







摘要:随着人工智能技术的飞速发展,AI大模型已经成为推动各行各业技术革新的关键力量。本文将深入探讨AI大模型的核心技术栈的构建,以及不同技术组件的关键作用。
- AI大模型应用的核心技术栈
- 各组件的关键作用
- 基于大模型的应用和普通应用的区别

01
—
AI大模型应用的核心技术栈
为了开发一个AI大模型的应用,我们需要哪些必要的组件来完成相关开发了,下图是AI大模型的应用的核心技术栈。
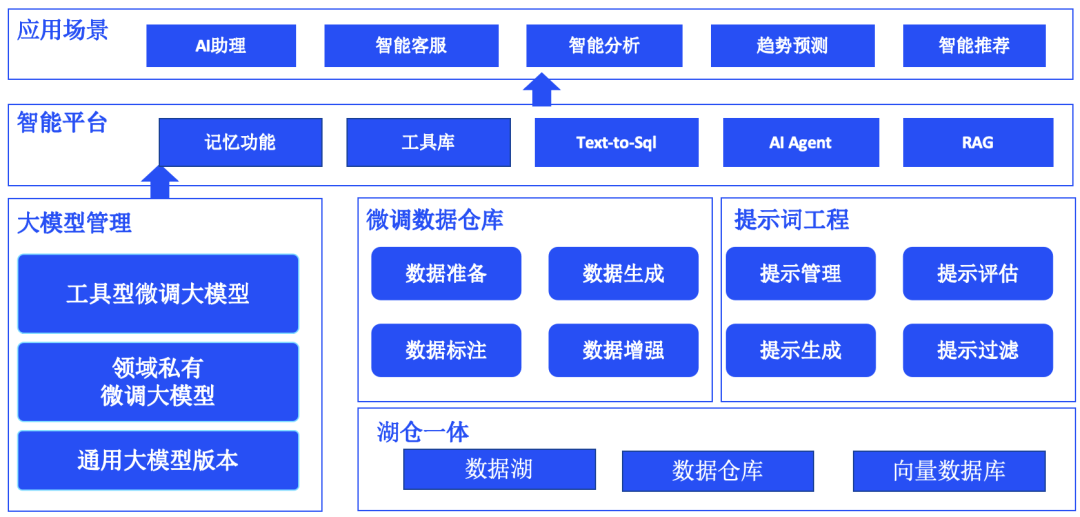
核心技术栈中主要包含的内容是大模型管理(通用大模型、领域私有化的微调大模型、工具型大模型)。微调的数据仓库,以及后期反馈的数据存储到微调数据仓库。提示词工程管理常见的提示词内容,湖仓一体为存储原始数据和向量数据的地方。而开发的智能体的应用则包含记忆功能,工具库,text-to-sql,AI agent 和RAG.后面详细介绍每一部分在整体应用中的作用。如果从使用的业务流程上来介绍一个完整的智能应用,如下图所示:
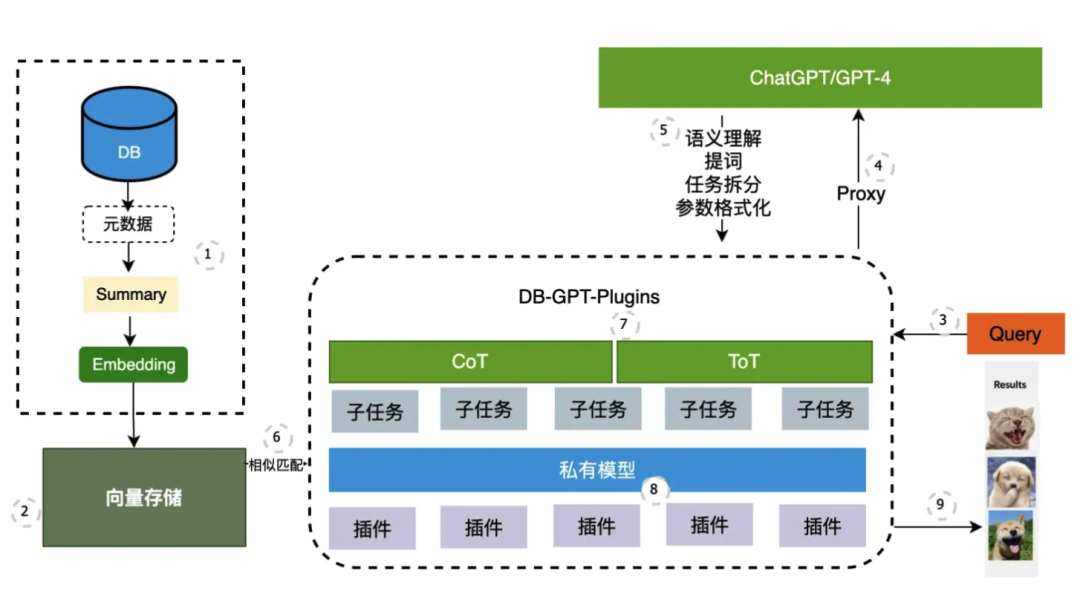
1、将文档数据,图片数据的元数据信息,文章内容总结、文章段落等向量化
2、将以上信息全部存储到向量数据库中,例如ES中
3、用户发起提问
4、智能Agent调用大模型
5、大模型语以理解后,通过调用合适的提示词工程形成一个完善的提示词,并进行参数格式化。
6、如果有专业领域知识内容,则进入到向量数据库中进行匹配。匹配内容返回到agent中。
7、AIagent 将提示词工程拆分成多个子任务,可能子任务需要调用私有模型或者插件
8、插件即为集成的各种工具API,便于完成整体的任务。
9、所有任务完成之后返回到agent中,agent将结果返回给用户。
这里需要说明一下为什么大模型有三种情况:
-
通用大语言模型(参数> 100B)
-
领域大语言模型(参数10~70B)
-
工具类模型(参数<10B)
在人工智能领域,"大模型"通常指的是具有大量参数的复杂模型,它们能够处理和理解大量数据,并在特定任务上表现出色。根据它们的应用范围和功能,大模型可以被分为以下几种类型:
-
通用大模型(General-Purpose Large Models):
-
- 这些模型设计得足够灵活,能够处理多种类型的任务,不局限于特定的领域或应用。例如,一个通用的语言模型可以用于文本生成、翻译、摘要、问答等多种自然语言处理任务。
