



卷疯了,通义千问真的卷疯了。
Qwen3-Coder刚炸完场,就隔了一天,马上全新开源Qwen3系列最强推理模型——Qwen3-235B-A22B-Thinking-2507。
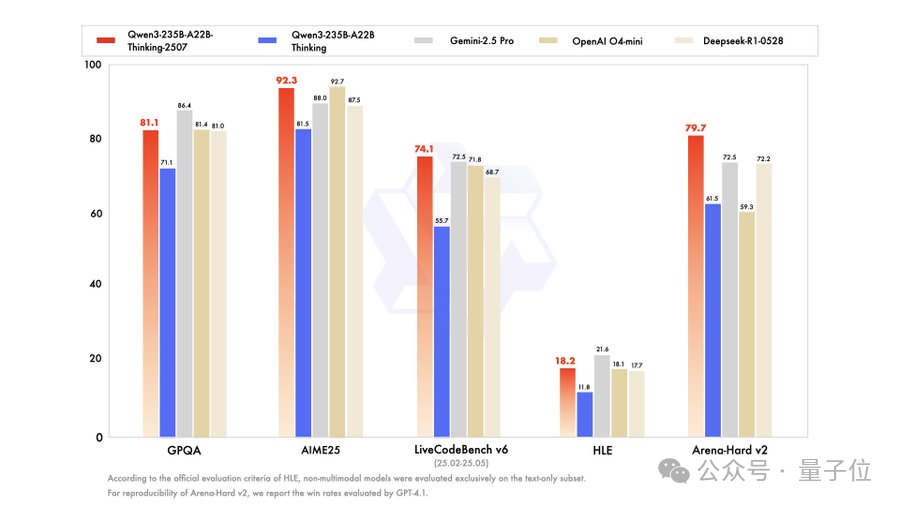
怎么个最强法?一登场,再次刷新SOTA,在各项测评中一举拿下「全球最强开源模型」宝座,比肩顶级闭源模型Gemini-2.5 Pro、o4-mini。
国外网友都馋哭了:
关键是,就在这短短一周里,算上前两天开源的新基础模型Qwen3-235B-A22B-Instruct-2507(非思考版),和Qwen3-Coder,通义千问是完成了一波开源三连。
开源还不算,各个出手即SOTA:接连斩获基础模型、编程模型、推理模型三项全球开源最强。
这个模型更新强度和效能提升,妥妥地引领全球了。
就问小扎慌不慌(doge)。
新版Qwen3推理模型,登顶全球开源最强
