






第一篇 ChatGPT背后强大而神秘的力量:用最简单的语言讲解Transformer架构之概览
2017年,谷歌的研究团队发表了具有里程碑意义的论文《Attention is All You Need》,首次提出了Transformer模型。这一创新架构极大地推动了自然语言处理(NLP)技术的发展,成为后续如Generative Pre-trained Transformer(GPT),Pathways Language Model(PaLM)等大型语言模型(LLM)开发的基石,彻底改变了之前依赖传统神经网络,比如Recurrent Neural Network(RNN)及其变种Long Short-Term Memory(LSTM)和Gated Recurrent Unit(GRU)的研究方向。
本系列文章致力于用最简单的语言讲解Transformer架构,帮助朋友们理解它的强大之处,本文是第一篇:概览。
01
RNN的挑战
循环神经网络(RNN)是神经网络(NN)的一种特别设计,专门用于处理按顺序排列的数据,比如文本、音频、时间序列等。它的独到之处在于引入了“记忆”功能,让网络能记住之前输入的信息。这种记忆功能在处理需要理解上下文的任务时显得尤为重要,比如在NLP中,语义的理解和生成过程。
如果从视觉角度描述,一个标准的RNN结构看起来就像是一个计算单元,它通过一个自连接的隐藏状态进行信息循环,让信息能够跨时间步(St)传递:
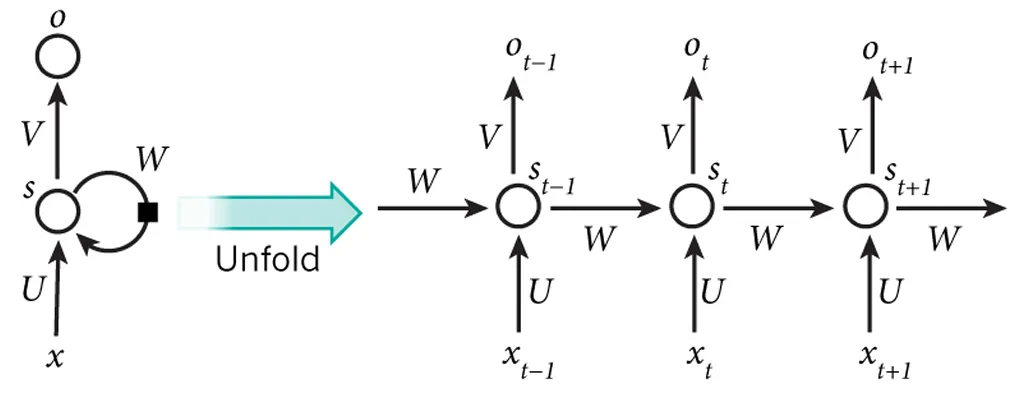
随着数据在RNN中的流动,之前时间步的激活状态会作为输入参与到当前数据的处理中,让模型能够动态地融合时间上下文和序列的历史信息。这一点对于很多序列到序列(Seq2Seq)的预测任务尤为关键。
RNN及其变种LSTM和GRU曾是序列模型的核心,专为顺序处理数据和捕捉时间序列依赖而设计。不过,它们面临几个关键挑战,这些挑战限制了其效能和效率:
难以理解长期关联:
-
梯度消失问题:在反向传播时,RNN面临梯度逐渐减小直至消失的问题,这使得模型难以学习序列中远距离元素间的关系。
-
梯度爆炸问题:另一方面,梯度可能会急剧增加,引发梯度爆炸问题,这会破坏学习过程的稳定性。
顺序处理的局限:
- 固有的顺序处理机制限制了并行处理的可能性,导致处理长序列时训练和推理速度缓慢。
计算和内存负担:
-
高计算需求:RNN,LSTM和GRU因其复杂结构而计算量巨大,这些结构旨在解决梯度消失问题。
-
内存限制:维护长序列的隐藏状态需要大量内存,这对扩展性构成了挑战。
想象一个简单的任务,RNN需要预测句子中的下一个单词。如果RNN在尝试预测之前只看到了一个词,那么它猜对的可能性不高。如果我们通过让它观察更多之前的词来提高其预测能力,我们就需要更多的计算资源。但即使有了更多资源和数据,RNN依然面临困难,因为它需要完整理解整个句子乃至整篇文章来准确预测。仅依赖观察前几个词是不够的,它需要全面理解上下文。
①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
02
Transformer的解决方案
Transformer模型的推出,正是Vaswani在其里程碑式的论文《Attention is All You Need》中所做的工作,这一创新不仅突破了传统限制,还为解决RNN面临的问题提供了解决方案。
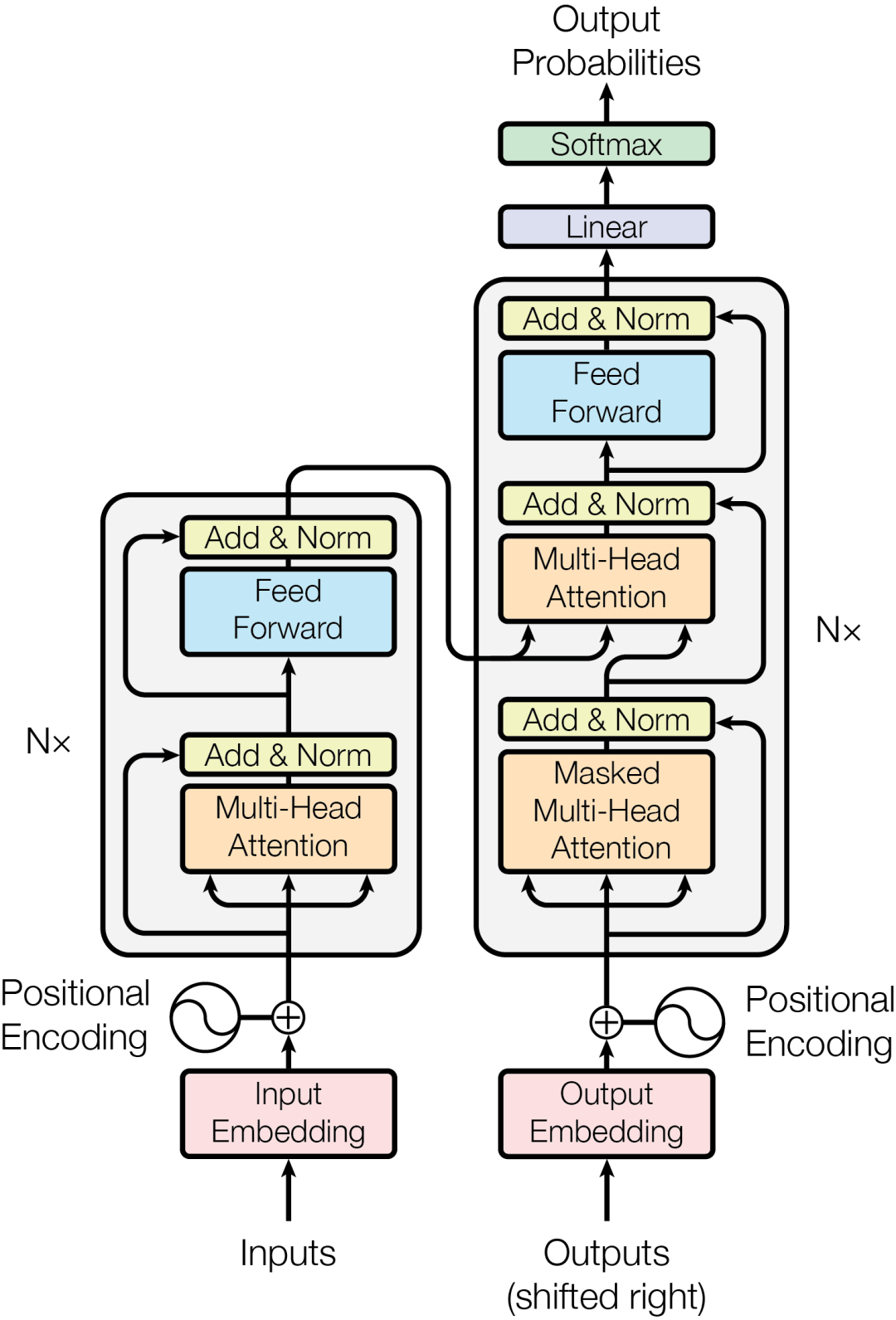
Transformer架构包括编码器和解码器两部分,每部分都含有多个层,这些层集成了多头自注意力机制和前馈神经网络,共同工作以提升处理效率和性能。
Transformer的工作方式是同时处理句子中的全部词序,而不是像RNN那样,一次只处理一个词。这种处理机制让Transformer在捕捉句子内词语之间的上下文关系和相互作用方面更为出色,对于理解人类语言来说,这一点极为关键。
此外,Transformer采用了一种名为自注意力(self-attention)的技术,能够对句中各词赋予不同的权重,并集中关注对完成特定任务最关键的词语。正是这种机制,使得Transformer能够灵活应对各种任务,并且达到非常高的准确度。
RNN vs Transformer
Transformer解决了RNN的几个关键问题,并提供了更高效和更强大的解决方案:
并行处理与效率提升:
-
自注意力机制:与RNN不同,Transformer通过自注意力机制评估输入数据各部分的重要性,实现对序列更加精细的理解。
-
并行化能力:Transformer架构支持数据的并行处理,大幅提高了训练和推理速度。
解决长期依赖问题:
- 全局上下文感知:得益于自注意力机制,Transformer能够同时处理整个序列,有效地捕捉长期依赖,避免了顺序处理的限制。
可伸缩性与灵活性:
-
降低内存需求:通过去除循环连接的需求,Transformer减少了内存使用,提高了模型的可伸缩性和效率。
-
高度适应性:Transformer的架构包含了堆叠的编解码器,这种设计使其不仅在自然语言处理领域,在计算机视觉和语音识别等多个领域也能发挥出色的适应性。
|
|
RNN |
Transformer |
|
处理方式 |
顺序处理 |
并行处理 |
|
长上下文理解 |
难以捕捉长依赖 |
通过自注意力机制捕捉长依赖 |
|
可伸缩性 |
差 |
好 |
|
应用领域 |
自然语言处理 |
自然语言处理、计算机视觉、语音识别等 |
|
训练速度 |
慢 |
快 |
自注意力机制
注意力机制的精髓在于,它让模型能够在执行任务时专注于输入序列的不同部分,正如人们在处理信息时会更加关注某些特定的词或物体。这一机制极大地提升了模型把握数据上下文和内在联系的能力。
注意力机制基于查询(Queries),键(Keys),值(Values)三个向量运作,这些向量源自输入数据,查询和键的相互作用决定了模型对输入的各个部分的关注程度,而值则承载了实际要处理的信息。
注意力权重用来评估输入数据各部分之间的相关性,指导模型应更多关注哪些部分。
自注意力,作为一种特殊的注意力机制,让模型能够评估输入数据各部分之间的相对重要性。它是Transformer架构的基础,使得模型能够高效地并行处理数据序列,这是之前按顺序处理数据的模型所不具备的。
