






3月25日,通义千问团队开源了新的VL模型——Qwen2.5-VL-32B-Instruct。这个模型在Qwen2.5-VL系列的基础上,使用强化学习做了优化,在三个方面改进显著:回复更符合人类主观偏好;拥有更强的数学推理能力,复杂数学问题求解的准确性显著提升;在图像解析、内容识别以及视觉逻辑推导等任务中表现出更强的准确性和细粒度分析能力。
昇腾MindIE已适配支持Qwen2.5-VL-32B-Instruct并上架魔乐社区,欢迎广大开发者下载体验!
模型链接:https://modelers.cn/models/Models_Ecosystem/Qwen2.5-VL-32B-Instruct(或点击文末阅读原文直达)
01 模型介绍
与业内先进的同规模模型进行比较,包括近期推出的 Mistral-Small-3.1-24B 和 Gemma-3-27B-IT, Qwen2.5-VL-32B-Instruct 展现出了明显的优势,甚至超越了更大规模的 Qwen2-VL-72B-Instruct 模型。尤其是在多模态任务中,例如 MMMU、MMMU-Pro和MathVista,这些任务强调复杂的多步骤推理,Qwen2.5-VL-32B-Instruct 表现尤为突出。在注重主观用户体验评估的 MM-MT-Bench 基准测试中,该模型相较于其前代 Qwen2-VL-72B-Instruct 取得了显著进步。
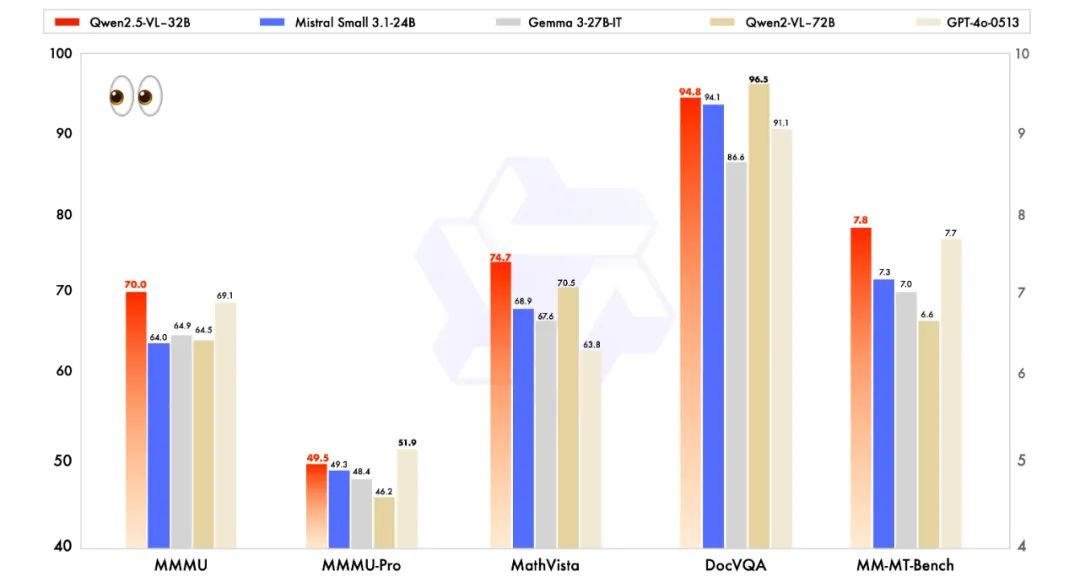
除了在视觉能力上优秀,Qwen2.5-VL-32B-Instruct 在纯文本能力上也达到了同规模的最优表现。
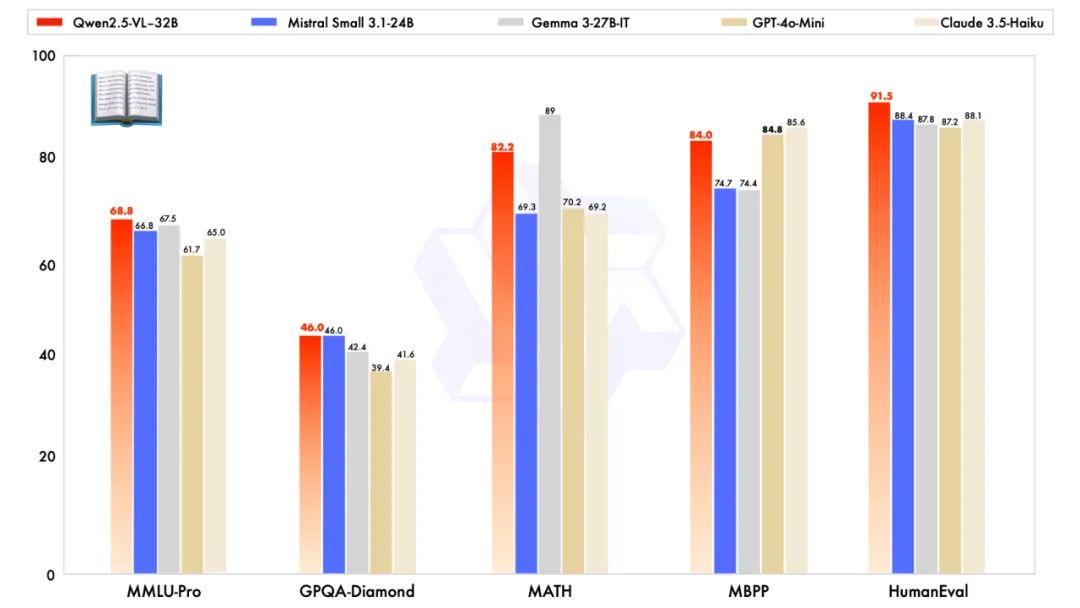
简而言之,这一次的32B版本更轻量更聪明,可在本地部署运行。
02 准备运行环境
2.1 加载镜像
前往 昇腾社区/开发资源 下载适配本模型的镜像包。
-
下载链接:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
-
镜像包名称:1.0.0-800I-A2-py311-openeuler24.03-lts
完成之后,运行下列命令确认查找具体镜像名称与标签。
docker images2.2 硬件要求
部署Qwen2.5-VL-32B-Instruct模型至少需要1台Atlas 800I A2(8*32G)。
2.3 新建容器
自行修改端口等参数,启动样例。
docker run -dit -u root \--name ${容器名} \-e ASCEND_RUNTIME_OPTIONS=NODRV \--privileged=true \-v /home/路径:/home/路径 \-v /data:/data \-v /usr/local/Ascend/driver/:/usr/local/Ascend/driver/ \-v /usr/local/Ascend/firmware/:/usr/local/Ascend/firmware/ \-v /usr/local/sbin/:/usr/local/sbin \-v /etc/ascend_install.info:/etc/ascend_install.info \-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \--shm-size=100g \-p ${映射端口}:22 \--cap-add=SYS_PTRACE \--security-opt seccomp=unconfined \${MindIE 1.0.0 镜像} \/bin/bash
2.4 进入容器
docker exec -it ${容器名} bash03 准备模型
