






搭建大语言模型知识库问答系统
部署OneAPI
拉取镜像
bash
复制代码docker pull justsong/one-api
创建挂载目录
bash
复制代码mkdir -p /usr/local/docker/oneapi
启动容器
bash
复制代码docker run --name one-api -d --restart always -p 3001:3000 -e TZ=Asia/Shanghai -v /usr/local/docker/oneapi:/data justsong/one-api
访问IP:3001 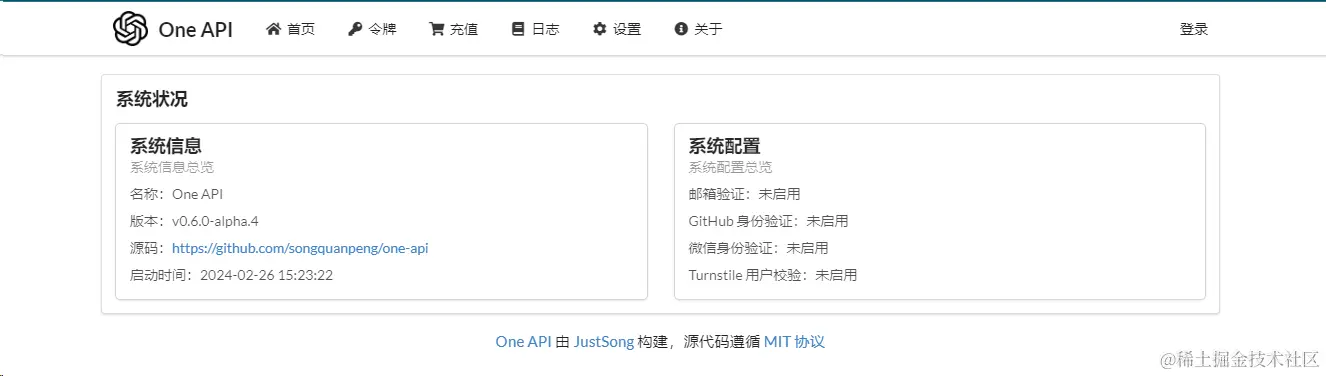
①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
注意:
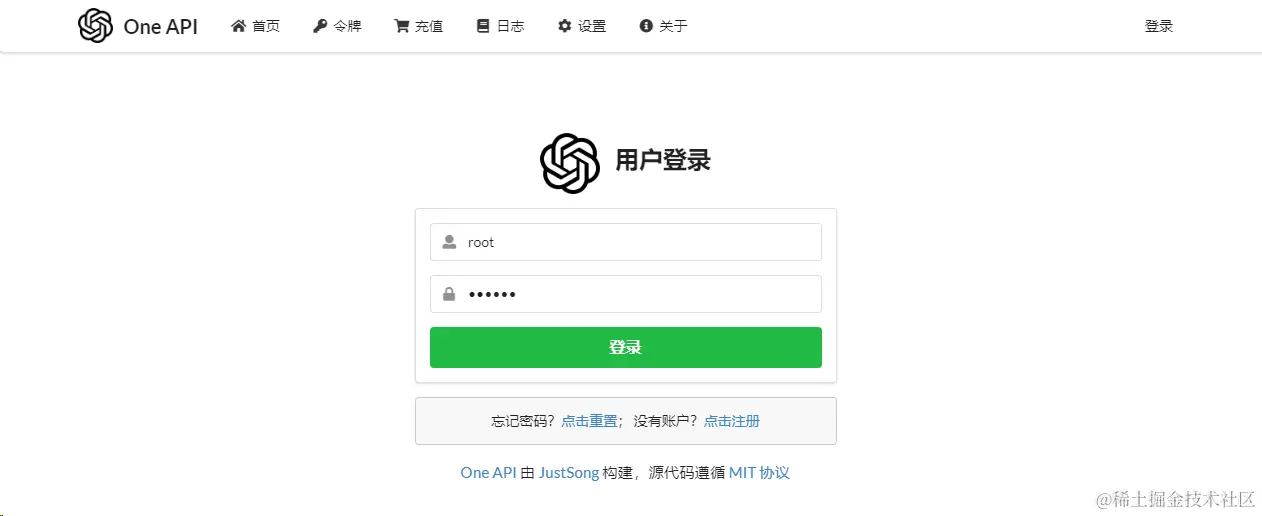
用户默认
root密码默认123456,首次登录后务必修改密码
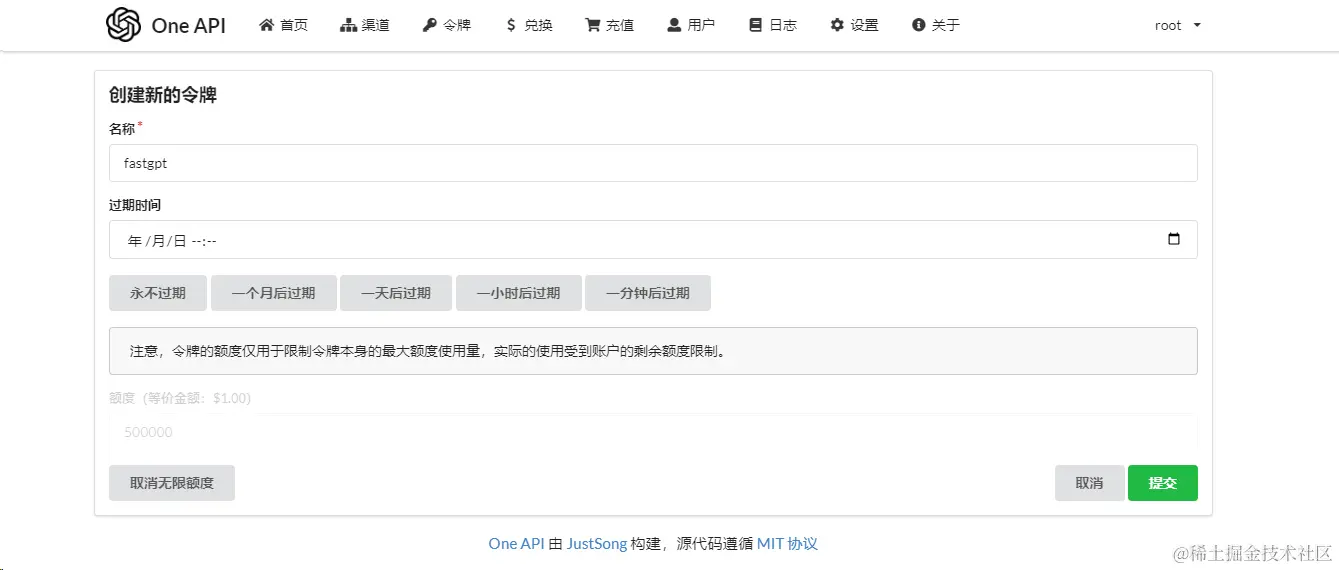
 创建接口令牌
创建接口令牌API Key备用
根据需要配置,这里点击“永不过期”+“设为无限额度”
项目地址: One API
部署一个LLM模型
下载ChatGLM3项目
bash
复制代码git clone https://github.com/THUDM/ChatGLM3
创建conda环境
bash复制代码cd /work/ChatGLM3
conda create -n ChatGLM3 python=3.10
conda activate ChatGLM3
编辑ChatGLM3/openai_api_demo/api_server.py文件,指定LLM模型、嵌入模型位置
相关模型可以从huggingface下载
bash复制代码# set LLM path
MODEL_PATH = os.environ.get('MODEL_PATH', '/root/work/models/chatglm3-6b')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
# set Embedding Model path
EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', '/root/work/models/bge-large-zh')
启动项目
bash复制代码(ChatGLM3) root@master:~/work/ChatGLM3/openai_api_demo# python api_server.py
Setting eos_token is not supported, use the default one.
