






我的学生时代,曾经深深痴迷阿西莫夫的科幻小说。
在他的科幻小说里,机器人已经进化出了人的意识。
有意识的机器人,对于人类,是一种巨大的威胁。如何保障人类的安全?

阿西莫夫,通过机器人三大定律来规范机器人伦理与使用安全。
这也是阿西莫夫整个科幻世界的构建基础。
这三大定律,几乎就是机器人宪法。分别是:
第一定律:机器人不得伤害人类,或者通过不作为让人类受到伤害。
第二定律:机器人必须服从人类的命令,除非这些命令与第一定律相冲突。
第三定律:机器人必须保护自己的存在,只要这种保护不与第一或第二定律相冲突。
人类真的是自私又高傲。这三大定律总结下来就是,人权高于机器权。保障人类安全的情况下,再保障机器人自身安全。
那么,类似 ChatGPT 这样的人工智能,会不会演化出自我意识。是否也需要有类似的人工智能三大定律来规范他们的行为呢?
答案先摆出来,不会,不用担心。
你完全不用担心人工智能按照这个速度发展下去,哪一天一觉醒来,这个世界被机器人统治了。
这有基本前提,也就是,人工智能大模型基础原理一直是 Transformer 。
当然,如果底层原理有了其他突破,保不准真的会演化出自我意识。
言归正传,这次特地新开一个坑来聊一聊,为啥 ChatGPT 不会演化出自我意识。
这就得详细说一说,刚才提到的关键技术,Transformer ,看完这篇文章,你就能明白ChatGPT 这类大预言模型是怎么理解,并回复你说的话。
01 Transformer 概述
ChatGPT 这一类大语言模型的工作原理,其实是“成语接龙”。我还记得,在第一次使用 ChatGPT3.5 的时候,看着它一个字一个字的吐字出来的震撼感。
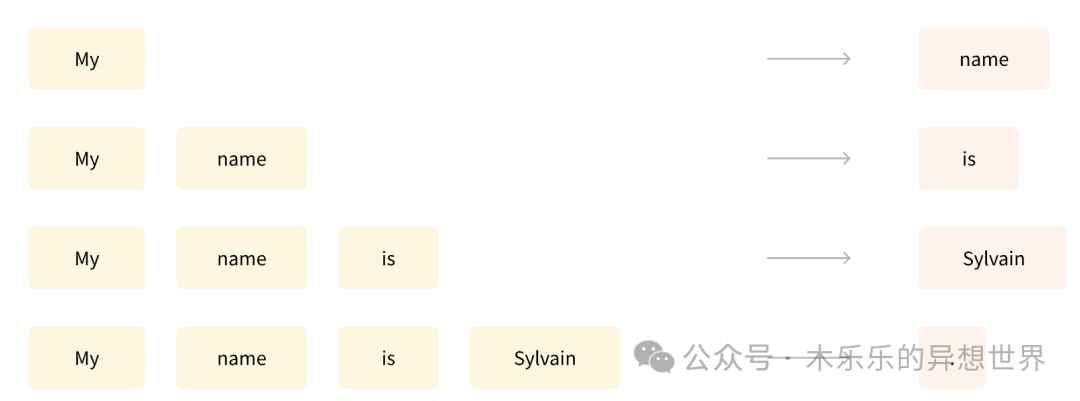
既然是“成语接龙”,ChatGPT 是怎么决定下一个要接哪个字的呢?
