






deepseek满血版昇腾显卡部署指南,网上有很多相关的教程,但是实际操作下来发现有非常多的坑,这里记录一下部署的流程,希望给国产化部署的朋友一些帮助。
现在各大平台好多提供了deepseek-r1满血版的推理服务,在网上看到一个比较有意思的检测
是否满血的prompt,可以试一下

测试一下deepseek官方的回答:

再看一下使用昇腾部署的回答:

昇腾官方有出一个部署指南,本文也是参考该教程进行的,虽然有很多槽点,但是依然是一个不错的参考。
模型权重
第一步是模型权重的下载,对于满血版R1这个庞然大物,如果网速不够快,下载起来还是非常麻烦的,我尝试了多个下载渠道,最终使用了魔乐社区,峰值速度达80M/s,全部下载完也就一小时左右,速度非常可观。可以看一下官方的介绍,所言非虚,推荐使用。
下载的时候需要导入一个白名单,否则自定义位置报错
from openmind_hub import snapshot_download
snapshot_download(
repo_id="State_Cloud/DeepSeek-R1-origin",
local_dir="xxx",
cache_dir="xxx",
local_dir_use_symlinks=False,
)
然后就是权重转换了,需要将FP8的转成FP16,可以使用昇腾里DeepSeek-V3的权重转换脚本
DeepSeek-R1在转换前权重约为640G左右,在转换后权重约为1.3T左右,记得提前规划好存储的位置,避免中断。
另外这里提一下,在部署的时候,有遇到一个错误,就是加载权重的时候,好像对软链接不支持,因此这里在下载的时候,可以关闭软链接,设置参数local_dir_use_symlinks=False即可。
对于昇腾机器的的要求,BF16的R1需要至少需要4台Atlas 800I A2(8*64G)服务器,W8A8量化版本则至少需要2台Atlas 800I A2 (8*64G) , 我在部署的时候使用的是量化版本,用的是两台Atlas 800T A2
如果不想经过上述的权重转换步骤,又需要部署W8A8的量化版本,可以直接下载社区里转换好的权重,下载量已经到了6k+,可以使用。
下载后的模型权重,需要管理一下权限,方便后续读取:
chown -R 1001:1001 /path-to-weights/DeepSeek-R1
chmod -R 750 /path-to-weights/DeepSeek-R1
镜像部分
昇腾官方出了可以直接部署的镜像,方便开发者一键启动
镜像链接:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
目前提供的MindIE镜像预置了DeepSeek-R1模型推理脚本,无需再下载模型代码
这里的镜像需要申请,通过后才能下载
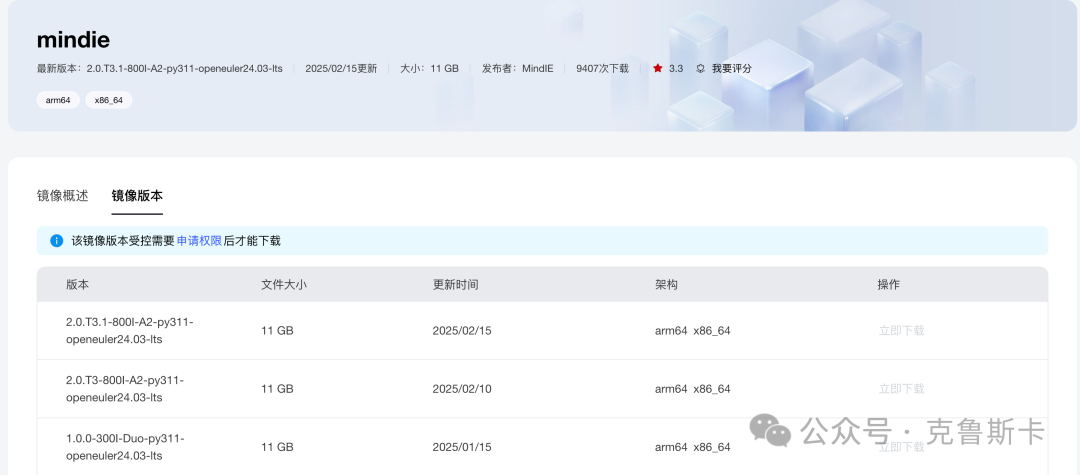
执行命令:
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.0.T3-800I-A2-py311-openeuler24.03-lts
拉取镜像后,需要启动容器,可以使用下面的命令,与官方教程有些区别
docker run -itd --privileged --name=deepseek-r1 --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/bin/hccn_tool:/usr/bin/hccn_tool \
-v /usr/local/sbin:/usr/local/sbin \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /etc/hccn.conf:/etc/hccn.conf \
-v xxxxxx/DeepSeek-R1-weight:/workspace \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.0.T3-800I-A2-py311-openeuler24.03-lts \
bash
--name 容器名, -v 挂载下载好的模型
其中需要注意的地方在于,把下载好模型权重的位置,挂载到容器中,可以放到workspace目录下,这样后面部署的时候,就可以使用了
其它的挂载盘都是常规的驱动或者工具,确保本地可以正常运行,一般是没问题的
多台服务器部署,每台服务器下载同样的模型权重,位置可以不同,但是都需要执行上述启动容器的命令,把挂载盘换一下

进入容器
启动好容器之后,接下来的操作都默认在容器中
首先便是进入容器,假设上述容器名字为deepseek-r1
docker exec -it deepseek-r1 bash
容器检查
进入容器之后,先检查一下机器的网络情况,如果有问题,可以先查一下本机是否正常 如果本机正常,容器内有问题,那应该是有些目录没有挂载好,可以问下G老师或者D老师
# 检查物理链接
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done
# 检查链接情况
for i in {0..7}; do hccn_tool -i $i -link -g ; done
# 检查网络健康情况
for i in {0..7}; do hccn_tool -i $i -net_health -g ; done
# 查看侦测ip的配置是否正确
for i in {0..7}; do hccn_tool -i $i -netdetect -g ; done
