










Pandas的query函数为我们提供了一种编写查询过滤条件更简单的方法,特别是在的查询条件很多的时候,在本文中整理了10个示例,掌握着10个实例你就可以轻松的使用query函数来解决任何查询的问题。
一、选择股票人气排名网址
小编选择股票人气排名的网址是同花顺旗下的问财网址。
同花顺股票软件是一款提供行情显示、行情分析和行情交易的股票软件,是投资者炒股的入门必备工具之一。其强大、方便、人性化,且免费给投资者提供网上股票证券交易资讯行情。
其主要特色功能如下:
(1)提供上证所Level-2主力买卖指标。
(2)闪电下单模块使投资者委托交易更加快捷和方便。
(3)问财是同花顺旗下的AI投顾平台,是财经领域落地最为成功的自然语言、语音问答系统。
(4)资金博弈,将主力大单显示给投资者。
(5)股票人气排名结合市场人气,给每支股票排名。
笔者认为人气排名与资金博弈都对量化选股有重要影响,甚至会严重影响收益率,所以要重点研究。操作步骤如下:
(1)打开同花顺旗下的问财网址
http://www.iwencai.com/unifiedwap/home/index?qs=1,如图6.5所示。在这里,你可以编写简单量化语句或组合筛选语句。例如,跳空高开股票;市盈率大于3的股票;跳空高开0.5%~7%之间,boll线突破中轨等。
图1 问财主页
(2)输入“人气”,搜索人气,如图2所示,股票人气排名按从高到低排列。
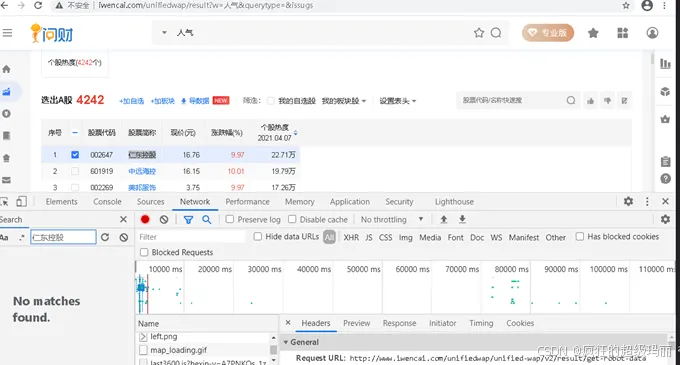
图2 问财人气搜索
(3)通过对Network搜索发现,没有现成的网址供我们直接爬取,其中原因之一是在today.js?hexin中进行了JS加密。
(4)在Elements中查找、定位元素,如图3所示。
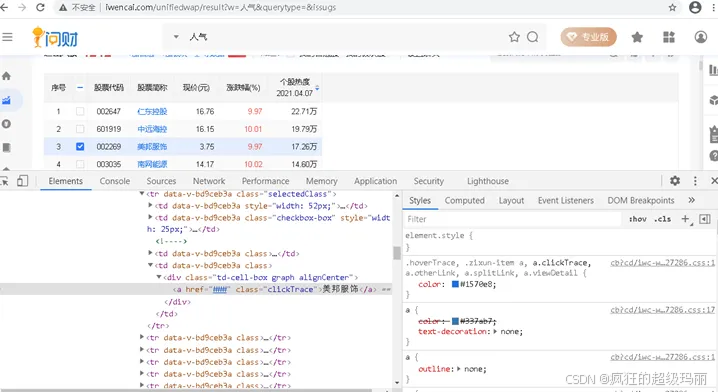 图3 在Elements中查找、定位元素
图3 在Elements中查找、定位元素
(5)使用Selenium进行自动化爬取。
(6)使用find_element_by_id定位元素,或者使用wd.page_source打印网页源代码,通过正则或BeautifulSoup定位元素。
二、使用request请求并了解反爬技术
如果笔者只想简单、直接地使用requests.get()语句获取股票人气排名,不想麻烦地使用Selenium进行自动化爬取,那么对这个网站就无计可施了吗?答案是还是有办法的。
通过笔者的深入了解和仔细研究,网址
http://www.iwencai.com/stockpick/search?typed= 1&preParams=2&ts=2&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94会提供网站源代码。
下面对该网址进行爬取。详细代码如下:
import requestsurl='http://www.iwencai.com/stockpick/search?typed=1&preParams=2&ts=2&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94'r = requests.get(url)print(r.text)print(r.status_code)
返回值如图4所示。
以上代码的返回值为403,也就是代表该网站被禁止访问。是什么原因导致该网站被禁止访问呢?答案就是反爬技术。该网站不想让大家顺利爬取,采用了反爬技术,即采用设置headers(UA、referer、cookies)识别请求的浏览器身份,当请求headers中没有带headers时,返回403。