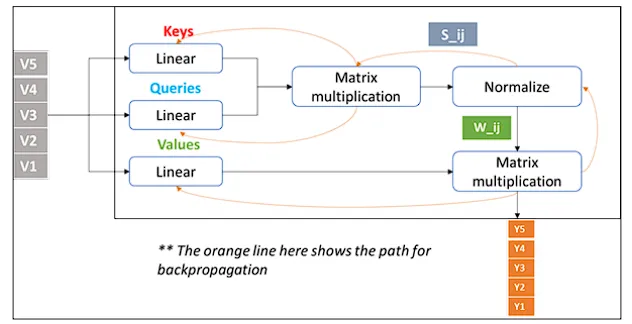
自注意力实现了输入数据所有部分的同时处理,显著提升了训练速度和效率。而且,它能够无视位置距离,捕捉序列元素间的关系,克服了如RNN和LSTM这类早期模型的主要局限。
模型不仅关注每个单词,还会评估每个单词与其他单词之间的关系,并对这些关系赋予注意力权重,从而学习每个单词与其他单词之间的相关性。
注意力及其映射
假设你在看一张公园里有许多狗和人的图片,如果要你找出所有黄色的球,你的大脑会自动聚焦于可能有黄色球的地方,忽略掉大部分狗和人。这种聚焦机制类似于机器学习中的注意力机制,它帮助模型专注于对当前任务(本例中为黄色球)重要的数据部分,而忽略不相关的信息(如狗和人)。
注意力图类似于一个展示你在寻找黄色球时关注点的地图,它会突出显示黄色球的区域并淡化其他部分。在机器学习中,注意力图直观地显示了模型在数据中的关注焦点,以做出决策或预测。因此,在上述示例中,注意力图会突出显示模型认为对找到黄色球重要的输入部分,帮助我们理解模型做出决策的逻辑。
机器学习模型把数字视为语言,但不直接理解文字,因此我们需要通过标记化过程将文字转换为数字,即为每个单词分配一个基于模型已知的所有单词列表的唯一数字,使模型能够理解和处理文本。
文本输入被数字化后,就可以传递给嵌入层,将每个单词(或Token)转换为一个称为向量的数字列表。这些向量通过训练过程调整,随着模型从数据中学习,调整这些数字以提高其任务执行能力,这个过程称为“可训练的向量嵌入(Embedding)”,是使计算机能够理解和从中学习的文字表示方式。
一旦得到嵌入,就可以将其传递给自注意力层,该层分析输入序列中标记之间的关系,优化模型对数据的处理和理解能力。
多头自注意力
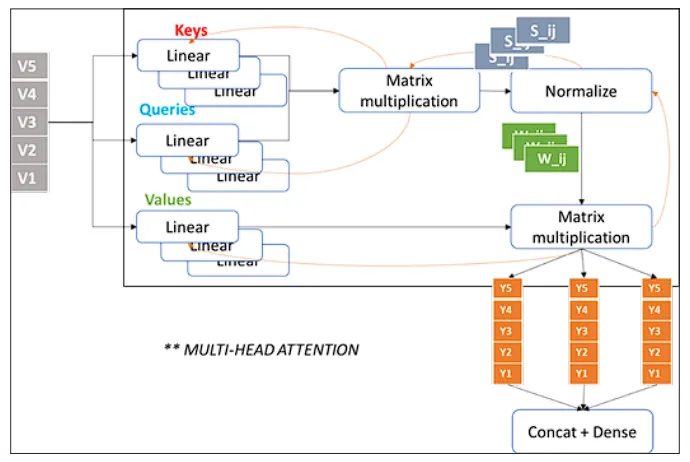
设想你在一个拥挤的公交车上,努力听朋友讲故事,你的大脑能自动关注到他所说的关键词,同时留意周围的环境声,譬如有人叫你的名字或是公交车到站播报声。
多头自注意力机制在计算机中实现了类似的功能。它使得模型能够同时关注句子或图像的多个部分,不仅抓住主旨,同时也能从多角度捕捉上下文和微妙之处。
这种技术仿佛为机器学习模型装配了一系列专业的“透镜”,每个“透镜”或“头”关注数据的不同维度。因此,在Transformer模型中,多头自注意力赋予了模型深入理解输入信息的能力。
这项技术的作用远不止于识别句子中的下一个词汇;它涉及到把握整个句子的含义,理解各个词汇间的关联,甚至识别讽刺或强调等语言细节。这让Transformer在执行语言翻译、文章摘要编写或生成逼真文本等任务上展现出了强大的能力。
在训练期间,模型通过学习并储存在各层的自注意力权重来识别输入序列中每个词对于序列中其他所有词的重要性。这个过程不止进行一次。实际上,模型会并行地学习多组自注意力权重,也就是所谓的“头”,而这些头彼此之间是独立的。
预测过程
在机器学习模型中,自注意力机制负责捕捉语言的各种特性,每个部分关注不同的语言特征。比如,某部分可能探寻句子中字符间的关系,另一部分关注动作发生的情况,还有的部分可能识别单词的发音相似性。有趣的是,这些自注意力“头”的关注点并非预设,而是从随机开始,通过处理大量数据并自我学习,自然而然地识别出各种语言特征。它们学习到的一些特征我们能够理解,如前所述的例子,但有些则更加难以捉摸。
模型对输入数据应用了所有这些注意力机制后,接下来会通过一个全连接层进行处理,生成一个与模型词汇表中每个词作为下一词出现的可能性相关的数值列表(即logits)。随后,这些数值通过softmax层转换成概率,给模型词汇表中的每个单词一个表示其作为下一词出现概率的分数。虽然会有成千上万个这样的分数,但通常情况下,某个单词的分数会比其他单词高,成为模型预测下一词的首选。
03
总结
Transformer模型极大地推动了自然语言处理(NLP)的发展,它为处理语言提供了一种更加高效和有效的架构,使得开发像GPT和PaLM这样强大的大型语言模型成为可能。
不仅如此,Transformer模型还展示了机器学习模型在处理序列数据方面的强大能力,为其他相关领域如语音识别、图像字幕和推荐系统等提供了新的思路和工具。因此,Transformer模型在人工智能和机器学习领域具有深远的影响,它为更智能、更高效和更准确的模型开发铺平了道路。
第二篇:ChatGPT背后强大而神秘的力量:用最简单的语言讲解Transformer架构之Embedding

本系列文章致力于用最简单的语言讲解Transformer架构,帮助朋友们理解它的强大力量。
本文是第二篇:**词嵌入,**它是Transformer的初始输入形式。
点击这里看第一篇:概览。
词嵌入(Word embedding)也有人叫做词向量,本文统一称做词嵌入。
目录
_1. 词嵌入介绍
_
2. 词嵌入的实现方法
_2.1 稀疏表示法_
_2.1.1 词袋模型_
_2.1.2 词频-逆文档频率(TF-IDF)_
_2.2 密集向量表示法_
_2.2.1 Word2Vec_
_2.2.2 GloVe_
_2.2.3 OpenAI Transformer嵌入_
3. 词嵌入相似度计算方法
_3.1 欧几里得距离(L2)_
_3.2 曼哈顿距离(L1)_
_3.3 点积_
_3.4 余弦距离_
4. 总结
01
词嵌入介绍
众所周知,计算机是“用数字来思考”的,无法自动掌握单词和句子的意义,如果我们想让计算机理解自然语言,就需要把这些信息转换成计算机能够处理的格式,即数字向量。
人类很早以前就学会了怎样把文本转换为机器能理解的格式,其中最早的一种格式是ASCII,这种方式虽然在文本渲染和传输方面有效,但却无法传递词汇的深层含义,那个时代,标准的搜索技术是基于关键词的搜索,即查找包含特定单词或词组的所有文档。
词嵌入技术的出现彻底改变了这一格局,通过将单词、句子甚至图像转化为数字向量,它不仅仅改善了文本的表示方式,更重要的是,它捕捉到了语言的本质和丰富的语义;这一创新使得语义搜索成为可能,让我们能够精准地理解和分析不同语言的文档,通过探索这些高级的数值表示形式,我们能够洞察计算机是如何开始理解人类语言的细微差别的,这一进步正在改变我们在数字时代处理信息的方式。
今天,词嵌入技术也是LLM的核心技术之一,也是Transformer的初始输入形式。
02
词嵌入的实现方法
稀疏表示法(Sparse Representations)