# 查看网关是否配置正确
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done
# 检查NPU底层tls校验行为一致性,建议全0
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
# NPU底层tls校验行为置0操作
for i in {0..7};do hccn_tool -i $i -tls -s enable 0;done
配置多机多卡文件
这个文件比较关键,配置好之后,后续的MindIE推理框架也会参考这个进行启动,不需要再额外设置
配置起来也比较简单,使用这个命令,把每张卡的ip地址记录下来
for i in {0..7};do hccn_tool -i $i -ip -g; done
每台机器都执行一次,其中,确定一台主节点
-
server_count:一共使用几台服务器,即节点数。server_list中第一个server为主节点
-
device_id:当前卡的本机编号,取值范围[0, 本机卡数)
-
device_ip:当前卡的ip地址,可通过hccn_tool命令获取
-
rank_id:当前卡的全局编号,取值范围[0, 总卡数)
-
server_id:当前节点的ip地址
-
container_ip:容器ip地址(服务化部署时需要),若无特殊配置,则与server_id相同
查看服务器的ip地址
hostname -I
查看docker容器的ip地址
docker inspect 容器id | grep "IPAddress"
如果返回为空,可能是使用和宿主机一样的网络,查看容器的网络模式
docker inspect 容器id | grep -i '"NetworkMode"'
如果返回为 "NetworkMode": "host", 则说明容器使用的是 host 网络,它没有自己的 IP,而是直接用 宿主机 IP。
下面是两个节点的配置文件,对着填好ip地址即可
{
"server_count": "2",
"server_list": [
{
"device": [
{"device_id": "0", "device_ip": "xxxx", "rank_id": "0"},
{"device_id": "1", "device_ip": "xxxx", "rank_id": "1"},
{"device_id": "2", "device_ip": "xxxx", "rank_id": "2"},
{"device_id": "3", "device_ip": "xxxx", "rank_id": "3"},
{"device_id": "4", "device_ip": "xxxx", "rank_id": "4"},
{"device_id": "5", "device_ip": "xxxx", "rank_id": "5"},
{"device_id": "6", "device_ip": "xxxx", "rank_id": "6"},
{"device_id": "7", "device_ip": "xxxx", "rank_id": "7"}
],
"server_id": "xxxx",
"container_ip": "xxxx"
},
{
"device": [
{"device_id": "0", "device_ip": "xxxx", "rank_id": "8"},
{"device_id": "1", "device_ip": "xxxx", "rank_id": "9"},
{"device_id": "2", "device_ip": "xxxx", "rank_id": "10"},
{"device_id": "3", "device_ip": "xxxx", "rank_id": "11"},
{"device_id": "4", "device_ip": "xxxx", "rank_id": "12"},
{"device_id": "5", "device_ip": "xxxx", "rank_id": "13"},
{"device_id": "6", "device_ip": "xxxx", "rank_id": "14"},
{"device_id": "7", "device_ip": "xxxx", "rank_id": "15"}
],
"server_id": "xxxx",
"container_ip": "xxxx"
}
],
"status": "completed",
"version": "1.0"
}
开启通信环境变量
export ATB_LLM_HCCL_ENABLE=1
export ATB_LLM_COMM_BACKEND="hccl"
export HCCL_CONNECT_TIMEOUT=7200
export WORLD_SIZE=32
export HCCL_EXEC_TIMEOUT=0
权重目录下config.json文件,将 model_type 更改为 deepseekv2 (全小写且无空格)
精度测试
官方给的精度测试例子,与我下载的镜像中的目录对不上,并且执行full_CEval的测试也会报错,缺少文件 modeltest路径,在镜像中的实际位置是:/usr/local/Ascend/atb-models/tests/modeltest
测试命令:
# 需在所有机器上同时执行
bash run.sh pa_bf16 [dataset] ([shots]) [batch_size] [model_name] ([is_chat_model]) [weight_dir] [rank_table_file] [world_size] [node_num] [rank_id_start] [master_address]
