






【深度学习】强化学习(五)深度强化学习
一、强化学习问题
强化学习的基本任务是通过智能体与环境的交互学习一个策略,使得智能体能够在不同的状态下做出最优的动作,以最大化累积奖励。这种学习过程涉及到智能体根据当前状态选择动作,环境根据智能体的动作转移状态,并提供即时奖励的循环过程。
1、交互的对象
在强化学习中,有两个可以进行交互的对象:智能体和环境
- 智能体(Agent):能感知外部环境的状态(State)和获得的奖励(Reward),并做出决策(Action)。智能体的决策和学习功能使其能够根据状态选择不同的动作,学习通过获得的奖励来调整策略。
- 环境(Environment):是智能体外部的所有事物,对智能体的动作做出响应,改变状态,并反馈相应的奖励。
2、强化学习的基本要素
强化学习涉及到智能体与环境的交互,其基本要素包括状态、动作、策略、状态转移概率和即时奖励。
- 状态(State):对环境的描述,可能是离散或连续的。
- 动作(Action):智能体的行为,也可以是离散或连续的。
- 策略(Policy):智能体根据当前状态选择动作的概率分布。
- 状态转移概率(State Transition Probability):在给定状态和动作的情况下,环境转移到下一个状态的概率。
- 即时奖励(Immediate Reward):智能体在执行动作后,环境反馈的奖励。
3、策略(Policy)
策略(Policy)就是智能体如何根据环境状态 𝑠 来决定下一步的动作 𝑎(智能体在特定状态下选择动作的规则或分布)。
- 确定性策略(Deterministic Policy) 直接指定智能体应该采取的具体动作
- 随机性策略(Stochastic Policy) 则考虑了动作的概率分布,增加了对不同动作的探索。
上述概念可详细参照:【深度学习】强化学习(一)强化学习定义
4、马尔可夫决策过程
为了简化描述,将智能体与环境的交互看作离散的时间序列。智能体从感知到的初始环境
s0