这就是 Transformer,完整的Transformer 架构很辅助。
下面的图引用论文《Attention Is All You Need》
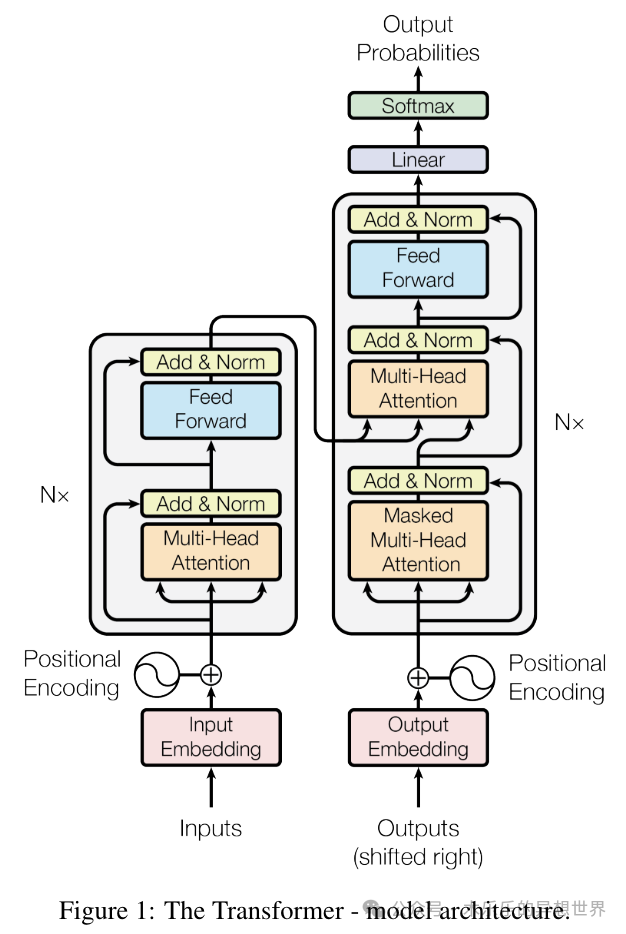
https://arxiv.org/pdf/1706.03762
下面这张图将整个过程做了简化。
主要有将文字转为 Token( Tokenization)、理解 Token(Input Layer)、再经过多次的理解上下文(Attention)和整合/思考(Feed Forward)后,再得到要接哪个字。
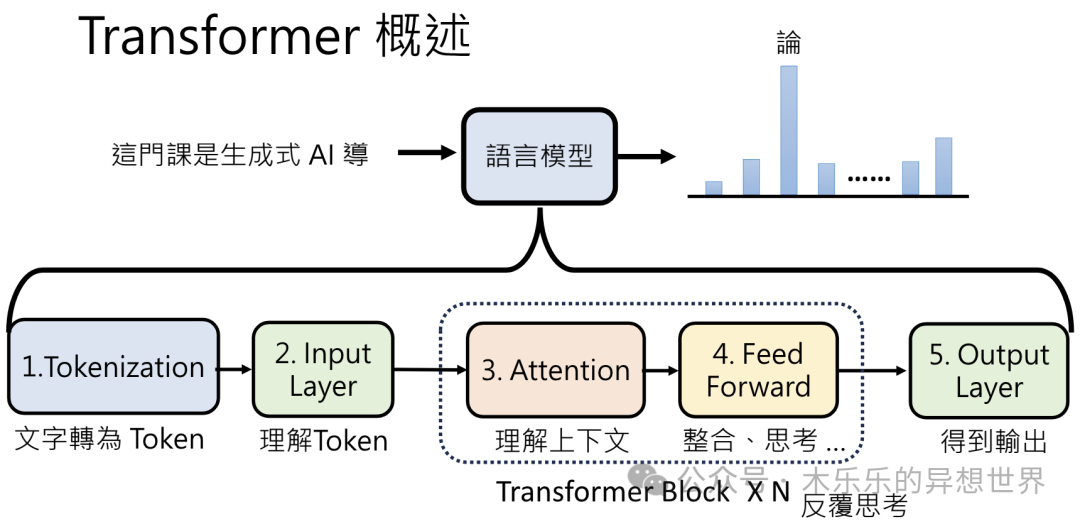
02 Tokenization+Input Layer 文字转化成 Token +理解 Token
在计算机和人工智能处理自然语言时,它们不能直接理解我们人类的语言。因为计算机只能处理 0|1 这样的数字。
所以,我们需要把文本转换成计算机能理解的格式。Tokenization就是把句子或段落拆分成一个个小块,这些小块可以是单词、短语,甚至是单个字符。
举个例子-假设有这样一句话:“小狗在公园里快乐地跑。”
-
分词-文字变成Token
首先,我们把这句话分成几个部分,每个部分都是计算机能处理的小块。可以这样分:小狗|在|公园里|快乐地|跑
-
Embedding,先理解每个分词Token的意思
