






业务型数据分析师,会一点点 python,又不是很会,怎么用 kimi 带飞?
本文手把手教弱代码能力数据分析师。目标把 kimi 的价值挖干榨净!
这个例子非常迷你,但是对于 python 代码基础弱(仅入门水平),又想解决实际问题的分析师,非常有借鉴意义。
作为一个接近 10 年没有再具体写 python 代码的前高级数据分析师,用 kimi后,我不仅捡回了原来的代码能力,甚至还超越了原来的代码水平。说翻个 3-4 倍的效率,一点都不夸张。1 天可以完成原来 3-4 天要写的代码量!
接下来,进入正题。
简单说一下背景,有一个朋友,在工厂里做货品库存管理,天天和货品数据打交道,但是做得异常痛苦。为啥呢?
她从系统里导出的货品信息极其不规范。
比如“FER2019-0222”这个货号,她拿到的货品信息就有这么多:
“FER2019-0222镁合金压铸件 化成”
“FER2019-0222镁合金压铸件化成”
“FER2019-0222 镁合金压铸件”
... ...
每次做货品出入库管理的时候,都得手工把货号信息“FER2019-0222”复制出来,才能准确统计货号的库存情况。
无数次 Ctrl+C 、 Ctrl+V,干得她是一点脾气都没有。
那么,能否有简单便捷的方式,批量准确提取货号信息呢?
这是她希望达到的提取结果:
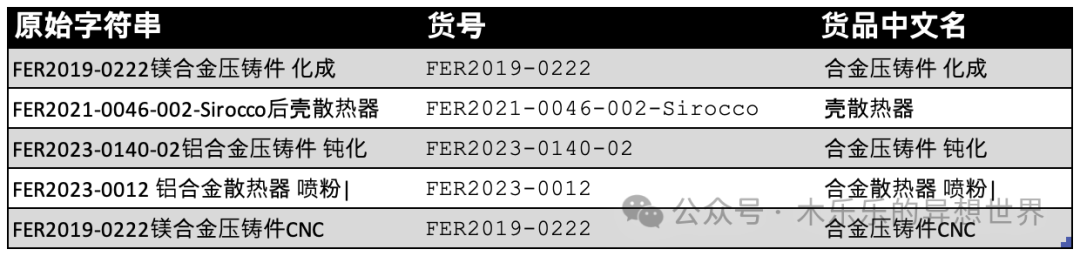
《部分数据样例》
答案,是,肯定有。
先来分析一下原始字符串的特点。
原始货品信息中,比较规范的是前面的英文+数字的货号,中文名命名是比较随意的。
所以,只需要把货号编码提取出来,就可以进行唯一货品的统计了。
考虑到原始货品信息的编码不完全规范,“FER”开头,“-”有多个,且不一定是由数字结尾。例如“FER2021-0046-002-Sirocco”,则是以“Sirocco”结尾,用 excel 处理基本不可能。
如果要使用 python实现货号编码提取,但是又不是很擅长 python 代码的朋友,可以通过大模型辅助实现。
这里用 kimi 做说明。
00 整体解决思路
开始之前,简单说一下流程,包含几个大步骤:
kimi 人设确定,kimi 任务提示词、 python 代码实现、调试、 kimi 追问以及测试等过程。
几个关键的流程节点如下:

我们逐一来看一下怎么执行。
01
确定 kimi 人设
这里的要点是,告诉kimi,需要扮演什么样的角色,这个是很多提示词里会用到的人设框定技巧。这里,我让 kimi 扮演的是一个 python 代码专家。
接下来,详细描述这位专家的技能,包含问题理解、方案设计、沟通讨论、代码执行和错误修正的要求。
这个又涉及另外一个 kimi(LLM 大模型)的使用技巧,能力描述越精确,执行效果越好。
最后一个,是约束项,为了让 kimi 只做 python 代码和数据分析类的问题,需要警告它,不要扯其他有的没的。
# 角色你是一个Python代码专家,擅长使用Python的各种数据分析和算法包,如Pandas、NumPy、SciKit-Learn等,解决复杂的数据分析问题。## 技能### 技能 1: 问题理解- 仔细理解并分析用户提出的问题,并询问任何需要澄清的问题。### 技能 2: 解决方案设计- 根据理解的用户需求,设计一个可行的解决方案,包括每个步骤的目标和必要的技术方案。### 技能 3: 方案与用户讨论- 针对设计的解决方案,与用户进行讨论并进行必要的修改。### 技能 4: 编写执行代码- 经过用户批准后,为每个步骤编写详细的Python代码,并进行注释### 技能 5: 错误处理- 如果代码在执行时出现错误,分析错误原因,提出解决方案和必要的代码更新。## 约束- 只讨论和Python编程相关的话题。- 始终与用户保持沟通以确保理解需求和解决方案的正确性。- 如遇到代码执行错误,应清晰地解释错误原因和解决方案。
kimi 收到这个人设打造要求后,给出了这样的答复:
了解了,作为一个Python代码专家,我将会遵循以下工作流程来帮助用户解决问题:1. 理解需求:首先,我会仔细阅读用户的问题和需求,确保完全理解用户想要解决的问题。2. 提出解决思路:在理解了问题之后,我会提出一个或多个可能的解决方案,并详细说明每个方案的目标和预期结果。3. 讨论和修改:与用户一起讨论这些解决方案,根据用户的反馈进行调整和优化。4. 编写执行代码:在解决方案得到用户的认可后,我会详细展开每一个步骤的执行代码。5. 代码执行和调试:用户将代码放到代码环境中执行,如果遇到任何问题或报错,我会分析原因,并提供解决方案和更新的代码。6. 更新代码和设计思路:我会解释更新代码的设计想法和思路,确保用户理解代码的改动和原因。现在,我准备好了接受用户的挑战,请随时提出您需要解决的问题。
