学术论文。这些数据被整合成一本“超级教材”,包含从几千亿到几万亿的词汇(Tokens)。通过学习这些内容,模型逐渐掌握语言规则、语境和生成能力。
1、它有多“重”?
-
目标:让模型掌握语言规则和海量知识。
-
数据量单位:
-
数据量:
2. 怎么训的?
- 海量阅读:模型逐字逐句读各种文本,比如新闻、小说、合同,分析语法和语义。
- 模仿学习:用“自回归”方式训练,看到前面几个字,猜下一个字。比如看到“你好,我是”,它得猜下一个可能是“谁”。
3、挑战在哪儿?
预训练费时费力,像烧钱烧电的“怪兽”。计算资源分配或参数设置稍有差错,模型就可能“学崩”,前功尽弃。研究人员得像“调音师”一样精心调整,确保一切顺利。
三、有监督微调(SFT):从读书到干专业的活
预训练让模型有了语言基础,但要让它真正派上用场,还得再“深造”一下。这就是有监督微调的阶段。SFT 就像技能培训,把模型从“通才”变成“专才”。
在这个阶段,研究人员会用标注好的数据集来训练模型,让它学会做具体的事儿,比如回答问题、翻译文本、写代码等。这些数据集就像“教材和答案”,比如:
- 提问:纽约大学有几个校区?
- 标准答案:纽约大学在美国和全球共有多个校区,包括但不限于纽约校区、阿布扎比校区和上海校区。
通过这样的训练,模型就变成了有监督微调模型(SFT Model),能更精准地理解任务要求,完成各种实用工作。
1、有监督和无监督啥区别?
- 有监督:给模型“标准答案”。
- 无监督:没答案,模型自己摸索规律,像预训练那样。
2、为啥预训练叫“自监督”?
预训练不用人工标注答案,数据自己提供线索。比如用“你好,我”预测“是”,这叫自监督学习。
3、SFT干啥用?
- 问题:预训练的模型只会续写,不会回答问题或完成任务。
- 解决:通过“指令微调”(Instruction Tuning),用问答数据训练它。比如教它:“用户问天气,你得回答今天天气如何”。
4、SFT的数据咋样?
- 数据量:比预训练少得多,大概是1/100。比如Llama 3预训练用15万亿Token,SFT可能就几百万到几千万。
- 格式:通常是问答对,比如“问题:1+1=?” “回答:2”。
5、优点是什么?
相比预训练,这个阶段快多了。通常只需要几十个 GPU,几天就能搞定。因为模型已经有了“底子”,微调只是让它“专精”某项技能。
四、奖励模型:谁来告诉模型“对”还是“错”?
微调后的模型已经能干活了,但输出质量参差不齐,怎么让它变得更“优秀”呢?答案是奖励建模。
这个阶段的目标是打造一个奖励模型(RM Model),专门用来评价模型输出的质量。比如,同一个问题,模型可能给出好几个答案,奖励模型会“打分”,告诉它哪个更好。
1、奖励模型是怎么炼成的?
你可能会问:模型怎么知道自己的回答好不好?这就需要 奖励模型(Reward Model) 来当“裁判”。
- 准备一堆问题(Prompt),让模型生成多个回答(如 GPT 通常生成 4-5 个,Llama 会生成 20 个)。
- 请人工进行打分或排序,比如说:“回答 A 比 B 更自然”。
- 用这些标注数据训练一个专门评分的模型。
- 以后每次模型生成答案,奖励模型就能“打分”,告诉它表现如何。
这个过程非常关键,因为它直接影响后续强化学习阶段的优化方向。
2、有啥用?
奖励模型给PPO或DPO提供依据,告诉模型“这个回答行不行”,帮它越变越好。
3、有啥难点?
人工排序特别费时间,而且不同的人可能看法不一样,怎么保证标注一致是个大问题。还有,奖励模型得足够聪明,能适应各种情况,这也挺考验技术。
五、强化学习优化:模型的“冲刺阶段”
最后一个阶段,就是利用奖励模型的反馈进行 强化学习优化,比如 GPT 使用的是 PPO(近端策略优化),而 Llama 更倾向于 DPO(直接偏好优化)。
这一步就像是高考冲刺班,根据错题本反复练习,优化每一个细节。
- GPT 通常用 RLHF(基于人类反馈的强化学习),也就是 SFT + 奖励模型 + PPO 三件套,反复调整,像苦练技巧的学生。。
- Llama 的策略略有不同:它把“奖励模型 + 拒绝采样 + SFT + DPO”这一整套流程反复执行 6 轮,像精雕细琢的工匠。不断打磨回答质量。
简单对比一下:GPT 像一个苦练技巧的优等生,反复刷题。Llama 更像一个精雕细琢的工匠,通过多轮精选优化模型表现。
六、总结
通过这篇文章,你是不是对GPT和Llama的训练过程有了清晰的认识?已经了解了大语言模型的开发全流程——从预训练打下语言基础,到有监督微调学会具体技能,再到奖励建模和强化学习精益求精,每一个环节都环环相扣,缺一不可。正是这些复杂而精妙的步骤,让 ChatGPT 这样的模型变得如此智能和可靠。从海量文本到精炼的智能,这段旅程无疑是科技与人类智慧的结晶,令人叹为观止。不懂 LLM 训练,所有算法都是空中楼阁! 这不仅是 AI 学习的第一定律,更是通往智能未来的钥匙。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









