






这篇文章就针对 RAG 检索这个问题提供一些思路, 以 Shortwave 这家 AI 邮件助手公司的设计思路作为案例,真的很难有公司把产品详细技术机制公布出来
本文在01 部分还针对"微调和 RAG,到底选哪个? " , " 有了支持超长上下文窗口的 LLM,是否还需要 RAG"进行说明
01
现在支持超长上下文窗口long context LLM(如 10M tokens的 gemini 1.5)的模型已经出现,许多人认为 RAG 已经没有必要,因为可以将数百个文档直接上传给 LLM 进行阅读和处理。
但是,需要考虑以下三个关键问题:
相关性:上传如此多的文档,仍然需要考虑哪些文档与问题最相关,否则容易导致答案偏离
性能影响:上传大量文档对模型性能的影响有多大?模型是否能够高效地处理并回答相关问题?
算力成本:上传过多文档会导致算力成本显著增加,这也是为什么很多 LLM 目前仍然无法支持过多上下文窗口的原因。比如,GPT-4 在处理 30k 汉字内容时可能会出现宕机的情况
对于超长上下文窗口一个有趣的类比是:尽管我们的 RAM 内存足够大,但很多操作仍需在硬盘上进行读写传输,而不是全部存储在 RAM 中

我上传 3w 的文档, 结果 GPT-4 说他没有直接访问具体文章的权利??
RAG&Finetuning,都能用来优化大模型在下游任务的适应能力,选哪个, 有什么区别
“
https://arxiv.org/abs/2401.08406
https://arxiv.org/abs/2312.05934