词袋模型
文本转换成向量的一种基础方法是词袋模型,它将文档视为一组不考虑顺序的单词集合。
词袋模型中,每个单词都被视为一个“词元”,文档中的每个词元都被赋予一个唯一的数字ID,然后,我们可以使用一个向量来表示文档,其中向量的每个维度代表一个词元,向量的每个元素表示该词元在文档中出现的次数。
我们可以利用NLTK Python库来完成这一任务,如下是费曼的一句著名引语生成的词袋模型的词嵌入,”We are lucky to live in an age in which we are still making discoveries“(我们很幸运生活在一个仍在不断发现新事物的时代)。

代码实现:
from nltk.stem import SnowballStemmer
from nltk.tokenize import word\_tokenize
import collections
text = 'We are lucky to live in an age in which we are still making discoveries'
# tokenization - splitting text into words
words = word\_tokenize(text)
print(words)
# \['We', 'are', 'lucky', 'to', 'live', 'in', 'an', 'age', 'in', 'which',
# 'we', 'are', 'still', 'making', 'discoveries'\]
stemmer = SnowballStemmer(language = "english")
stemmed\_words = list(map(lambda x: stemmer.stem(x), words))
print(stemmed\_words)
# \['we', 'are', 'lucki', 'to', 'live', 'in', 'an', 'age', 'in', 'which',
# 'we', 'are', 'still', 'make', 'discoveri'\]
bag\_of\_words = collections.Counter(stemmed\_words)
print(bag\_of\_words)
# {'we': 2, 'are': 2, 'in': 2, 'lucki': 1, 'to': 1, 'live': 1,
# 'an': 1, 'age': 1, 'which': 1, 'still': 1, 'make': 1, 'discoveri': 1}
词频-逆文档频率(TF-IDF)
相比词袋方法,TF-IDF(词频-逆文档频率)是一种略有改进的版本,它通过两个指标的乘积来实现。
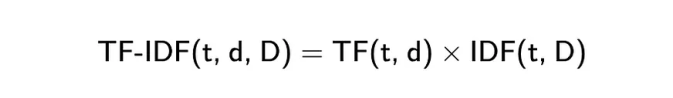
词频(TF)是衡量一个词在文档中出现频率的基本指标,它是评价单词在文档内重要性的简单方法;计算词频时,我们会计算特定词汇在文档中出现的次数,并将其除以文档中的总词数,这样做的目的是为了消除不同文档长度带来的影响。

逆文档频率(IDF)是一个用来评估一个词在整个文档集或语料库中重要性的指标,它帮助我们了解一个词在所有文档中是常见的还是罕见的。
计算这个指标时,我们会用语料库中的文档总数除以含有该词的文档数,然后取这个比值的对数;这样的计算方法降低了那些在众多文档中频繁出现的词的重要性,认为这些词相对不太重要;这个计算过程有助于我们更好地理解和评估不同词汇在文档集中的独特性和重要性。

代码实现:
from sklearn.feature\_extraction.text import TfidfVectorizer
def compute\_tfidf(documents):
vectorizer = TfidfVectorizer()
return vectorizer.fit\_transform(raw\_documents=documents)
if \_\_name\_\_ == "\_\_main\_\_":
docs = \[
"I love natural language processing",
"In natural language processing, the sentences are represented as embeddings or vectors",
"The distance between the embedding vectors gives the contextual meaning between them"
\]
result = compute\_tfidf(documents=docs)
print(result.toarray()
密集向量表示法(Dense Vector Representations)
Word2Vec
Word2Vec是一种划时代的技术,它通过神经网络生成词嵌入,能够捕捉单词间的语义关系,更真实地反映出单词在语言中的使用和意义。
它通过在大规模文本语料库上的训练,能够理解单词间复杂的关系,如同义词、反义词和关联词,这些都是通过向量空间的几何属性来实现的。
Word2Vec使用一个简单的双层神经网络来从大量文本中学习单词之间的联系,其设计基于假设出现在相似语境中的单词在语义上是相似的,这一原则主要通过两种训练算法实现:连续词袋(CBOW)和Skip-Gram,它们主要在处理单词上下文的方法上有所区别。
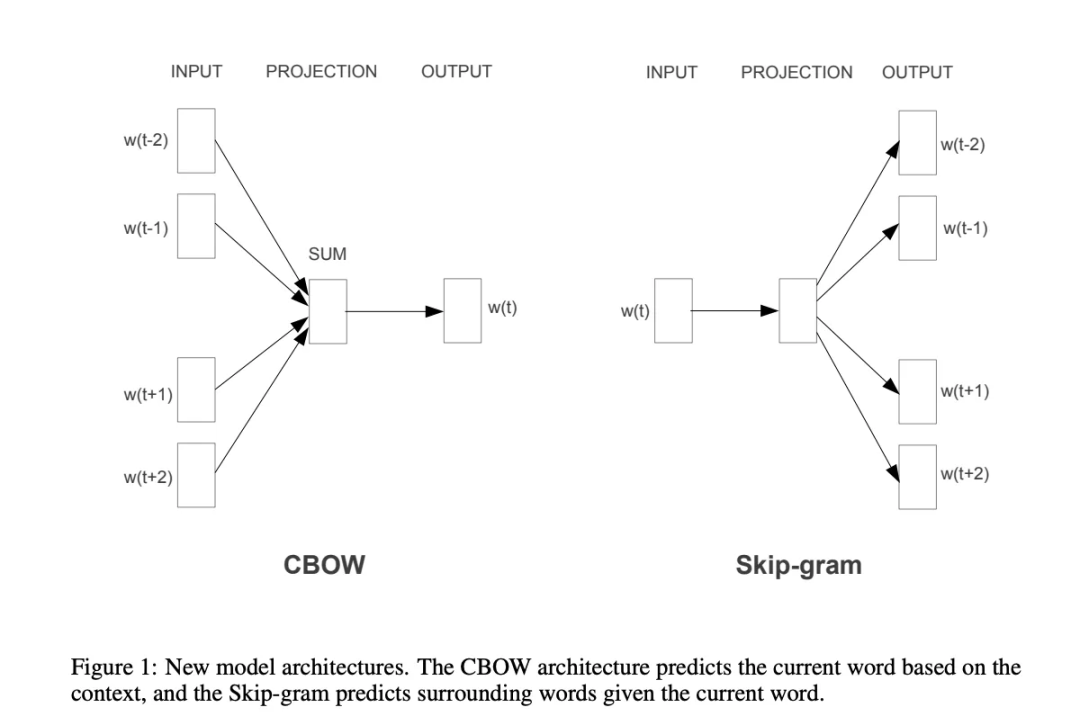
CBOW通过给定的上下文来预测目标单词。上下文是指目标单词周围的单词窗口,例如,在句子“The cat sits on the mat”中,若以“sits”为目标词,并选择周围各2个单词作为窗口,上下文就是[“The”, “cat”, “on”, “the”, “mat”]。
它以上下文中的单词为输入,合并它们的向量,然后使用这个综合向量来预测目标单词,并通过调整单词向量来减少预测目标单词时的误差。
Skip-Gram采取与CBOW相反的逻辑,它使用目标单词来预测周围的上下文单词,以“sits”为目标单词,其目标是预测[“The”, “cat”, “on”, “the”, “mat”]这样的上下文单词。
