






魔乐社区新版本来啦!
此次openmind Library新版本带来了多项重要功能的提升和优化,包括集成微调功能、LoRA权重合并、模型部署支持以及MindOne框架下的text2image推理能力等。这些特性将简化模型开发和部署流程,提升您的工作效率和用户体验。同时,站点新增开发者积分中心功能,让您在贡献和创新的同时,享受更多的社区福利。
快来了解并试试新版本,让开发工作更轻松!
openMind Library v1.0.0 新增特性详解
1 集成微调功能
openMind Library v1.0.0基于transformers库,集成了PyTorch框架下主流第三方工具的功能,提供了一键式的模型微调解决方案,涵盖了从数据处理、多站点权重加载,到低参数微调、量化适配以及训练监控的全流程功能。同时,openMind Library还提供了昇腾NPU亲和算子优化等加速手段,显著提升模型训练效率。
openMind Library目前支持的微调特性如下:
-
微调阶段:SFT
-
高效参数微调算法:Full、LoRA、QLoRA
-
加速优化:npu_fusion_attention、npu_rms_norm
-
训练监控:SwanLab
-
分布式训练:单机多卡-DDP、单机多卡-DeepSpeed
-
导出:LoRA权重合并
openMind Library提供命令行接口(command-line interface, CLI),支持用户在shell环境下交互式实现训练流程。用户只需要通过openmind-cli train demo.yaml,就可以动态解析yaml文件里的配置参数,并自动完成训练全流程。
openmind-cli train微调命令通过解析yaml文件的方式拉起微调训练。用户首先需要配置一个包含微调训练参数的yaml文件,然后通过命令行方式运行,openMind Library会自动完成参数解析和微调流程配置运行。以下为一个简单的示例demo.yaml,更多的参数配置请参考openMind Library v1.0.0文档说明中的基础教程
# model
model_id: Qwen2-7B
# method
stage: sft
do_train: true
finetuning_type: full
logging_steps: 1
max_steps: 10
# dataset
dataset: alpaca_zh_51k, alpaca
# train
output_dir: saves/Qwen2-7B/sft/lora/
overwrite_output_dir: true
运行命令为:
openmind-cli train demo.yaml
训练配置包括微调算法参数、模型参数、数据集参数和训练参数。用户可根据实际微调训练需要,参考文档说明中的基础教程进行更详细配置:
2 模型导出优化
同时,针对LoRA微调阶段,新增openmind-cli exportLoRA权重合并功能,支持命令行一键式解析yaml文件合并适配器权重和基座权重。
经过LoRA微调训练后,保存的权重并非完整模型的权重,而是适配器的权重文件。这种权重文件仅包含 LoRA 层相关的参数,因此需要与预训练的基础模型权重一起加载才能使用。
LoRA训练完成后保存的文件通常包括以下内容:
output_dir/
├── adapter_config.json # LoRA 的配置文件
├── adapter_model.safetensors # LoRA 层的权重文件
而完整模型的权重文件通常类似于:
base_model_dir/
├── config.json # 模型的配置文件
├── model.safetensors # 基础模型的权重文件
openMind Library提供了openmind-cli export命令,帮助用户完成LoRA微调后的权重合并。该命令与openmind-cli train命令相似,都是基于对yaml文件得解析完成对应的合并操作。yaml文件的一种典型示例如下:
假设该文件名为merge.yaml,文件须包含如下参数:
-
model_id或者model_name_or_path:基础模型权重。如果训练的时候使用model_id,可复用该参数。如果需要手动加载社区模型仓内容或者加载本地权重,可使用model_name_or_path,请注意二者只能选用其中一个,不可同时出现。 -
adapter_models:微调后保存的适配器权重。 -
output_dir:合并后的权重文件保存路径。
#base model args
model_id: Qwen2-7B
#model_name_or_path: AI_Connect/Qwen2_7B or /home/base_mode/Qwen2_7B
#adapter model args
adapter_models: lora_checkpoint_path
#ouput args
output_dir: ./saves_merge
可通过以下命令完成合并操作:
openmind-cli export merge.yaml
3 模型部署支持
openmind-cli deploy用于在单机环境下部署openai接口服务。目前支持MindIE和LMDeploy两种方式提供推理服务。
注:该接口暂时仅支持PyTorch框架
LMDeploy
- 环境准备
不同于openMind Library v1.0.0版本默认配套的PyTorch 2.1.0,由于该接口所使用的LMDeploy库依赖PyTorch2.3.1版本,即使用该功能需要修改环境中的PyTorch版本。对此,我们建议用户创建新环境进行模型部署,新建环境可参考openMind Library安装指南。
python -c "import torch_npu;print(torch_npu.npu.is_available());"
'''
True
'''
LMDeploy安装命令如下:
git -b v0.6.4 clone https://github.com/InternLM/lmdeploy.git
cd lmdeploy
pip install -e .
- 接口调用示例
从魔乐社区上获取模型AI-Research/Qwen2-7B在默认端口1025上进行部署。
openmind-cli deploy AI-Research/Qwen2-7B --backend lmdeploy
使用本地Qwen2-7B模型在指定端口1025上进行部署。
openmind-cli deploy /path/to/your/Qwen2-7B --backend lmdeploy --port 1025
- 交互示例
部署成功后,可以在同服务器上使用curl进行交互。
查看模型列表v1/models
curl http://127.0.0.1:1025/v1/models
对话v1/chat/completions
curl http://127.0.0.1:1025/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "AI-Research/Qwen2-7B",
"messages": "推荐一个海边度假的地方"
}'
MindIE
- 接口调用示例
从魔乐社区上获取模型MindIE/llama2_7b在默认端口1025上进行部署。
openmind-cli deploy MindIE/llama2_7b --backend mindie
使用本地llama2_7b模型在指定端口1025上进行部署,指定0,1号卡。
openmind-cli deploy /path/to/your/llama2_7b --backend mindie --port 1025 --world_size 2 --npu_device_ids '0,1'
停止MindIE服务
openmind-cli deploy stop
4 MindOne支持text2image推理
MindSpore框架下基于MindOne支持文本生成图像任务,示例代码如下:
from openmind import pipeline
import mindspore
pipe = pipeline(
"text-to-image",
model="AI-Research/stable-diffusion-3-medium-diffusers",
backend="mindone",
framework="ms",
mindspore_dtype=mindspore.float16,
)
image = pipe("masterpiece, best quality, Cute dragon creature, pokemon style, night, moonlight, dim lighting")
image.save("mindone.png")

5 openMind Library 新增支持8.0.RC3.beta1版本HDK基于openmind-cli run执行文生图任务
开发者体验提升
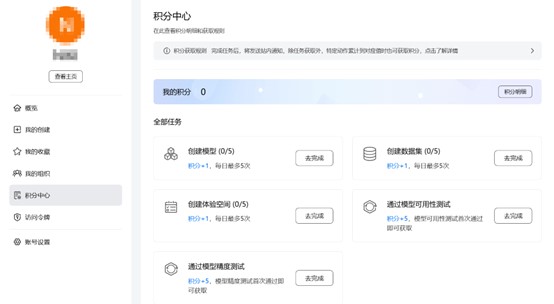
个人主页新增积分中心功能
魔乐社区积分中心上线啦,开发者可以通过贡献模型、数据集、体验空间以及模型测试等多种方式累计积分。后续社区将推出积分兑换礼品、算力资源等福利,敬请期待!
- 积分获取规则可以通过访问“个人中心”>“积分中心”查看。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









