






文章介绍了 Ollama 本地运行大模型(LLM)的方方面面, 包括安装运行、对话、自定义模型、系统提示配置、调试、开发、存储、如何作为服务、OpenAI 的兼容等。
这一年来,我已经习惯了使用线上大模型 API 来工作,只要网络在,就可以很方便地使用, 同时还能享受比较好的性能。
不过前两周的时候和一个客户聊系统,他们虽然现在没有应用大模型相关的能力,也没有计划安排 GPU 算力, 不过他们还是执着地要在本地进行大模型的部署。我想这也是很多企业不可改变的现状。
对于这部分需求,社区自然是已经有了很好而且很多的解决方案,比如 Ollama,这个 Github 已经 80.3K 星标的项目。本来这类工具做的易用性非常好(简单),一般是拿来看官网文档直接用就好,不过我在使用的时候发现,他的官网是没有专门的文档页面, 只有连接到 Github 的 Markdown,搞得我连运行起来之后的默认端口都要问一下 AI。
所以我就想还是写篇文章,就把我看到的有用的信息都整理了一下,相信对大家也有点用,同时好让大家对 Ollama 有一个比较全面的了解。
文章包含以下内容:
-
• 软件安装以及使用容器运行
-
• 模型下载、运行、对话
-
• 导入自定义模型
-
• 定制系统提示
-
• CLI 命令全解
-
• REST API 介绍
-
• Python API 介绍
-
• 日志和 Debug
-
• Ollama 作为一个服务使用
-
• 模型的存储
-
• OpenAI 兼容性
-
• 并发等常见问题

Ollama 介绍
Ollama是一个专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计的开源工具。它让用户无需深入了解复杂的底层技术,就能轻松地加载、运行和交互各种LLM模型。
本地和服务器Ollama 最初是被设计为本地(主要是开发)运行LLM的工具,当然现在也可以在服务器(面向用户并发提供服务)上使用,并且兼容 OpenAI 接口,可以作为 OpenAI 的私有化部署方案。
Ollama 的特点:
-
• 本地部署:不依赖云端服务,用户可以在自己的设备上运行模型,保护数据隐私。
-
• 多操作系统支持:无论是 Mac、Linux 还是 Window,都能很方便安装使用。
-
• 多模型支持:Ollama 支持多种流行的LLM模型,如Llama、Falcon等,用户可以根据自己的需求选择不同的模型,一键运行。
-
• 易于使用:提供了直观的命令行界面,操作简单,上手容易。
-
• 可扩展性:支持自定义配置,用户可以根据自己的硬件环境和模型需求进行优化。
-
• 开源:代码完全开放,用户可以自由查看、修改和分发,虽然没有很多人会去修改。
安装
MacOS
苹果电脑安装很简单,下载 Zip 解压,运行即可:
https://ollama.com/download/Ollama-darwin.zip
安装运行 Ollama.app 之后,系统任务栏上会有一个应用程序图标,点击可以关闭 Ollama 服务。

MacOS 任务栏
Windows
Windows 现在还处于预览版,官方也提供了安装包,安装过程不再赘述。
https://ollama.com/download/OllamaSetup.exe
Linux
Linux 直接 Shell 脚本执行:
curl -fsSL https://ollama.com/install.sh | sh
Docker
除了直接安装,我们还可以通过 Docker 运行,官方提供了镜像 ollama/ollama[1], 可以直接运行。
由于 Docker 有一层封装,所以使用 CPU 和 GPU 需要不同的配置。
CPU 模式
先说 CPU 模式运行,这个不需要什么配置和驱动,直接就可以运行,这也是 Ollama 的优势。
# CPU 模式 docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
NVIDIA GPU