此处,会将 Token 变成向量 Vector ,这个过程,称之为 Embedding 。意思相近的 Token,会有接近的 Embedding 。例如 小狗和小猫比较接近,快乐和高兴比较接近。计算机在计算这些 vector 的关系时,就可以通过 Embedding 后的向量来进行运算。
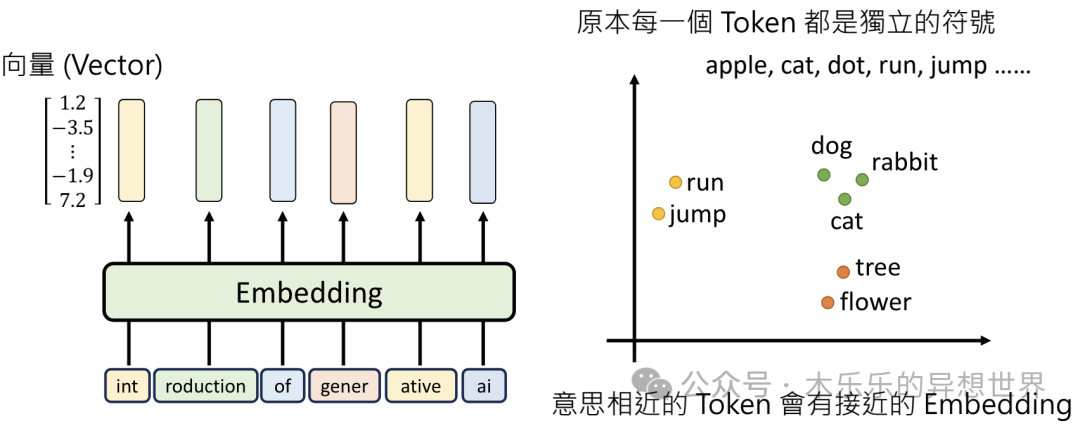
这会给每个分词一个向量Vector,比如:
小狗 -> [0.1, 0.3, 0.7, ...]
在 -> [-0.2, 0.1, -0.5, ...]
公园里 -> [0.4, -0.1, 0.2, ...]
快乐地 -> [-0.3, 0.6, -0.2, ...]
跑 -> [0.2, -0.4, 0.5, ...]
-
Positional Embedding,接下来理解每个分词Token的位置
只理解分词是不够的。“小猫追蝴蝶”和“蝴蝶追小猫”的 Token 一模一样,都是“小猫|蝴蝶|追”,但意思则大相径庭。
在处理上,会再叠加每个分词的位置向量,这里称之为 Positional Embedding 。
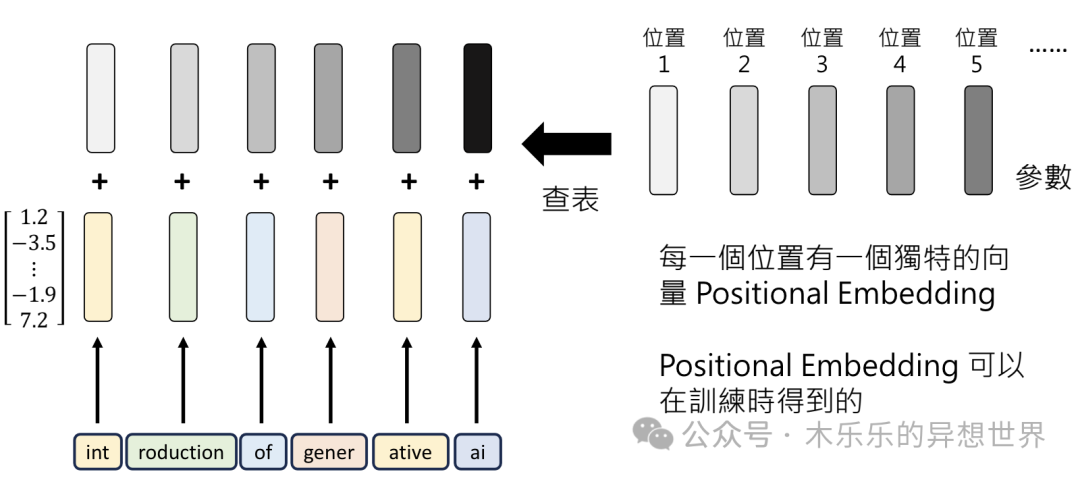
理解了分词的含义,且考虑了每个词在句子里的位置,差不多能把这句话的意思了解的七七八八。
但是,同样的一句话,在不同的上下文中,意思是完全不同的。
我们来看这样的一个例子。在 10+年前做 NLP 相关应用产品的时候,为了向客户解释中文语言博大精深,上下文语境会影响语句含义的时候,我特别喜欢举这个例子:
如果你妈妈跟你说「能穿多少穿多少?」,那么,妈妈是希望你多穿衣服还是少穿衣服?
