






为什么嵌入是关键
嵌入是现代生成式 AI 的基石,默默地驱动着我们日常交互的许多系统的功能。简单地说,嵌入是文本的数值表示——有效地将单词、句子甚至整个文档转换为数字。这些数字绝非随机;它们经过精心设计,以捕捉文本中的含义和关系。例如,“狗”和“小狗”的嵌入在数值空间中比“汽车”的嵌入更接近,反映了它们的语义相似性。这种将含义编码为可测量形式的能力使得嵌入对于搜索、推荐系统和高级 AI 应用程序(如检索增强生成 (RAG))等任务不可或缺。
向量相似性搜索
这种向数字的转换使 AI 能够以有意义的方式比较和理解文本。在处理海量数据时(RAG 系统中经常出现这种情况),嵌入变得至关重要。这些系统将嵌入的强大功能与称为矢量数据库的专用存储解决方案相结合。与搜索精确匹配的传统数据库不同,矢量数据库经过优化,可根据含义查找最接近的匹配。此功能使 RAG 系统能够从庞大的知识库中检索最相关的信息,并使用它来生成精确的、符合上下文的响应。通过连接原始数据和智能检索,嵌入和矢量数据库共同构成了 RAG 系统成功的支柱。
多语言系统的挑战
构建适用于英语的 RAG 系统已经是一项复杂的任务,但将其扩展到其他语言则带来了一系列全新的挑战。由于训练数据丰富且语言结构简单,英语嵌入通常经过高度优化。但是,将这些英语训练的嵌入用于其他语言可能会导致严重的不准确性。不同的语言有自己的细微差别、语法和文化背景,而主要在英语文本上训练的标准嵌入模型通常无法捕捉到这些。虽然存在一些多语言嵌入模型来弥补这一差距,但它们在不同语言中的效果并不相同,特别是对于那些训练数据有限或语言特征独特的语言。这使得构建对非英语语言和英语一样准确可靠的 RAG 系统变得困难。
为什么英语嵌入更准确?
-
大量高质量训练数据
英语在数字领域占据主导地位,可供训练的高质量内容数量空前庞大。维基百科、书籍、研究论文和社交媒体等数据集中的英语内容比其他语言丰富得多。相比之下,许多语言(尤其是资源匮乏的语言)缺乏多样化和标准化的数据集,这限制了基于这些语言进行训练的嵌入质量。 -
模型优化偏差
BERT 和 GPT 等 NLP 模型最初是针对英语开发和优化的,即使在多语言版本中也经常优先考虑英语。多语言模型在同一参数空间内平衡多种语言的学习,这可能会降低代表性较低的语言的性能,而有利于英语等主导语言。 -
语言复杂性和多样性
与许多其他语言相比,英语的形态相对简单。例如,英语中的单词形式往往保持一致(例如“run”和“running”),而土耳其语或芬兰语等语言的词形变化很大,单个词根可以有几十种变体。此外,具有不同语法或词序的语言,例如日语(主语-宾语-动词)或阿拉伯语(灵活的词序),对针对类似英语的结构进行优化的模型提出了额外的挑战。 -
语义和文化对齐
跨语言捕捉语义意义绝非易事。单词和短语通常带有无法直接翻译的细微含义。例如,英语单词“love”在其他语言中有多个文化上不同的对应词(例如西班牙语中的“amor”,希腊语中的“eros”或“agape”)。无法解释这些差异的嵌入很难实现多语言对齐。 -
基准测试和评估偏差
许多基准测试数据集和评估方法都是以英语为中心设计的。这种以英语为中心的关注可能会人为地夸大模型在英语方面的感知性能,同时掩盖其在其他语言方面的局限性。
对 RAG 系统的影响
当嵌入无法处理其他语言的复杂性时,RAG 系统可能会受到严重影响。由于嵌入可能难以捕捉非英语查询的细微含义,检索结果通常会变得不那么相关甚至完全错误。这不仅会影响准确性,还会破坏用户信任和系统的整体效用。检索过程中可能会遗漏关键文本块,从而阻止系统访问生成准确且与上下文相关的响应所需的信息。
为了使多语言 RAG 系统表现良好,它需要能够跨语言语义对齐的嵌入,同时考虑到其独特的结构和文化复杂性。投资高质量的多语言嵌入并针对特定语言或任务对其进行微调至关重要。这确保了 RAG 系统可以满足任何语言用户的需求——而不仅仅是英语。
但是,不同的嵌入在非英语环境中的实际表现如何?为了探索这一点,我们将使用荷兰数据集比较英语嵌入模型和多语言嵌入模型。此测试将揭示不同的嵌入方法如何影响多语言 RAG 系统中的检索准确性和生成的响应的质量。
比较荷兰 RAG 系统的嵌入模型
为了了解不同的嵌入模型如何处理荷兰语等非英语语言,我们将比较 Amazon Bedrock 上提供的两个模型:Cohere Embed English v3和Cohere Embed Multilingual v3。这些模型代表了不同的嵌入方法 - 一种专门针对英语进行了优化,另一种专为多语言任务而设计。下表总结了它们的主要属性:
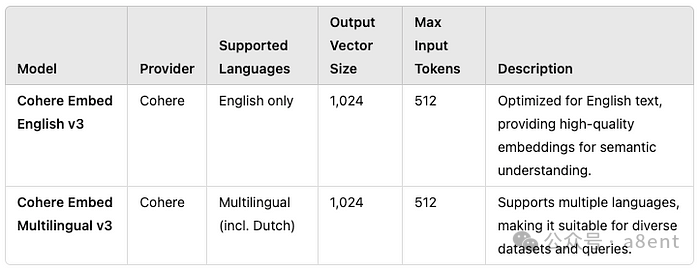
比较嵌入模型
构建嵌入
为了评估嵌入模型的性能,我们将使用 LangChain 框架构建本地向量存储。在此次评估中,我们将使用荷兰语编写的消防员指南作为数据集。此文档包含技术和程序信息,使其成为非英语语言语义检索的现实且具有挑战性的用例。以下是用于创建本地向量存储和索引文档块的干净且精简的代码。我们将使用此设置来测试两个嵌入模型:Cohere Embed English v3和Cohere Embed Multilingual v3。
import os
from langchain\_community.document\_loaders import DirectoryLoader
from langchain.text\_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain\_aws import BedrockEmbeddings
import boto3
\# Step 1: Load documents
