






matlab R2024a以上
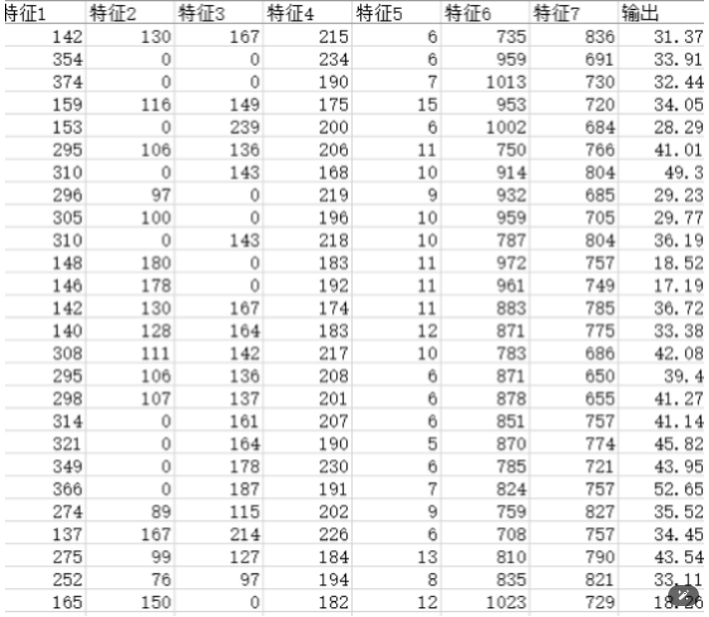
一、数据集
二、2024年中科院SCI期刊牛顿-拉夫逊优化算法NRBO

牛顿-拉夫逊优化算法(Newton-Raphson-based optimizer, NBRO)是一种新型的元启发式算法(智能优化算法),该成果由Sowmya等人于2024年2月发表在中科院2区Top SCI期刊《Engineering Applications of Artificial Intelligence》上。
NRBO受牛顿-拉弗逊方法启发,利用牛顿-拉弗逊搜索规则(NRSR)和躲避陷阱算子(TAO),以及一些矩阵组来探索整个搜索过程,进一步探索最佳结果。NRSR利用牛顿-拉弗逊方法改进NRBO的探索能力,提高收敛速度以达到改善搜索空间位置的目的。TAO帮助NRBO避免陷入局部最优解陷阱。对NRBO的性能进行了评估。
一、种群初始化
像其他元启发算法一样,NRBO通过在候选解的边界内产生初始随机种群来开始搜索最优解。基于存在Np个种群,且每个种群由dim决策变量/向量组成的事实。
![]()
二、Newton-Raphson搜索规则(NRSR)
这些矢量由NRSR控制,可以更准确地探索可行区域并获得更好的位置。NRSR是基于NRM的概念,提出了提高勘探趋势和加速收敛。由于许多优化技术是不可微的,在这种情况下,数学NRM被用来取代显式公式的功能。NRM从一个假定的初始解开始,并在一个确定的方向上进行到下一个位置。为了从中公式(5)中获取NRSR,必须使用TS来确定二阶导数。f(x−Δx)和f(x+Δx)的TS如下所示:
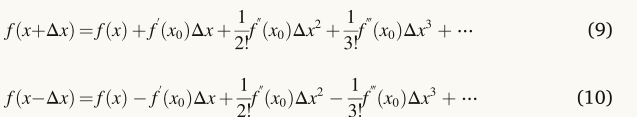
