






基于数据挖掘的微博用户兴趣群体发现与分类是一项重要研究,其主要目的是通过深入挖掘和分析微博用户的行为数据,从而识别出具有相似兴趣爱好的用户群体,并对其进行有效的分类。这项研究对于理解社交媒体用户的兴趣分布,以及构建个性化的推荐系统和广告定向投放系统具有重要意义。
为了实现这一目标,研究者采用了多种数据挖掘技术和机器学习算法,对微博用户的行为数据进行深入分析。通过这些技术,研究者能够发现并识别出具有相似兴趣爱好的用户群体,同时也可以对用户群体进行有效的分类。这不仅可以为用户提供更个性化的服务,还可以为广告商提供更有针对性的广告投放方案。
微博用户兴趣群体发现与分类系统总体分为前台用户模块和后台管理员模块。两个模块表现上是分别独立存在,综上所述,系统功能结构图如下图所示。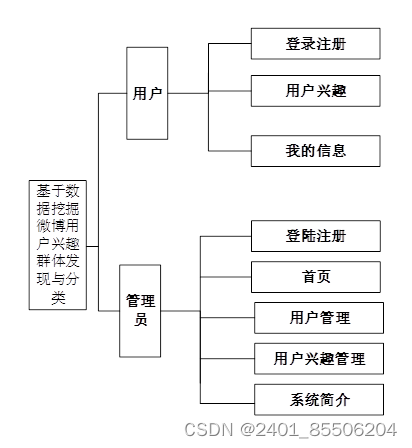
用户登录/注册成功之后可以查看到用户兴趣,在用户兴趣界面可以查看到感兴趣的博主、来源、评论数、点赞数、分享数、显示量。可以对个人信息进行管理。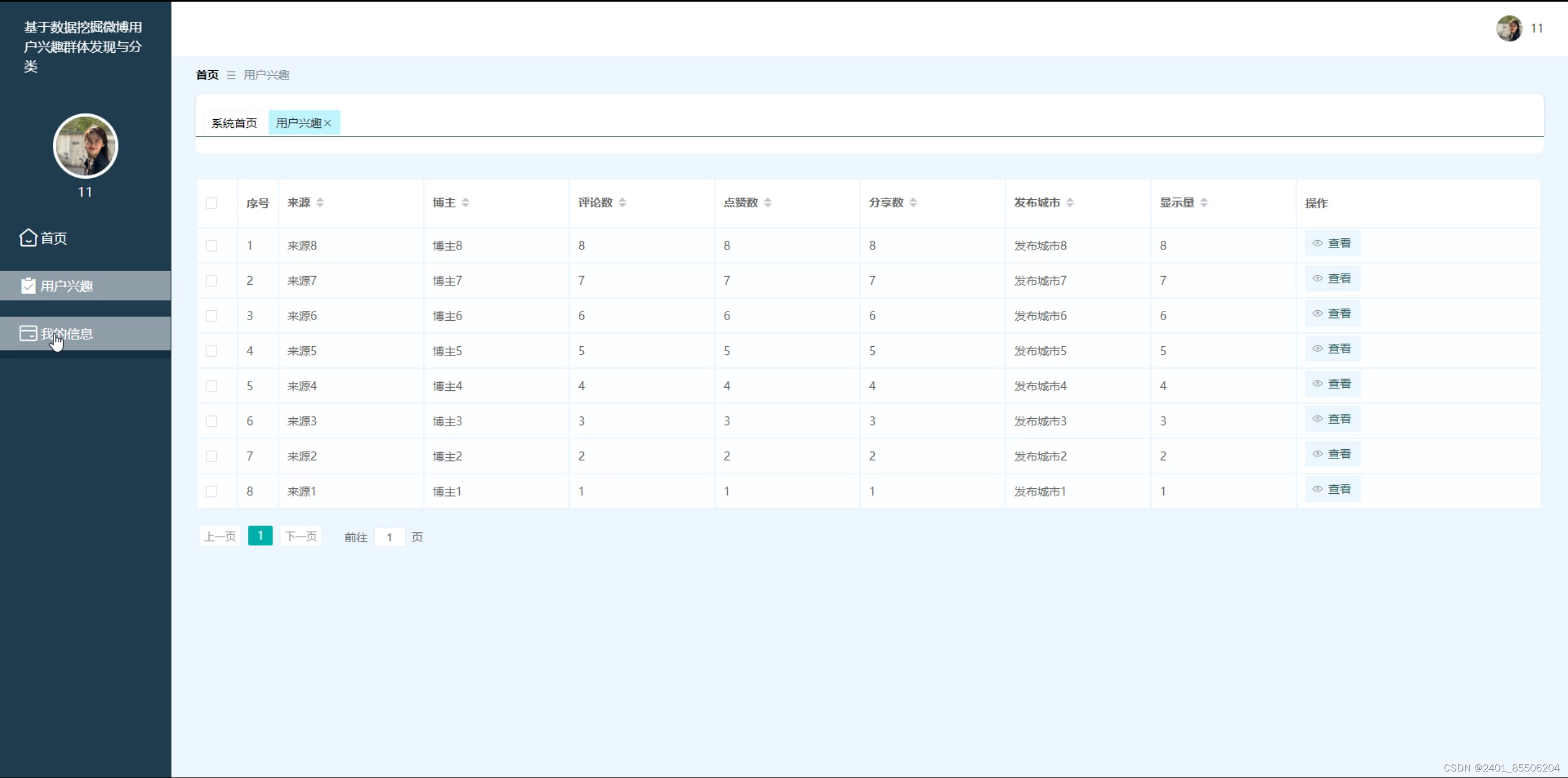
图5-5用户兴趣界面















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