上面两篇论文研究得出: RAG(检索增强生成)在生成质量上往往优于(有监督/无监督)微调的传统语言模型,特别是在需要外部知识回答的场景下
RAG 不仅在保持高效性能的同时使用更少的算力资源,还具备灵活应对信息检索准确性问题的能力。具体而言,当检索到的信息不准确或有害时,RAG 允许对索引进行调整或替换,而不需要重新训练整个模型
此外,RAG 的模块化设计使得不同的组织可以根据需求使用专属的知识库,避免了将所有数据混合在一个不可解释的黑箱模型中的问题,从而提高了模型的透明度和可定制性。这种架构对企业和研究机构尤其有吸引力,因为它能够更好地管理专有数据和知识
02
目前的 RAG 系统在知识库具备高相关性、高密度、以及包含丰富细节信息的情况下表现最佳
为了确保 RAG 的高效性,需要对初始检索器initial retrieve、重新排序机制(re-rank mechanism)、或者类似 [EffectiveGPT]
相关性 (Relevance) - 最重要的评估标准: 使用 Mean Reciprocal Rank (MRR) 来评估系统的相关度排名。系统应确保与问题最相关的内容排在最前面,这是衡量初始检索质量的关键指标
知识密度 (Density): 在相关性相同的情况下,应优先参考知识密度高的文档,即那些内容质量更高、信息更精炼的文档,例如由专家撰写的主题内容
细节 (Details): 特别是在涉及工具调用时,对知识库或工具进行详细描述能帮助 LLM 更好地理解每个知识库的用途,尤其是在处理如 SQL 数据库这类需要精确调用的场景