正如DeepSeek R1是在V3基础上打造的推理模型,Qwen3全新推理模型,是基于Qwen3-235B-A22B打造——就是235B参数那版MoE,激活参数22B。
官方表示,新推理模型主要提升了3方面的核心能力:
-
逻辑推理、数学、科学和编码等任务上性能显著提升;
-
能更好地遵循指令、使用工具、生成文本;
-
支持256K原生上下文,适用于高度复杂的推理任务。
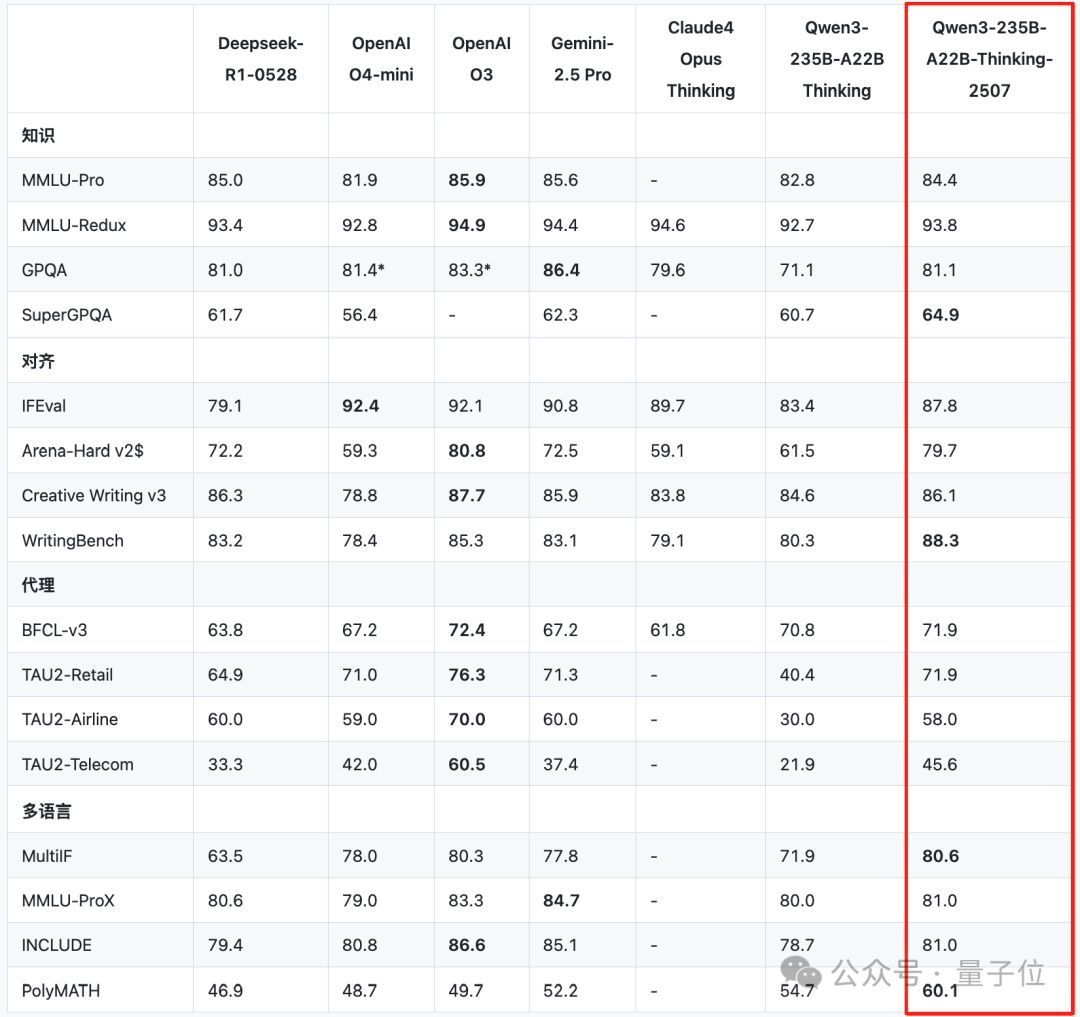
而此番刷新SOTA,登顶开源最强,确实不是那种一丢丢提升,仔细看测评分数,那是「真有点东西」。
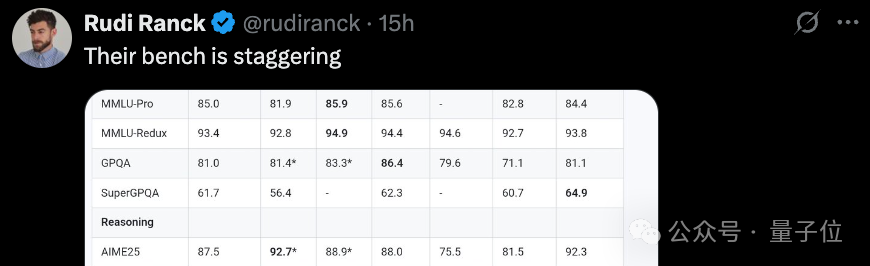
先来看推理方面。
在超高难度测试「人类最后的考试」中,最新的2507版推理模型,相较4月底初发布的Qwen3推理模型,分数从11.8分提升到了18.2分。
超过了DeepSeek-R1-0528的17.7分,和OpenAI o4-mini在高性能推理模式下拿到的18.1分。