目前提供的MindIE镜像未预置Qwen2.5-VL-32B-Instruct推理脚本,需下载模型仓库内mindie下的atb_llm.zip和models.zip文件。
下载链接:https://modelers.cn/models/Models_Ecosystem/Qwen2.5-VL-32B-Instruct/tree/main/mindie
下载完成后,将其分别解压缩至 /usr/local/Ascend/atb-models/atb_llm和 /usr/local/Ascend/atb-models/examples/models
安装Python依赖
下载模型仓库内mindie/requirements_qwen2_vl.txt并安装依赖:
pip install -r ./requirements_qwen2_vl.txt04 执行推理
4.1 纯模型推理
1. 控制日志输出到控制台:
export MINDIE_LOG_TO_FILE=0;export MINDIE_LOG_TO_STDOUT=1;export MINDIE_LOG_LEVEL=info;
2. 修改脚本/usr/local/Ascend/atb-models/examples/models/qwen2_vl/run_pa.sh
# 设置卡数,800I-A2-32G至少4卡,800I-A2-64G至少2卡export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3...# 模型权重路径model_path="/data/Qwen2.5-VL-32B-Instruct/"# 批次大小,底层使用continuous batching逻辑max_batch_size=1# 最大输入长度,输入长视频或者较大分辨率图片时,需要设置较大的值,以便支持更长的输入序列# kv cache会根据,最大输入长度、最大输出长度以及bs进行预分配,设置太大会影响吞吐max_input_length=8192# 最大输出长度max_output_length=80# 单张图或单个图片input_image="XXX.jpg/png/jpeg/mp4/wmv/avi"# 用户prompt,默认放置在图片后input_text="Explain the details in the image."# dataset_path优先级比input_image高,若要推理整个数据集,base_cmd入参中添加 ```--dataset_path $dataset_path \```dataset_path="/data/test_images"# 共享内存name保存路径,任意位置的一个txt即可shm_name_save_path="./shm_name.txt"
3. 运行脚本
bash /usr/local/Ascend/atb-models/examples/models/qwen2_vl/run_pa.sh4.2 服务化推理
1. 打开配置文件。
vim /usr/local/Ascend/mindie/latest/mindie-service/conf/config.json2. 更改配置文件(可根据实际需求变更参数)。
{..."ServerConfig" :{..."port" : 1040, #自定义"managementPort" : 1041, #自定义"metricsPort" : 1042, #自定义..."httpsEnabled" : false,...