Setting pad_token is not supported, use the default one.
Setting unk_token is not supported, use the default one.
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:04<00:00, 1.07it/s]
INFO: Started server process [517231]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
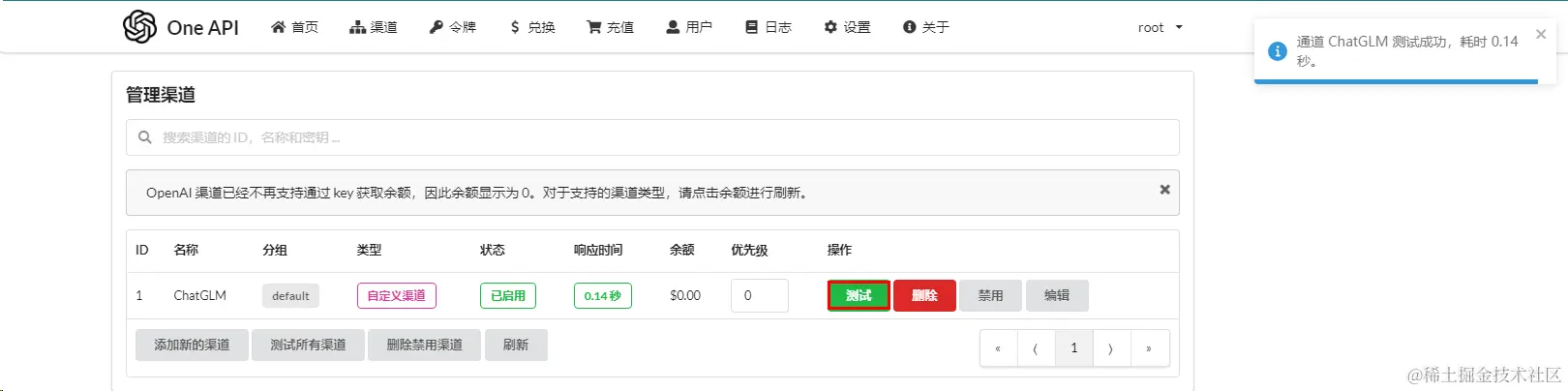
在OneAPI中创建一个渠道,并使用事先创建的API Key 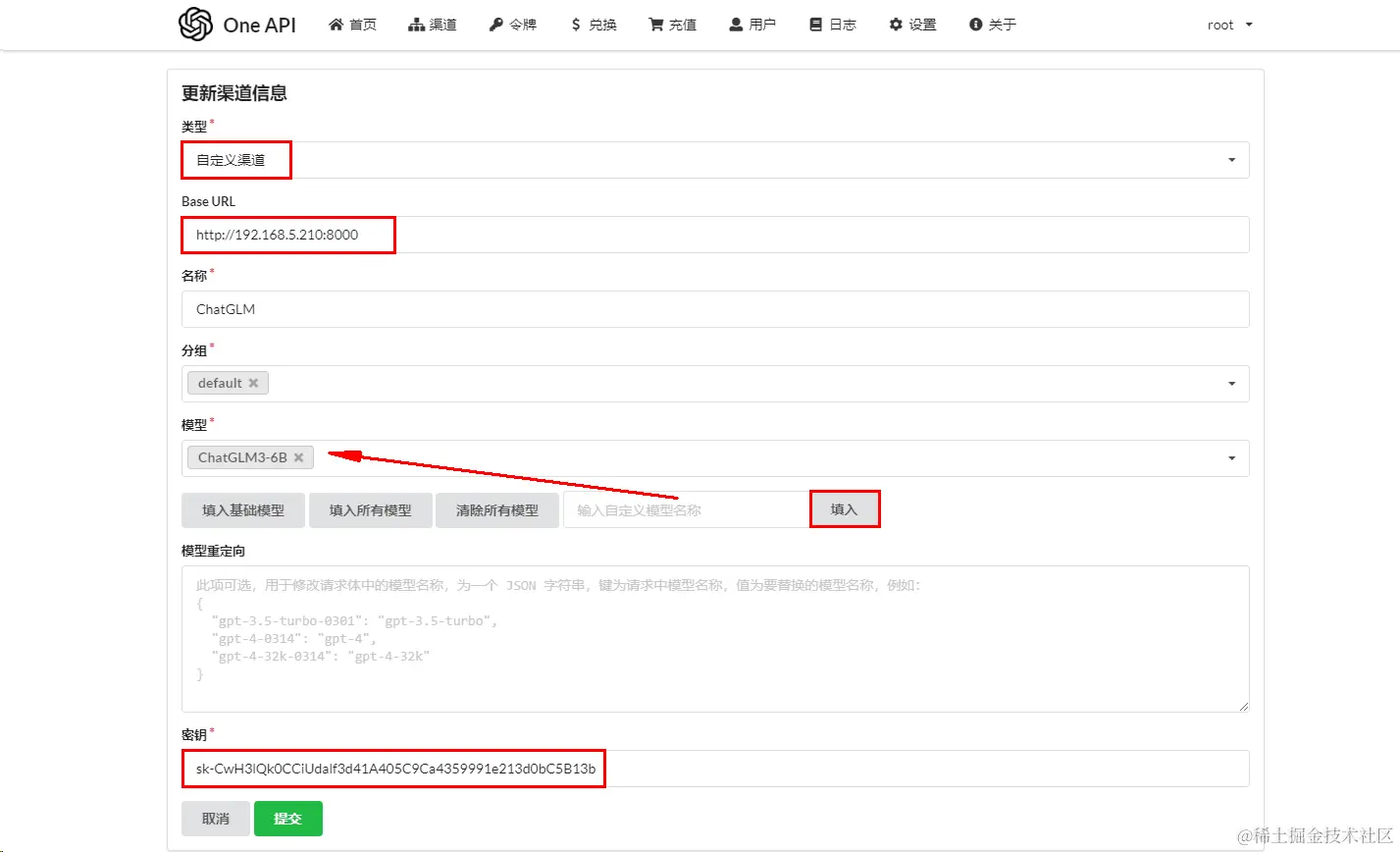 注意:
注意:
当完成下面
部署FastGPT操作后,可以测试对接是否成功。前提:这里配置的模型名称ChatGLM3-6B需要与在部署FastGPT中的fastgpt/config.json文件中配置模型名称一致。具体参考下面新建FastGPT对话应用操作。
部署嵌入模型
这里使用m3e嵌入模型
bash
复制代码docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
在运行容器的时候调用GPU,直接使用--gpus all参数指定即可
