






train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
for num, (image, label) in enumerate(train_loader):
image_batch = torchvision.utils.make_grid(image, padding=2)
plt.imshow(np.transpose(image_batch.numpy(), (1, 2, 0)), vmin=0, vmax=255)
plt.show()
print(label)
得到图片:


这是标签:
tensor([2, 1, 7, 7, 2, 4, 2, 2, 0, 1, 7, 1, 5, 7, 9, 0, 2, 7, 4, 7, 0, 2, 7, 1,
6, 9, 1, 1, 1, 5, 4, 3, 8, 0, 1, 0, 1, 3, 8, 0, 1, 4, 5, 1, 8, 4, 7, 3,
8, 3, 2, 2, 0, 0, 4, 0, 2, 9, 7, 1, 8, 3, 2, 3])
tensor([6, 6, 7, 2, 5, 4, 0, 3, 4, 6, 1, 4, 1, 9, 2, 2, 8, 7, 5, 7, 9, 6, 6, 7,
1, 9, 9, 5, 5, 6, 9, 6, 8, 5, 5, 7, 8, 9, 8, 3, 1, 0, 1, 4, 6, 1, 8, 6,
1, 4, 6, 7, 1, 9, 5, 4, 3, 4, 6, 1, 7, 3, 7, 6])
tensor([7, 1, 5, 1, 4, 0, 9, 2, 2, 0, 1, 5, 2, 3, 6, 4, 6, 9, 3, 3, 2, 8, 1, 5,
8, 0, 1, 4, 5, 6, 2, 6, 4, 9, 2, 0, 7, 2, 0, 1, 2, 4, 4, 6, 5, 9, 1, 2,
5, 3, 3, 8, 8, 3, 4, 5, 2, 6, 0, 0, 8, 7, 1, 7])
## 4.使用残差网络RESNET识别手写数字
### 残差网络:
残差网络(Residual Network,ResNet)是在神经网络模型中给非线性层增加直连边的方式来缓解梯度消失问题,从而使训练深度神经网络变得更加容易。在残差网络中,最基本的单位为残差单元。
### 算子ResBlock:
首先实现一个算子ResBlock来构建残差单元,其中定义了use\_residual参数,用于在后续实验中控制是否使用残差连接:
class ResBlk(nn.Module): # 定义Resnet Block模块
“”"
resnet block
“”"
def \_\_init\_\_(self, ch_in, ch_out, stride=1): # 进入网络前先得知道传入层数和传出层数的设定
"""
:param ch_in:
:param ch_out:
“”"
super(ResBlk, self).init() # 初始化
# we add stride support for resbok, which is distinct from tutorials.
# 根据resnet网络结构构建2个(block)块结构 第一层卷积 卷积核大小3\*3,步长为1,边缘加1
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 将第一层卷积处理的信息通过BatchNorm2d
self.bn1 = nn.BatchNorm2d(ch_out)
# 第二块卷积接收第一块的输出,操作一样
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# 确保输入维度等于输出维度
self.extra = nn.Sequential() # 先建一个空的extra
if ch_out != ch_in:
# [b, ch\_in, h, w] => [b, ch\_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x): # 定义局部向前传播函数
out = F.relu(self.bn1(self.conv1(x))) # 对第一块卷积后的数据再经过relu操作
out = self.bn2(self.conv2(out)) # 第二块卷积后的数据输出
out = self.extra(x) + out # 将x传入extra经过2块(block)输出后与原始值进行相加
out = F.relu(out) # 调用relu
