






深度学习目标检测算法Yolov5训练雾天行人车辆检测数据集模型 基于YOLOv5的雾天行人车辆检测,识别雾天车辆及行人的检测
文章目录
雾天行人车辆检测数据集 nc: 5
names:
:- person- bus- bicycle- car- motorbike
4312张,8:1:1比例划分,txt格式。
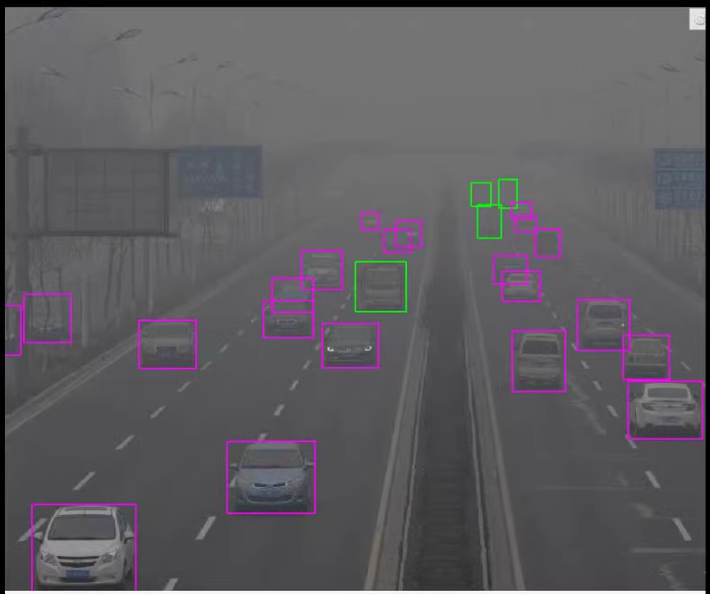
使用YOLOv5模型进行目标检测任务。以下是完整的流程,包括安装依赖、准备数据集、配置YOLOv5、训练模型、评估模型、推理代码以及构建GUI应用程序的详细步骤。
标题:基于YOLOv5的雾天行人车辆检测

1. 安装依赖
首先,确保你的环境中已安装了必要的库和工具:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113 # 根据CUDA版本选择
git clone https://github.com/ultralytics/yolov5 # 克隆YOLOv5仓库
cd yolov5
pip install -r requirements.txt
2. 准备数据集
数据集已经按照近似8:1:1的比例划分为训练集、验证集和测试集,并且标注文件为YOLO适用的txt格式。

数据集结构示例
foggy_pedestrian_vehicle_dataset/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ └── ...
│ ├── val/
│ │ ├── img801.jpg
│ │ └── ...
│ └── test/
│ ├── img1201.jpg
│ └── ...
└── labels/
├── train/
│ ├── img1.txt
│ └── ...
├── val/
│ ├── img801.txt
│ └── ...
└── test/
├── img1201.txt
└── ...
创建data.yaml文件
在YOLOv5项目的根目录下创建一个名为data.yaml的数据配置文件,内容如下:
train: ./path/to/foggy_pedestrian_vehicle_dataset/images/train/
val: ./path/to/foggy_pedestrian_vehicle_dataset/images/val/
test: ./path/to/foggy_pedestrian_vehicle_dataset/images/test/
nc: 5 # 类别数量
names: ['person', 'bus', 'bicycle', 'car', 'motorbike'] # 类别名称
请将路径替换为你实际的数据集路径。
3. 配置并训练YOLOv5模型
训练模型
使用YOLOv5的预训练模型开始训练。这里我们以YOLOv5s为例:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt
--img 640: 输入图像尺寸。--batch 16: 批次大小。--epochs 50: 训练轮数。--data data.yaml: 数据配置文件。--weights yolov5s.pt: 使用YOLOv5s预训练权重。
模型评估
训练完成后,可以对验证集进行评估:
python val.py --weights runs/train/exp/weights/best.pt --data data.yaml --img 640
这会输出模型在验证集上的性能指标(如mAP)。
4. 推理代码
编写推理代码用于预测新图片中的目标:
from pathlib import Path
import cv2
from models.experimental import attempt_load
from utils.general import non_max_suppression, scale_coords
from utils.datasets import letterbox
def detect(image_path, model, img_size=640):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
names = model.module.names if hasattr(model, 'module') else model.names
# 读取图像
img0 = cv2.imread(image_path)
img = letterbox(img0, new_shape=img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
# 转换为tensor
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 to fp32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 推理
pred = model(img)[0]
pred = non_max_suppression(pred, 0.25, 0.45, classes=None, agnostic=False)
# 处理预测结果
for i, det in enumerate(pred): # detections per image
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in reversed(det):
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, img0, label=label, color=(0, 255, 0), line_thickness=3)
return img0
# 示例用法
image_path = './path/to/test/image.jpg'
model = attempt_load('runs/train/exp/weights/best.pt', map_location='cuda')
result_image = detect(image_path, model)
cv2.imshow('Result Image', result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
请注意,上述代码需要导入YOLOv5项目中的一些辅助函数和类,例如models.experimental.attempt_load和utils.general.non_max_suppression等。
5. 构建GUI应用程序
使用PyQt5构建一个简单的GUI应用程序,用于选择图片并展示检测结果:
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QVBoxLayout, QPushButton, QLabel, QFileDialog
from PyQt5.QtGui import QPixmap
from PyQt5.QtCore import Qt
import cv2
class App(QWidget):
def __init__(self, model):
super().__init__()
self.model = model
self.initUI()
def initUI(self):
self.setWindowTitle('雾天行人车辆检测系统')
layout = QVBoxLayout()
self.image_label = QLabel(self)
layout.addWidget(self.image_label)
self.select_button = QPushButton('选择图片', self)
self.select_button.clicked.connect(self.select_image)
layout.addWidget(self.select_button)
self.setLayout(layout)
self.show()
def select_image(self):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Image Files (*.jpg *.jpeg *.png)", options=options)
if file_name:
self.detect_and_show(file_name)
def detect_and_show(self, image_path):
detected_image = detect(image_path, self.model)
height, width, channel = detected_image.shape
bytes_per_line = 3 * width
q_img = QImage(detected_image.data, width, height, bytes_per_line, QImage.Format_RGB888).rgbSwapped()
pixmap = QPixmap.fromImage(q_img)
self.image_label.setPixmap(pixmap)
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = App(model) # 将训练好的模型传入
sys.exit(app.exec_())


















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