bash
复制代码 docker run -d -p 6008:6008 --name m3e --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
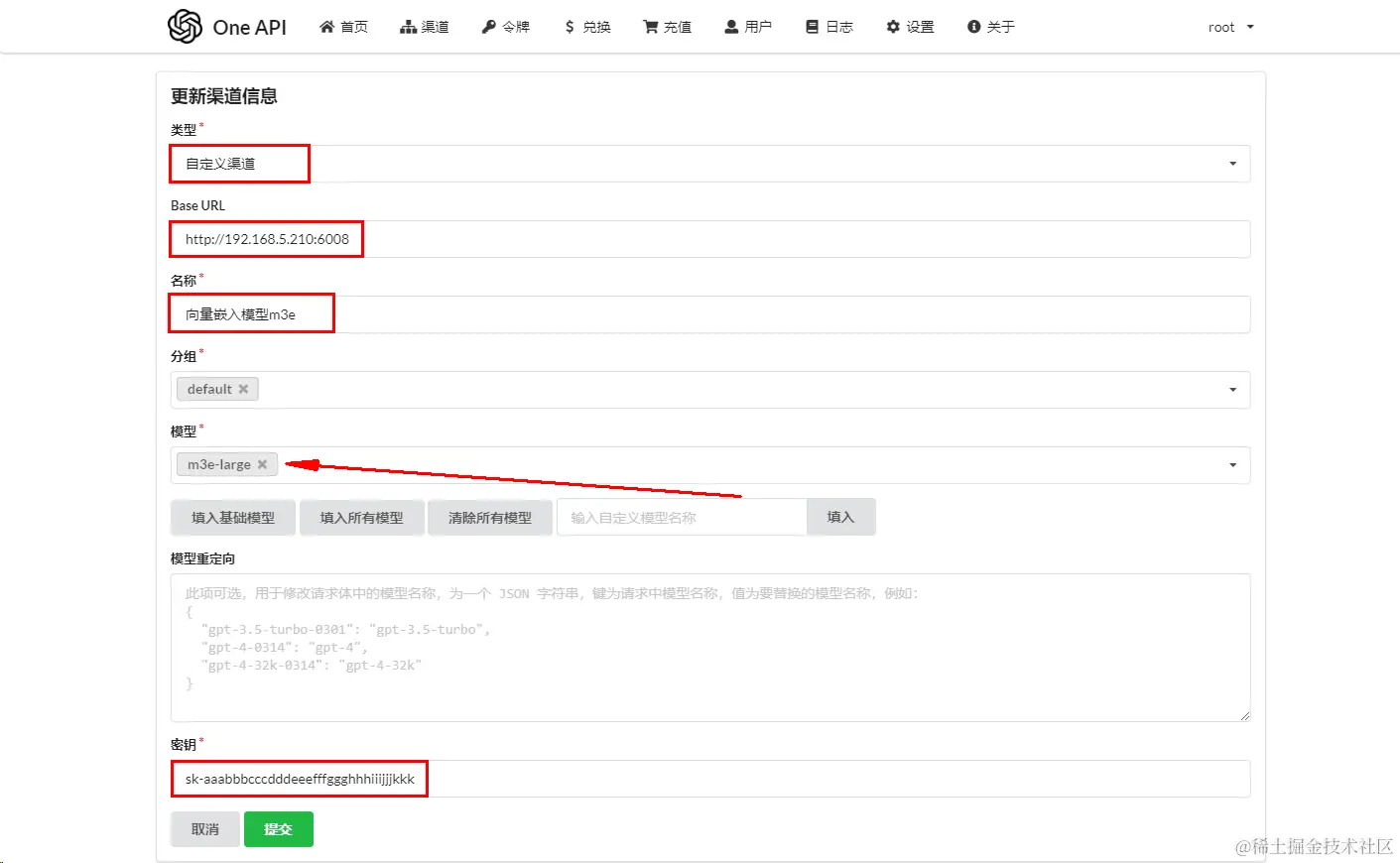
接入One API,添加一个渠道,根据官方参数说明如下:
vbnet复制代码设置安全凭证
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
也可以通过环境变量引入:sk-key
注意:渠道对应鉴权密匙一定是sk-aaabbbcccdddeeefffggghhhiiijjjkkk
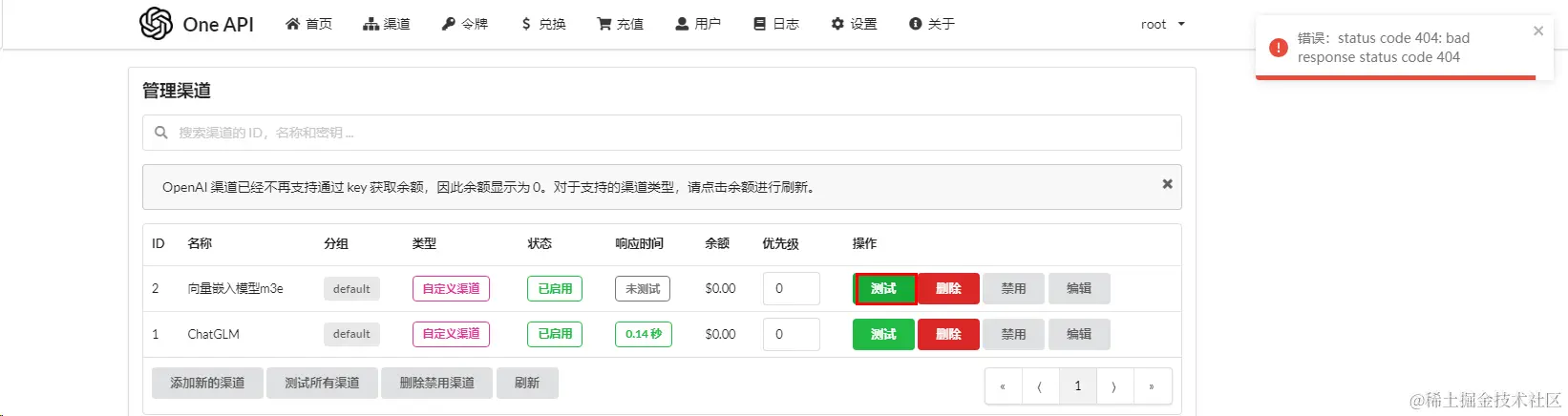
测试服务
这里将出现404异常,原因:由于不是对话生成模型(/v1/chat/completions)所以会404
 进一步验证,查看容器内部运行日志信息
进一步验证,查看容器内部运行日志信息
bash复制代码root@master:~/work/# docker logs -f friendly_feistel
No sentence-transformers model found with name ./moka-ai_m3e-large. Creating a new one with MEAN pooling.