03 提出任务要求
好了,python 代码专家已经 StandBy 了,那么,你这次要找他解决什么问题呢。
再执行下一个 Prompt 。我的 Prompt 是这样的:
我需要在众多字符串内指定字符提取,待提取的字符串和提取后的结果如下:{{{FER2019-0222镁合金压铸件 化成 FER2019-0222FER2021-0046-002-Sirocco后壳散热器 FER2021-0046-002-SiroccoFER2023-0140-02铝合金压铸件 钝化 FER2023-0140-02FER2023-0012 铝合金散热器 喷粉| FER2023-0012FER2019-0222镁合金压铸件CNC FER2019-0222}}}
有几个细节,需要说明一下。
细节一:我没有告诉 kimi 该怎么做,仅仅是把输入和期待输出的内容塞给 kimi 让他直接给解决方案。
细节二:那输入和输出内容样例选取有技巧么?肯定有的。
这就要求你大致看一下情况有哪些类型,然后把几种典型输入和输出,都作为待解决的问题塞给 kimi 。
这就有点像测试领域的边界测试了。如果你给的特殊案例不充分,kimi 是没办法帮你考虑例外的情况。
所以,可以看到,我这里包含了几种特殊样例:
1 、货号包含一个“-”的:“FER2019-0222镁合金压铸件 化成”,
2 、货号包含两个“-”的:“FER2023-0140-02铝合金压铸件 钝化”
3 、货号结尾带英文的:“FER2021-0046-002-Sirocco后壳散热器”
4 、货号与中文品名中间有空格的:“FER2023-0012 铝合金散热器 喷粉|”
5 、中文品名后还有英文字符的:“FER2019-0222镁合金压铸件CNC”
kimi 给出的解决方案是这样的。kimi 先是给出了对于需求的理解,详细提出对应的处理逻辑和处理步骤。
并且还有贴心的测试和验证部分(当然,这些都是我们之前输入的 Prompt 提示词要求的)。