},"BackendConfig": {..."npuDeviceIds" : [[0,1,2,3,4,5,6,7]],..."ModelDeployConfig":{"maxSeqLen" : 32768,"maxInputTokenLen" : 32768,"truncation" : false,"ModelConfig" : [{"modelInstanceType": "Standard","modelName" : "qwen2_vl", # 为了方便使用benchmark测试,modelname建议使用qwen2_vl"modelWeightPath" : "/data/Qwen2.5-VL-32B-Instruct","worldSize" : 8,..."npuMemSize" : 8, #kvcache分配,可自行调整,单位是GB,切勿设置为-1,需要给vit预留显存空间...}]},"ScheduleConfig" :{..."maxPrefillTokens" : 32768,"maxIterTimes": 4096,...}}}
3. 设置运行多卡环境变量。
export MASTER_ADDR=localhostexport MASTER_PORT=7896
4. 拉起服务化。
cd /usr/local/Ascend/mindie/latest/mindie-service/bin./mindieservice_daemon
5. 容器内新端口测试 VLLM接口。
curl 127.0.0.1:1025/generate -d '{"prompt": [{"type": "image_url","image_url": ${图片路径}},{"type": "text", "text": "Explain the details in the image."}],"max_tokens": 512,"stream": false,"do_sample":true,"repetition_penalty": 1.00,"temperature": 0.01,"top_p": 0.001,"top_k": 1,"model": "qwen2_vl"}'
若测试视频理解:
curl 127.0.0.1:1025/generate -d '{"prompt": [{"type": "video_url","video_url": "/home/demo.mp4"},{"type": "text", "text": "Explain the details in the image."}],"max_tokens": 512,"stream": false,"do_sample":true,"repetition_penalty": 1.00,"temperature": 0.01,"top_p": 0.001,"top_k": 1,"model": "qwen2_vl"}'
6. 容器内新端口测试 OpenAI 接口。
curl 127.0.0.1:1025/v1/chat/completions -d ' {"model": "internvl","messages": [{"role": "user","content": [{"type": "image_url", "image_url": ${图片路径}},{"type": "text", "text": "Explain the details in the image."}]}],"max_tokens": 512,"do_sample": true,"repetition_penalty": 1.00,"temperature": 0.01,"top_p": 0.001,"top_k": 1}'
欢迎体验
欢迎大家下载体验昇腾MindIE版Qwen2.5-VL-32B-Instruct,也欢迎广大开发者在模型评论区留言交流!

















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