通过减去/加上等式(9)和等式(10),f“(x)和f”(x)的表达式推导如下:
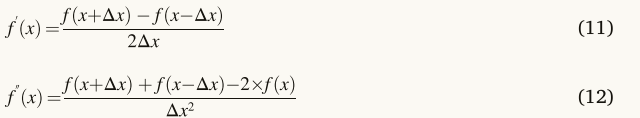
将等式(11)和等式(12)由方程式(5),并且更新的根位置被重写如下。
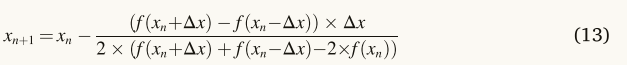
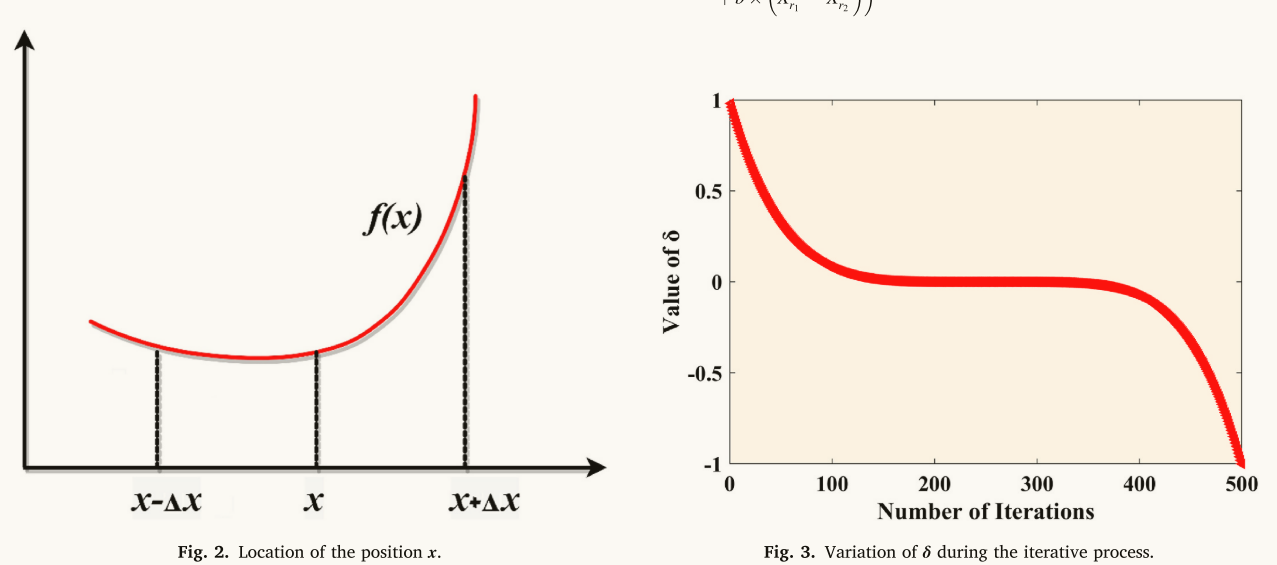
考虑到NRSR应该是NRBO的主要组成部分,有必要进行某些调整,以管理基于人口的搜索。作为等式(13),x的相邻位置分别用xn+Δx和xn-Δx表示,如图2所示。NRBO将这对相邻位置转换为群体中的另外两个向量。因为f(xn)是一个极小化问题,如图2所示,位置xn+Δx的适应度值比位置x的差,而位置xn-Δx的适应度值比位置xn的大。因此,NRBO用位置xn-Δx替换位置Xb,位置Xb在其邻域中的位置比位置xn更好,而位置xn+Δx被位置Xw替换,位置Xw在其邻域中的位置比位置xn更差。所建议的方法的另一优点在于,其使用位置(xn)而不是其适合度(f(xn)),这节省了计算时间。接下来,建议的NRSR表示如下:
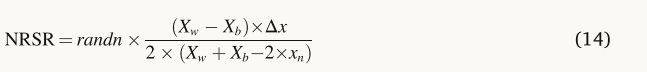
其中randn表示具有平均值0和方差1的正态分布随机数,Xw表示最差位置,Xb表示最佳位置。当量(14)可以通过用当前的解决方案来帮助它来更新它的位置。当量(14)具有一个随机参数,以提高NRBO的搜索能力,并更好地平衡开发和勘探能力。作为经验法则,所提出的算法必须能够在多样化和集约化之间达到平衡,以便在搜索空间中发现最优解并最终收敛到全局解。可以通过应用称为δ的自适应系数来增强算法。δ的表达式如方程所示。