开始,然后决定做一个相应的动作
a0
,环境相应地发生改变到新的状态
s1
,并反馈给智能体一个即时奖励
r1
,然后智能体又根据状态
s1
做一个动作
a1
,环境相应改变为
s2
,并反馈奖励
r2
。这样的交互可以一直进行下去:
s0,a0,s1,r1,a1,…,st−1,rt−1,at−1,st,rt,…,
其中
rt=r(st−1,at−1,st)
是第
t
时刻的即时奖励。这个交互过程可以被视为一个马尔可夫决策过程(Markov Decision Process,MDP)。
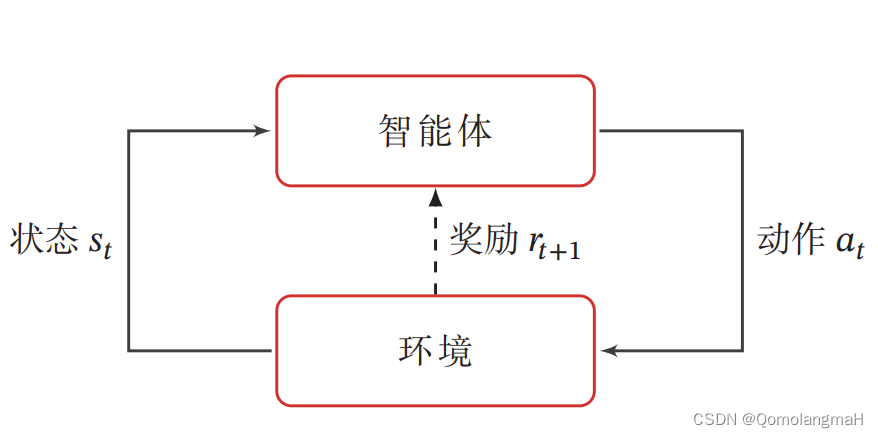
关于马尔可夫决策过程可详细参照:【深度学习】强化学习(二)马尔可夫决策过程
5、强化学习的目标函数
强化学习的目标是通过学习一个良好的策略来使智能体在与环境的交互中获得尽可能多的平均回报。强化学习的目标函数
J(θ)
定义如下:
J(θ)=Eτ∼pθ(τ)[G(τ)]=Eτ∼pθ(τ)[T−1∑t=0γtrt+1]
其中,
θ
表示策略函数的参数,
τ
表示强化学习的轨迹,
γ
是折扣率……
- 这个目标函数表达的是在策略
πθ
下,智能体与环境交互得到的总回报的期望。(这个期望是对所有可能的轨迹进行的)
- 总回报(Total Return)是对一个轨迹的累积奖励,引入折扣率(Discount Factor)来平衡短期和长期回报。
- 总回报:对于一次交互过程的轨迹,总回报是累积奖励的和。
- 折扣回报:引入折扣率,考虑未来奖励的权重。
关于目标函数可详细参照:【深度学习】强化学习(三)强化学习的目标函数
6、值函数
在强化学习中,为了评估策略
π
的期望回报,引入了值函数的概念,包括状态值函数和状态-动作值函数。 值函数在强化学习中起到了桥梁的作用,连接了策略、状态和动作的关系。它们是智能体学习和改进的核心工具,使其能够在未知环境中获得最大的累积奖励。
- 状态值函数
V(s)
:表示从状态
s
开始,执行策略得到的期望总回报。
- 状态-动作值函数