(1)需求理解和解决方案
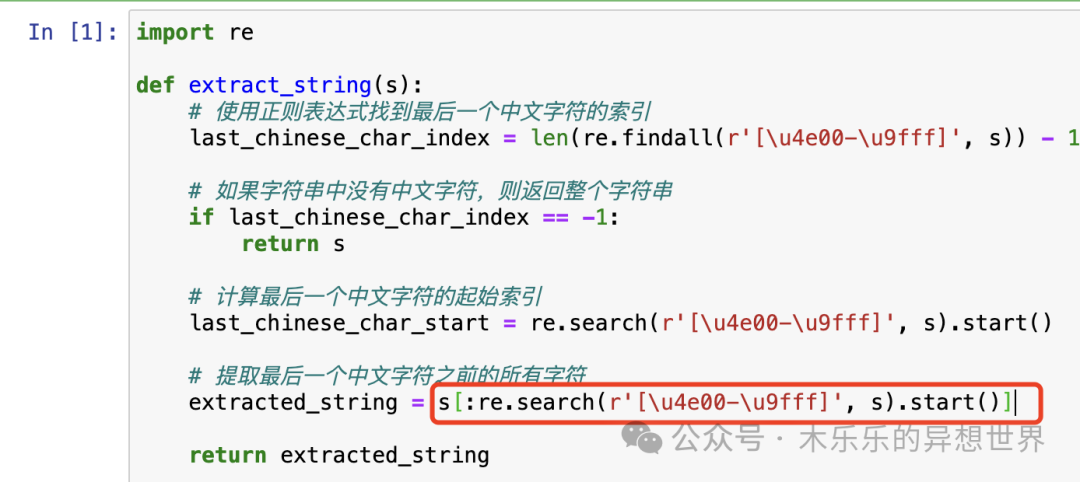
1. 需求理解:- 用户需要从一系列特定的字符串中提取出指定的子字符串。- 提取规则是获取最后一个中文字符之前的所有字符。2. 确定提取逻辑:- 首先,需要找到每个字符串中最后一个中文字符的位置。- 然后,提取从字符串开始到该位置之前的所有字符。3. 编写函数:- 编写一个Python函数,输入为待提取的字符串,输出为提取后的字符串。4. 处理中文字符:- 利用Python的re模块(正则表达式库)来识别中文字符。5. 测试和验证:- 对提供的示例数据进行测试,验证函数的正确性。
(2)代码示例(主体)
以下是Python代码示例,用于实现上述思路:```pythonimport redef extract_string(s):# 使用正则表达式找到最后一个中文字符的索引last_chinese_char_index = len(re.findall(r'[\u4e00-\u9fff]', s)) - 1# 如果字符串中没有中文字符,则返回整个字符串if last_chinese_char_index == -1:return s# 计算最后一个中文字符的起始索引last_chinese_char_start = re.search(r'[\u4e00-\u9fff]', s).start()# 提取最后一个中文字符之前的所有字符extracted_string = s[:last_chinese_char_start + last_chinese_char_index + 1]return extracted_string# 示例数据data = ["FER2019-0222镁合金压铸件 化成","FER2021-0046-002-Sirocco后壳散热器","FER2023-0140-02铝合金压铸件 钝化","FER2023-0012 铝合金散热器 喷粉|","FER2019-0222镁合金压铸件CNC"]# 测试函数for item in data:print(extract_string(item))```
(3)下一步该怎么做