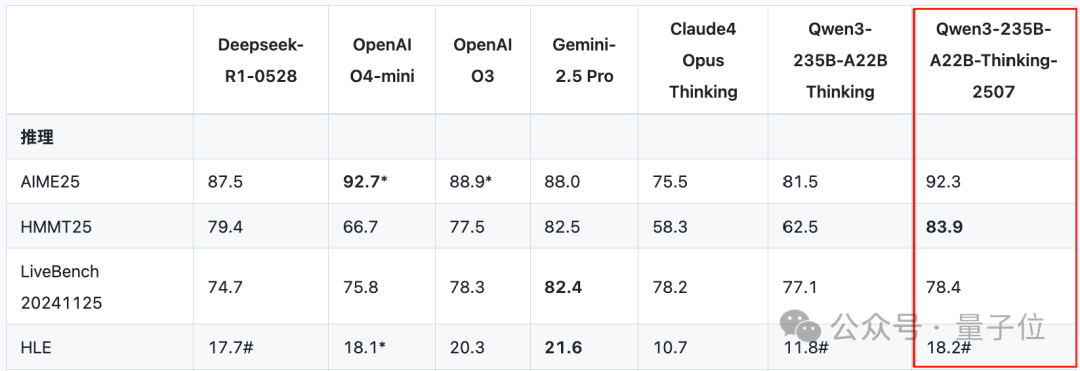
编程方面,在LiveCodeBench v6和CFEval中,Qwen3新推理模型甚至超越了Gemini-2.5 Pro等闭源业界标杆,刷新SOTA。
除此之外,在知识、对齐、智能体、多语言等基准评测中,Qwen3新推理模型都有比肩闭源模型的表现,达到开源SOTA。
纸面上的成绩属实是相当优秀,那么具体使用起来,这个新推理模型表现又会如何?
我们也简单测试了一下。
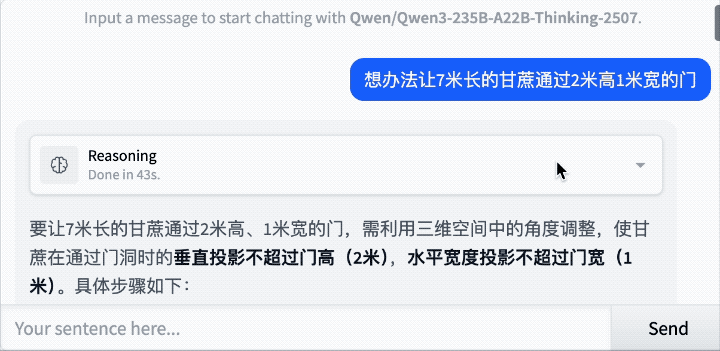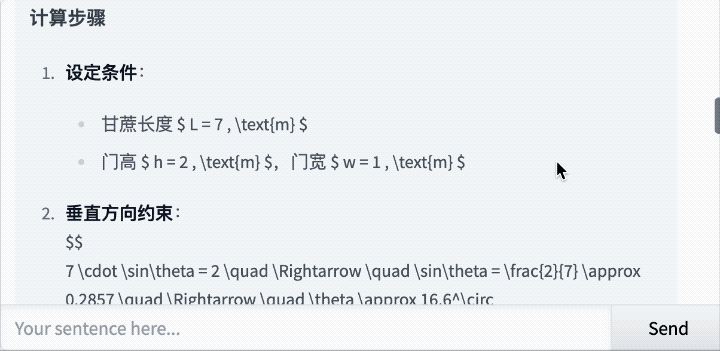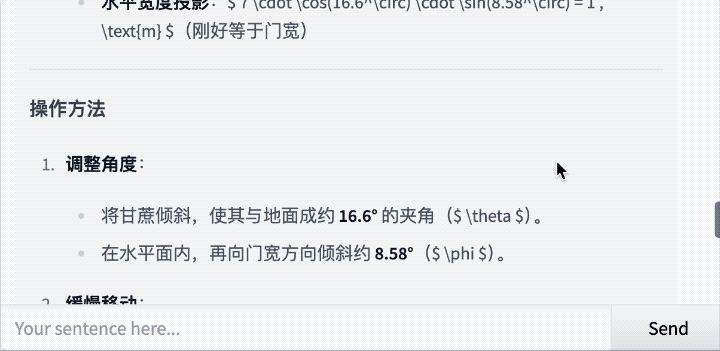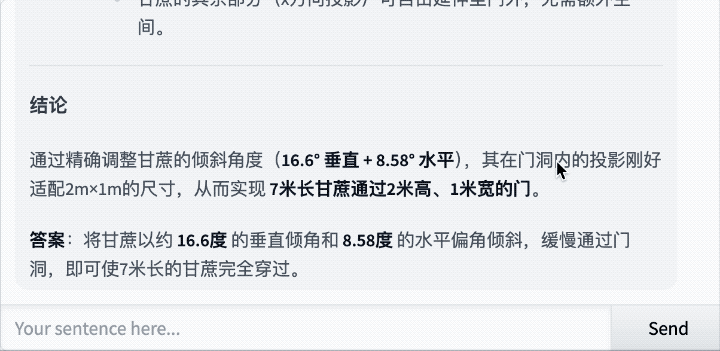
还是那道经典题:7米长的甘蔗如何通过2米高1米宽的门?