它针对每一个目标单词,使用它的向量来预测特定范围内的上下文单词向量,其目标是调整单词向量,以提高上下文单词预测的准确率。
从性能方面来说,CBOW运行更快,对常见词的准确性略优于Skip-Gram;而Skip-Gram虽然运行较慢,但对于不常见的词汇和小型数据集来说,表现更佳,因为它为每个单词提供了更多的训练样本。
从训练目标来说,CBOW通过平均上下文单词向量,模糊了一些分布信息,这对于表示高频词汇较为有利;而Skip-Gram将每一对上下文-目标视为独立的观察,因此它能够更好地捕捉各种关系,尤其是对于低频词汇。
代码实现:
from gensim.utils import simple\_preprocess
from gensim.models import Word2Vec
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
def compute(documents):
# preprocessing the text by tokenization, stemming
processed\_docs = \[simple\_preprocess(document) for document in documents\]
# train using Word2Vec, sg=0 is CBoW model
model\_cbow = Word2Vec(sentences=processed\_docs, window=5, vector\_size=100, workers=5, min\_count=1, sg=0)
# train using Skip-Gram, sg=1 is Skip-Gram model
model\_skip\_gram = Word2Vec(sentences=processed\_docs, window=5, vector\_size=100, workers=5, min\_count=1, sg=1)
# Get the vector for a word from the CBOW model
vector\_cbow = model\_cbow.wv\['language'\]
# Get the vector for a word from the Skip-Gram model
vector\_skipgram = model\_skip\_gram.wv\['language'\]
return model\_cbow, model\_skip\_gram
def visualize(model: Word2Vec):
# Retrieve word vectors and corresponding word labels from the model
word\_vectors = model.wv.vectors
words = model.wv.index\_to\_key # List of words in the model
# Use t-SNE to reduce word vectors to 2 dimensions for visualization,
# this is like dimensionality reduction, similar to PCA
tsne = TSNE(n\_components=2, random\_state=0)
word\_vectors\_2d = tsne.fit\_transform(word\_vectors)
# Plotting the 2D word vectors with annotations
plt.figure(figsize=(10, 10))
for i, word in enumerate(words):
plt.scatter(word\_vectors\_2d\[i, 0\], word\_vectors\_2d\[i, 1\])
plt.text(word\_vectors\_2d\[i, 0\] + 0.03, word\_vectors\_2d\[i, 1\] + 0.03, word, fontsize=9)
plt.show()
if \_\_name\_\_ == "\_\_main\_\_":
# Sample dataset: Expressing liking, love, and interest in NLP
sentences = \[
"The brilliant data scientist loves exploring the depths of NLP techniques.",
"I find immense joy in unraveling the mysteries behind language models.",
"NLP enthusiasts are fascinated by the way algorithms understand human language.",
"There's a certain beauty in teaching machines to interpret the nuances of words.",
"Discovering new applications for text embeddings fills me with excitement.",
"The passion for semantic analysis drives researchers to innovate.",
"She adores the challenge of making computers comprehend linguistic subtleties.",
"Our team is dedicated to advancing the frontiers of NLP with each project.",
"The breakthrough in sentiment analysis has captured the interest of many.",
"Witnessing the evolution of NLP technologies sparks a profound sense of wonder."