其中IT表示当前迭代,Max IT表示最大迭代次数。为了保持勘探和开采阶段之间的平衡,参数δ在迭代过程中自适应。图3显示了δ在每次迭代中的变化。δ的值在1到-1之间变化,如方程式所示。(十五)、该算法通过引入自适应参数δ,在优化过程中考虑了随机行为,增加了多样性,避免了局部最优,同时大大减少了迭代次数,从而改进了NRBO算法。方程中Δx的表达式(14)如方程式所示。(16)、

其中Xb表示迄今为止获得的最佳解,并且兰德(1:dim)是具有dim决策变量的随机数。现在,方程(13)通过考虑NRSR进行修改,并重写如下。

通过引入另一个称为ρ的参数,改进了所提出的NRBO的利用,该参数将种群引导到正确的方向。ρ的表达式如下所示。
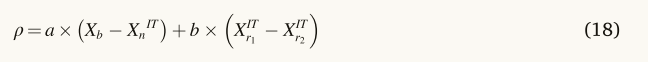
其中a和B是(0,1)之间的随机数,r1和r2是从总体中随机选择的不同整数。然而,r1和r2的值不相等。矢量(Xn IT)的当前位置已由等式(1)更新。(19)、
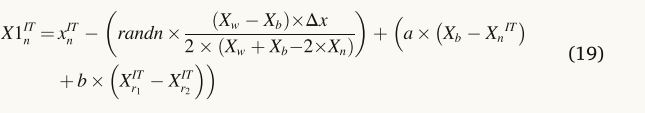
其中X1 IT n是通过更新xIT n而得到的新向量位置。NRSR通过(Weerakoon和Fernando,2000年; Magre Rennan和Argyros,2018年)提出的NRM和Eq.(13)更改并重写如下。
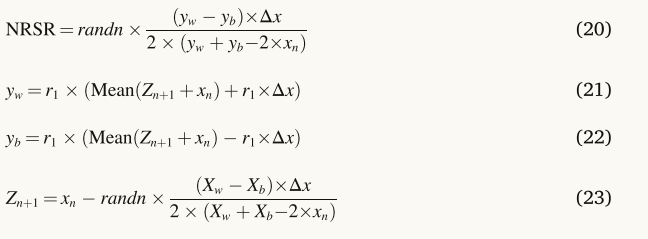
其中,yw和yb是使用Zn+1和xn生成的两个向量的位置,r1表示(0,1)之间的随机数。NRSR的增强版本如方程(1)所示。(20)、使用等式(20),方程式(19)更新如下。
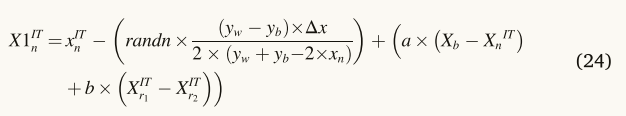