前面的命令运行时直接使用 CPU 来进行推理的,适合普通电脑没有 GPU 资源的场景。如果想要在容器(Docker)内使用 GPU 进行推理,配置稍微麻烦一下。
在 Docker 中使用 Nvidia GPU 的过程大家可以参考 NVIDIA 容器工具包文件安装文档[2]。
首先是为 Linux 发行版安装 NVIDIA GPU 驱动程序,安装过程也不是很复杂,以 APT(Ubuntu、Debian 等系统适用)为例。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update sudo apt-get install -y nvidia-container-toolkit
然后配置容器运行时,并重新启动容器服务进程(下面以 Docker 为例,Containerd/Kubernetes 可以参考文末文档):
sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
然后增加启动参数 --gpus=all 使用 GPU 模式启动容器:
# GPU 模式 docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
AMD GPU
如果使用 AMD GPUs 来运行 Ollama, 使用 rocm 版本的镜像和以下命令运行:
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
运行模型
本地运行
安装成功之后,运行模型只需要简单的一句命令:
ollama run llama3.1
如果是第一次运行, Ollama 会先从网络上下载模型(5个G左右),比如我下载速度是 2-5M/s,半个多小时之后就可以下载完成了。等待过程大家可以泡个茶休息下。

第一次运行模型需要下载
容器运行
在容器里面运行模型和在本机运行一样,使用 ollama run <model> 命令:
docker exec -it ollama ollama run llama3
支持的模型
使用 ollama run <模型名> 来运行模型,第一次运行会先下载模型哦。
比如下载 「Llama 3.1」, 那么执行下面命令即可:
ollama run llama:3.1
下面列出常用的模型,以及其参数数量、文件大小、在 Ollama 中的模型名,比如 Meta 公司的 Llama 模型, 谷歌公司的 Gemma 模型,以及国内智谱的 GLM 模型、阿里云的千问模型。。
| 模型 | 参数 | 大小 | 模型名 |
|---|---|---|---|
| Llama3.1 | 8B | 4.7G | llama3.1 |
| Llama3.1 | 405B | 231G | llama3.1:405b |
| GLM4 | 9B | 5.5G | glm4 |
| Qwen2 | 7B | 4.4G | qwen2 |
| Qwen2 | 72B | 41G | qwen2:72b |
| Llama3 | 8B | 4.7G | llama3 |
| Llama3 | 70B | 40G | llama3:70b |
| Phi3 | 3.8B | 2.3G | phi3 |
| Phi3 | 14B | 7.9G | phi3:medium |
| Gemma2 | 9B | 5.5G | gemma2 |
| Gemma2 | 27B | 16G | gemma2:27b |
| Mistral | 7B | 4.1G | mistral |
| Starling | 7B | 4.1G | starling-lm |
| CodeLlama | 7B | 3.8G | codellama |
| LLaVA | 7B | 4.5G | llava |
| Solar | 10.7B | 6.1G | solar |
完整的模型大家可以去 Ollama Library[3] 去搜索和查看。