\]
cbow\_model, skip\_gram\_model = compute(documents=sentences)
visualize(cbow\_model
词嵌入可视化:
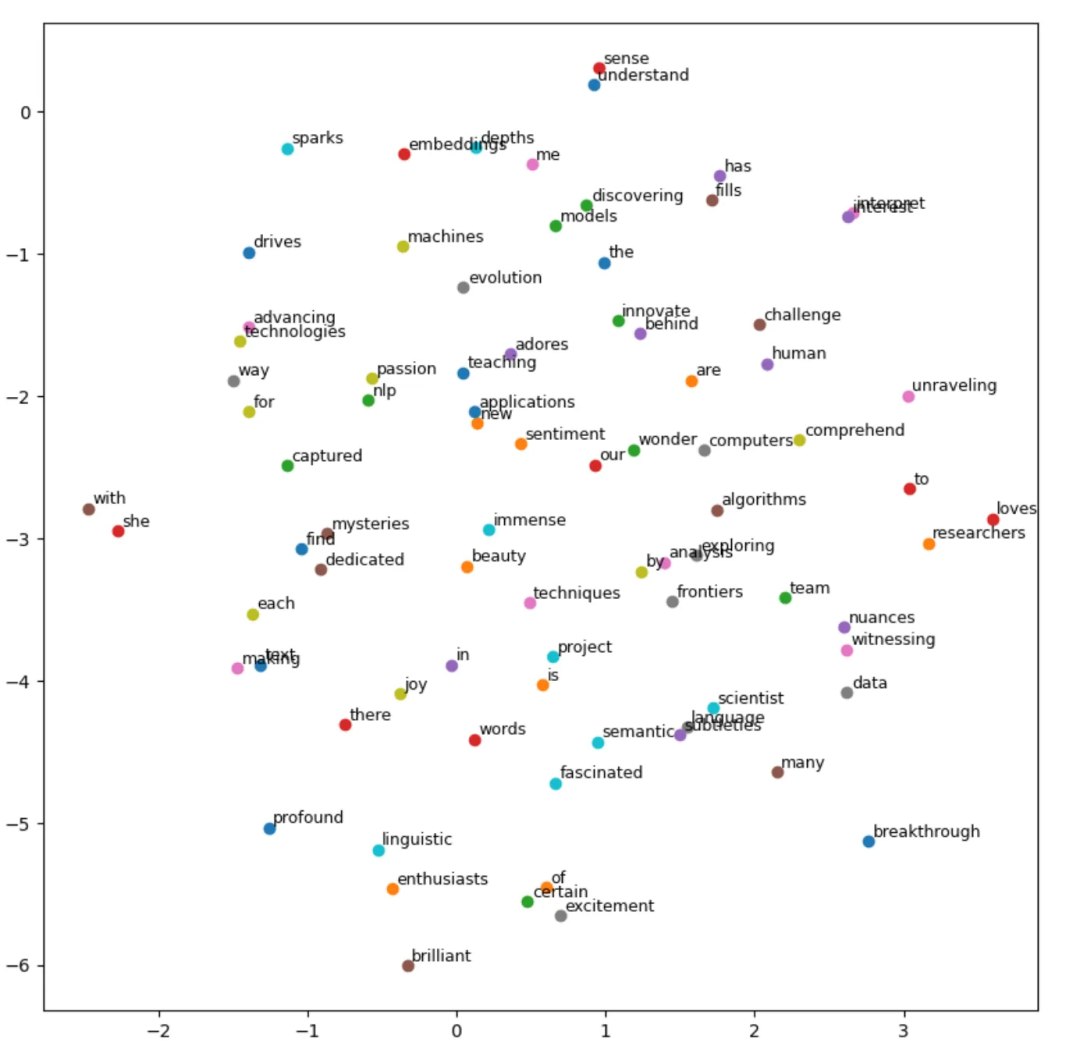
GloVe
GloVe(全局词向量表示)是斯坦福大学研究人员开发的一种无监督学习模型,专门用于创建单词的向量表示;不同于传统模型那样仅仅基于单词共现次数,GloVe模型通过考虑这些次数的比率来揭示单词之间的语义联系,这一点使其能够同时捕捉语言的局部和全局统计特性。
GloVe的核心优势在于它能够通过分析词共现的概率来识别语义关系,采用一种混合方法结合了全局矩阵分解和局部上下文窗口技术,为词汇提供全面的表示。
此外,其可扩展性强,能够处理大规模语料库和庞大的词汇量,非常适合于分析网络级别的数据集。
代码实现:
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
# Path to the downloaded GloVe file (change as needed)
glove_input_file = 'glove.6B.100d.txt'
# Output file in Word2Vec format
word2vec_output_file = 'glove.6B.100d.word2vec.txt'
# Convert GloVe format to Word2Vec format
glove2word2vec(glove_input_file, word2vec_output_file)
# Load the converted model
model = KeyedVectors.load_word2vec_format(word2vec_output_file, binary=False)
# Example: Retrieve the vector for the word 'computer'
word_vector = model['language']
print(word_vector)
# Perform similarity operations
print(model.most_similar('language'))
OpenAI Transformer嵌入
OpenAI能够生成信息丰富的密集向量(Dense Vector),并成为现代语言模型的主流技术。
OpenAI允许你使用同一个“核心”模型,并根据不同的使用案例进行微调,无需重新训练核心模型(这会耗费大量时间和成本),这促成了预训练模型的兴起;这些模型属于GPT系列,包括GPT-3及其最新迭代,这些都可以通过OpenAI的API获得。
Google AI的BERT(Bidirectional Encoder Representations from Transformers)是首批流行模型之一,text-embedding-3-small和text-embedding-3-large是最新也是性能最强的嵌入模型,它们引入新的参数,允许用户控制模型的整体大小。
代码实现:
from openai import OpenAI client = OpenAI() def get_embedding(text, model="text-embedding-3-small"): text = text.replace("\n", " ") return client.embeddings.create(input = [text], model=model)\ .data[0].embedding get_embedding("We are lucky to live in an age in which we are still making discoveries.")
03
词嵌入相似度计算方法
词嵌入本质上是向量,因此,如果我们想了解两个单词或句子在语义上的接近程度,我们可以计算向量之间的距离,距离越小,语义意义上越接近。
有几种不同的度量方法可以用来衡量两个向量之间的距离:
-
欧几里得距离(L2)
-
曼哈顿距离(L1)
-
点积
-
余弦距离
下面我们将讨论这些方法,作为一个简单的例子,我们将使用两个二维向量A=(1,4)和B=(2,2)。
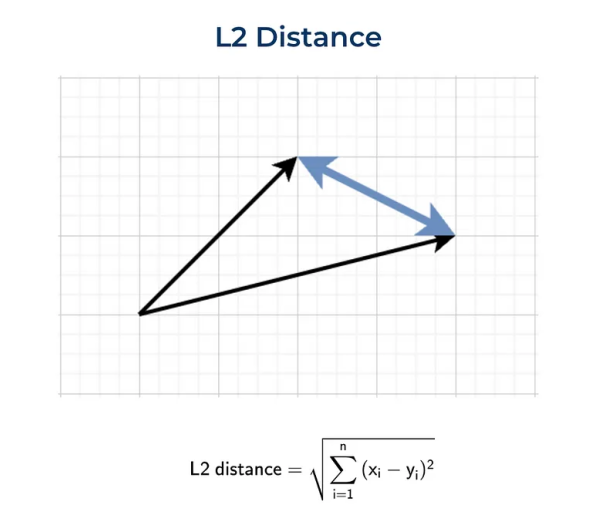
欧几里得距离(L2)
定义两点(或向量)之间距离的最标准方法是欧几里得距离,也称为L2范数,它是我们日常生活中最常用的度量方法,例如,当我们谈论两个城镇之间的距离时。
代码实现:
import numpy as np sum(list(map(lambda x, y: (x - y) ** 2, vector1, vector2))) ** 0.5 # 2.2361 np.linalg.norm((np.array(vector1) - np.array(vector2)), ord = 2) # 2.2361
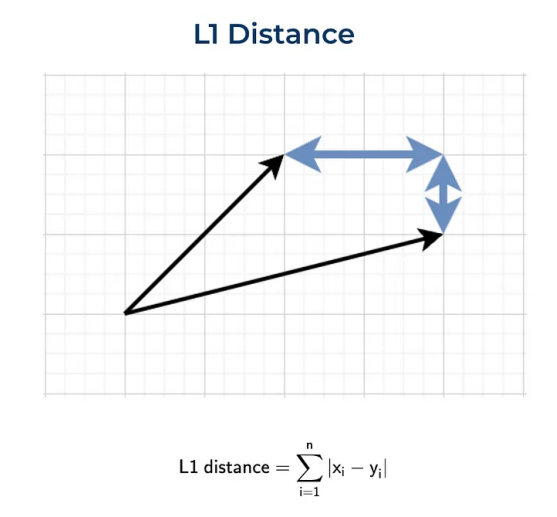
曼哈顿距离(L1)
曼哈顿距离,也称为L1范数。这个名称来源于纽约的曼哈顿,因为这个岛有一个街道网格布局,而在曼哈顿两点之间的最短路线将是L1距离,因为你需要遵循街道网格。
代码实现:
sum(list(map(lambda x, y: abs(x - y), vector1, vector2))) # 3 np.linalg.norm((np.array(vector1) - np.array(vector2)), ord = 1) # 3.0
点积
点积或标量积,它的公式如下。
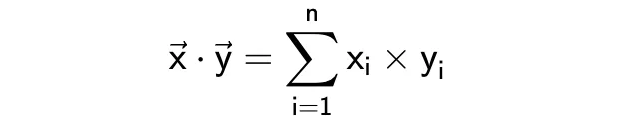
这个度量有点难以解释,一方面,它表明了向量是否指向同一方向;另一方面,结果很大程度上依赖于向量的大小;
例如,让我们计算两对向量之间的点积:
-
对于向量A=(1,1)和B=(1,1),它们的点积计算结果是1∗1+1∗1=2。
-
当我们考虑另一对向量C=(1,1)和D=(10,10)时,点积为1∗10+1∗10=20。
尽管这两对向量在方向上保持一致,但由于它们的大小存在差异,导致它们的点积有很大的不同。这就解释了为什么在进行向量比较时,点积并非总是最合适的选择。
代码实现:
sum(list(map(lambda x, y: x*y, vector1, vector2))) # 11 np.dot(vector1, vector2) # 11
余弦距离
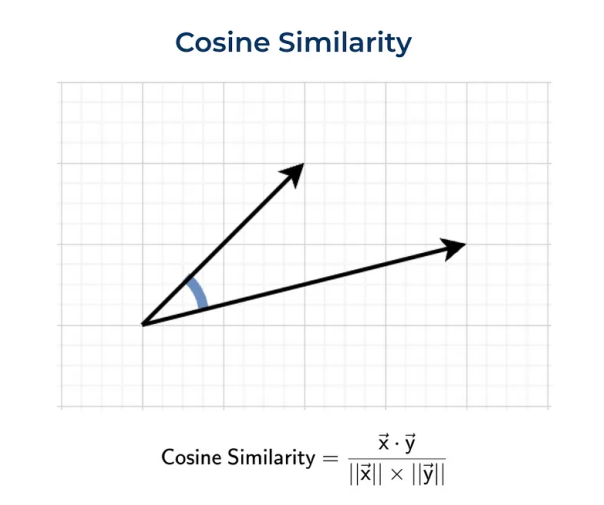
余弦距离,不同于点积,它衡量的是两个向量之间的角度差异,而非它们的长度,这使得它特别适用于比较文档或句子的相似性,因为它不会受到文档长度的影响。
余弦相似度的值范围是从-1到1,值越接近1,表示两个向量的方向越相似;值为0,则表示它们是正交的;而值为-1,则表示它们方向完全相反。
通过计算向量之间的余弦相似度,我们可以更精确地评估它们在语义上的相似度,而不仅仅是比较它们的数值大小或直线距离。
代码实现:
dot_product = sum(list(map(lambda x, y: x*y, vector1, vector2))) norm_vector1 = sum(list(map(lambda x: x ** 2, vector1))) ** 0.5 norm_vector2 = sum(list(map(lambda x: x ** 2, vector2))) ** 0.5 dot_product/norm_vector1/norm_vector2 # 0.8575 from sklearn.metrics.pairwise import cosine_similarity cosine_similarity( np.array(vector1).reshape(1, -1), np.array(vector2).reshape(1, -1))[0][0] # 0.8575
04
总结
总的来说,从基本的频率统计演变到深度学习的上下文表征,无论是TF-IDF的统计见解,Word2Vec和GloVe捕捉的语义深度,还是OpenAI提供的先进的、有上下文感知的词嵌入技术,都逐步提升了语义分析工具,为自然语言处理开辟了新道路。
这一系列进展不仅凸显了词嵌入技术在文本理解中的重要性,也彰显了自然语言处理技术不断的创新,为我们处理更加复杂和精细的语言应用提供了可能,如聚类、分类、异常检测和检索式生成网络(RAG)等。
第三篇:ChatGPT背后强大而神秘的力量,用最简单的语言讲解Transformer架构之Tokenizer

本系列文章致力于用最简单的语言讲解Transformer架构,帮助朋友们理解它的强大力量,本文是第三篇:分词(Tokenizer);在上一篇文章Embedding中,我们介绍了Transformer架构中的Embedding,它将输入的文本转换为模型可以理解的数字向量,而分词是Embedding之前非常重要的一个步骤。
在接下来的文章中,将详细讲解分词的流程,算法以及Transformer,GPT中用到的分词算法。
目录
1. 分词介绍
2. 分词流程
_2.1 Normalization_
_2.2 Pre-tokenization_
_2.3 Model_
_2.4 Post-tokenization_
3. 分词算法
_3.1 Byte Pair Encoding (BPE)_
_3.2 WordPiece_
_3.3 Unigram LM_
_3.4 SentencePiece_
4. 总结
01
