






今年下半年的小陈,主跟CDP项目。
项目在数据接入阶段,团队小伙伴每天都在死啃数据库。今天CRM、明天DMS,后天还有神策APP埋点和DMP埋点。
数据枯燥,也能发现一些有意思的玩意儿。
甲方的各系统分别在不同年份建设的。在盘点细节时,有旧技术考古,也有新技术更新;玩起来,就像考古学家观看岩土断层切面一样,
如同寒武纪的三叶虫化石戴着墨镜跟你喊“泰酷啦”
这里引入的是数据库的行式存储和列式存储。
CRM的大神很自豪的说,我们数据列式存储,运算速度快,查询等待短。
那么,列式存储究竟是怎样的存储模式,为什么有这样的特点。
和我们常规的行式存储有什么区别?
啥时候选择行式存储,啥时候选择列式存储呢?
让我们一一道来。
先举个例子🌰
为了方便理解,这里举了一些具体的数据列表来举例说明。
假设我们有一个学生表,包含四个属性:学号(id)、姓名(name)、性别(gender)、成绩(score)。表中有三条记录,如下所示:
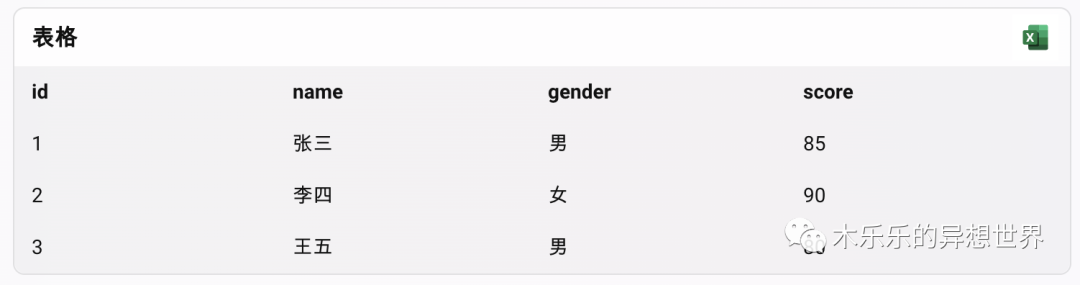
excel表用过吧,简单说来,行式存储就是选择了一行,然后ctrl+c。

如果采用行式存储,那么数据在存储介质中的形式如下,每一行的数据是连续存储的,用逗号分隔。
1,张三,男,852,李四,女,903,王五,男,80
那么,列式存储就是选择了一列,然后ctrl+c。
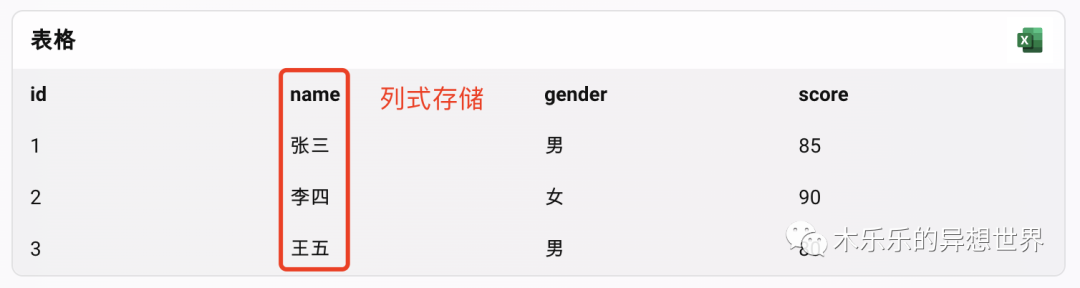
如果采用列式存储,那么数据在存储介质中的形式如下,每一列的数据是连续存储的,用逗号分隔。
1,2,3张三,李四,王五男,女,男85,90,80
接下来,说一说行列式存储的优劣势
如果我们要查询所有学生的姓名和成绩。
行式存储怎么做?
统计:因为我们并不需要知道学生的学号和性别。所以,我们需要读取每一行的所有数据,然后从中选取姓名和成绩。这样会造成无关的IO和内存消耗。
更新:但是,如果我们要更新王五的成绩,那么我们只需要修改第三行的最后一个数据,而不需要修改其他列的数据。这样就可以快速地完成更新操作。
列式存储怎么做?
同样是查询所有学生的姓名和成绩,那么我们只需要读取第二列name(姓名)和第四列score(成绩)的数据,而不需要读取其他列的数据。这样就可以减少无关的IO和内存消耗。
更新起来就比较麻烦:如果我们要更新王五的成绩,那么我们需要修改第四列的最后一个数据,同时还需要修改每一列的数据版本,以保证数据的一致性。这样就会增加更新操作的复杂度。
稍微,总结一下?
通过刚才的简单例子,我们对行式存储和列式存储有了直观的理解。
行式存储模式:
适合于随机的增删改查操作,以及需要在行中选取所有属性的查询操作。
传统的关系型数据库,如Oracle、MySQL、SQL Server等,都采用行式存储,它们主要用于在线事务处理(OLTP)的应用,如电商、银行、社交等。
行式存储的优势是:
-
可以快速地插入或更新数据,因为只需要修改一行的数据,而不需要修改多个列的数据。
-
可以方便地读取整个记录,因为一行的数据是连续存储的,而不需要从多个列中拼接数据。
-
可以利用索引或分区等技术提高查询效率,因为索引或分区是基于行的数据结构。
劣势也很明显:
-
不适合做数据分析或数据挖掘等操作,因为这些操作通常只涉及少数几个属性,而行式存储需要读取每一行的所有属性,造成大量的无关IO和内存消耗。
-
不适合做数据压缩或数据去重等操作,因为行式存储的数据是不同类型的数据混合在一起的,而不是同一类型的数据连续存储的,这降低了压缩或去重的效率。
列式存储模式:
适合于数据分析或数据挖掘等操作,以及需要在列中进行聚合或运算的查询操作。
新兴的分布式数据库,如HBase、Vertica、Greenplum等,都采用列式存储,它们主要用于在线分析处理(OLAP)的应用,如数据仓库、数据挖掘、数据可视化等。
列式存储的优势是:
-
可以高效地做数据分析或数据挖掘等操作,因为这些操作通常只涉及少数几个属性,而列式存储可以只读取相关的列,减少无关的IO和内存消耗。
-
可以高效地做数据压缩或数据去重等操作,因为列式存储的数据是同一类型的数据连续存储的,而不是不同类型的数据混合在一起的,这提高了压缩或去重的效率。
-
可以并行地对各列进行运算或聚合,然后在内存中组合成完整的记录集,这可以降低查询响应时间。
劣势是:
-
不适合做频繁的插入或更新操作,因为这些操作需要修改多个列的数据,而不是只修改一行的数据。
-
不适合做读取整个记录的操作,因为这些操作需要从多个列中拼接数据,而不是直接读取一行的数据。
-
不适合做实时的删除或更新操作,因为这些操作需要维护每一列的数据版本,而不是只维护一行的数据版本。















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