性能测试
性能测试是在同样的目录下,但是是可以执行成功的
运行命令
bash run.sh pa_bf16 performance [[256,256]] 16 deepseekv2 /path/to/weights/DeepSeek-R1 /path/to/xxx/ranktable.json 16 2 0 {主节点IP}
# 0 代表从0号卡开始推理,之后的机器依次从8,16,24。
跑完会生成一个csv文件,里面保存了本次测试的指标,比如
| Model | Batchsize | In_seq | Out_seq | Total time(s) | First token time(ms) | Non-first token time(ms) | Non-first token Throughput(Tokens/s) | E2E Throughput(Tokens/s) | Non-first token Throughput Average(Tokens/s) | E2E Throughput Average(Tokens/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| deepseekv2 | 16 | 256 | 256 | 18.6202795506 | 478.01 | 71.03 | 225.25693369 | 219.9752151346 | 225.25693369 | 219.9752151346 |
参数解释:
-
Batch size,批次大小
-
输入序列长度(In_seq)
-
输出序列长度(Out_seq)
-
总耗时(Total time)
-
首 token 生成耗时(First token time)
-
非首 token 平均生成耗时(Non-first token time)
-
非首 token 吞吐率(Throughput)
-
端到端吞吐率(E2E Throughput)
推理部署
上述的两个测试都是可选的,性能测试可以跑一下,调一下bs,看看能跑出什么样的效果
启动前需要配置一下容器,每个容器都执行一下:
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export MIES_CONTAINER_IP=容器ip地址
export RANKTABLEFILE=rank_table_file.json路径
export OMP_NUM_THREADS=1
export NPU_MEMORY_FRACTION=0.95
注意,上述的路径是指容器内的路径,并且每台机器的ip都要对应正确
执行完后,每台机器都要对应修改服务化参数,即部署的参数配置
因为这个文件是在容器中,需要用vim修改,比较麻烦,这里推荐一个方法
将该文件复制一份到宿主机上,使用的命令是:
docker cp 镜像id:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json /本地目录
这样,你可以在宿主机上进行修改json文件,方便快捷,因为每台机器都是一样的配置,因此,修改好后,每台机器复制一份就可以了。 改完之后,需要在传回到镜像中,使用
docker cp 本地目录/config.json 容器id:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json
这样就完成了配置文件的修改,这个配置文件后续需要调整,这种方式省去了很多麻烦
下面是官方给的配置,如果想要部署的模型推理更快或者输入输出更长,都需要对应的调整该文件的参数,这部分暂时没有什么好的建议,目前我设置的是32k,可以正常部署起来,推理速度还可以
详细的参数介绍参考这个
{
"Version" : "1.0.0",
"LogConfig" :
{
"logLevel" : "Info",
"logFileSize" : 20,
"logFileNum" : 20,
"logPath" : "logs/mindie-server.log"
},
"ServerConfig" :
{
"ipAddress" : "改成主节点IP",
"managementIpAddress" : "改成主节点IP",
"port" : 1025,
"managementPort" : 1026,
"metricsPort" : 1027,
"allowAllZeroIpListening" : false,
"maxLinkNum" : 1000, //如果是4机,建议300
"httpsEnabled" : false,
"fullTextEnabled" : false,
"tlsCaPath" : "security/ca/",
"tlsCaFile" : ["ca.pem"],
"tlsCert" : "security/certs/server.pem",
"tlsPk" : "security/keys/server.key.pem",
"tlsPkPwd" : "security/pass/key_pwd.txt",
"tlsCrlPath" : "security/certs/",
"tlsCrlFiles" : ["server_crl.pem"],
"managementTlsCaFile" : ["management_ca.pem"],