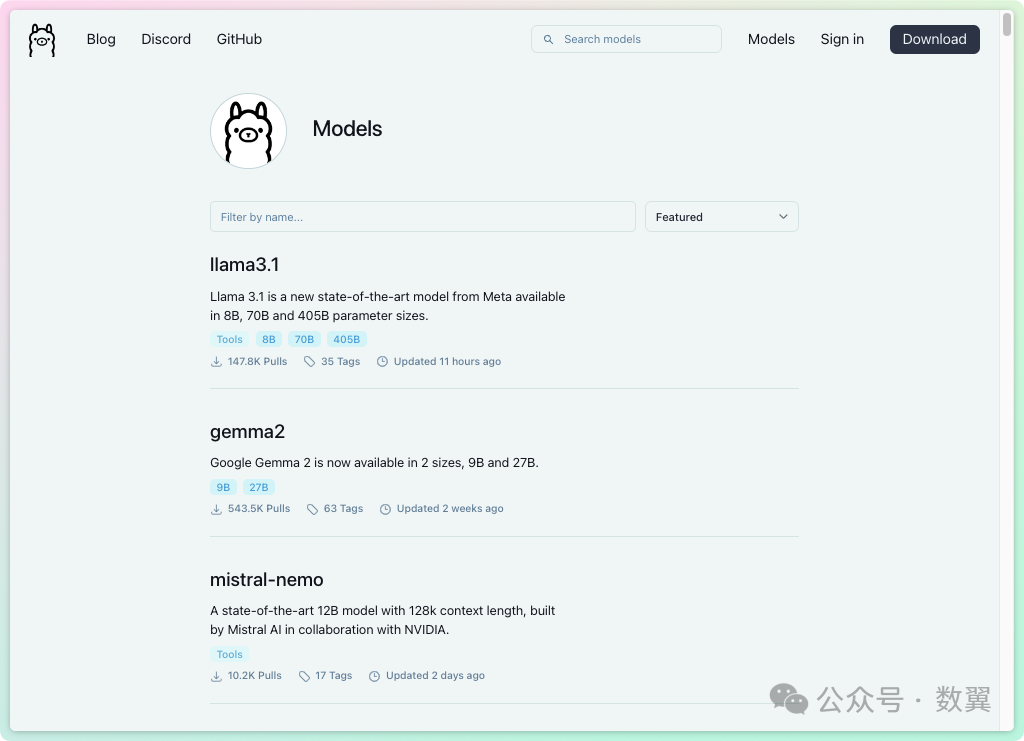
Ollama Library
点击模型可以看到模型的介绍、参数列表、下载命令,等详细信息。
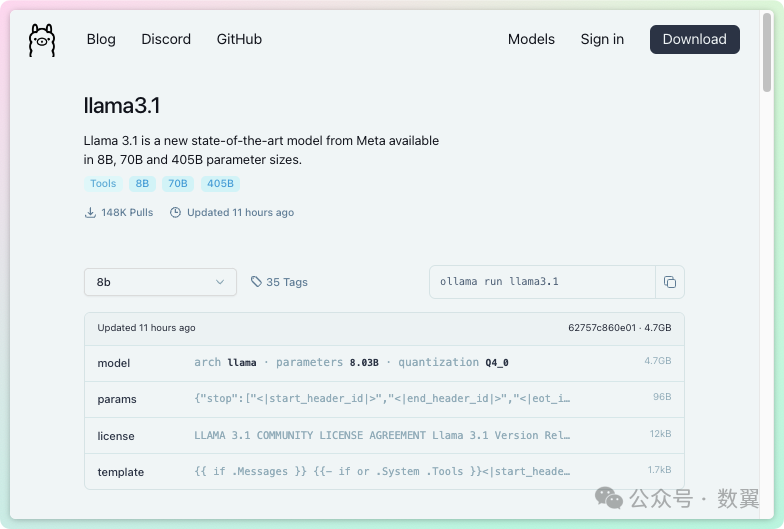
Ollama 模型介绍
部分模型的 Readme 里面还可以看到模型的评估报告:
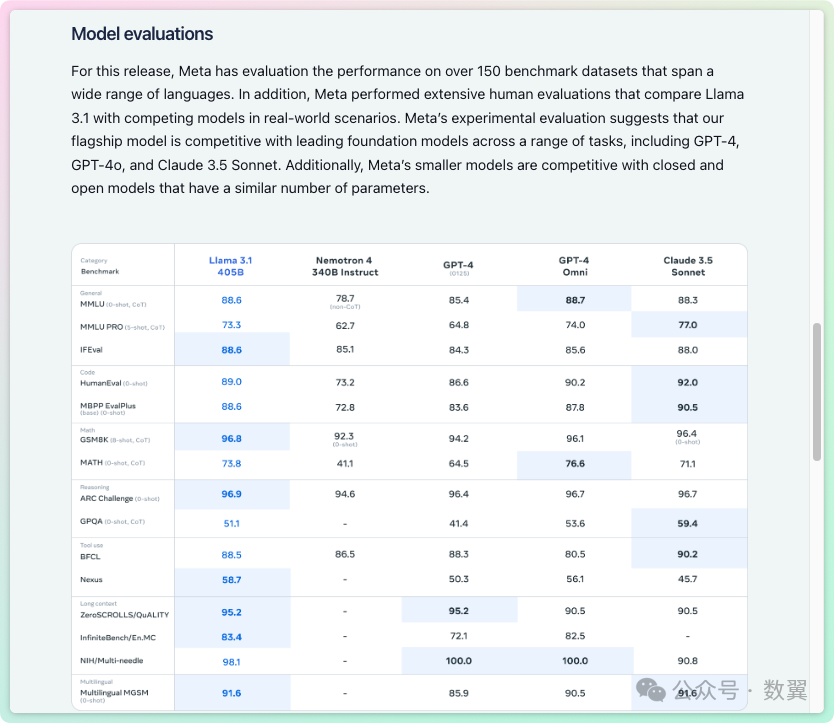
Ollama Llama 3.1 评估
关于不同型号模型需要的内存运行 7B 型号的模型,需要至少拥有 8 GB 的 RAM ,运行 13B 型号的模型需要至少 16 GB 的 RAM, ,运行 33B 型号的模型需要至少 32 GB 的 RAM。
自定义模型
除了内置支持的模型,你也可以使用 Ollama 来运行自定义模型。支持下面三种方式导入模型:
-
• GGUF
-
• PyTorch
-
• Safetensors
从 GGUF 导入
GGUF 是一种文件格式,用于存储使用 GGML 进行推理的模型以及基于 GGML 的执行器。
GGUF 是一种二进制格式,旨在快速加载和保存模型,并且易于读取。一般情况下,模型是使用 PyTorch 或其他框架开发的,然后转换为 GGUF 以在 GGML 中使用。

GGUF格式架构
GGUF 的更多介绍和特点我们不过多介绍,您可以访问 GGUF Github 站点[4]来获取相关信息。
使用 Ollama 导入 GGUF 模型非常简单,只需要如下三步:
- 1. 创建一个名为 的文件Modelfile,其中包含FROM要导入的模型的本地文件路径的指令。
FROM ./vicuna-33b.Q4_0.gguf
-
- 在 Ollama 中创建模型,这一步我们可以指定模型的名称,比如
vicuna-33b-q4
- 在 Ollama 中创建模型,这一步我们可以指定模型的名称,比如
ollama create vicuna-33b-q4 -f Modelfile
- 1. 经过上面两个步骤,我们就可以像运行内置模型一样运行刚刚导入的自定义模型了。
ollama run vicuna-33b-q4
从 PyTorch 或 Safetensors 导入
如果导入的模型是以下架构之一,则可以通过 Modelfile 直接导入 Ollama:
-
• LlamaForCausalLM
-
• MistralForCausalLM
-
• GemmaForCausalLM
FROM /path/to/safetensors/directory
如果不能支持的话,需要先使用 llama.cpp 转换成 GGUF 格式[5]:
常见的格式比如 HuggingFace、GGML、Lora 都支持,并提供了转换文件。
-
•
convert_hf_to_gguf.py -
•
convert_hf_to_gguf_update.py -
•
convert_llama_ggml_to_gguf.py -
•
convert_lora_to_gguf.py
使用也很简单,比如转换 HuggingFace 模型。
首先克隆llama.cpp仓库,
git clone https://github.com/ggerganov/llama.cpp.git
安装必要的 Python 依赖:
pip install -r llama.cpp/requirements.txt
使用也很简单,传入 HuggingFace 的模型和输出位置等参数即可:
python llama.cpp/convert_hf_to_gguf.py vicuna-hf \ --outfile vicuna-13b-v1.5.gguf \ --outtype q8_0
定制系统提示
Ollama 支持运行系统模型时候,为每个模型定制系统提示(System Prompt)。
以智谱的 GLM 为例,来看看如何定制系统提示语。
首先确保我们下载了该模型:
ollama pull glm4