loader = DirectoryLoader('data', glob="\*\*/\*.pdf") \# Adjust 'data' to your document directory
documents = loader.load()
print(f"You have {len(documents)} documents")
print(f"Document 1 contains {len(documents\[0\].page\_content)} characters")
\# Step 2: Split documents into smaller chunks
text\_splitter = RecursiveCharacterTextSplitter(chunk\_size=400, chunk\_overlap=50)
chunks = text\_splitter.split\_documents(documents)
print(f"You have {len(chunks)} chunks")
print(f"The first chunk is {len(chunks\[0\].page\_content)} characters long")
\# Step 3: Set up Bedrock embeddings
bedrock\_client = boto3.client("bedrock-runtime", region\_name='us-east-1')
bedrock\_embeddings = BedrockEmbeddings(model\_id="cohere.embed-multilingual-v3", client=bedrock\_client)
\# Step 4: Build the FAISS vectorstore
vectorstore = FAISS.from\_documents(chunks, bedrock\_embeddings)
\# Save the vectorstore locally for reuse
vectorstore.save\_local("faiss\_cohere\_multilingual")
本守则如何运作
-
文档加载:
代码从目录加载所有 PDF 文件data。您可以调整文件路径和格式以匹配您的数据集。 -
文本分割:
将文档分割成 400 个字符的小块,其中 50 个字符重叠,以提高检索准确性。这可确保每个块在上下文上都有意义。 -
嵌入模型:
该类BedrockEmbeddings初始化嵌入模型。您可以替换model_id以测试Cohere Embed English v3 或 Cohere Embed Multilingual v3。 -
本地向量存储:
FAISS 库用于从文档块创建内存中的向量存储。这允许快速进行相似性搜索,并且可以本地保存以供重复使用。
要测试所有模型,请用适当的模型替换初始化model_id中的:BedrockEmbeddings
-
"cohere.embed-english-v3"适用于 Cohere English。 -
"cohere.embed-multilingual-v3"用于 Cohere Multilingual。
评估嵌入模型
为了评估嵌入模型的性能,我们将提出以下问题:“Welke rangen zijn er bij de brandweer?”,翻译为“消防部门内有哪些等级?”。之所以选择这个问题,是因为我们的文档仅使用了术语“hiërarchie”,它在荷兰语中的语义与“rangen”相似。然而,在英语中,“hierarchy”和“ranks”并不具有语义相似性。

我们的荷兰语数据集中提到的 Hiërarchie
这种区别对于我们的测试至关重要。我们预计Cohere Embed English v3模型会难以处理此查询,因为它依赖于英语语义,而术语之间没有关联。另一方面,经过训练可以理解荷兰语语义的Cohere Embed Multilingual v3模型应该可以从文档中检索正确的信息,这证明了它能够处理非英语语言中的语义细微差别。
通过提出这个问题,我们旨在强调语义对齐如何影响荷兰 RAG 系统中的检索性能。此测试将清晰地比较模型处理非英语查询和检索相关信息的能力。结果将展示多语言嵌入对于在非英语环境中实现准确检索的重要性。
为了实现和测试此设置,我们可以使用以下代码。此脚本演示了如何查询向量存储并利用 RAG 链将嵌入与语言模型相结合以回答问题。请注意,在测试不同的嵌入(例如,Cohere Embed English v3与Cohere Embed Multilingual v3)时,您需要确保使用相应的嵌入模型构建向量存储。将向量存储替换为使用您要测试的嵌入模型索引的向量存储,以获得准确的结果。
from langchain.prompts import ChatPromptTemplate
from langchain\_aws import ChatBedrock
from langchain\_core.runnables import RunnablePassthrough
from langchain\_core.output\_parsers import StrOutputParser
instructions = """Je bent een brandweer expert. Beantwoord de vraag, maak gebruik van de context"""
human = """
Dit is de context: {context}
Dit is de vraag: {question}
"""
prompt = ChatPromptTemplate(
messages=\[