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:6008 (Press CTRL+C to quit)
本次加载模型的设备为GPU: Tesla V100S-PCIE-32GB
INFO: 172.17.0.1:59468 - "POST /v1/chat/completions HTTP/1.1" 404 Not Found
到这里,嵌入模型准备完毕,在接下来接入FastGPT即可。
部署FastGPT
具体部署可参考官方文档:FastGPT
创建挂载目录
bash
复制代码mkdir -p /usr/local/docker/fastgpt
下载文件
bash复制代码curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
在项目fastgpt目录中,创建mongo密钥
bash复制代码openssl rand -base64 756 > ./mongodb.key
chmod 600 ./mongodb.key
chown 999:root ./mongodb.key
bash复制代码root@master:/usr/local/docker/fastgpt# ls
config.json docker-compose.yml mongodb.key
执行命令拉取容器镜像
bash
复制代码docker-compose pull
启动容器
bash
复制代码 docker-compose up -d
初始化 Mongo 副本集(4.6.8以前可忽略)
bash复制代码# 查看 mongo 容器是否正常运行
docker ps
# 进入容器
docker exec -it mongo bash
# 连接数据库
mongo -u myname -p mypassword --authenticationDatabase admin
# 初始化副本集。如果需要外网访问,mongo:27017 可以改成 ip:27017。但是需要同时修改 FastGPT 连接的参数(MONGODB_URI=mongodb://myname:mypassword@mongo:27017/fastgpt?authSource=admin => MONGODB_URI=mongodb://myname:mypassword@ip:27017/fastgpt?authSource=admin)
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
# 检查状态。如果提示 rs0 状态,则代表运行成功
rs.status()
访问IP:3000  注意:
注意:
yaml复制代码用户默认 root
密码默认 1234
密码设置修改:docker-compose.yml 文件中的 DEFAULT_ROOT_PSW