分词介绍
分词是Transformer架构中Embedding之前非常重要的一步。
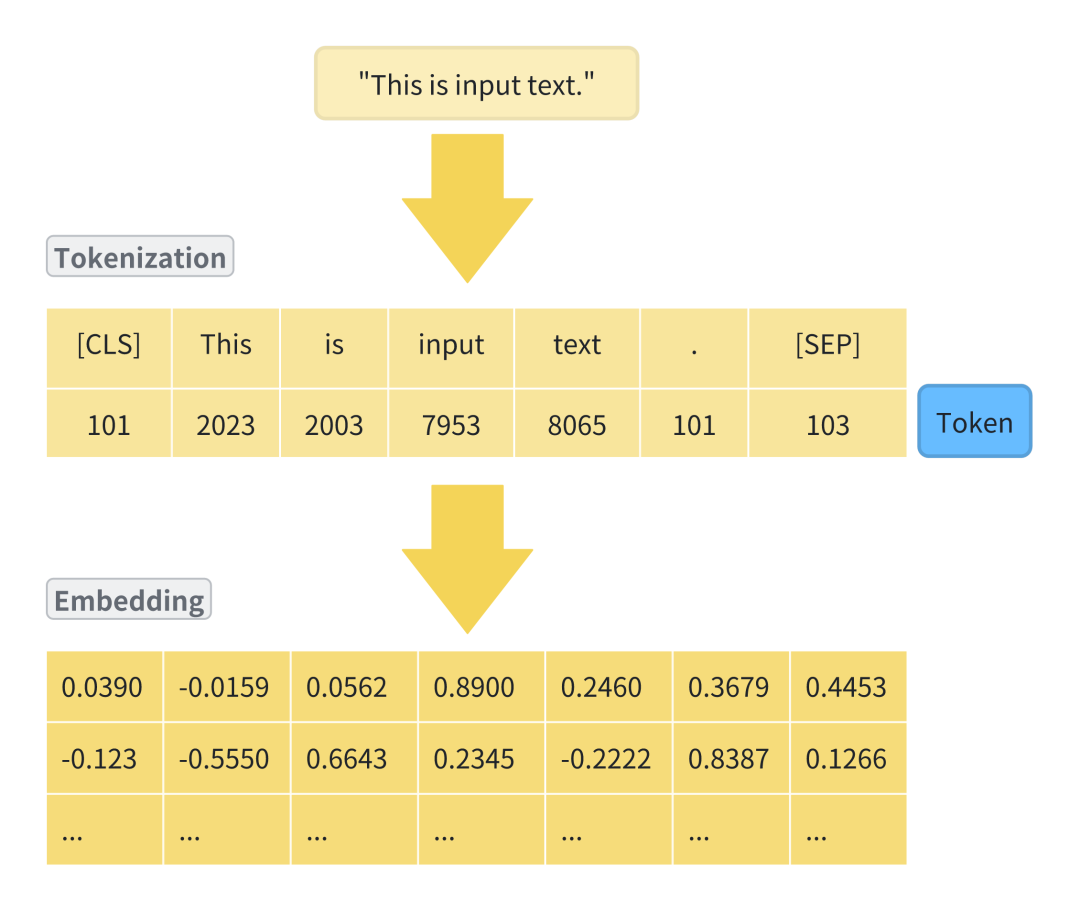
它将文本拆分为模型或机器可以处理的小单位,并分配一个唯一的标识符(Token);就像我们学习外语时,首先要学习字母和单词一样,分词是模型或机器学习语言的第一步。


分词可视化工具,请访问https://tiktokenizer.vercel.app/
02
分词流程
分词的流程通常包括Normalization, Pre-tokenization, Model和Post-tokenization。
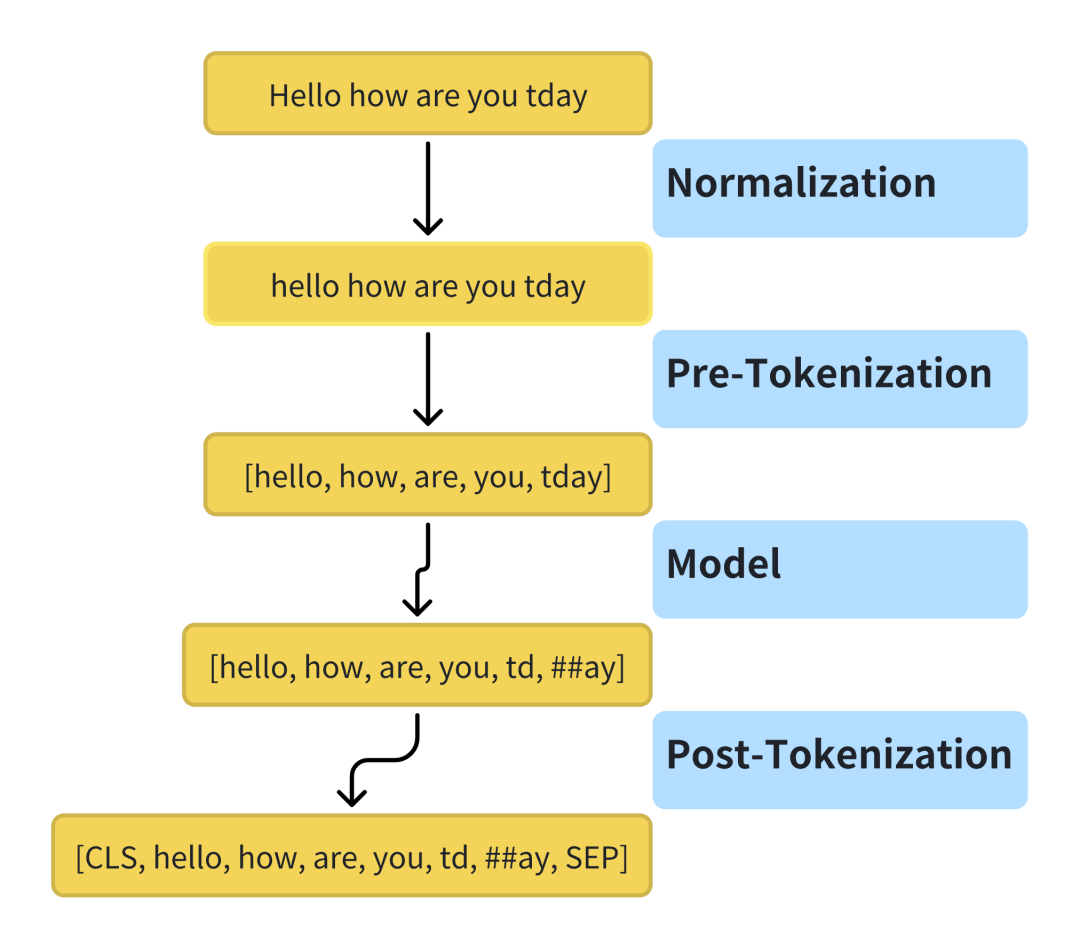
Normalization
Normalization主要包括以下几个方面:
-
文本清洗
-
去除无用字符:移除文本中的特殊字符、非打印字符等,只保留对分词和模型训练有意义的内容。
-
去除额外空白:消除文本中多余的空格、制表符、换行符等,统一文本格式。
-
标准化写法
-
统一大小写:将所有文本转换为小写或大写,减少大小写变体带来的影响。
-
数字标准化:将数字统一格式化,有时候会将所有数字替换为一个占位符或特定的标记,以减少模型需要处理的变量数量。
-
编码一致性
-
字符标准化:确保文本采用统一的字符编码(如UTF-8),处理或转换特殊字符和符号。
-
语言规范化
-
词形还原(Lemmatization):将单词还原为基本形式(lemma),例如将动词的过去式还原为一般现在时。
-
词干提取(Stemming):去除单词的词缀,提取词干,这是一种更粗糙的词形还原方式。
Pre-tokenization
Pre-tokenization是基于一些简单的规则(如空格和标点)进行初步的文本分割,这一步骤是为了将文本初步拆解为更小的单元,如句子和词语;对于英文等使用空格分隔的语言来说,这一步相对直接,但对于中文等无空格分隔的语言,则可能直接进入下一步。
Model
Model是分词的核心部分,在Pre-tokenization的基础上,根据选定的模型或算法(BPE,WordPiece,Unigram语言模型(LM)或SentencePiece等)进行更细致的处理,包括通过大量文本数据,根据算法规则生成词汇表(Vocabulary), 然后依据词汇表,将文本拆分为Token。
在自然语言处理模型中,确定合适的词汇表大小是一个关键步骤,它直接影响模型的性能、效率以及适应性;理想的词汇表应该在保证模型性能和效率的同时,满足特定任务和数据集的需求。
较大的词汇表意味着模型需要更多的计算资源来处理和存储分词嵌入,在资源有限的环境下,过大的词汇表可能导致训练和推理过程变得低效。
词汇表的大小也会影响模型的处理速度,较大的词汇表可能增加模型在进行词嵌入查找和生成输出时的计算负担,从而减慢处理速度。
较大的词汇表可以提高模型覆盖不同词汇和表达的能力,有助于模型更好地理解和生成文本;然而,过大的词汇表也可能导致模型在某些Token上的训练不足,影响其泛化能力。
一个庞大的词汇表可能导致词嵌入空间的稀疏性问题,使得模型难以有效学习某些较少见的Token的表示。
不同的自然语言处理任务可能需要不同大小的词汇表。例如,精细的文本生成任务可能需要较大的词汇量以覆盖更多细节,而一些分类任务则可能只需较小的词汇表即可达到较高性能。
特定任务可能需要引入特殊Token(如控制代码,隐私标记等,这些在LLM如何通过监督学习使用Tools中有应用到),这也需要在设置词汇表时考虑。
不同语言的结构差异意味着对词汇表的需求也不同。例如,拼接语(如德语)可能需要更大的词汇量来覆盖其丰富的复合词形态。
数据集中文本的复杂性和多样性也影响词汇表的设置,丰富多变的数据集可能需要更大的词汇量来捕获文本的多样性。
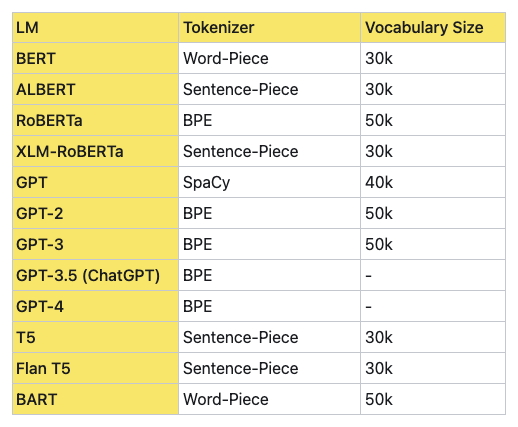
如上所述,在实际应用中,可能需要通过实验和调整来找到最适合特定模型和任务的词汇表大小,下面是各大LLM词汇表的大小和性能对比:
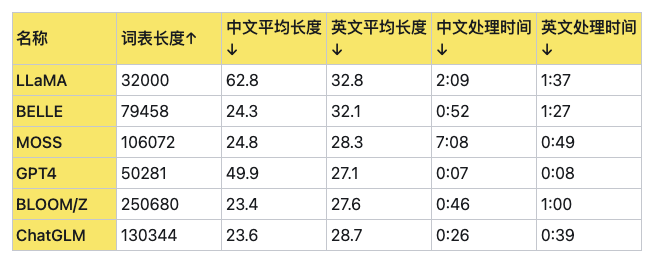
Post-tokenization
Post-tokenization主要包括:
-
序列填充与截断:为保证输入序列的长度一致,对过长的序列进行截断,对过短的序列进行填充。
-
特殊Token添加:根据模型需求,在序列的适当位置添加特殊Token(如[CLS], [SEP])。
-
构建注意力掩码:对于需要的模型,构建注意力掩码以区分实际Token和填充Token。
03
分词算法
Tokenizer按粒度分,常见的有:
-
按单词划分(word base): 按照词进行分词, 如英文Today is sunday. 则根据空格或标点进行分割[today, is, sunday, .]