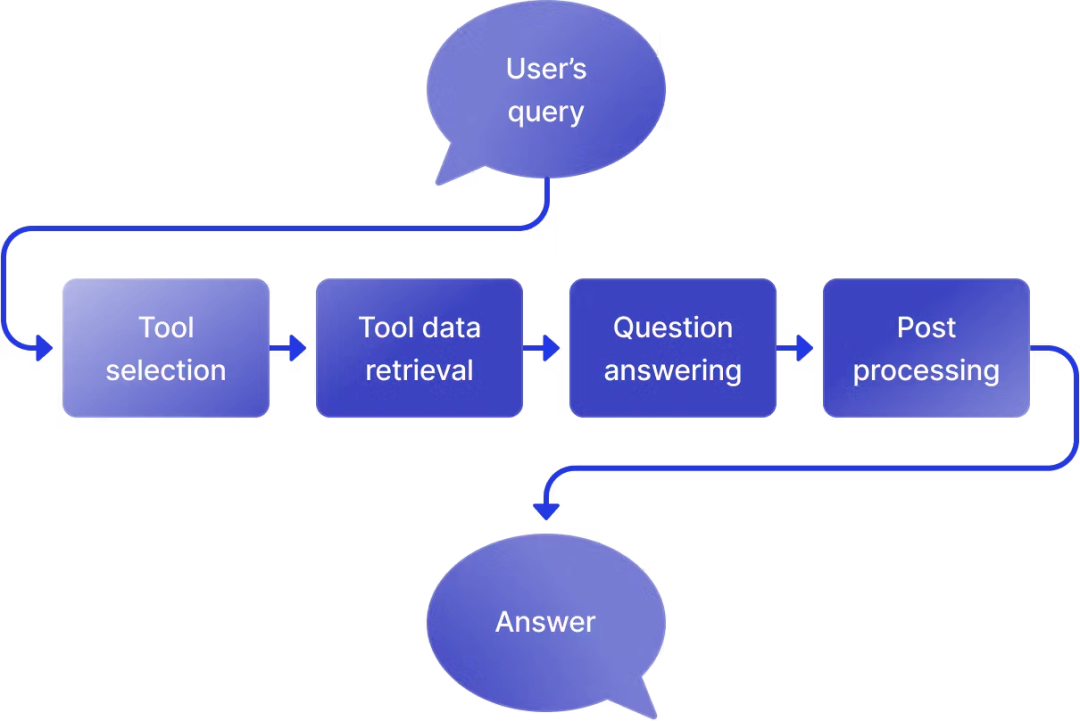
post processing将回答形成用户友好的格式,包括引用内容和相关问题
当前,基于向量的语义相似性搜索的结果在准确性上可能还不如传统的关键词搜索(如 BM25)。因此,类似 Sourcegraph 的 CTO 建议将语义相似性搜索与传统关键词搜索结合,以提升 RAG 检索的整体质量
现实可行的提升 RAG 的现实措施可参考 AI 邮件助手 Shortwave 的 AI Search 机制:
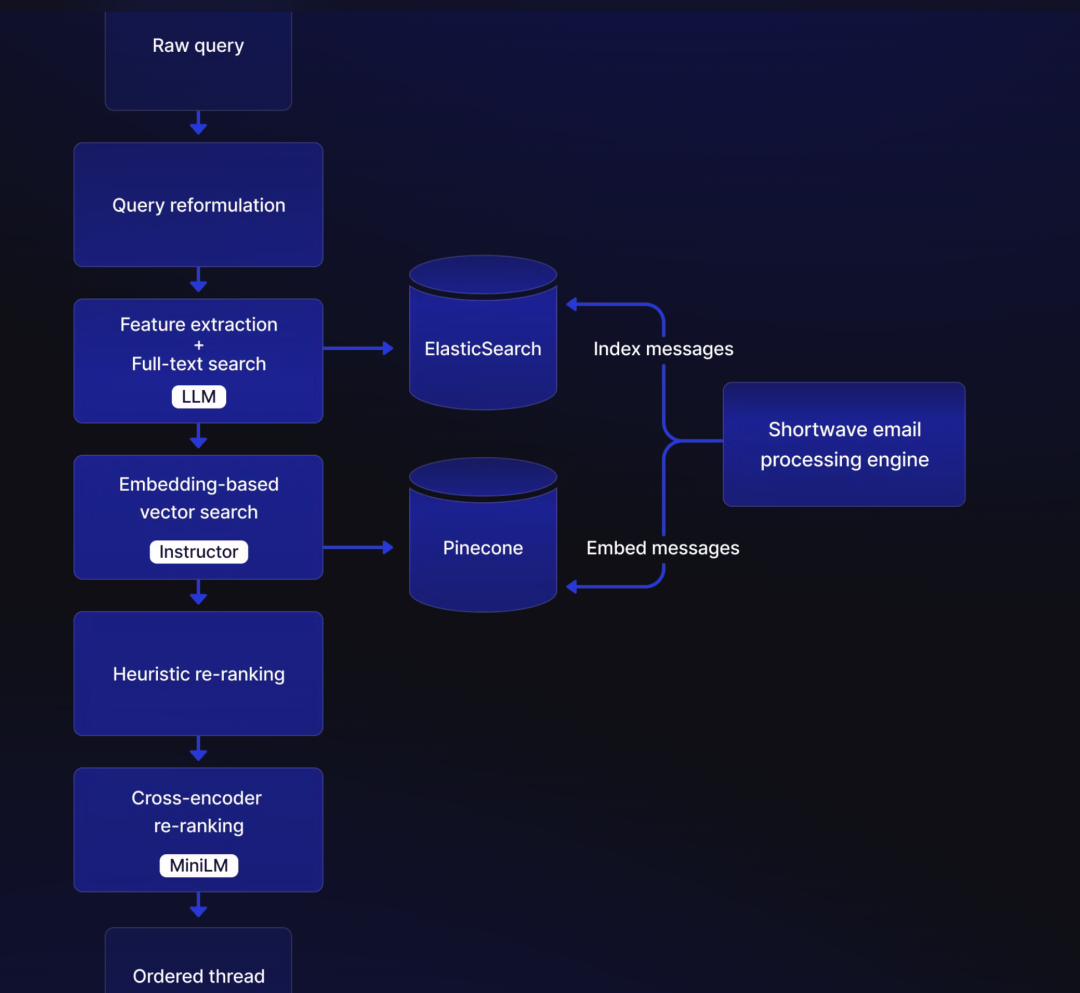
问题重写 (Query Reformation): 对用户的原始查询进行重写或优化,使其更适合检索系统。例如,通过重新组织句子结构、消除歧义或补充上下文信息,来提高查询的清晰度和相关性。
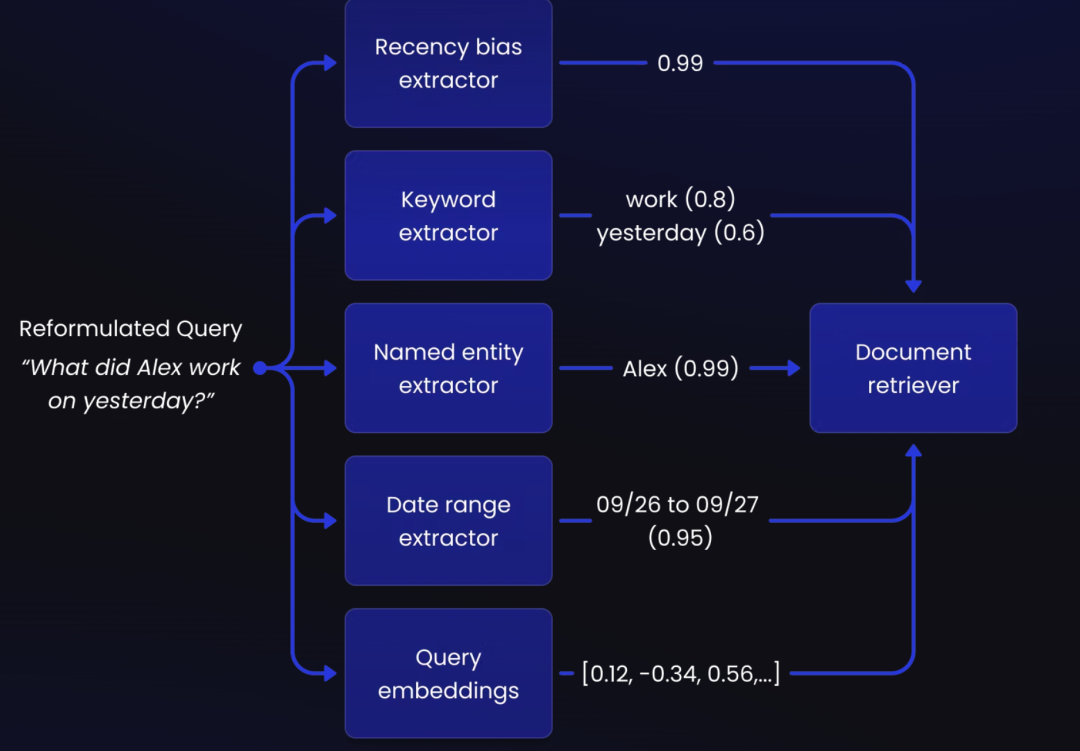
关键信息提取 (Feature Extraction): 从用户问题中提取关键特征,如时间、地点、姓名等重要信息。这些特征可以帮助进一步定义检索范围,并提高匹配的准确性
Recency bias extractor 是一种用于识别和提升与当前时间点最相关信息的工具。在 Shortwave 的 AI 系统中,它根据查询中特征(如日期或时间)来判断信息的时效性,从而在初步检索后对更近期的内容给予更高的优先级。这种方法帮助系统快速筛选出与用户当前需求最相关的最新信息,适用于需要强调“近因效应”的场景
