







🔍 大模型真的能进行逻辑推理吗?
近年来,大型语言模型(LLMs)在推理任务上的表现令人惊叹,但它们是否真正具备严谨的逻辑推理能力?OpenAI的 o3 和 DeepSeek-R1 等先进模型的崛起,让学界开始重新审视这一问题。逻辑推理不同于一般的类比或模式识别,它要求模型能够遵循严格的规则进行推导,类似于数学证明或法律推理。那么,当前的大模型在逻辑推理上的表现如何?又有哪些提升的可能性?
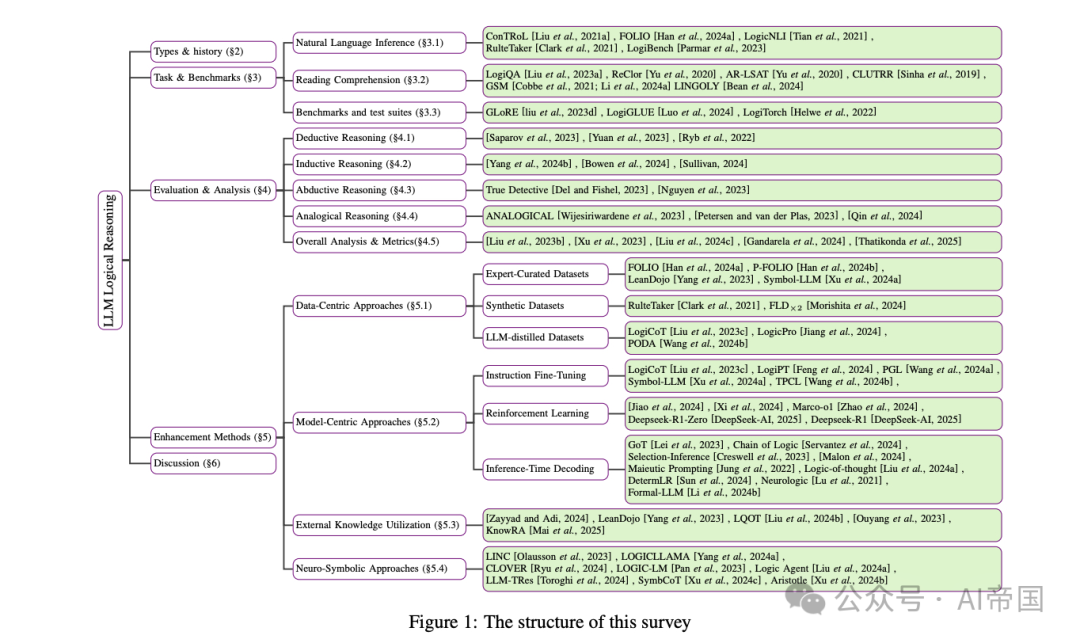
🧠 四大逻辑推理方式:LLMs 真的能做到吗?
论文系统性地梳理了逻辑推理的四大主要范式,并分析了 LLMs 在这些任务上的表现:
1.演绎推理(Deductive Reasoning): 依据普遍规则推导具体结论(如数学证明)。现有 LLMs 能在特定任务上表现良好,但在长链推理、假设检验等方面仍然薄弱。
2.归纳推理(Inductive Reasoning): 通过具体案例总结一般规律(如科学发现)。研究表明,即使是最先进的 LLM,在归纳任务上也经常出现泛化失败,无法形成稳定的推理模式。
3.溯因推理(Abductive Reasoning): 从已知结果推测最可能的原因(如医学诊断)。当前 LLMs 难以有效处理缺失信息,推测出的结论往往不够严谨。
4.类比推理(Analogical Reasoning): 通过相似性类比来推导新知识(如法律判例)。虽然 LLMs 能在简单的类比推理上接近人类水平,但面对复杂场景时,其表现仍然欠缺稳定性。
研究显示,尽管 LLMs 能在某些任务上展现出令人惊艳的推理能力,但在严格的逻辑推理框架下,它们仍然远远不如人类。
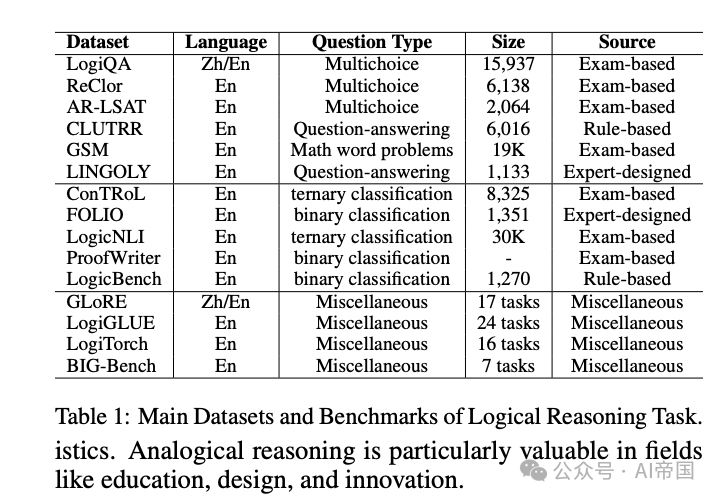
**
**
🔬 提升 LLM 逻辑推理能力的新方法
论文总结了当前主流的增强 LLM 逻辑推理能力的方法,主要包括:
-
数据增强(Data-centric tuning): 通过高质量的逻辑推理数据集,如 FOLIO、LogiQA 进行训练,提高模型的逻辑一致性。
-
强化学习(Reinforcement Learning): 通过自我博弈和反馈机制,让 LLM 在推理任务上不断优化决策。
-
神经-符号结合(Neuro-symbolic approaches): 将传统符号逻辑方法(如自动定理证明器)与神经网络结合,以提升逻辑推理能力。
-
推理优化(Decoding strategies): 通过更合理的采样和搜索方法,提高推理的稳定性和正确率。
研究表明,纯数据驱动的方法无法彻底解决 LLM 逻辑推理的瓶颈,未来可能需要结合符号逻辑和混合推理策略,才能让大模型在复杂推理任务上表现得更可靠。
📌 未来展望:如何让 LLM 具备真正的逻辑推理能力?
尽管 LLM 在推理任务上取得了重要突破,但目前仍面临泛化能力差、推理一致性不足、缺乏可解释性等挑战。未来,研究者认为可以通过以下方向进一步突破:
-
构建更强的混合推理架构,结合神经网络与符号逻辑,提升模型的严谨性和可解释性。
-
优化评测体系,开发更复杂的逻辑推理基准测试,推动 LLM 在不同推理范式下的能力提升。
-
探索跨模态逻辑推理,使 LLM 在文本、图像、代码等不同领域实现推理能力的迁移。
总的来说,这篇论文不仅总结了 LLM 在逻辑推理上的能力边界,还提出了多种增强策略,为未来的 AI 逻辑推理研究提供了清晰的方向。
论文PDF已整理,需要的下方直接领取!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