return out
### ResNet18结构及六个模块:
残差网络就是将很多个残差单元串联起来构成的一个非常深的网络。ResNet18 的网络结构如图所示:
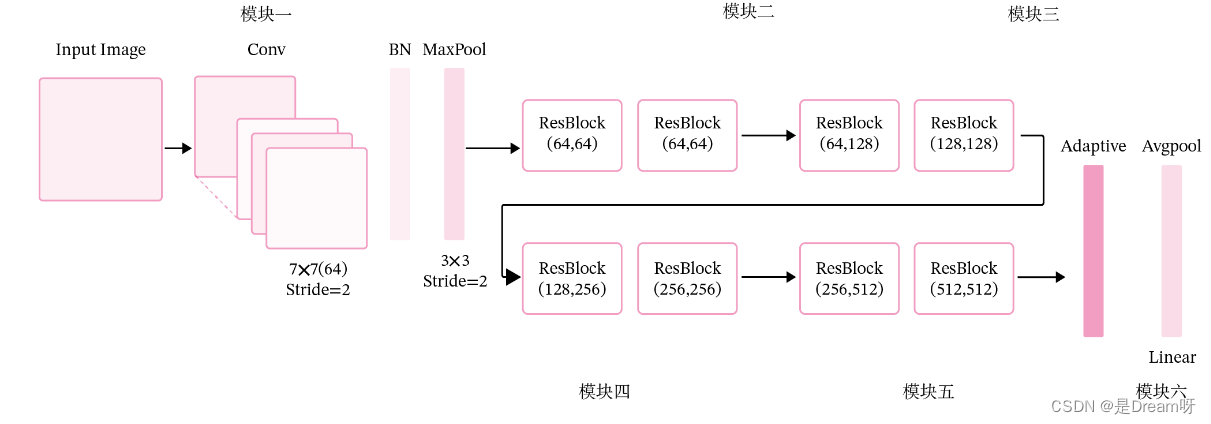
其中为了便于理解,可以将ResNet18网络划分为6个模块:
第一模块:包含了一个步长为2,大小为7 × 7 的卷积层,卷积层的输出通道数为64,卷积层的输出经过批量归一化、ReLU激活函数的处理后,接了一个步长为2的3 × 3 的最大汇聚层;
第二模块:包含了两个残差单元,经过运算后,输出通道数为64,特征图的尺寸保持不变;
第三模块:包含了两个残差单元,经过运算后,输出通道数为128,特征图的尺寸缩小一半;
第四模块:包含了两个残差单元,经过运算后,输出通道数为256,特征图的尺寸缩小一半;
第五模块:包含了两个残差单元,经过运算后,输出通道数为512,特征图的尺寸缩小一半;
第六模块:包含了一个全局平均汇聚层,将特征图变为1 × 1 的大小,最终经过全连接层计算出最后的输出。
### 定义完整网络:
class ResNet18(nn.Module): # 构建resnet18层
def \_\_init\_\_(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential( # 首先定义一个卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(32)
)
# followed 4 blocks 调用4次resnet网络结构,输出都是输入的2倍
self.blk1 = ResBlk(32, 64, stride=1)
self.blk2 = ResBlk(64, 128, stride=1)
self.blk3 = ResBlk(128, 256, stride=1)
self.blk4 = ResBlk(256, 256, stride=1)
self.outlayer = nn.Linear(256 \* 1 \* 1, 10) # 最后是全连接层
def forward(self, x): # 定义整个向前传播
x = F.relu(self.conv1(x)) # 先经过第一层卷积
x = self.blk1(x) # 然后通过4次resnet网络结构
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1) # 平铺一维值
x = self.outlayer(x) # 全连接层
return x
完整代码:
coding=gbk
1.加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
import argparse
2.超参数
BATCH_SIZE = 32#每批处理的数据 一次性多少个
DEVICE = torch.device(“cuda”)#使用GPU
DEVICE = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)#使用GPU
EPOCHS =4 #训练数据集的轮次
3.图像处理
pipeline = transforms.Compose([transforms.ToTensor(), #将图片转换为Tensor
])
4.下载,加载数据
from torch.utils.data import DataLoader
#下载
train_set = datasets.MNIST(“data”,train=True,download=True,transform=pipeline)
test_set = datasets.MNIST(“data”,train=False,download=True,transform=pipeline)
#加载 一次性加载BATCH_SIZE个打乱顺序的数据
train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True)
test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)
5.构建网络模型
class ResBlk(nn.Module): # 定义Resnet Block模块
“”"
resnet block
“”"
def \_\_init\_\_(self, ch_in, ch_out, stride=1): # 进入网络前先得知道传入层数和传出层数的设定
"""
:param ch_in:
:param ch_out:
“”"