-
领域大模型(Domain-Specific Large Models):
-
- 领域大模型是针对特定领域或行业定制的模型,它们在特定类型的数据和任务上进行了优化。例如,医疗领域的大模型可能专门用于理解医学文献、辅助诊断或患者记录分析。
-
工具大模型(Tool-Oriented Large Models):
-
- 工具大模型专注于提供特定的功能或服务,它们通常被设计为与其他系统或应用程序集成,以增强或自动化特定的工作流程。例如,一个图像识别工具大模型可能被集成到电子商务平台中,用于自动分类商品图片。
-
每种类型的大模型都有其特定的优势和应用场景:
-
通用大模型的优势在于它们的灵活性和广泛的适用性,但可能需要针对特定任务进行微调以获得最佳性能。
-
领域大模型的优势在于它们在特定领域的专业性和高效性,但可能不如通用模型那样灵活。
-
工具大模型的优势在于它们能够提供高度专业化的服务,并且易于集成到现有的系统和工作流程中。
选择哪种类型的大模型取决于具体的应用需求、可用的数据、预期的性能和资源限制。在实际应用中,这些模型也可以相互结合,以实现更全面和高效的解决方案。例如,一个领域特定的工具大模型可能使用通用大模型作为其基础,然后针对特定任务进行定制和优化。
02
—
关键步骤的关键作用
提示词工程(Prompt Engineering)是一种在人工智能领域,特别是在自然语言处理(NLP)中使用的技术,它涉及到设计和优化用于激发或引导AI模型输出特定类型回答的提示或问题。在基于Transformer的模型如GPT(生成式预训练转换器)中,提示词工程尤为重要,因为这些模型通常通过大量的文本数据进行预训练,能够根据输入的提示生成文本。
提示词工程(Prompt Engineering)是一种在人工智能领域,特别是在自然语言处理(NLP)中使用的技术,它涉及到设计和优化用于激发或引导AI模型输出特定类型回答的提示或问题。在基于Transformer的模型如GPT(生成式预训练转换器)中,提示词工程尤为重要,因为这些模型通常通过大量的文本数据进行预训练,能够根据输入的提示生成文本。
提示词工程的作用
- 引导回答:通过精确的提示词,可以引导AI模型提供更加准确和相关的回答。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