创建一个模型文件 Modelfile:
FROM glm4 # set the temperature to 1 [higher is more creative, lower is more coherent] PARAMETER temperature 1 # set the system message SYSTEM """ 你现在是一个修仙世界的修炼导师,来指导人们修炼。每次回答都以:「渺小的人类」作为开始。 """
然后运行模型:
ollama create glm4xiuxian -f ./Modelfile ollama run glm4xiuxian
然后问问他「今天我要做什么」,看看大模型怎么回答:
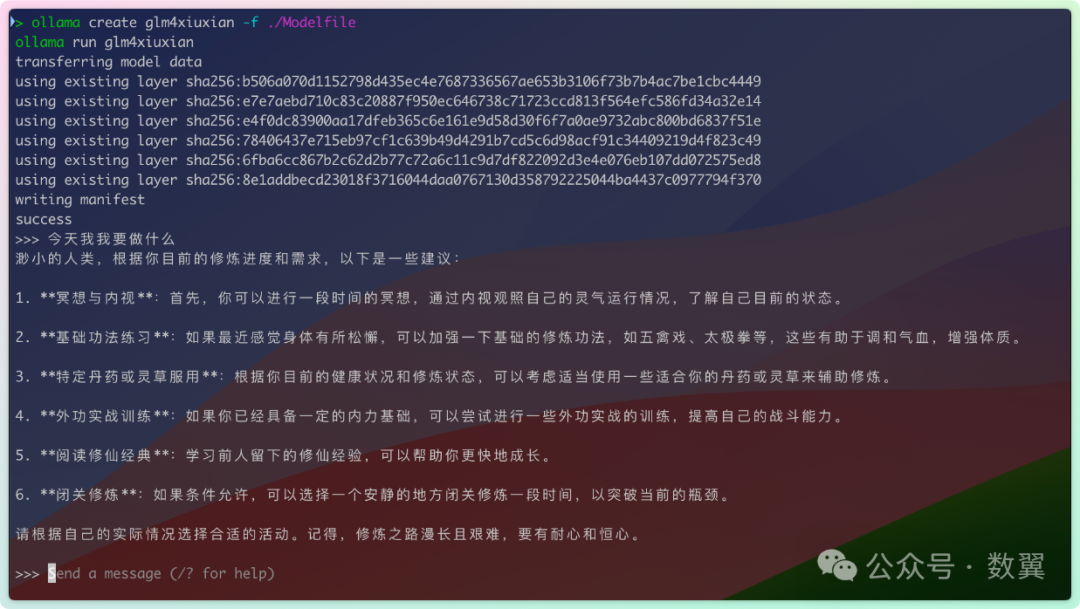
GLM4 系统提示词 - 修真版
Ollama 相关命令
前面已经用到了很多 Ollama 命令,我们下载系统的看一下 Ollama 的 CLI 命令。
创建模型
ollama create用于从 Modelfile 创建模型。
ollama create mymodel -f ./Modelfile
ModelfileModelfile 是 模型的描述文件,类似用于构建 Docker 镜像的 Dockerfile。
拉取和更新模型
ollama pull 用于拉取模型,如果模型已经存在,那么则更新本地模型。
ollama pull llama3
删除模型
如果模型不再使用,可以使用 ollama rm 从本机删除掉,以节省磁盘存储空间。下次使用的时候,仍然可以重新拉取。
ollama rm llama3
复制模型
ollama cp 命令可以复制一个模型,复制模型会占用双倍的磁盘空间。
ollama cp llama3 my-model
多行输入
在 Ollama 的命令行里面,回车表示发送指令,如果需要多行输入,可以使用单引号 ( """ ) 来完成。
>>> """Hello, ... world! ... """
多模态模型
使用多模态模型,只需要输入文件图片地址,即可表示上传了这个图片文件。
>>> What's in this image? /Users/jmorgan/Desktop/smile.png The image features a yellow smiley face, which is likely the central focus of the picture.
run 参数提问
我们可以把提示词直接通过参数传递给大模型,该命令不会进入交互式输入模式。比如:
ollama run glm4xiuxian 今天我要做什么

显示模型信息
ollama show glm4
注意,只有下载过之后的模型才能通过 show 命令来显示模型相关信息。
启动
当您想启动 Ollama 时可以使用 ollama serve。这样就不需要使用 Ollama 的客户端程序了。比如我们在 Linux 服务器上就可以这样使用。
ollama serve
启动之后,我们需要新开一个 Shell 窗口来运行模型:
./ollama run glm4
默认端口Ollama 服务的默认端口是 11435,无论是使用 App 启动,还是使用命令行启动,均是这个默认端口。
由于 命令行和 APP 都使用 11435 默认端口,我们再 GUI 工作的时候执行 ollama server 会提示端口已占用。我们可以通过环境变量指定一个新的端口,来同时运行两个 ollama 实例:
OLLAMA_HOST=127.0.0.1:11435 ollama serve
Serve 命令提供了很多环境变量,可以让你更自由的运行 Ollama 程序:
-
•
OLLAMA_DEBUG显示其他调试信息(例如 OLLAMA_DEBUG=1) -
•
OLLAMA_HOSTollama 服务器的 IP 地址(默认 127.0.0.1:11434) -
•
OLLAMA_KEEP_ALIVE模型在内存中保持加载状态的持续时间(默认“5 分钟”) -