super(ResBlk, self).init() # 初始化
# we add stride support for resbok, which is distinct from tutorials.
# 根据resnet网络结构构建2个(block)块结构 第一层卷积 卷积核大小3\*3,步长为1,边缘加1
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 将第一层卷积处理的信息通过BatchNorm2d
self.bn1 = nn.BatchNorm2d(ch_out)
# 第二块卷积接收第一块的输出,操作一样
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# 确保输入维度等于输出维度
self.extra = nn.Sequential() # 先建一个空的extra
if ch_out != ch_in:
# [b, ch\_in, h, w] => [b, ch\_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x): # 定义局部向前传播函数
out = F.relu(self.bn1(self.conv1(x))) # 对第一块卷积后的数据再经过relu操作
out = self.bn2(self.conv2(out)) # 第二块卷积后的数据输出
out = self.extra(x) + out # 将x传入extra经过2块(block)输出后与原始值进行相加
out = F.relu(out) # 调用relu
return out
class ResNet18(nn.Module): # 构建resnet18层
def \_\_init\_\_(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential( # 首先定义一个卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(32)
)
# followed 4 blocks 调用4次resnet网络结构,输出都是输入的2倍
self.blk1 = ResBlk(32, 64, stride=1)
self.blk2 = ResBlk(64, 128, stride=1)
self.blk3 = ResBlk(128, 256, stride=1)
self.blk4 = ResBlk(256, 256, stride=1)
self.outlayer = nn.Linear(256 \* 1 \* 1, 10) # 最后是全连接层
def forward(self, x): # 定义整个向前传播
x = F.relu(self.conv1(x)) # 先经过第一层卷积
x = self.blk1(x) # 然后通过4次resnet网络结构
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1) # 平铺一维值
x = self.outlayer(x) # 全连接层
return x
6.定义优化器
model = ResNet18().to(DEVICE)#创建模型并将模型加载到指定设备上
optimizer = optim.Adam(model.parameters(),lr=0.001)#优化函数
criterion = nn.CrossEntropyLoss()
7.训练
def train_model(model,device,train_loader,optimizer,epoch):
# Training settings
parser = argparse.ArgumentParser(description=‘PyTorch MNIST Example’)
parser.add_argument(‘–batch-size’, type=int, default=64, metavar=‘N’,
help=‘input batch size for training (default: 64)’)
parser.add_argument(‘–test-batch-size’, type=int, default=1000, metavar=‘N’,
help=‘input batch size for testing (default: 1000)’)
parser.add_argument(‘–epochs’, type=int, default=14, metavar=‘N’,
help=‘number of epochs to train (default: 14)’)
parser.add_argument(‘–lr’, type=float, default=1.0, metavar=‘LR’,
help=‘learning rate (default: 1.0)’)
parser.add_argument(‘–gamma’, type=float, default=0.7, metavar=‘M’,
help=‘Learning rate step gamma (default: 0.7)’)
parser.add_argument(‘–no-cuda’, action=‘store_true’, default=False,
help=‘disables CUDA training’)
parser.add_argument(‘–dry-run’, action=‘store_true’, default=False,
help=‘quickly check a single pass’)
parser.add_argument(‘–seed’, type=int, default=1, metavar=‘S’,
help=‘random seed (default: 1)’)
parser.add_argument(‘–log-interval’, type=int, default=10, metavar=‘N’,
help=‘how many batches to wait before logging training status’)
parser.add_argument(‘–save-model’, action=‘store_true’, default=False,
help=‘For Saving the current Model’)
args = parser.parse_args()
model.train()#模型训练
for batch_index,(data ,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)#部署到DEVICE上去
optimizer.zero_grad()#梯度初始化为0
output = model(data)#训练后的结果
loss = criterion(output,target)#多分类计算损失
loss.backward()#反向传播 得到参数的梯度值
optimizer.step()#参数优化
if batch_index % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_index \* len(data), len(train_loader.dataset),
100. \* batch_index / len(train_loader), loss.item()))
if args.dry_run:
break
8.测试
def test_model(model,device,text_loader):
model.eval()#模型验证
correct = 0.0#正确率
global Accuracy
text_loss = 0.0
with torch.no_grad():#不会计算梯度,也不会进行反向传播
for data,target in text_loader:
data,target = data.to(device),target.to(device)#部署到device上
output = model(data)#处理后的结果
text_loss += criterion(output,target).item()#计算测试损失
pred = output.argmax(dim=1)#找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()#累计正确的值
text_loss /= len(test_loader.dataset)#损失和/加载的数据集的总数
Accuracy = 100.0*correct / len(text_loader.dataset)
print(“Test__Average loss: {:4f},Accuracy: {:.3f}\n”.format(text_loss,Accuracy))
9.调用
for epoch in range(1,EPOCHS+1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)
torch.save(model.state_dict(),‘model.ckpt’)
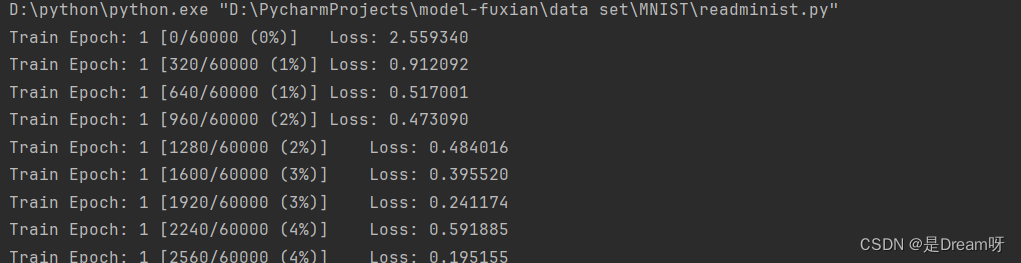
### 精确度
**Test\_\_Average loss: 0.000808,Accuracy: 99.150**
最后可以发现准确度达到了99%还高,可以看出来残差网络识别手写数字的准确性还是很高的。
没有GPU的可以使用CPU,不过速度会大打折扣:`DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")`,最好是可以使用`GPU`,这样速度会快很多: `torch.device("cuda")#使用GPU`
## 文末免费送书:C语言从入门到精通(第6版)
## 写在最后
**在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。**
需要完整版PDF学习资源私我















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