有必要通过用等式(1)中的当前矢量xIT n的位置替换最佳矢量Xb的位置来构造新矢量X2IT n。(24页)。
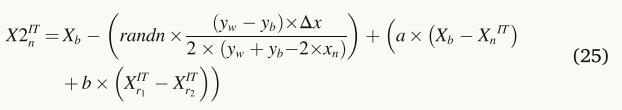
开发阶段是这个搜索方向策略的主要焦点。当涉及到局部搜索时,Eq.(25)是良性的,但它有局限性,当涉及到全球搜索,而搜索策略提出的方程。(24)对于全局搜索是有益的,但是当涉及到局部搜索时具有局限性。无论如何,NRBO都使用Eq。(24)和(25)改善潜水和强化阶段。下一次迭代期间的新位置向量表示为等式(1)。(26页)。
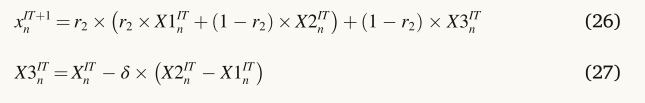
其中r2表示(0,1)之间的随机数。
三、陷阱规避操作(TAO)
纳入TAO的目的是为了提高建议的NRBO处理实际问题的有效性。TAO是从Ahmadianfar等人(2002)采用的修改和增强的算子,2020年)的报告。通过使用TAO,可以显著地改变xIT+1 n的位置。它通过组合最佳位置Xb和当前矢量位置XITn产生具有增强质量XITTAO的解。如果兰德的值小于DF,则解XIT TAO由等式产生。(28页)。
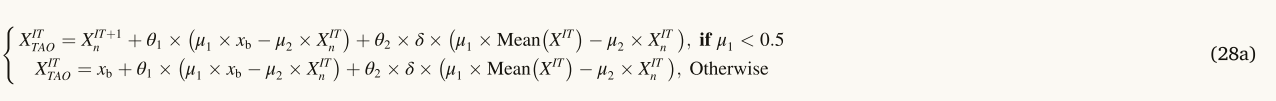

其中,兰德表示(0,1)之间的均匀随机数,θ1和θ2分别是(− 1,1)和(− 0.5,0.5)之间的均匀随机数,DF表示控制NRBO性能的决定因子,μ1和μ2是随机数,使用等式(29)和等式(30)分别表示。

其中,rand表示(0,1)之间的随机数,Δ表示(0,1)之间的数。当量(29)和等式(30)被进一步简化如下。

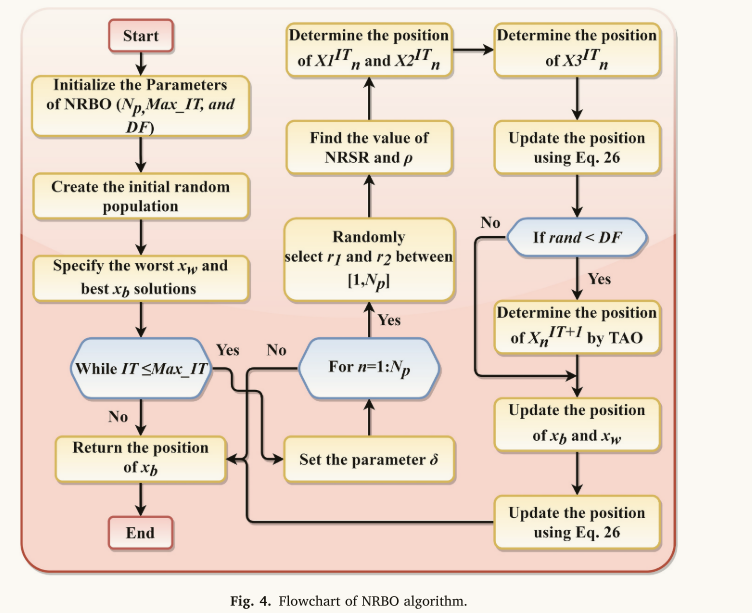