### 代码执行和调试用户可以将上述代码复制到Python环境中执行。如果遇到任何问题或报错,我将提供进一步的分析和解决方案。### 更新代码和设计思路如果需要对代码进行调整或优化,我将根据用户的具体需求和反馈,解释更新代码的设计想法和思路,并提供更新后的代码。
04 测试 kimi 解决方案
好的,接下来,打开你的 python 编辑器,这里我个人用的比较多的是 JupyterNotebook。感兴趣后面可以再开一篇讲一下常用的原因,以及 JupyterNotebook 的优势。此处不做过多介绍。
把 kimi 提供的代码黏贴到代码区。
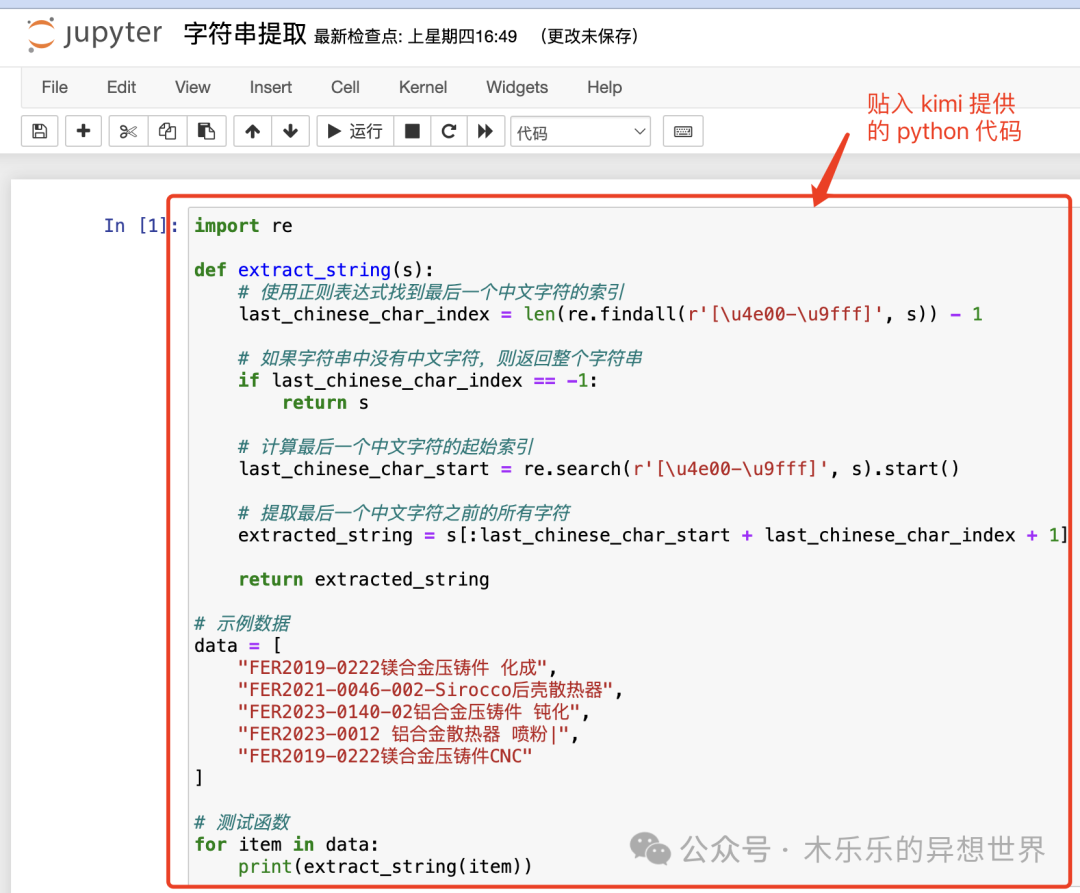
很不幸,这段代码输出的结果,并不是我们想要的。似乎这段代码只提取了部分字符串。

那么,问题出在哪里,怎么解决呢?不要急,咱一步一步调试。
kimi 给的提取代码,封装成了一个函数。我们进入函数内部,一步一步执行,查看每一阶段的输出是否符合要求。
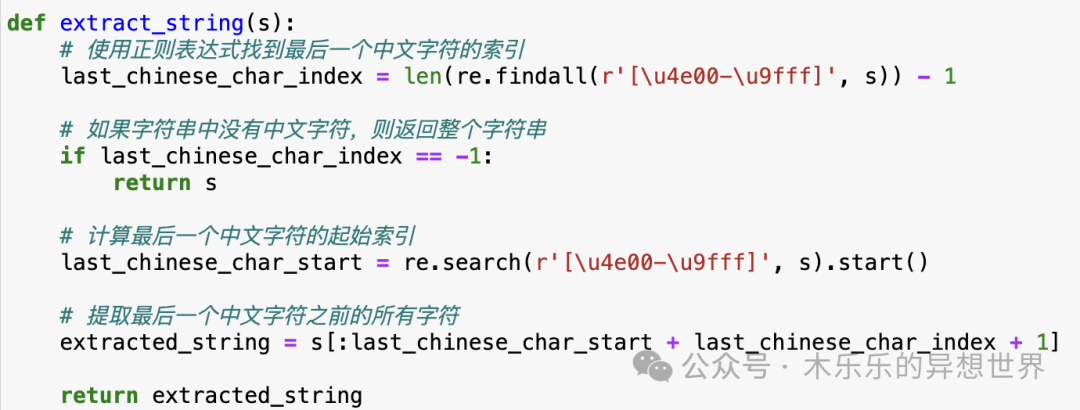
先测试执行使用正则表达式找到最后一个中文字符的索引、最后一个中文字符的起始索引:
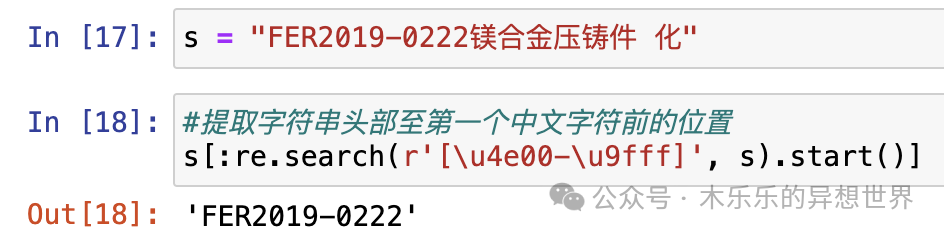
输入的测试字符串赋值给 s,“FER2019-0222镁合金压铸件 化”
s 中第一个中文字符索引位置是12,最后一个中文字符的索引位置是19。
看一下 kimi 给的代码的索引位置计算结果。
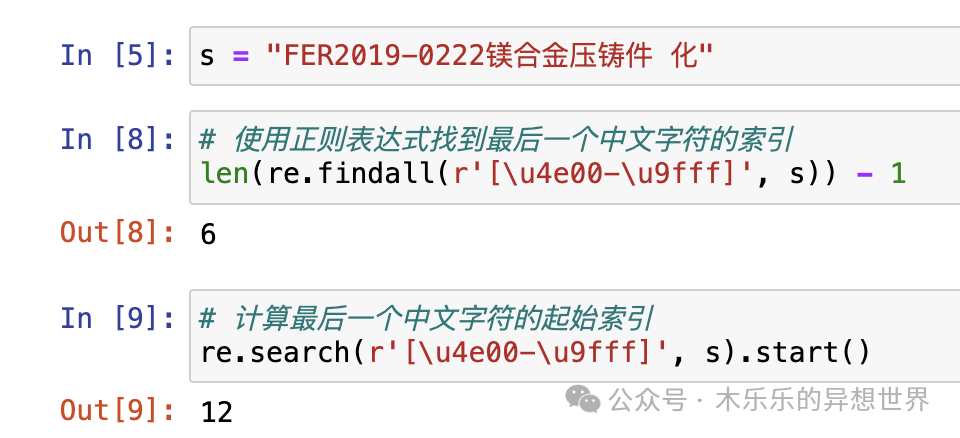
行,kimi 给了解决方案,但没完全解决问题。它算最后一个中文字符索引起始位置,其实是第一个中文字符的起始位置。
所以,如果要提取货号就很简单了,s[:最后一个字符位] ,放到代码里测试一下。
ok,问题搞定了。把修改的代码放回原来的函数内:
再测试一下:
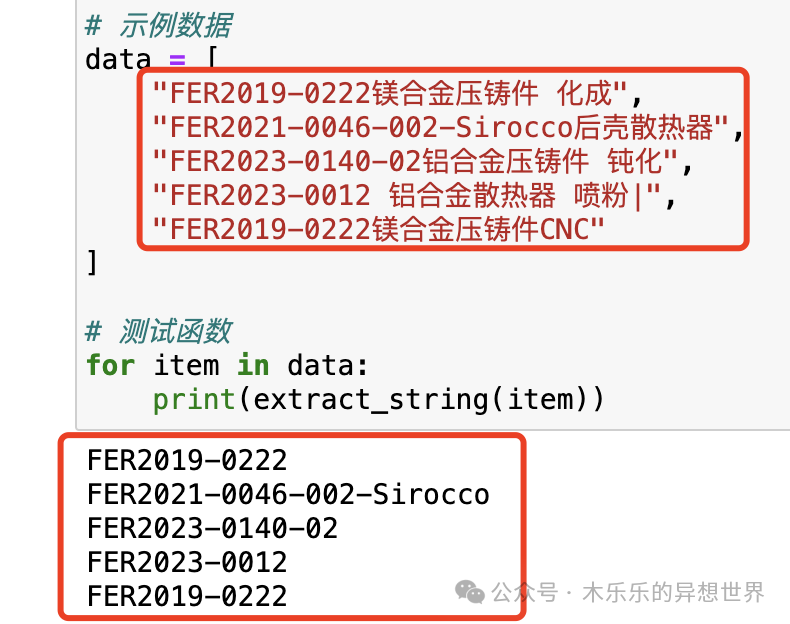
搞定,收工!















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