"managementTlsCert" : "security/certs/management/server.pem",
"managementTlsPk" : "security/keys/management/server.key.pem",
"managementTlsPkPwd" : "security/pass/management/key_pwd.txt",
"managementTlsCrlPath" : "security/management/certs/",
"managementTlsCrlFiles" : ["server_crl.pem"],
"kmcKsfMaster" : "tools/pmt/master/ksfa",
"kmcKsfStandby" : "tools/pmt/standby/ksfb",
"inferMode" : "standard",
"interCommTLSEnabled" : false,
"interCommPort" : 1121,
"interCommTlsCaPath" : "security/grpc/ca/",
"interCommTlsCaFiles" : ["ca.pem"],
"interCommTlsCert" : "security/grpc/certs/server.pem",
"interCommPk" : "security/grpc/keys/server.key.pem",
"interCommPkPwd" : "security/grpc/pass/key_pwd.txt",
"interCommTlsCrlPath" : "security/grpc/certs/",
"interCommTlsCrlFiles" : ["server_crl.pem"],
"openAiSupport" : "vllm"
},
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 1,
"npuDeviceIds" : [[0,1,2,3,4,5,6,7]],
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : true,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : false,
"interNodeTlsCaPath" : "security/grpc/ca/",
"interNodeTlsCaFiles" : ["ca.pem"],
"interNodeTlsCert" : "security/grpc/certs/server.pem",
"interNodeTlsPk" : "security/grpc/keys/server.key.pem",
"interNodeTlsPkPwd" : "security/grpc/pass/mindie_server_key_pwd.txt",
"interNodeTlsCrlPath" : "security/grpc/certs/",
"interNodeTlsCrlFiles" : ["server_crl.pem"],
"interNodeKmcKsfMaster" : "tools/pmt/master/ksfa",
"interNodeKmcKsfStandby" : "tools/pmt/standby/ksfb",
"ModelDeployConfig" :
{
"maxSeqLen" : 10000,
"maxInputTokenLen" : 2048,
"truncation" : true,
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "deepseekr1",
"modelWeightPath" : "/home/data/dsR1_base_step178000",
"worldSize" : 8,
"cpuMemSize" : 5,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false
}
]
},
"ScheduleConfig" :
{
"templateType" : "Standard",
"templateName" : "Standard_LLM",
"cacheBlockSize" : 128,
"maxPrefillBatchSize" : 8,
"maxPrefillTokens" : 2048,
"prefillTimeMsPerReq" : 150,
"prefillPolicyType" : 0,
"decodeTimeMsPerReq" : 50,
"decodePolicyType" : 0,
"maxBatchSize" : 8,
"maxIterTimes" : 1024,
"maxPreemptCount" : 0,
"supportSelectBatch" : false,
"maxQueueDelayMicroseconds" : 5000
}
}
}
启动服务
启动命令也比较简单
cd /usr/local/Ascend/mindie/latest/mindie-service
nohup ./bin/mindieservice_daemon > /workspace/output.log 2>&1 &
这里最好是把启动服务的命令挂后台,这样能查看日志,否则关闭终端后,虽然服务不掉,但是日志是找不到了,不方便debug
执行命令后,首先会打印本次启动所用的所有参数,然后直到出现以下输出:
Daemon start success!