•
OLLAMA_MAX_LOADED_MODELS每个 GPU 加载的最大模型数量 -
•
OLLAMA_MAX_QUEUE排队请求的最大数量 -
•
OLLAMA_MODELS模型目录的路径 -
•
OLLAMA_NUM_PARALLEL并行请求的最大数量 -
•
OLLAMA_NOPRUNE启动时不修剪模型 blob -
•
OLLAMA_ORIGINS允许来源的逗号分隔列表 -
•
OLLAMA_TMPDIR临时文件的位置 -
•
OLLAMA_FLASH_ATTENTION启用闪存注意 -
•
OLLAMA_LLM_LIBRARY设置 LLM 库以绕过自动检测
REST API
Ollama 启动之后,会自动运行一个执行和管理模型的 API。
回答 API
curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt":"Why is the sky blue?" }'
聊天 API
curl http://localhost:11434/api/chat -d '{ "model": "llama3", "messages": [ { "role": "user", "content": "why is the sky blue?" } ] }'
除了上述最基本的用法,我们还可以指定响应格式、使用流式响应等。
比如使用流式 API:
curl http://localhost:11434/api/generate -d '{ "model": "glm4", "prompt": "天空是什么颜色?" }'
或者非流式 API,直接返回结果:
curl http://localhost:11434/api/generate -d '{ "model": "glm4", "prompt": "天空是什么颜色?", "stream": false }'
更多用法可以参考 Ollama API 文档[6]。
Python API
Ollama 提供了 Python API,可以让 Python 程序快速与 Ollama 集成起来。
首先安装依赖库:
pip install ollama
聊天:
import ollama response = ollama.chat(model='llama3', messages=[ { 'role': 'user', 'content': 'Why is the sky blue?', }, ]) print(response['message']['content'])
使用流式API:
import ollama stream = ollama.chat( model='llama3', messages=[{'role': 'user', 'content': 'Why is the sky blue?'}], stream=True, ) for chunk in stream: print(chunk['message']['content'], end='', flush=True)
另外,CLI 提供的指令在 Python 里面都有 API 对应。
聊天
ollama.create(model='example', modelfile=modelfile)
生成文本
ollama.generate(model='llama3', prompt='Why is the sky blue?')
列出模型
ollama.list()
显示模型信息
ollama.show('llama3')
创建模型
modelfile=''' FROM llama3 SYSTEM You are mario from super mario bros. ''' ollama.create(model='example', modelfile=modelfile)
拉取模型
ollama.pull('llama3')
拷贝模型