SystemMessagePromptTemplate.from\_template(instructions),
HumanMessagePromptTemplate.from\_template(human), #User query will go here
\],
input\_variables=\['context','question'\], \# context provided by retriever and question by the user
)
model = ChatOpenAI(
model="gpt-4", \# or "gpt-3.5-turbo" based on your needs
temperature=0,
max\_tokens=512
)
\# Function to merge text chunks
def format\_docs(docs):
return "\\n\\n".join(doc.page\_content for doc in docs)
\# RAG chain
rag\_chain = (
{"context": vectorstore.as\_retriever(k=10) | format\_docs, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
rag\_chain.invoke("Welke rangen zijn er bij de brandweer?")
嵌入模型的结果
为了评估这两个嵌入模型的性能,我们提出了一个问题:“Welke rangen zijn er bij de brandweer?”(翻译为:“消防部门内有哪些等级?”)。以下是每个模型生成的响应:
Cohere 嵌入英语 v3
回应:
“De tekst geeft geen specifieke informatie over de verschillende rangen binnen de brandweer. Echter, in veel brandweerorganisaties zijn er verschillende rangen zoals brandweerman, luitenant, kapitein, bataljonschef, assistent-chef en brandweerchef. De specifieke rangen kunnen variëren afhankelijk van het land en de specifieke organisatie.”。
分析:
响应是通用的,不依赖于荷兰语文档提供的上下文。这是意料之中的,因为英语嵌入模型很难将“hiërarchie”(在文档中使用)和“rangen”(在查询中使用)之间的语义相似性联系起来。因此,它默认为有关消防部门等级的一般知识。
Cohere Embed 多语言 v3
回应:
“Binnen de brandweer zijn er verschillende rangen. Deze zijn onderverdeeld in het basiskader en het middenkader. In het basiskader hebben we de B01 brandweerman en de B02 korporaal. In het middenkader, dat bestaat uit onderofficieren, hebben we de M01 sergeant en de M02 adjudant. Deze rangen worden aangeduid op het diensttenue, het uitgaanstenue en op de interventiekledij.”。
分析:
此回复高度相关,并准确地从文档中检索信息。多语言嵌入模型成功识别了“hiërarchie”(上下文)和“rangen”(查询)之间的语义关系。它直接根据文档内容提供详细的答案,展示了其有效处理荷兰语特定语义的能力。
关键要点
-
Cohere Embed English v3:由于查询和文档术语之间缺乏语义一致性,英语模型无法从荷兰语文档中检索相关上下文。这凸显了使用特定于英语的嵌入来处理非英语任务的局限性。
-
Cohere Embed Multilingual v3:多语言模型在本次测试中表现出色,从荷兰语文档中检索并利用了上下文相关信息。这表明多语言嵌入对于实现准确检索和有效回答非英语查询的重要性。
结论
这项评估为任何为非英语语言构建检索增强生成 (RAG) 系统的人都强调了一个关键见解:嵌入很重要,尤其是当任务需要跨语言的细微理解时。Cohere Embed English v3 和 Cohere Embed Multilingual v3 模型之间的性能对比说明了非英语环境中特定于英语的嵌入的局限性以及多语言模型的巨大价值。
当用荷兰语回答查询时,多语言模型表现出色,直接从文档中检索出准确且语境丰富的信息。与此同时,英语嵌入模型默认使用通用的、不相关的知识,表明它无法弥合查询和文档内容之间的语义鸿沟。
对于在全球多语言环境中开发 AI 系统的组织,此测试强调了为手头的任务选择正确的嵌入模型的重要性。多语言嵌入不仅仅是一个“锦上添花”的功能;它们对于确保非英语应用程序的准确性、相关性和用户信任至关重要。
随着生成式人工智能的影响力不断扩大,通过更好的嵌入来拥抱语言多样性将成为在全球范围内提供有意义且有影响力的解决方案的关键。通过优先考虑多语言能力,企业可以创建不仅更智能而且更具包容性的系统,从而为跨语言和文化的用户提供支持。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