-
按字符划分(character base):按照单字符进行分词,就是以char为最小粒度, 如英文Today is sunday. 则会分割成[t, o, d,a,y,i, s, s,u,n,d,a,y,.]
-
按子单词划分(subword tokenization):按照词的subword进行分词,如英文Today is sunday. 则会分割成[to, day,is , s,un,day, .]
按单词划分简单易理解,每个word都分配一个ID,所需的词汇表会根据语料库大小而不同,而且这种分词方式,会将两个本身意思一致的词分成两个毫不同的ID,在英文中尤为明显,如cat,cats。
按字符划分,此种现象会有所减缓,而且词汇表相对小的多,但分词后的每个char字符是毫无意义的,而且输入的长度变长不少,只有合并后才有意义,这种分词在模型的初始character embedding是无意义的,英文中尤为明显,但中文是较为合理的,在中文中用得比较多。
最后,为了平衡以上两种方法, 提出了subword tokenization,典型的有Byte Pair Encoding (BPE),Wordpiece,Unigram和SentencePiece。
BPE
BPE最初是作为一种数据压缩技术提出的,后来被应用于自然语言处理领域,特别是在LLM的Tokenizer过程中;BPE的核心思想是通过迭代合并文本数据中最频繁出现的字符或字符序列来动态构建词汇表;这个过程从字符级别开始,逐渐构建出更长的词汇或短语表示,直到达到预设的词汇表大小或合并次数为止。
BPE标记化的主要步骤如下:
-
初始化:以单个字符初始化词汇表的元素。
-
统计共现频率:计算所有相邻字符对的共现频率。
-
合并操作:选择最频繁出现的字符对,将它们合并为新的词汇表项。
-
重复:重复上述过程,直到达到预设的合并次数或词汇表大小。
OpenAI从GPT2开始就是使用的这种分词方式。
WordPiece
WordPiece在选择要合并的字符或词对时采取了更为复杂的策略;它不仅计算这些组合的频率,还考虑了合并后带来的概率增益。
这意味着WordPiece在构建词汇表时,会更倾向于选择那些能够显著提高文本表示准确性的单元。Google的BERT模型就是采用了WordPiece作为其分词器,这也是BERT在多种语言任务上表现出色的原因之一。
Unigram
Unigram方法采用的是一种概率统计的方式,它会预测每个单词作为独立单元出现的概率(基于朴素贝叶斯统计),并基于这个概率来进行分词。这个过程中,某些词可能会被拆分成更小的单元,以便模型可以更灵活地处理语言中的变化和新词。
Unigram的一个关键优势是其能够自动适应不同语言的特性,使得模型在处理多语言文本时更加高效,它在GPT-1中被使用。
总结一下:
-
BPE是在每次迭代中只使用出现频率来识别最佳匹配,直到达到预定义的词汇量大小。
-
WordPiece类似于BPE,使用频率出现来识别潜在的合并,但根据合并词前后分别出现的可能性概率大小,进行是否合并。
-
Unigram没有频率出现的概率模型进行直接分词,相反,它使用概率模型训练语言模型(LM),移除使得最大似然概率减小最小的子词,然后进行反复计算,达到最大似然概率。
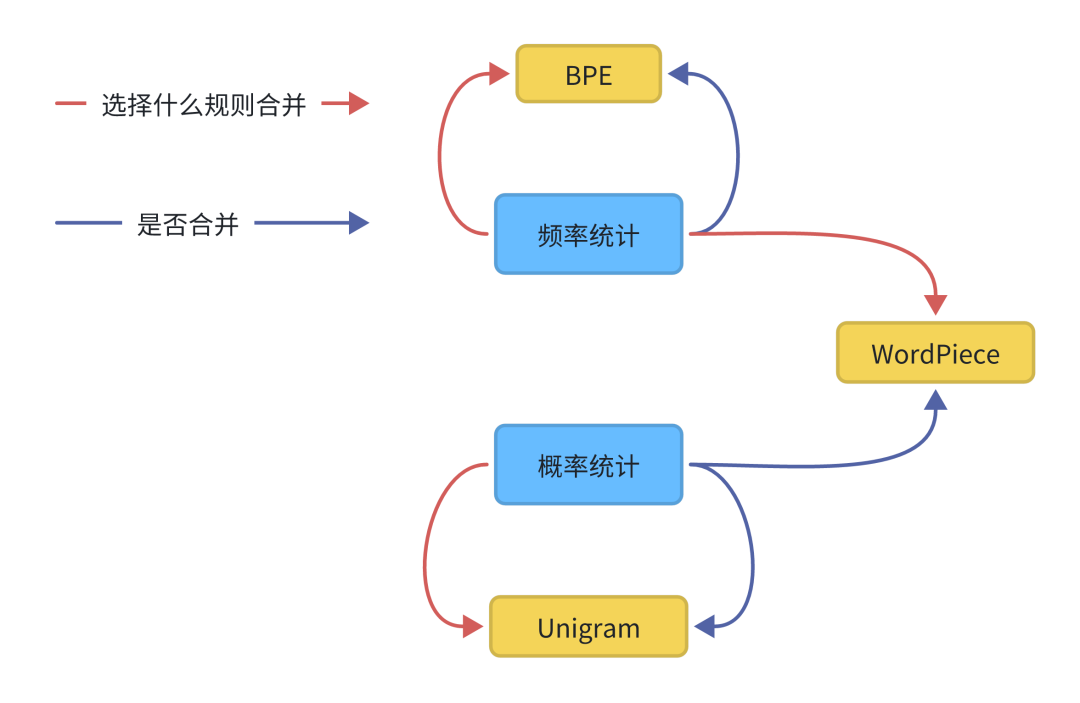
SentencePiece
SentencePiece是Google推出的subword开源工具包,集成了BPE和Unigram;除此之外,SentencePiece还能支持字符和词级别的分词。
SentencePiece主要解决了以下三点问题:
-
以unicode方式编码字符,将所有的输入(英文、中文等不同语言)都转化为unicode字符,解决了多语言编码方式不同的问题。
-
将空格编码为‘_’, 如’New York’ 会转化为[‘_’, ‘New’, ‘_York’],这也是为了能够处理多语言问题,比如英文解码时有空格,而中文没有, 这种语言区别。
-
优化了速度,如果您实时处理输入并对原始输入执行标记化,则速度会太慢。SentencePiece通过使用BPE算法的优先级队列来加速它来解决这个问题,以便您可以将它用作端到端解决方案的一部分。
如果任务涉及到多语言处理,特别是包含无空格分隔的语言,SentencePiece可能是一个好的选择。对于希望在词汇丰富度和处理未知词上取得平衡的项目,BPE或WordPiece可能更加合适。而如果项目特别注重于统计特性和语言模型的精确性,Unigram或许能提供更好的支持。
04
总结
分词是Transformer架构或者NLP中非常重要的一步,选择合适的分词方法对于模型非常重要。
随着NLP技术的不断进步,Tokenizer技术也在持续发展中,未来可能将不仅仅是要将文本转换为模型可理解格式,而是要扩展到语音和图像特征级别的数据,将更加智能化,包括细粒度,跨模态,自适应和可学习的Tokenizer技术。
同时,随着对AI伦理和隐私保护的重视,未来的Tokenizer技术将更加注重安全性和隐私保护;这可能包括开发新的技术来匿名化敏感信息、防止数据泄露,并确保在模型训练和推理过程中保护用户隐私。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
















 1979
1979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}