关键词与嵌入结合的初步检索 (Keyword + Embedding Initial Retrieval):使用关键词搜索进行初步检索,找到最精准和明显的匹配项,确保高相关性。
辅以向量搜索处理同义词、多模态信息,以及处理有语法错误的查询内容。嵌入方法有助于捕捉更广泛的语义关系,即使关键词不完全匹配。
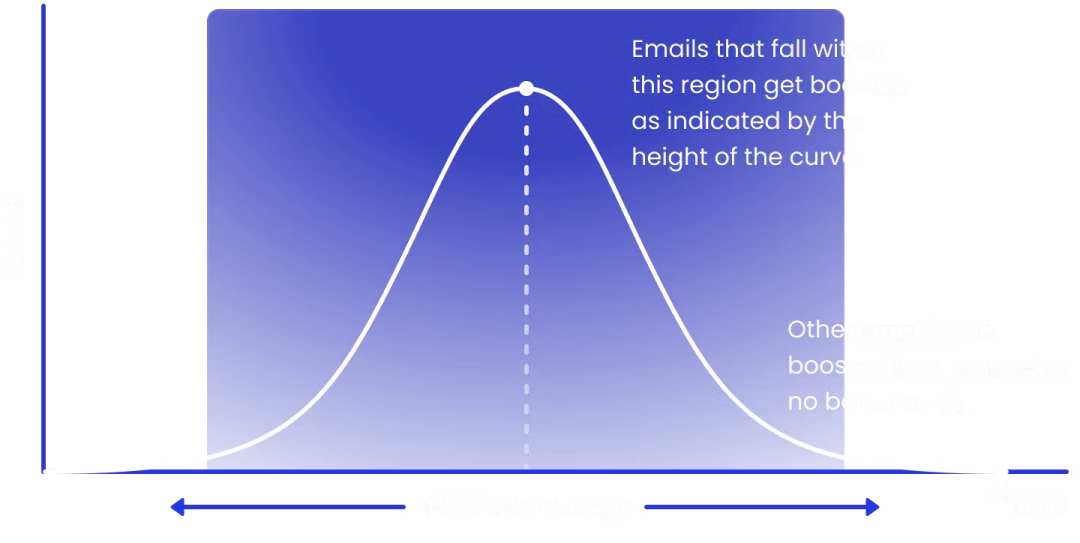
启发式重新排序 (Heuristic Re-ranking):利用从问题中提取的特征缩小向量搜索的范围。例如,如果问题中提及了时间、姓名等特征,则这些信息在重新排序时应获得最高权重(boost),从而更加突出相关答案。对于次相关的内容则给予较低权重或惩罚(penalty),以避免无关信息干扰检索结果
最跟关键词符合的素材获得最高的 boost, 就是下面曲线的最高值
利用 MS Marco MiniLM 进行 Cross-Encoder Re-ranking: MiniLM 模型在本地运行,能够根据 reformulated query 和上一步中排名靠前的信息,对其进行更精细的匹配评分
尽管 MiniLM 提供了更好的效果,但由于其计算量较大,为了节省资源,仅对通过启发式嵌入排名靠前的文档进行 re-ranking
Cross-Encoder 输入包括 reformulated query 以及上一步通过 heuristic embedding 排名靠前的文档。模型会对每个文档与 reformulated query 的匹配性进行评分,生成更精确的相关性分数