图4 返回值
所以我们也设置headers请求。详细代码如下:
import requestsheaders={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Cache-Control': 'max-age=0','Connection': 'keep-alive','Cookie':'PHPSESSID=09577a6ece656917a4c43358873b7ae6;cid=09577a6ece656917a4c43358873b7ae61617717486;ComputerID=09577a6ece656917a4c43358873b7ae61617717486;WafStatus=0;v=A7qdyFvvjlmHcQK1nT3B0UKnC-vfaz5vsO-y6cSzZs0Yt1RdrPuOVYB_AvSX','Host': 'www.iwencai.com','Referer': 'http://www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/89.0.4389.114 Safari/537.36'}url='http://www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn =&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94'r = requests.get(url,headers = headers)print(r.text)print(r.status_code)
返回结果如下:
<html><body><script type="text/javascript" src="//s.thsi.cn/js/chameleon/chameleon.1.6.min.1617800.js"></script><script src="//s.thsi.cn/js/chameleon/chameleon.1.6.min.1617800.js" type="text/javascript"></script><script language="javascript" type="text/javascript">window.location.href="//www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94";</script></body></html>200
与我们想要的Elements代码不太一样,如图5所示。
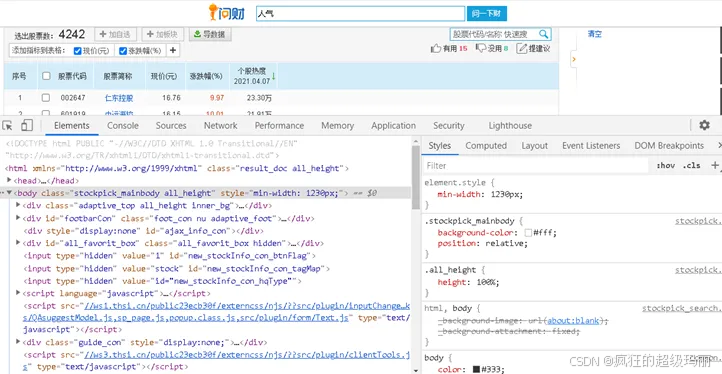
图5 Elements代码
这是网站为了反爬设置的第二个障碍。该网站设置Cookie,并对Cookie进行了函数加密,加密与时间有关。这样爬虫就必须对Cookie中的内容进行破解,或者使用第一个方法,用Selenium自动化爬取。
我们不在这里讲解Cookie的JS加密,前端经验丰富的读者可以自行了解利用浏览器的JS代码调试功能,具体在Sources里面调试。我们把Cookie修改成如下代码,即可解决问题。
'Cookie':'PHPSESSID=09577a6ece656917a4c43358873b7ae6;cid=09577a6ece656917a4c43358873b7ae61617717486;ComputerID=09577a6ece656917a4c43358873b7ae61617717486; WafStatus=0; user_status=0;other_uid=Ths_iwencai_Xuangu_ckirvbpw79oikwk4n56xv71mwnjy1wbz;v=A3QK7FAaqMovLzyGG4vnAzjpRTnlTZg32nEsew7VAP-CeRpvNl1oxyqB_Ald',
爬取代码如下:
import requestsheaders={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Cache-Control': 'max-age=0','Connection': 'keep-alive','Cookie':'PHPSESSID=09577a6ece656917a4c43358873b7ae6;cid=09577a6ece656917a4c43358873b7ae61617717486;ComputerID=09577a6ece656917a4c43358873b7ae61617717486; WafStatus=0; user_status=0;other_uid=Ths_iwencai_Xuangu_ckirvbpw79oikwk4n56xv71mwnjy1wbz;v=A3QK7FAaqMovLzyGG4vnAzjpRTnlTZg32nEsew7VAP-CeRpvNl1oxyqB_Ald','Host': 'www.iwencai.com','Referer': 'http://www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/89.0.4389.114 Safari/537.36'}url='http://www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94'r = requests.get(url,headers = headers)print(r.text)print(r.status_code)
返回结果如图6所示。
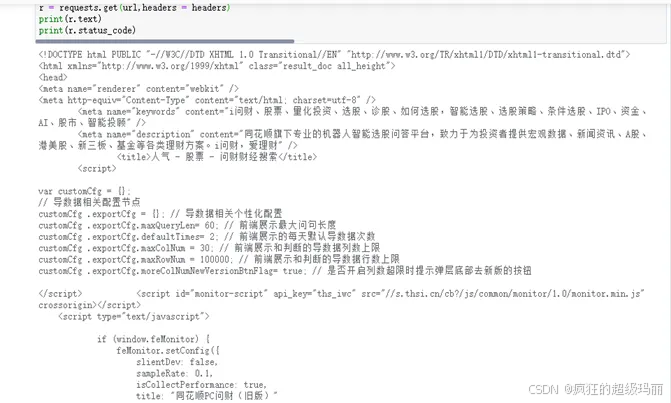
图6 返回结果
2021年4月7日美邦服饰对应在r.status_code中的位置,如图7所示。