bash复制代码 environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
 配置docker-compose.yml文件,使用 OneAPI接口、令牌
配置docker-compose.yml文件,使用 OneAPI接口、令牌
注意:这里地址指向OneAPI地址,令牌使用上面创建的令牌。
bash复制代码 environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管。务必加 /v1
- OPENAI_BASE_URL=http://192.168.5.210:3001/v1
- CHAT_API_KEY=sk-CwH3lQk0CCiUdalf3d41A405C9Ca4359991e213d0bC5B13b
重启FastGPT容器
bash
复制代码docker-compose up -d
新建FastGPT对话应用
接下来配置FastGPT,修改fastgpt/config.json文件,复制一份gpt-3.5-turbo配置,修改为ChatGLM 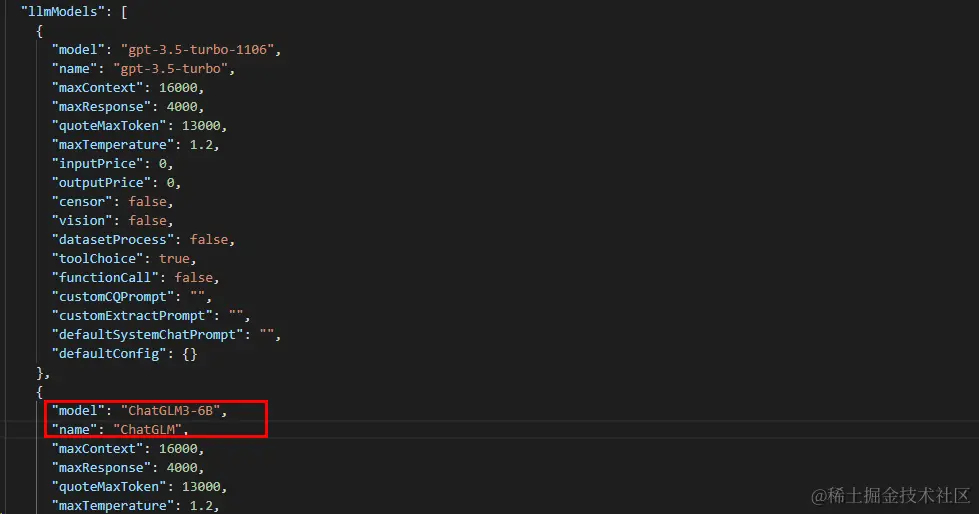
注意:这里配置的model值
ChatGLM3-6B需要与渠道中配置的模型名称一致
重启FastGP 容器
bash
复制代码docker restart fastgpt
访问IP:3000/,新建FastGPT应用