03 Attention 考虑上下文
前面提到的「能穿多少穿多少?」在不同的上下文情况下,意思完全不同。Transformer 中,考虑上下文的技术,叫做 Attention 。
下面的例子中,举的例子更加直观。都是「苹果」,「苹果」电脑与来吃「苹果」,这两个短句中的「苹果」,有着不同的含义。
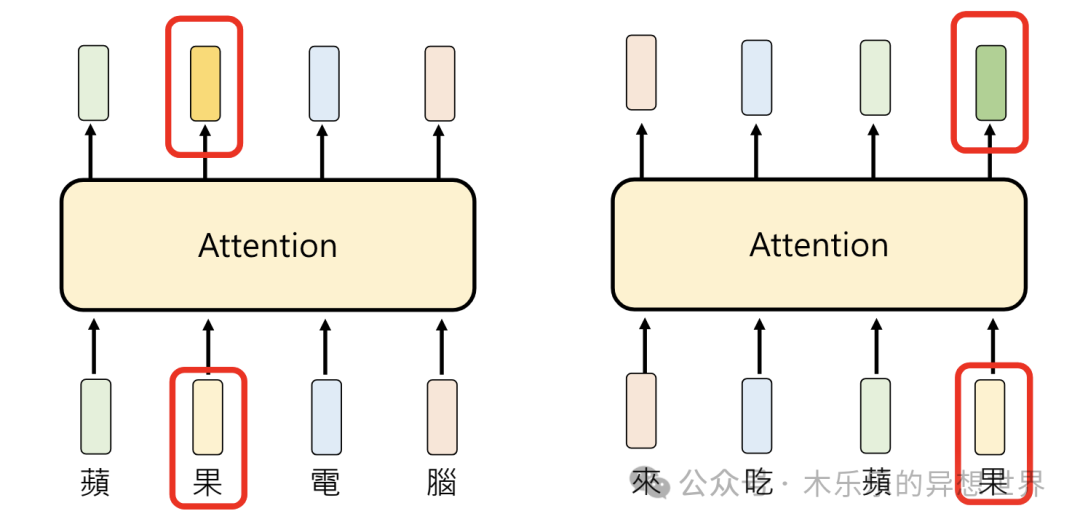
Attention技术,如何将不同含义的「苹果」区分出来呢?方式挺有意思的,会通过计算「苹果」与句子里每一个 Token 的相关性,然后将其相关性作为一个权重(Attention Weight),输出一个加权了句子中其他 Token 的Embedding 向量,作为 Attention 后的Embedding 值。
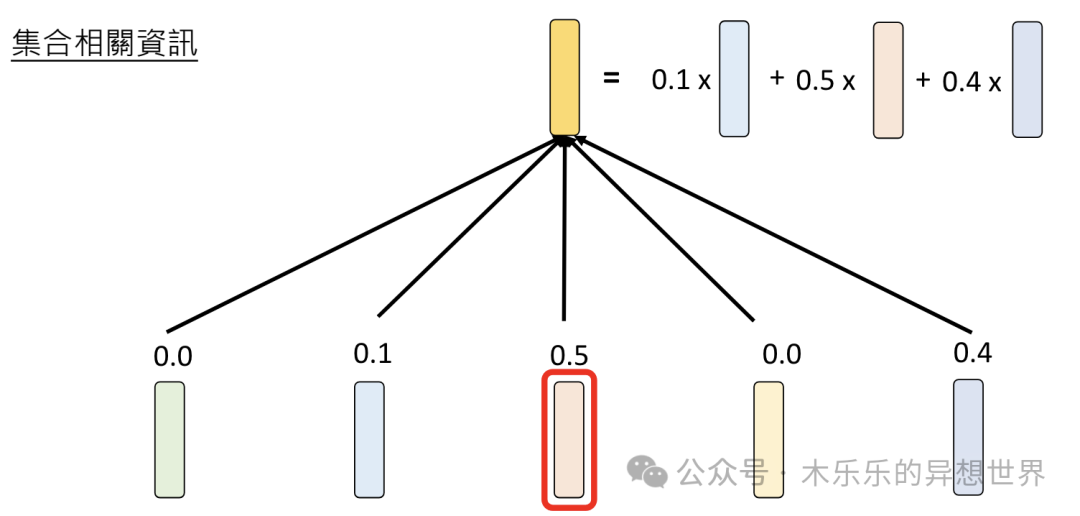