图7 美邦服饰对应在r.status_code中的位置
三、使用
BeautifulSoup查找人气排名并保存数据
爬取网页代码,可以使用三种网页抓取方法,如表1所示。

学会使用find和find_all分别找到第一个符合要求的标签和所有符合要求的标签。
(1)find:找到第一个符合要求的标签。常用语法格式如下:
soup.find('a') # 找到第一个符合要求的a标签soup.find('a', title="xxx")soup.find('a', alt="xxx")soup.find('a', class_="xxx")soup.find('a', id="xxx")
(2)find_all:找到所有符合要求的标签。常用语法格式如下:
soup.find_all('a')soup.find_all(['a','b']) # 找到所有符合要求的a标签和b标签soup.find_all('a', limit=5) # 限制仅找到前5个a标签
所以爬虫代码如下:
import requestsfrom bs4 import BeautifulSoupheaders={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Cache-Control': 'max-age=0','Connection': 'keep-alive','Cookie':'PHPSESSID=09577a6ece656917a4c43358873b7ae6;cid=09577a6ece656917a4c43358873b7ae61617717486;ComputerID=09577a6ece656917a4c43358873b7ae61617717488; WafStatus=0; user_status=0;other_uid=Ths_iwencai_Xuangu_ckirvbpw79oikwk4n56xv71mwnjy1wbz;v=A3QK7FAaqMovLzyGG4vnAzjpRTnlTZg32nEsew7VAP-CeRpvNl1oxyqB_Ald','Host': 'www.iwencai.com','Referer': 'http://www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/89.0.4389.114 Safari/537.36'}data={'typed': '1','preParams': '2','ts': '2','f': '','qs': '','selfsectsn': '','querytype': '','searchfilter':'' ,'tid': 'stockpick','w': '人气'}url='http://www.iwencai.com/stockpick/search?typed=1&preParams=&ts=1&f=1&qs=1&selfsectsn=&querytype=&searchfilter=&tid=stockpick&w=%E4%BA%BA%E6%B0%94'r = requests.get(url,headers = headers,params=data)soup = BeautifulSoup(r.text, "lxml")soup.find_all('a',target="_blank")[2:]
返回结果如图8所示。
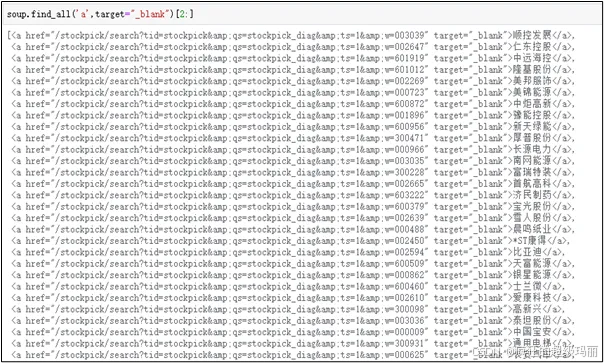
图8 返回股票代码
返回值顺序即是全市综合人气值排名顺序。将清洗好的数据使用to_csv()函数保存到本地。

包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便****


















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