Q(s,a)
:表示在状态
s
下执行动作
a
并执行策略得到的期望总回报。
关于值函数可详细参照:【深度学习】强化学习(四)强化学习的值函数
7、深度强化学习
深度强化学习是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决状态表示、策略表示和值函数建模等问题。 强化学习在早期主要关注离散且有限状态和动作的问题,通常使用表格记录策略和值函数。然而,许多实际问题中的状态和动作空间是连续且高维的,这使得传统的表格方法难以适用。为了解决这些挑战,深度强化学习(Deep Reinforcement Learning,DRL)将强化学习与深度学习相结合,利用深度神经网络来有效地处理复杂的环境。
1. 背景与动机
-
状态和动作空间的复杂性:
在很多实际问题中,状态和动作空间可能是非常庞大、连续的。
- 数量庞大:比如围棋的棋局有
3361≈10170
种状态,动作(即落子位置)数量为361)
-
连续的:
自动驾驶
的环境包含大量的可能状态和动作
- 状态:智能体感知到的环境状态是各种传感器数据,一般都是连续的
- 动作:操作方向盘的方向(−90度∼ 90度)
- 动作:速度控制(0 ∼ 300公里/小时),也是连续的
-
深度学习的优势: 深度学习通过神经网络可以灵活地逼近复杂的函数关系,对高维连续空间的建模具有优势。
2. 关键要素
-
策略函数的深度表示:
- 传统的策略函数可能是基于表格的
- 在深度强化学习中,策略函数通常由深度神经网络表示,使得智能体能够处理高维状态空间,学习复杂的决策规则。
-
值函数的逼近:
- 同样,值函数
Vπ(s)
和
Qπ(s,a)
的逼近也通过深度神经网络完成,因而能够处理大规模的状态空间,从而更好地估计策略的质量。
-
经验回放:
- 为了更有效地利用经验数据,深度强化学习通常使用经验回放(Experience Replay)技术,将智能体过去的经验存储在缓冲区中,然后从中随机抽样进行学习。
-
目标网络:
- 为了稳定训练,DRL 中常常使用目标网络(Target Network),即两个网络的参数在一定步数或周期内进行同步,这有助于减小训练中的不稳定性。
3. 成功案例
-
AlphaGo: DeepMind的AlphaGo在围棋领域实现了超越人类的水平,使用深度强化学习训练的神经网络展示了强大的决策能力。
-
Atari 游戏:
DQN(Deep Q-Network)在Atari 2600(雅达利)游戏上实现了超越人类玩家的表现,通过学习从像素级别的游戏画面中提取有效的状态表示。
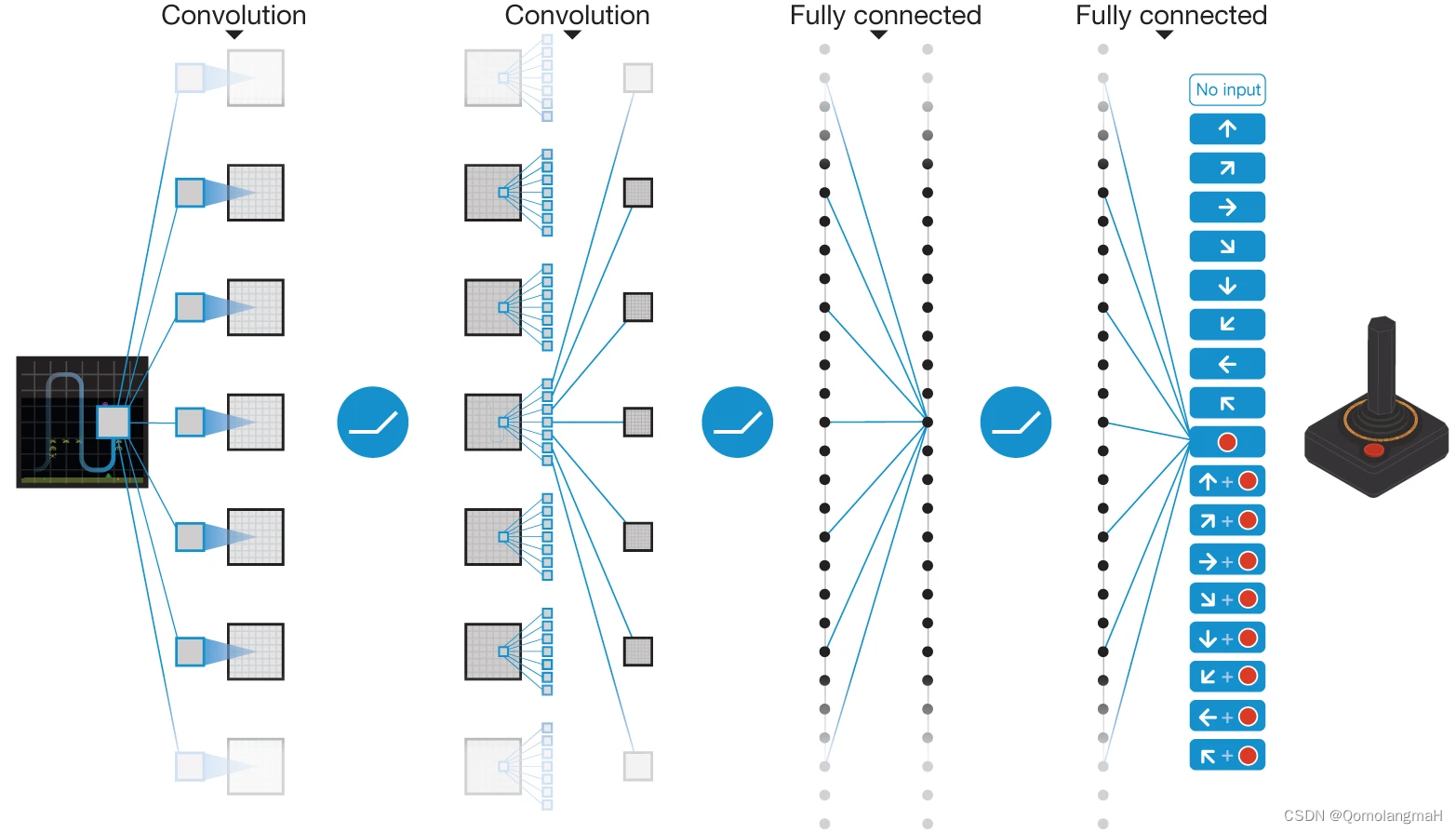
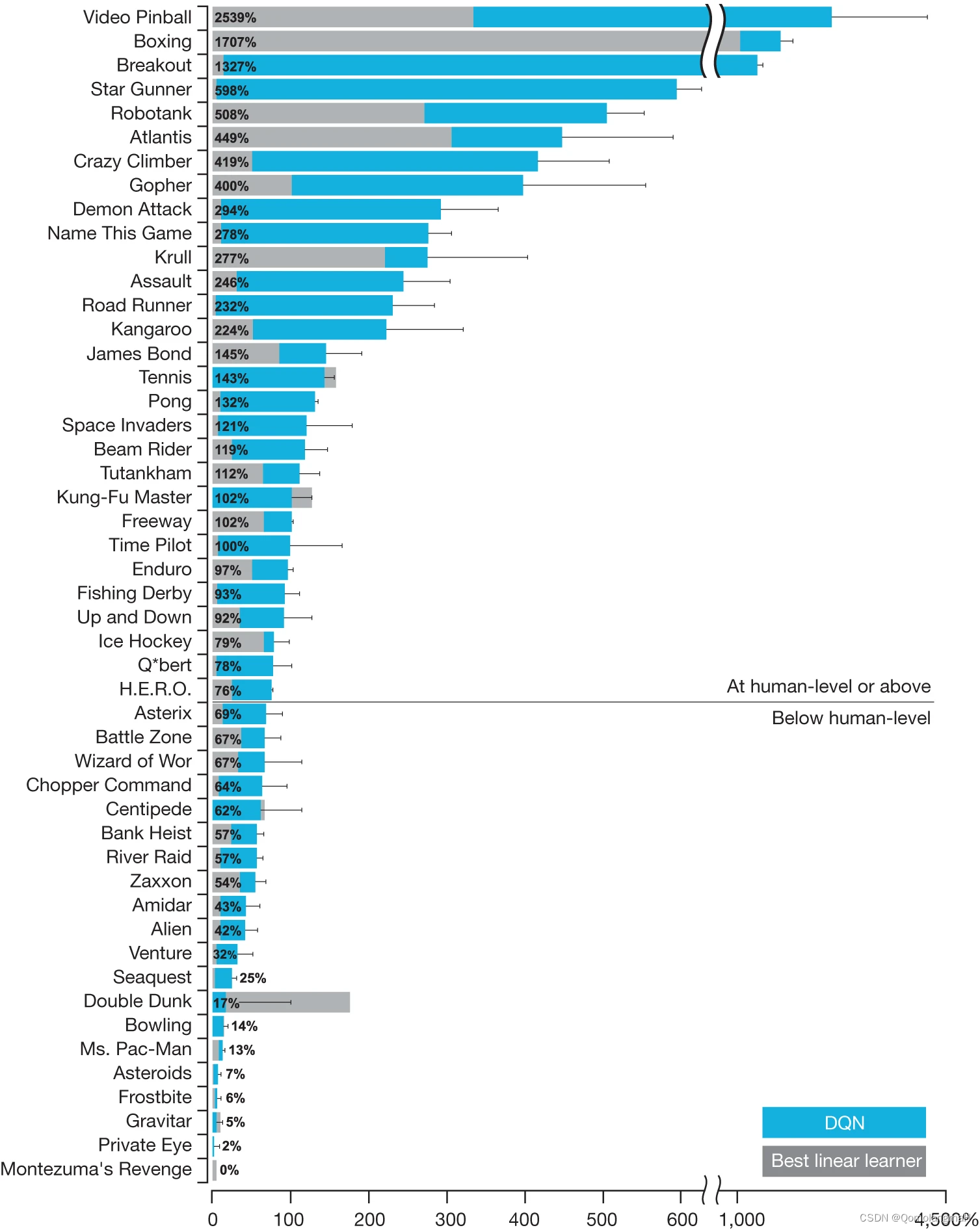
- 机器人控制: DRL 应用于机器人控制,使机器人能够学习在复杂环境中执行任务,如机械臂控制、步态学习等。

- 自动驾驶: 在自动驾驶领域,DRL 被用于训练智能体以处理复杂的驾驶场景,优化车辆的决策和控制。
4. 挑战和未来展望
- 样本效率: DRL 在处理大规模连续空间时可能需要大量的样本,提高样本效率仍然是一个挑战。
- 泛化能力: 深度强化学习在处理一些需要泛化能力的任务时可能受到限制,未来的研究也需要关注模型的泛化能力。
- 可解释性: 深度神经网络通常被认为是黑盒模型,解释其决策过程仍然是一个开放的问题。
5. 核心概念和方法总结
- 深度神经网络:用于表示策略和值函数,处理高维度状态和动作空间。
- 策略梯度方法:通过优化策略的梯度直接学习策略函数的参数。
- 值函数逼近:使用深度神经网络逼近状态值函数和状态-动作值函数。
- 经验回放:存储和重用过去的交互经验,提高学习效率和稳定性。
- 目标网络:引入目标网络以提高训练稳定性。
- 探索与利用:使用随机性策略、ε-贪心策略来平衡探索和利用。















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