则认为服务成功启动。
到这里可以认为是部署成功了,还有最后一步的测试:
curl -X POST http://{ip}:{port}/v1/chat/completions \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1",
"messages": [{
"role": "user",
"content": "你好"
}],
"max_tokens": 20,
"presence_penalty": 1.03,
"frequency_penalty": 1.0,
"seed": null,
"temperature": 0.5,
"top_p": 0.95,
"stream": true
}'
注意,官方教程里是没有开启HTTPS通信,后续调用的时候用http,而不是https
使用https需要配置开启HTTPS通信所需服务证书、私钥等证书文件
以上能看到输出,就算是部署成功了
最后是适配OpenAI式的推理接口,可以参考
有些槽点不得不提:
整个部署流程基本按照官方教程来的,但是一步一坑,各种稀奇古怪的问题,主要还找不到日志,容器里的目录翻了一遍,没有几个能看到实质性报错的内容,一般可以从/root/mindie下找到一些。 网上也很少能搜到对应的问题,部署帖子如果能有个讨论的空间就好了,方便避坑
另外就是,这教程写的有些地方对不上(可能是我操作不对),很奇怪。比如测试的目录,刚开始很困惑,检查了数遍才在另外的目录下找到
还有一些问题,排查不出来,最后找华为老师解决的,还是很感谢快速的支持,希望国产越来越好。
部署问题,加载tokenizer失败 解决方式:检查tokenizer.json 文件是否和官网一致,并且检查一下权限,是否能正常读取
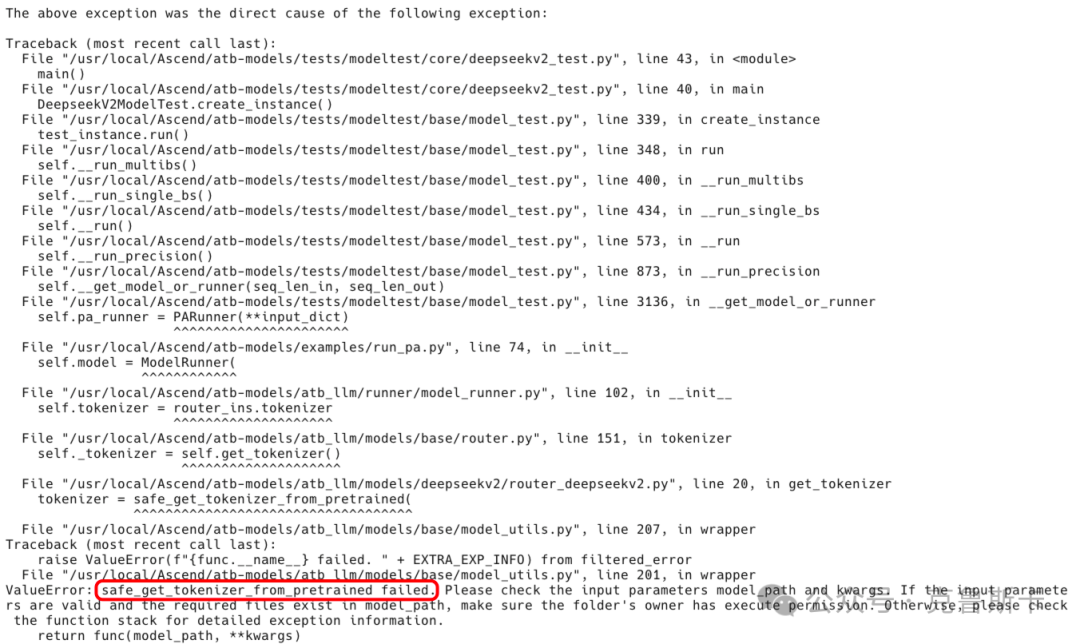
还遇到一个问题,比如下面这个
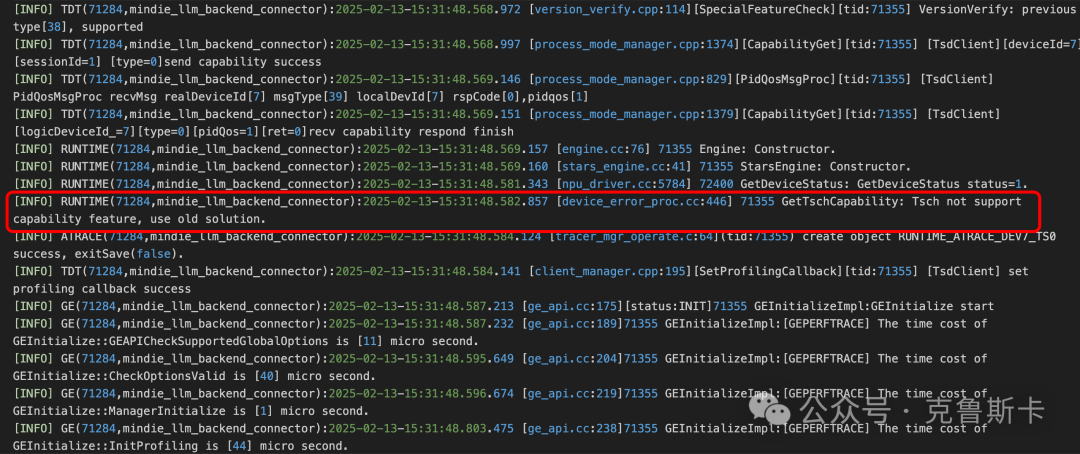
只看日志,好像也看不出是什么原因,最终的解决方案是:升级驱动!
有类似问题是hccn 导致的,升级到24.1.0很多问题就自然的解决了,遇到难以解决的问题,不要怀疑自己..
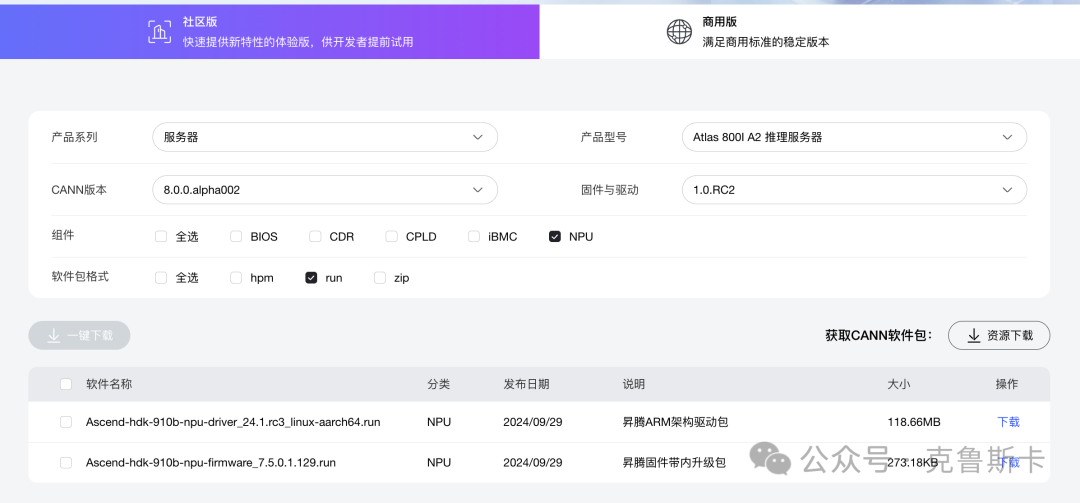
cann 不用升级,只需升级昇腾NPU固件和驱动
选择欧拉系统,注意,这里可以选择800I A2推理服务器,推理速度更快
下载完这两个文件,正常按照流程安装即可

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