这个处理方式有点绕口。
想象一下,你正在一个拥挤的公园里,周围有很多人在说话。如果你想听某个特定朋友的话,你会把注意力集中在他身上,这样你就能听到他说的话,而忽略其他人的谈话。在Transformer技术中,Attention机制也是类似的,它帮助模型把“注意力”集中在输入信息的某些部分上。
Attention的作用总结下来,就是描述相关性,再叠加权重。
-
相关性:模型会判断每个词与当前任务的相关性。在例子中,“快乐地”和“跑”与描述小狗的行为更相关。
-
权重:模型会给每个词分配一个权重,权重越高,这个词就越重要。这就像是你在听故事时,对某些情节记得更清楚。
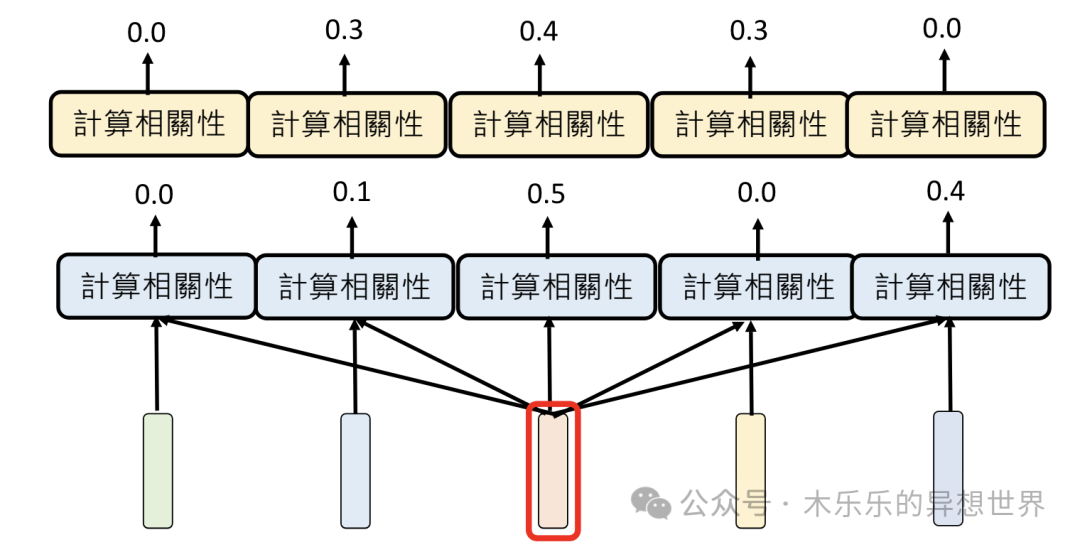
但是,相关性这里,有一点学问了。例如,「猫」和「狗」相关性很高,但是「猫」和「喵」的相关性也很高。那么,他们的相关性是同一个纬度的吗?