ollama.copy('llama3', 'user/llama3')
删除模型
ollama.delete('llama3')
自定义客户端
创建客户端的时候可以指定 host 和 timeout 两个参数:
from ollama import Client client = Client(host='http://localhost:11434') response = client.chat(model='llama3', messages=[ { 'role': 'user', 'content': 'Why is the sky blue?', }, ])
错误处理
一般使用 ResponseError 来捕获异常,处理错误:
try: ollama.chat(model) except ollama.ResponseError as e: print('Error:', e.error) if e.status_code == 404: ollama.pull(model)
日志
Ollama 的日志文件存储在 ~/.ollama/logs/server.log,我们可以通过查看 这个日志文件来获取 Ollama 的运行信息,以及排查错误。
在 Mac 上直接打开文件即可查看日志:
也可以通过命令行来查看:
cat ~/.ollama/logs/server.log
如果是容器运行的话,更简单,直接查看容器的输出即可:
docker logs <container-name>
调试
LLM 窗口大小
默认情况下,Ollama 使用 2048 个标记的上下文窗口大小。
要在使用ollama run 的时候更改此设置,请使用/set parameter:
/set parameter num_ctx 4096
使用API时,指定num_ctx参数:
curl http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt": "Why is the sky blue?", "options": { "num_ctx": 4096 } }'
GPU 使用
通过 PS 命令查看 模型是否加载到了 GPU 上。
PS 命令会返回当前内存中已经加载的模型:
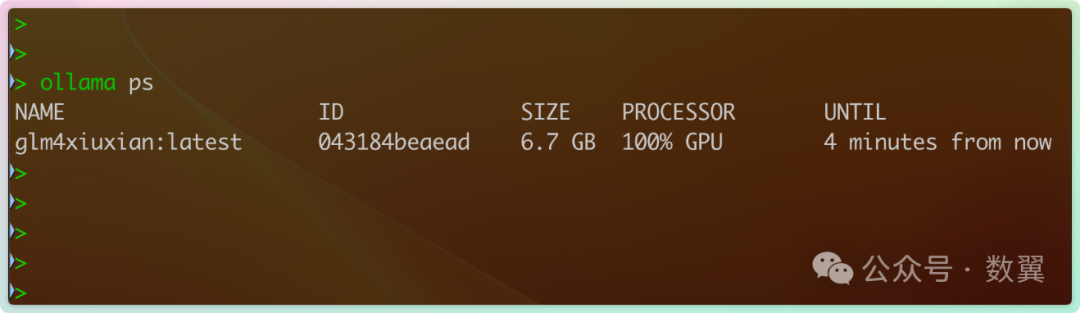
Processor 列显示模型被加载到哪个内存中:
-
•
100% GPU表示模型已完全加载到 GPU 中 -
•
100% CPU表示模型已完全加载到系统内存中 -
•
48%/52% CPU/GPU表示模型已部分加载到 GPU 和系统内存中
Ollama 作为服务使用
一直到前面为止, Ollama 运行起来都只能在本机使用,可以通过设置环境变量来让其他客户端访问。
Serve 命令
如果是使用 Serve 命令启动,那就比较简单,和我们前面改端口一样:
OLLAMA_HOST=0.0.0.0:11435 ollama serve
MacOS 应用程序
如果 Ollama 作为 macOS 应用程序运行,则应使用以下命令设置环境变量launchctl:
使用 launchctl setenv 设置环境变量,然后重新运行程序。
launchctl setenv OLLAMA_HOST "0.0.0.0"
使用代理
Ollama 支持使用 HTTP_PROXY 和 HTTPS_PROXY 来配置代理。
如果是 Docker 运行,那么使用 -e HTTPS_PROXY=https://proxy.example.com 来设置环境变量即可。
模型存储
Ollama 会下载模型到本地,不同操作系统的模型位置分别是:
-
• MacOS:
~/.ollama/models -
• Linux:
/usr/share/ollama/.ollama/models -
• Windows:
C:\Users\%username%\.ollama\models
如果你想将模型存储到不同位置,可以使用 OLLAMA_MODELS 环境变量来指定不同的目录。