其中β表示二进制数,1或0,rand表示随机数。如果Δ的值大于或等于0.5,则β的值为0;否则,该值为1。由于参数μ1和μ2的选择具有随机性,种群变得更加多样化,并逃离局部最优解,这有助于提高其多样化。与NRBO类似,GBO也受到牛顿方法的启发。因此,NRBO概念可能看起来类似于GBO,但由于NRBO的独特功能,其性能仍然优于GBO。算法中给出了NRBO的伪代码。所提出的NRBO的流程图如图4所示。
三、Transformer-LSTM模型
Transformer-LSTM 模型结合了 Transformer 和 LSTM(长短期记忆网络)两种架构的优点,用于处理序列数据。以下是对这两种模型及其结合的简要介绍:
1. LSTM(Long Short-Term Memory)
LSTM 是一种特殊的递归神经网络(RNN),特别适用于处理和预测序列数据中的长时间依赖关系。传统的 RNN 在处理长序列时会遇到梯度消失或梯度爆炸问题,而 LSTM 通过引入“记忆单元”(memory cell)和“门控机制”(gating mechanisms),如输入门、遗忘门和输出门,能够有效地保留或遗忘信息,从而克服这些问题。
- 输入门(Input Gate):控制新信息进入记忆单元的程度。
- 遗忘门(Forget Gate):决定记忆单元中已有信息的保留或丢弃。
- 输出门(Output Gate):决定记忆单元的信息将如何影响当前输出。
LSTM 擅长处理时间序列、自然语言处理等任务,特别是在需要记忆长时间依赖的信息时表现出色。
2. Transformer
Transformer 是一种完全基于注意力机制(Attention Mechanism)的架构,最初由 Vaswani 等人在 2017 年提出。与 RNN 类模型不同,Transformer 不依赖于序列顺序地处理数据,而是可以并行处理整个序列。因此,Transformer 在训练效率和捕捉长距离依赖方面具有显著优势。