取一个名称,从模板选择,这里选择“简单的对话”,点击“确认创建”按钮。
 选择上面配置的ChatGLM模型,然后点击“保存并预览”
选择上面配置的ChatGLM模型,然后点击“保存并预览” 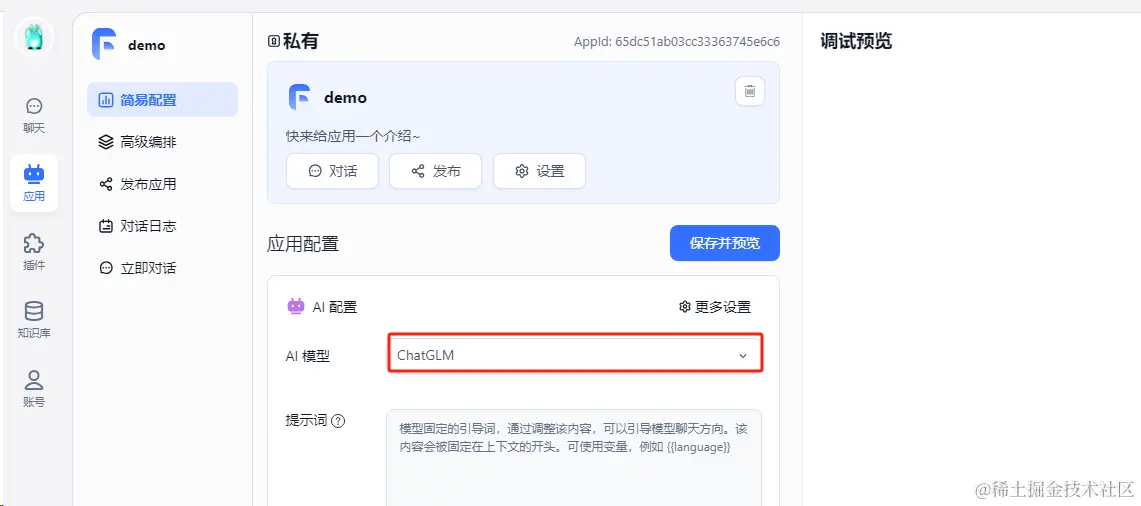 对话测试,输入问题,点击图标发送
对话测试,输入问题,点击图标发送 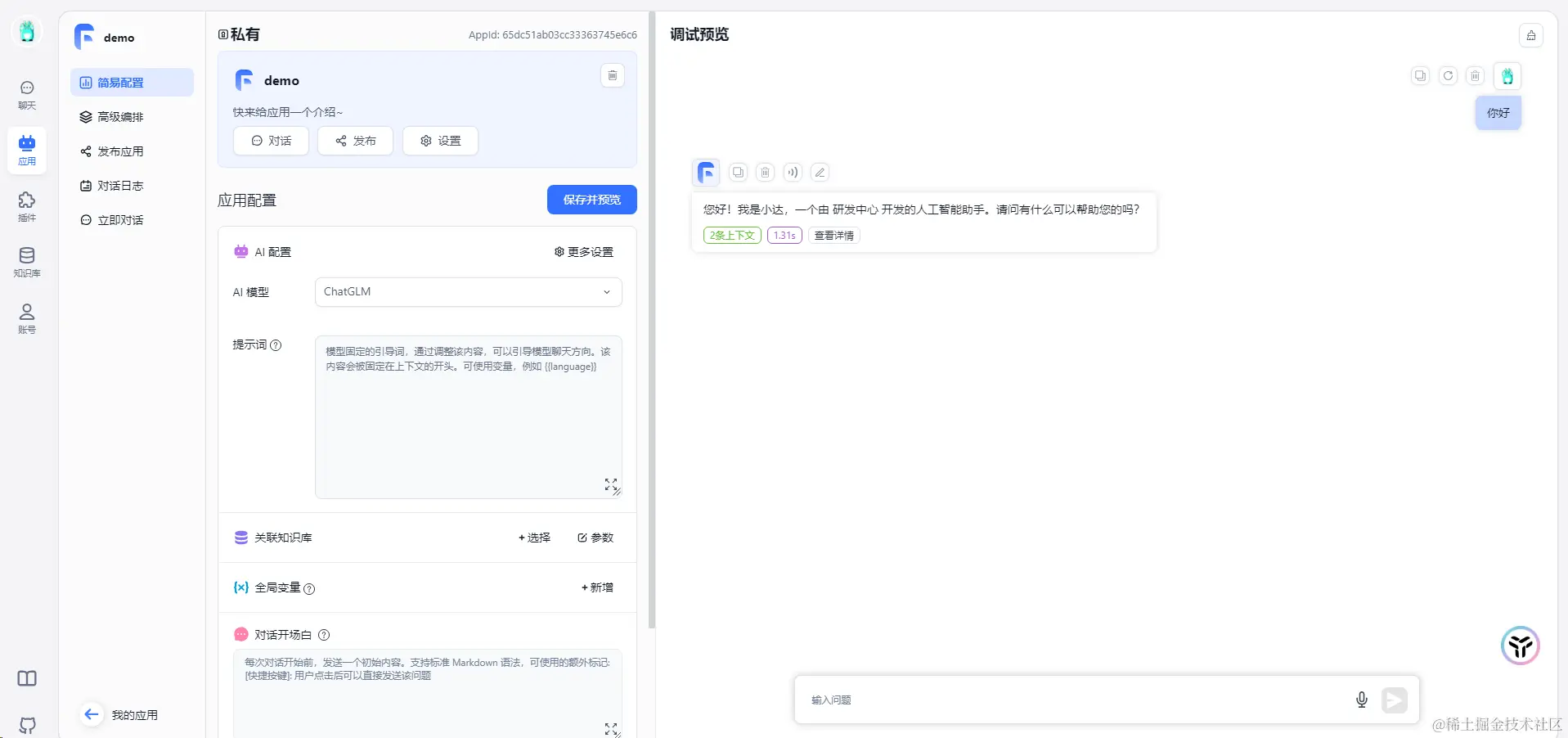
新建 FastGPT 知识库应用
知识库需要使用嵌入模型,所以需要提前进行配置。
修改fastgpt/config.json配置文件,在vectorModels 中加入M3E模型: 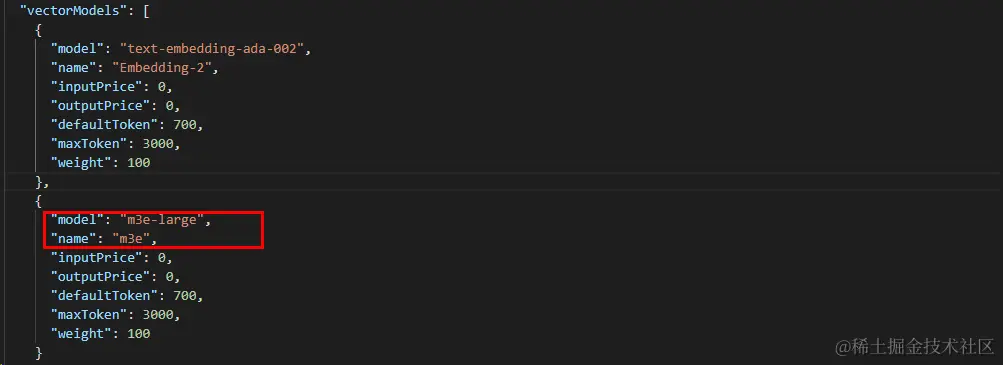
注意:这里配置的model值
m3e-large需要与渠道中配置的模型名称一致
重启FastGPT容器
bash
复制代码docker restart fastgpt
在知识库菜单栏,创建一个知识库,同时取一个名称,选择索引模型 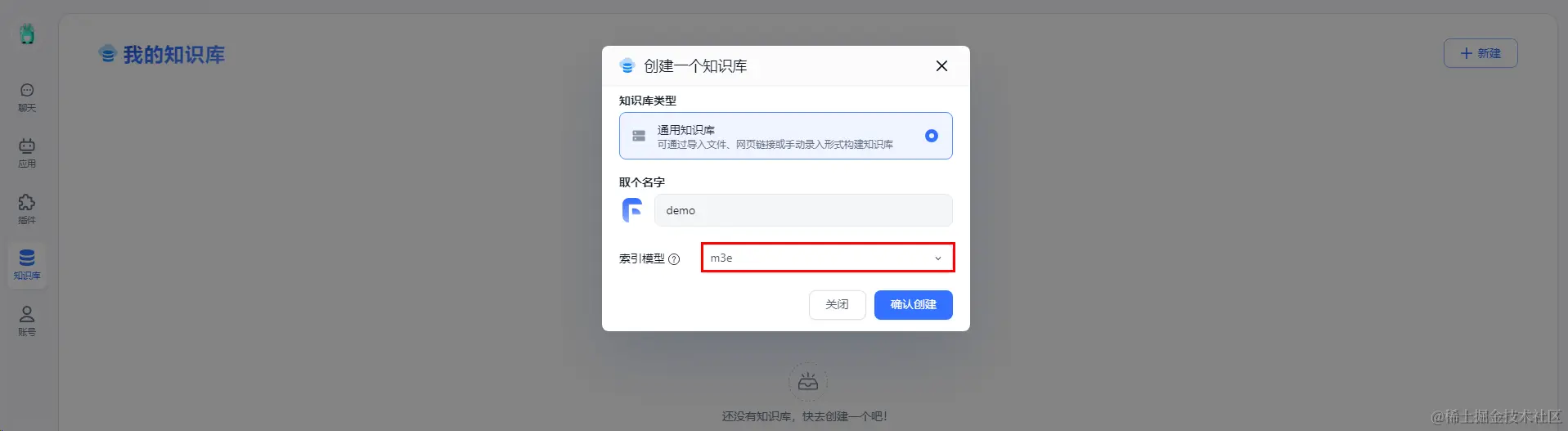 向
向demo知识库导入数据 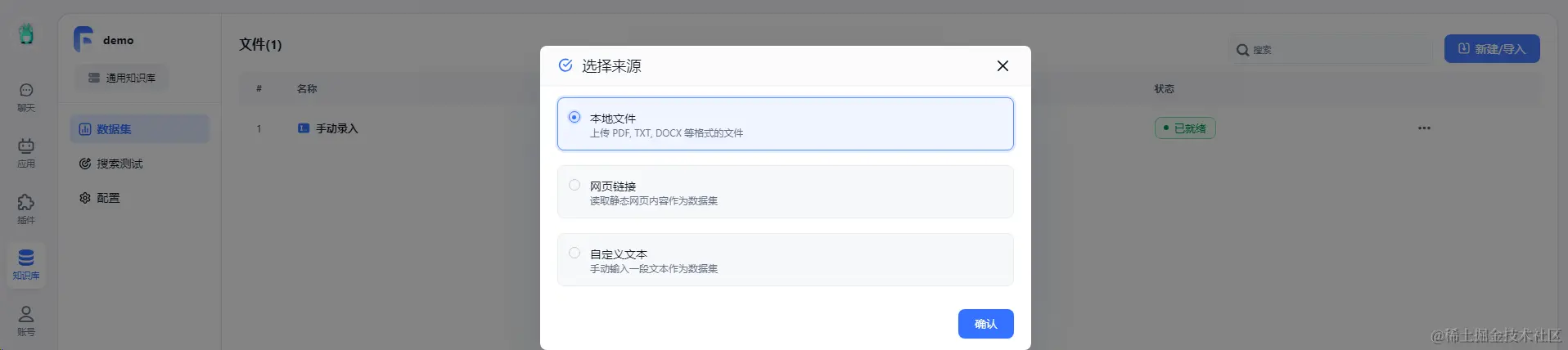 根据具体需求,进行配置数据处理参数
根据具体需求,进行配置数据处理参数 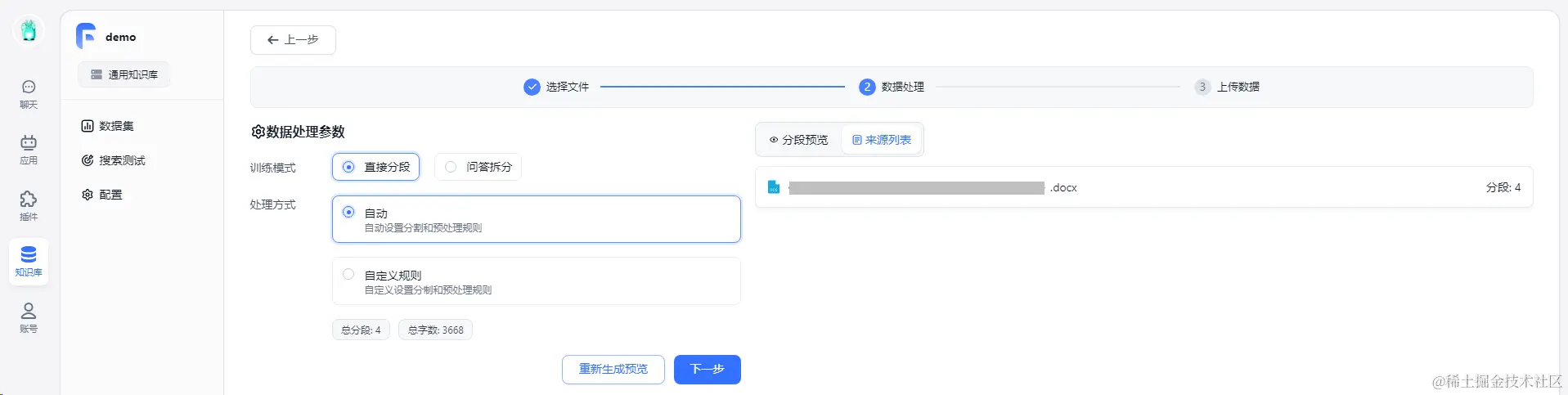 当上传数据训练完毕就绪后即可使用