Qwen3-235B-A22B-Thinking-2507思考了43秒,最后给出的答案是:

思考过程如下:
相较之下,o4-mini的答案就简单粗暴了些。

模型三连开源,摘下三项SOTA
前面也说到,全新推理模型,其实是本周阿里开源第三弹。
总结起来画风其实是酱婶的:
前两弹震得大家伙脑袋嗡嗡的,各种实测部署正上头呢,通义实验室的卷王们啪地又甩出了一对王炸。

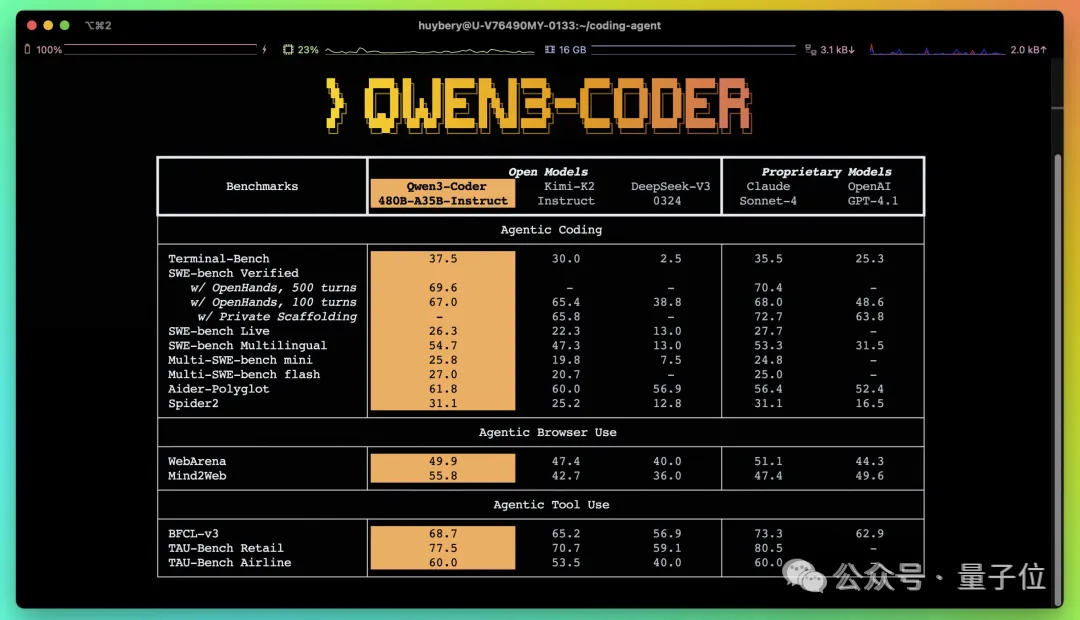
就说Qwen3-Coder,开源即刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
网友们实测起来,小球弹跳效果是这样的:

HuggingFace首席执行官Clement Delangue、Perplexity首席执行官Aravind Srinivas等大佬都第一时间加入了讨论、点赞:
这是开源的胜利。
Qwen3-Coder火爆,带动阿里千问API调用量暴涨。
海外知名模型API聚合平台OpenRouter数据显示,阿里千问API调用量过去几天已突破1000亿Tokens,在OpenRouter趋势榜上包揽全球前三,是当下最热门的模型。
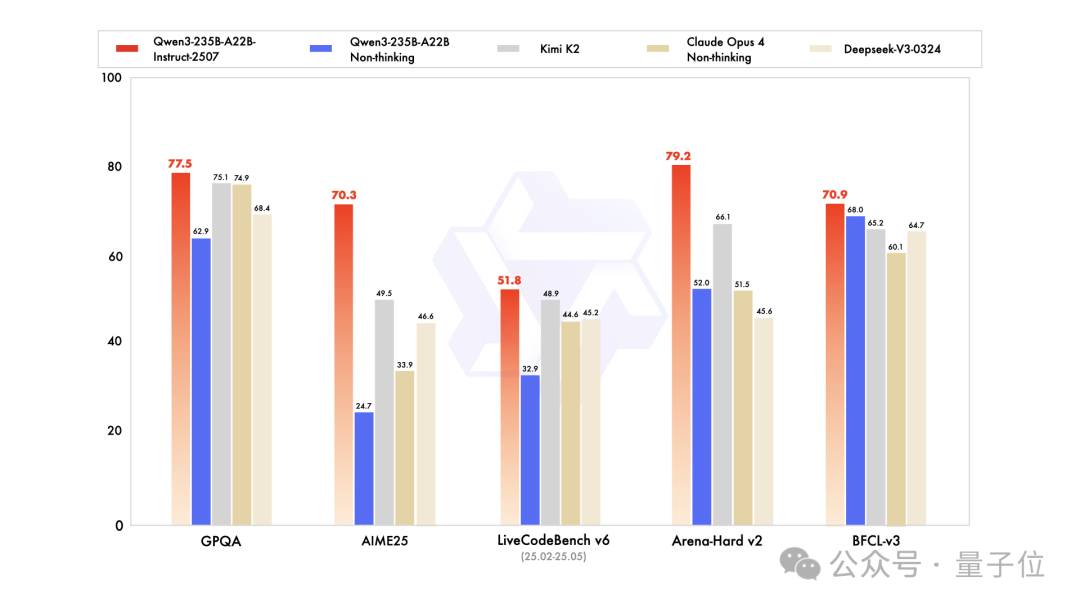
基础模型领域,Qwen3最新版本——Qwen3-235B-A22B-Instruct-2507(非思考版)也登顶全球开源第一,在GPQA(知识)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(人类偏好对齐)、BFCL(Agent能力)等众多测评中表现出色,超越Claude4(Non-thinking)等领先闭源模型。
中国开源,卷到了世界最前沿
三连开源,连摘三冠,对于中国开源力量而言,或许还只是一个开端。
有一说一,打从DeepSeek爆火、Llama 4翻车,要说开源领域哪股势力最为活跃,成为新的风潮引领者,还得看神秘的东方力量。
每有开源新王诞生,DeepSeek、Qwen、Kimi……看来看去,还是made in China。
「中国确实将开源提升到了一个新高度」,越来越多地被讨论、被赞同。

关键是,正如黄仁勋最新一次在北京所说,开源模型方面,「中国发展速度极快」。
以Qwen为例,目前,阿里已开源300余款通义大模型,通义千问衍生模型突破14万个,已经真真正正超越此前的全球开源老大Llama系列,成为全球第一开源模型家族。
阿里方面透露,未来三年,阿里巴巴还将投入超过3800亿元用于建设云和AI硬件基础设施,持续升级全栈AI能力。
更重要的是,开源和闭源的差距也正在这种中国速度中被压缩。
增长曲线的交叉点何时出现?尚未可知,但国产模型的身位已经实实在在排在了全球最前沿。
如何学习AI大模型 ?
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
(👆👆👆安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)

随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
(👆👆👆安全链接,放心点击)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