根据 cross-Encoder(MiniLM)给出的评分,进一步指导 heuristic re-ranking,完善对检索素材的排名。具体做法是对评分高的内容进行 boost,而对评分较低的内容进行 penalize。这一过程会对索引内容进行动态调整,确保最终评分反映文档与问题的精确相关性
输出最终排序结果: 最终将经过 cross-Encoder 和 heuristic re-ranking 双重优化的排序结果提供给 LLM
简要总结一下这 4 个机制:
高相关性、高密度、以及包含丰富细节信息的知识库(这3 个标准也可以作为评估器, 检索质量的评估标准) 对问题进行优化改写,让用户问题更清晰明确 提取问题相关特征,用关键词搜索先精准匹配 1 个或多个re-ranking 机制
03
通过Shortwave 这个例子, 我对 AI 产品更有感觉了, 大致是基于 LLM,根据用户场景需求,开发设计特定的 AI tool, 能一键满足用户需求的ai tool ,这个 ai tool 需要自己基于各种开源模型, 基于Prompt, 基于自定义的机制进行封装
像下面的 Summary 就很简单, 只是用了 Prompt 进行封装, 而 AI Search 就是 02部分的步骤, 涉及复杂的场景细化流程
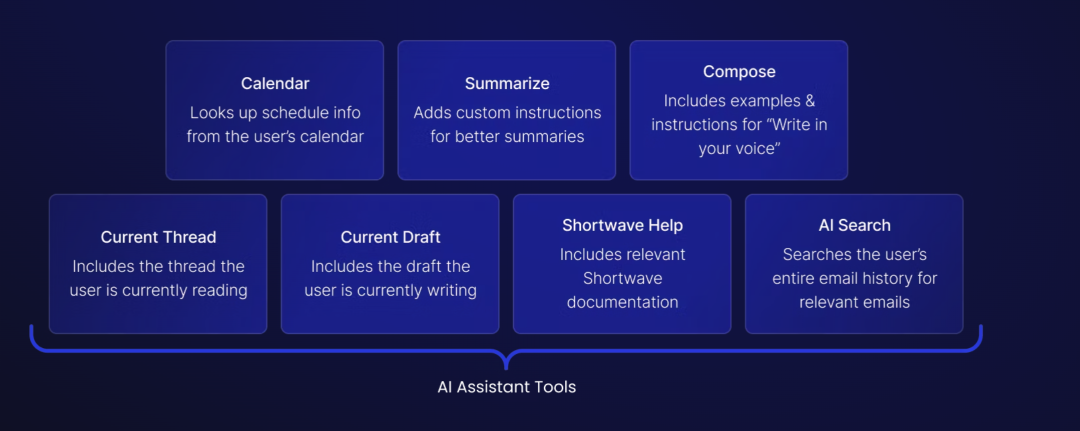
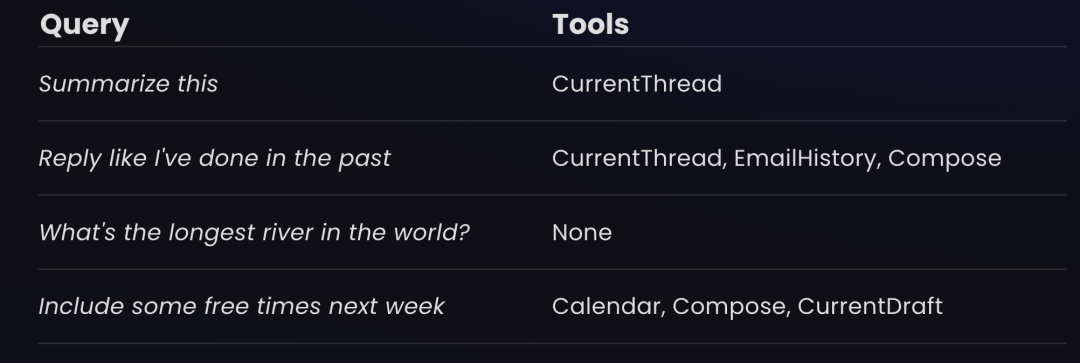
针对什么时候调用这些工具, 就需要做工具与用户问题的匹配
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}