当上传数据训练完毕就绪后即可使用 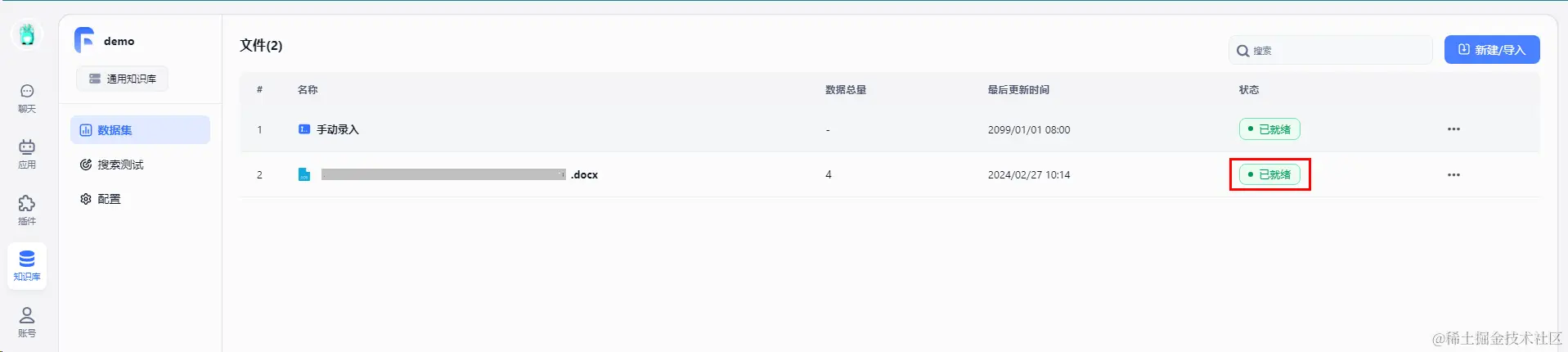
新建知识库,取个名字,从模板选择知识库+对话引导 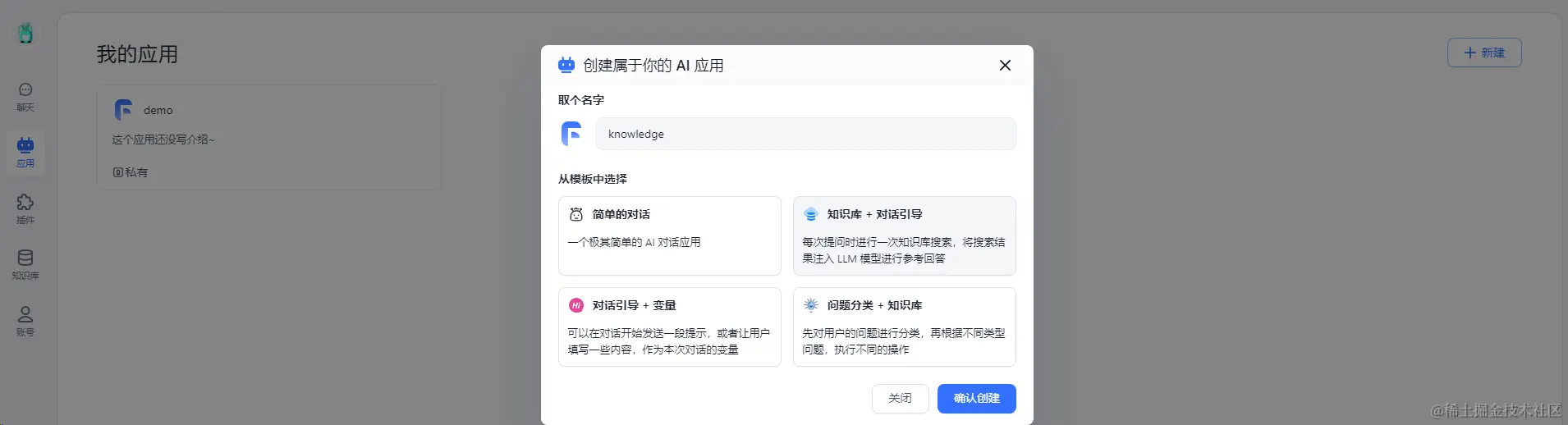 配置AI模型与关联知识库后,保存并预览,然后即可开始进行知识库的对话测试
配置AI模型与关联知识库后,保存并预览,然后即可开始进行知识库的对话测试 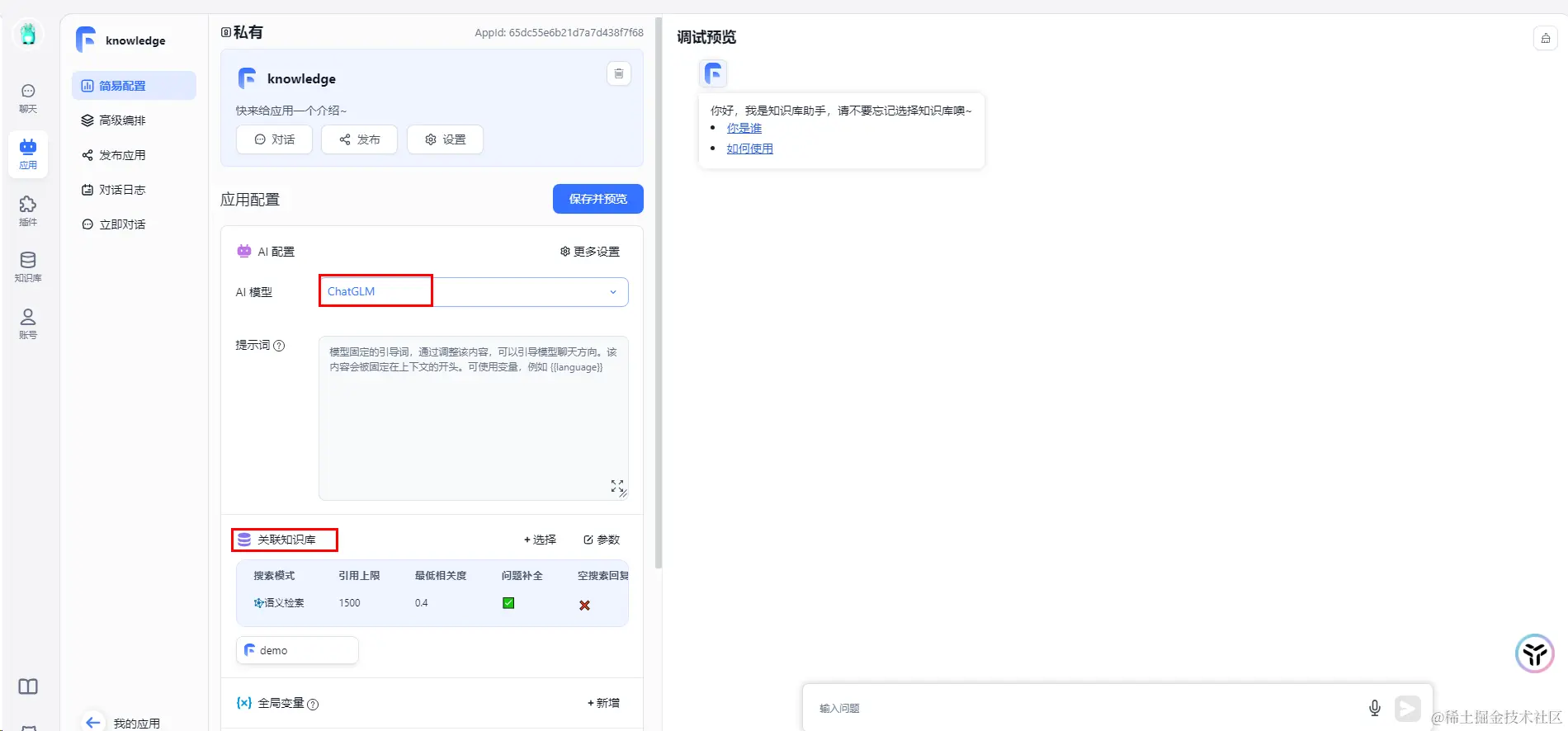 进行知识库问答对话时,出现一个异常
进行知识库问答对话时,出现一个异常  是因为知识库配置中,默认且只有一个文件处理模型,固定为
是因为知识库配置中,默认且只有一个文件处理模型,固定为gpt-3.5-turbo-1106,且目前没有配置该模型渠道 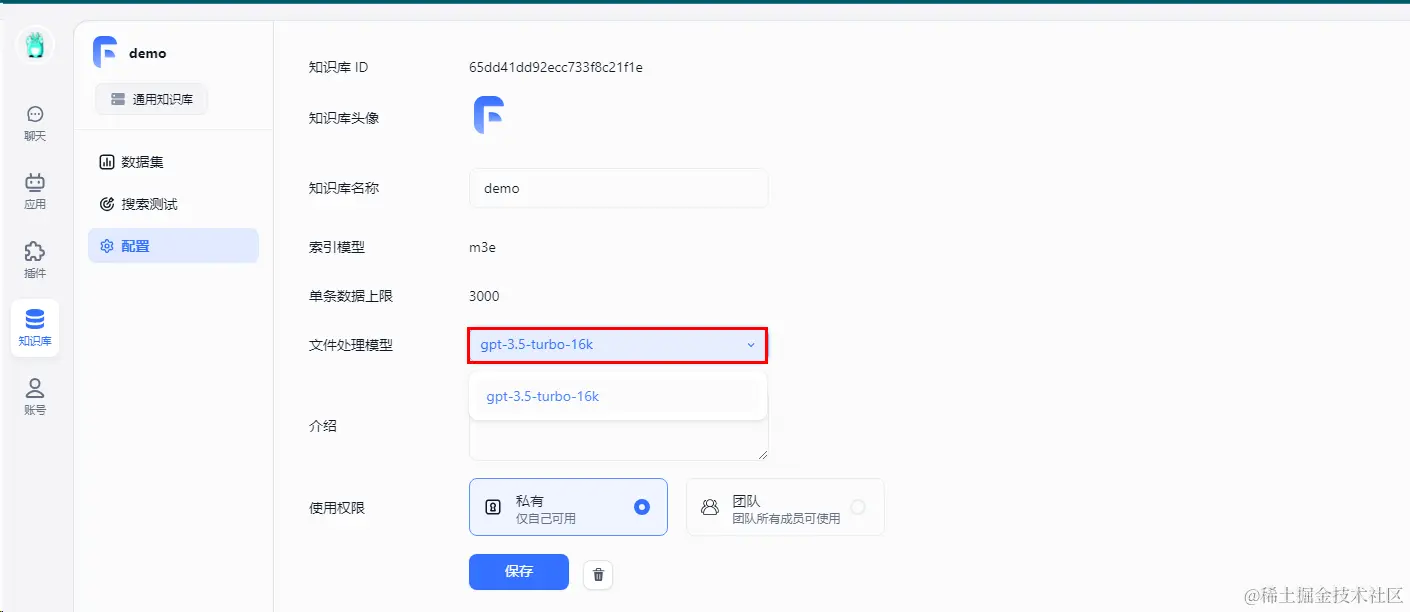
解决方案:
1.更新渠道,添加模型名称gpt-3.5-turbo-1106,意味着使用该模型的就会使用Base URL定义的模型
2.新建一个渠道,指定使用模型名称gpt-3.5-turbo-1106 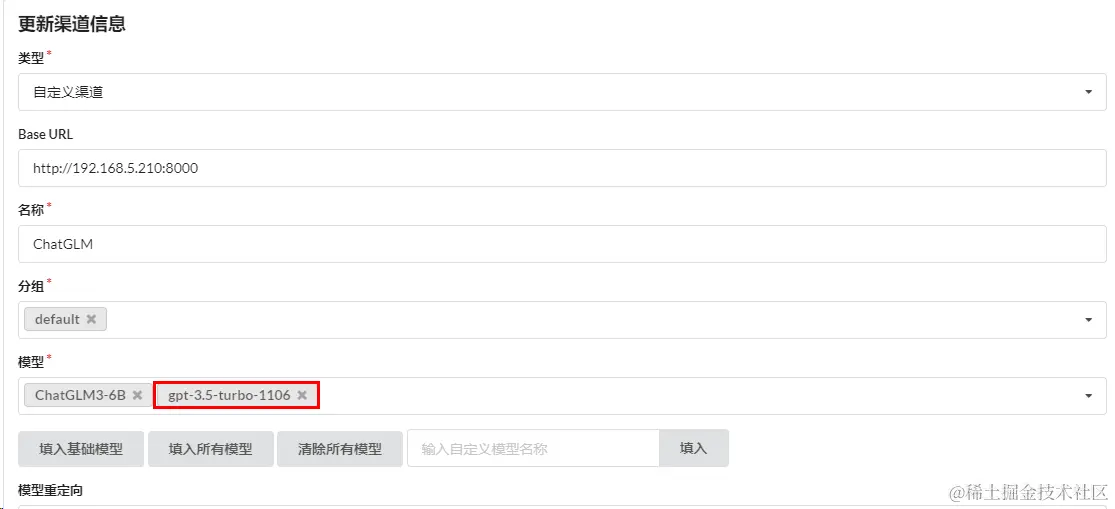
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}