- 自注意力机制(Self-Attention Mechanism):允许模型在处理序列的每个位置时,都能考虑整个序列中的其他位置的信息。
- 多头注意力(Multi-Head Attention):通过并行计算多个不同的注意力机制,捕捉到序列中更丰富的依赖关系。
Transformer 在机器翻译、文本生成、图像生成等领域取得了显著的成功,特别是像 BERT、GPT 这样的预训练模型。
3. Transformer-LSTM 结合模型
Transformer-LSTM 模型尝试结合两种架构的优点。一般有两种常见的结合方式:
- LSTM + Transformer:首先使用 LSTM 处理输入序列,提取时间序列中的长短期依赖关系,然后将这些特征传递给 Transformer 进行更高级的特征提取和捕捉全局依赖。这种方式可以保留 LSTM 的时序依赖能力,同时利用 Transformer 的全局特征捕捉能力。
- Transformer + LSTM:在这种架构中,Transformer 通常用于捕捉序列中的全局依赖和上下文信息,而 LSTM 则用于更好地理解这些特征在时间序列中的演变。这种方式常用于需要结合时间和全局依赖的复杂任务中。
4. 应用场景
- 自然语言处理(NLP):在机器翻译、文本生成等任务中,Transformer-LSTM 模型可以同时处理局部和全局的依赖关系,提升模型性能。
- 时间序列预测:在金融、气象等领域,结合模型可以更好地捕捉时间序列的动态特征。
5. 优缺点
- 优点:
- 能够同时捕捉序列中的长短期依赖和全局特征。
- 适应多种复杂任务,尤其在处理长序列时具有优势。
- 缺点:
- 模型复杂度较高,训练和推理时间较长。
- 需要大量数据和计算资源进行训练。
通过结合 LSTM 的时序建模能力和 Transformer 的全局依赖捕捉能力,Transformer-LSTM 模型能够更好地处理复杂的序列数据任务。
四、效果展示
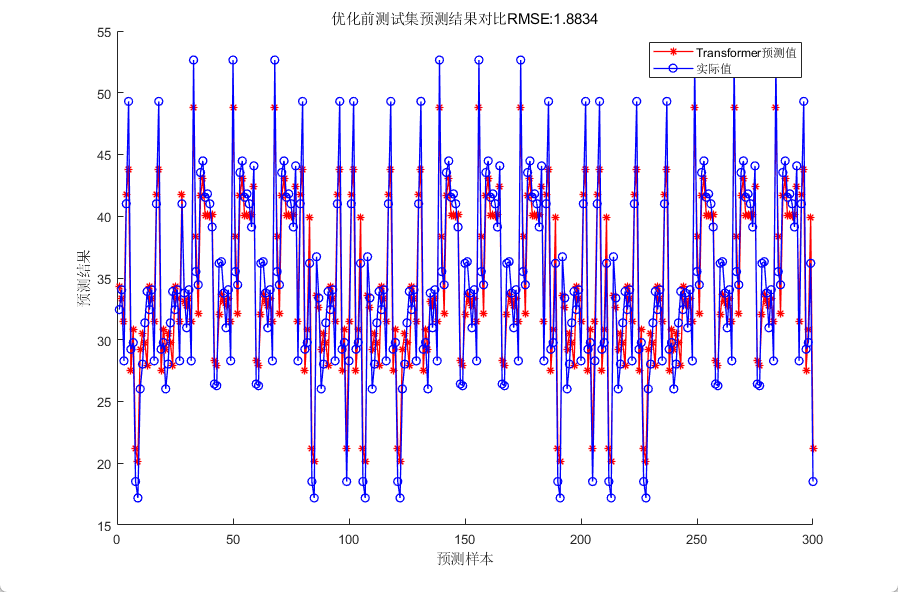
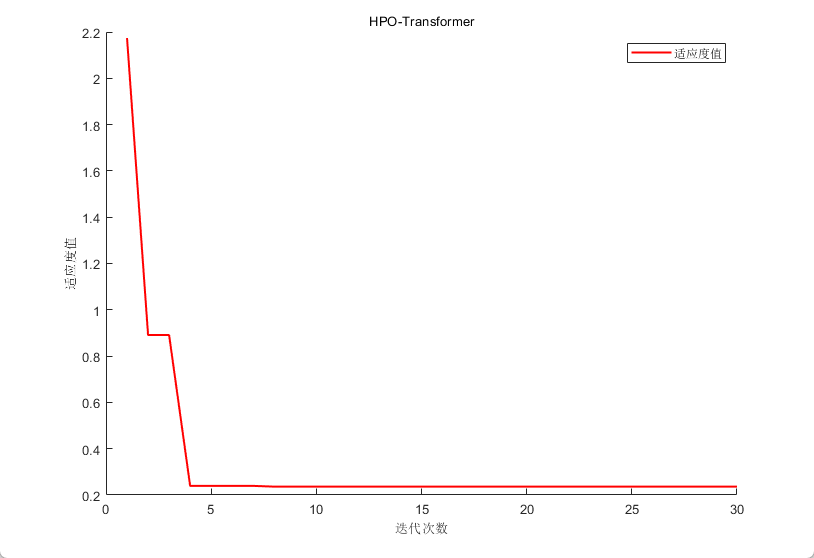
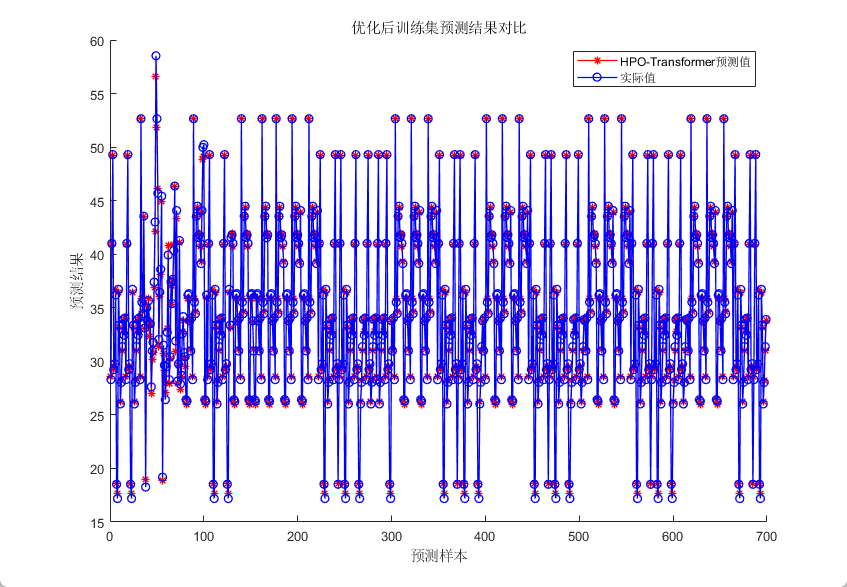
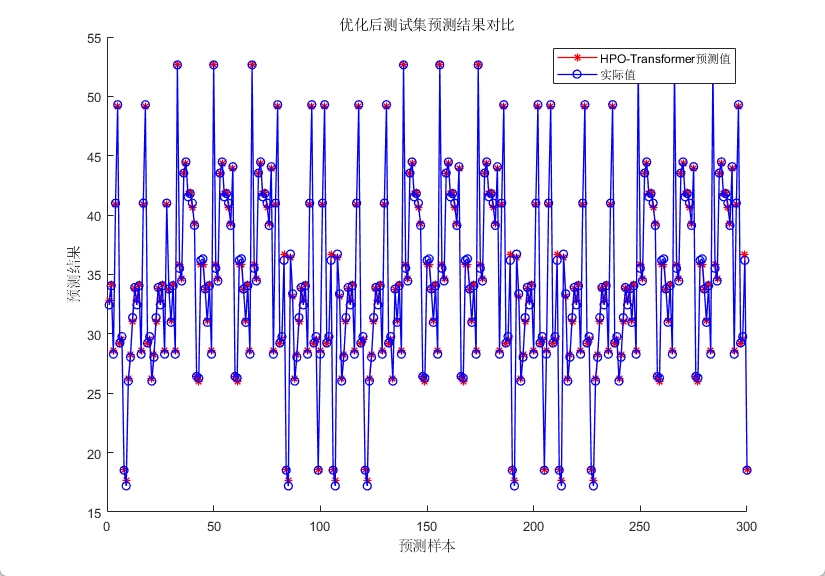
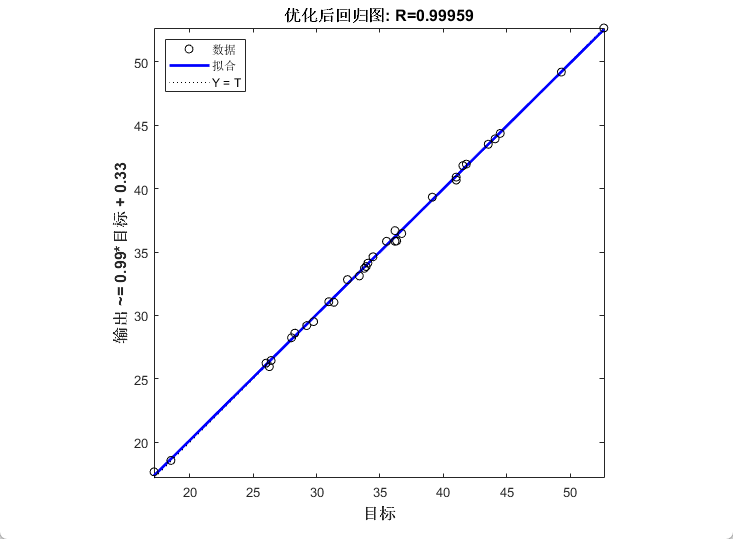
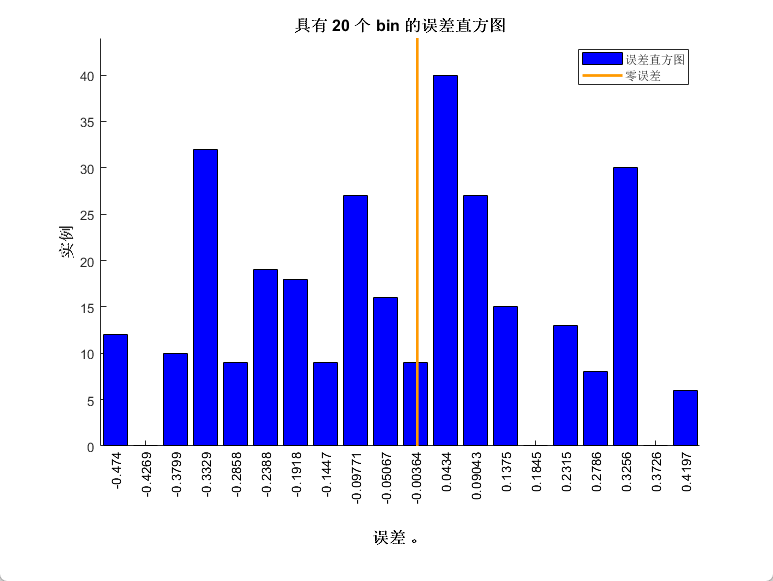
五、代码获取
感兴趣的朋友可以关注最后一行
% 参数设置
options0 = trainingOptions('adam', ...
'Plots','none', ...
'MaxEpochs', 100, ...
'MiniBatchSize', 32, ...
'Shuffle', 'every-epoch', ...
'InitialLearnRate', 0.01, ...
'L2Regularization', 0.002, ... % 正则化参数
'ExecutionEnvironment', "auto",...
'Verbose',1);
% https://mbd.pub/o/bread/mbd-ZpqUlJtw














 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