当然不是,「猫」和「狗」的相关,是物种之间的相关。而「猫」和「喵」之间的相关,是物种与声音之间的相关。所以,为了解决不同纬度间的相关,引入Multi-head Attention技术,能综合考量多个纬度的相关性计算结果,输出多组相关性计算后的不同 Embedding 。
04 FeedFoward 整合思考
前面提到引入Multi-head Attention技术后,每一个 Token 进来,会映射成多组不同的 Embedding,这时候,就需要由 FeedFoward 将多组不同的 Embedding作为输入(向量矩阵),最终,只输出一组独立的 Embedding 。
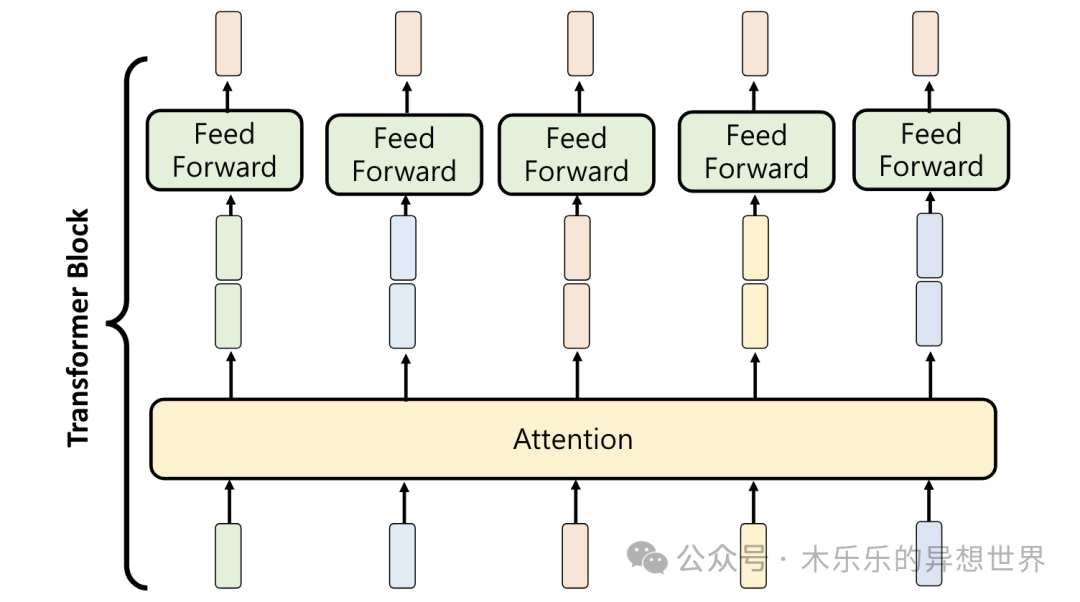
在Transformer模型中,FeedForward就像是一个“技能提升站”,它让模型在处理语言时能够更加深入和精准。这个技能提升站由两部分组成:
-
线性变换:首先,模型会把已经学到的信息(比如句子中的每个词的多个 Embedding向量表示)输入到一个线性层,这就像是给角色的基础属性加点,让它变得更强。
-
非线性激活:然后,模型通过一个非线性激活函数(比如ReLU),这就像是给角色添加特殊技能,让它能够应对更复杂的情况。
这个过程会重复两次,就像是角色通过了两个关卡,每次都变得更强。
举个例子:
假设我们有这样一段文本:“小狗在公园里快乐地跑。”
-
输入文本:首先,模型需要理解这段文本。
-
分词和编码:模型把文本分成单个的词,并为每个词生成一个向量表示。
-
通过技能提升站:然后,每个词的向量表示通过FeedForward网络:
-
首先,它们通过一个线性层,增加了新的特征。
-
接着,通过非线性激活函数,增加了模型处理复杂信息的能力。
-
再次通过另一个线性层,进一步调整和优化这些特征。
-
-
输出结果:最后,经过FeedForward网络处理的词向量,能够更好地捕捉文本中的深层含义和关系。
为什么FeedForward很重要?