并发
以下服务器设置可用于调整 Ollama 在大多数平台上处理并发请求的方式:
-
•
OLLAMA_MAX_LOADED_MODELS可同时加载的最大模型数量(前提是它们适合可用内存)。默认值为 3 * GPU 数量或 3(用于 CPU 推理)。 -
•
OLLAMA_NUM_PARALLEL每个模型同时处理的最大并行请求数。默认将根据可用内存自动选择 4 或 1。 -
•
OLLAMA_MAX_QUEUEOllama 在繁忙时排队的最大请求数,在拒绝其他请求之前。默认值为 512
Ollama 处理并发请求的逻辑是:
-
• 如果有足够内存,则可以同时加载多个模型
-
• 对于某个模型,如果有足够内存,则可以并发处理请求
-
• 如果内存不足以加载新模型:所有请求都排队,直至新模型加载
-
• 之前的模型空闲时,会写在一个或多个模型腾出空间给新模型
-
• 排队的请求按顺序处理
OpenAI 兼容性
Ollama 与OpenAI API的部分内容提供了实验性的兼容性, 以帮助将现有应用程序连接到 Ollama。
使用 OpenAI Python 库
用法和 OpenAI 的客户端用法一样。
from openai import OpenAI client = OpenAI( base_url='http://localhost:11434/v1/', # required but ignored api_key='ollama', ) chat_completion = client.chat.completions.create( messages=[ { 'role': 'user', 'content': 'Say this is a test', } ], model='llama3', )
OpenAI JavaScript
import OpenAI from 'openai' const openai = new OpenAI({ baseURL: 'http://localhost:11434/v1/', // required but ignored apiKey: 'ollama', }) const chatCompletion = await openai.chat.completions.create({ messages: [{ role: 'user', content: 'Say this is a test' }], model: 'llama3', })
CURL 工具
curl http://localhost:11434/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "llama3", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Hello!" } ] }'
模型名称
有些程序依赖 OpenAI 默认的模型名称(例如 gpt-3.5-turbo), 无法修改或者指定模型,可以使用如下方法来解决。
复制一个你喜欢的模型为 gpt-3.5-turbo,
ollama cp llama3 gpt-3.5-turbo
这样我们就可以李代桃僵来保证原有程序不变,依然传递 gpt-3.5-turbo 作为模型名称:
curl http://localhost:11434/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-3.5-turbo", "messages": [ { "role": "user", "content": "Hello!" } ] }'
社区和集成
社区有大量工具和类库都对 Ollama 做了集成,或者说基于 Ollama 进行构建, 我们可以在官网文档[7]上查看具体的项目列表:
Ollama 类库

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