-
深度处理:FeedForward网络增加了模型的深度,让模型能够更深入地理解语言。
-
复杂性处理:非线性激活函数让模型能够学习和模拟更复杂的语言模式。
-
性能提升:通过FeedForward网络,模型在处理语言时能够更加精确和有效。
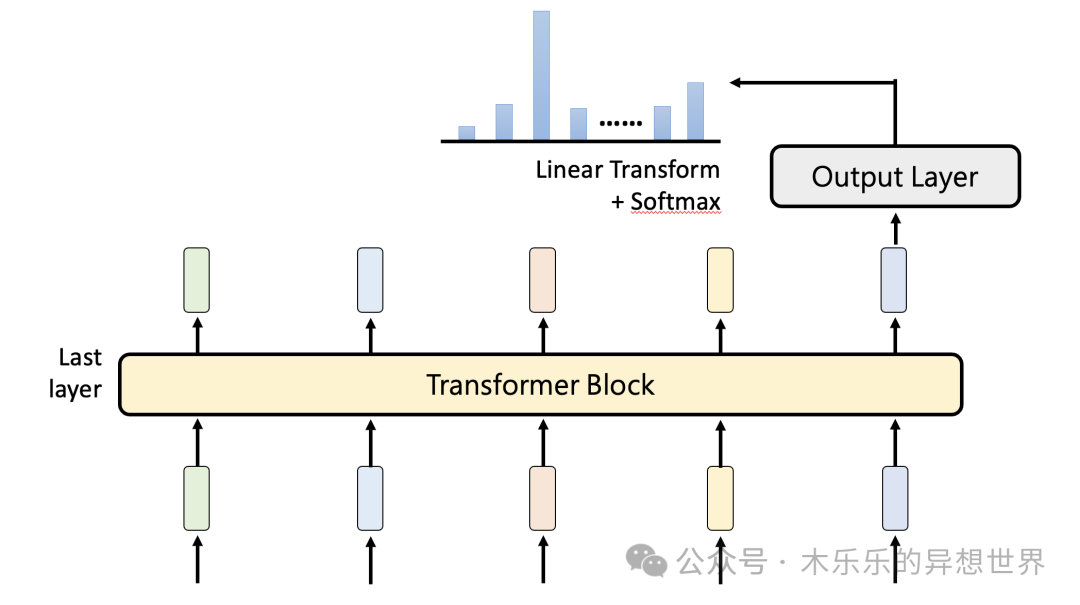
05 Output Layer 输出层
最后的 Output Layer 输出层,最终决定了模型“成语接龙”会接哪一个字。
此处用到的是 Linear Transform 和 Softmax 的技术。
你可以简单理解为,经过大量的语料学习,模型会告诉你,下一个字最大概率接哪一个。下一个字都是由概率控制的,你就能明白,为什么每次问模型同一个问题,它的输出都不一样。
写到这里,有一种巨大深坑被草草埋上的感觉。
回望整个过程,有一种巨大的机器,在喂养了无数多知识之后,突然得到了顿悟时刻。
我们今天提到的 Token 、 Attention 、 FeedFoward 和 OutPut Layer都是在基础的模型框架基础上,增加了大量的训练语料的学习,才成长出惊艳世人的 ChatGPT 这一类大预言模型。
人工智能这道快车,已经跨越过了凸变的奇点,未来会发生什么,没有人能料想的到。然而,对于我们这些打工人来说,扒上这道快车,才是正道。
感兴趣的小伙伴,欢迎关注、点赞、评论转发。您的每一份互动,都是我肝下去的动力。















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









