






一 概述
Qwen系列模型是由阿里巴巴开发的开源大语言模型,其被广泛用于自然语言处理的多种任务,包括文本生成、翻译、摘要生成等。本文的目标是使用 openMind 工具套件及 LLaMA-Factory 开源微调框架,在昇腾 NPU 上跑通 Qwen1.5-7B 模型的微调和推理全流程。
二 环境准备
1 安装 Ascend CANN Toolkit 和 Kernels
请参考安装教程或使用以下命令快速安装。
# 请替换URL为CANN版本和设备型号对应的URL
# 安装CANN Toolkit
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run
bash Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run --install
# 安装CANN Kernels
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run
bash Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run --install
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh2 安装 openMind Library 和 openMind Hub Client
- 安装openMind Hub Client
pip install openmind_hub- 安装openMind Library,并安装PyTorch框架及其依赖。
pip install openmind[pt]更详细的安装信息请参考openMind官方的环境安装章节。
3 安装 LLaMA-Factory
使用以下指令快速安装:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch-npu,metrics]"三 模型及配置文件准备
1 模型下载
参考魔乐社区官方指引,或使用以下脚本从魔乐社区下载 Qwen1.5-7B 模型:
from openmind_hub import snapshot_download
model_path = snapshot_download("PyTorch-NPU/qwen1.5_7b", revision="main", resume_download=True)2 配置文件准备
本文所用配置文件qwen1_5_lora_sft_ds.yaml内容如下:
### model
### 编辑此变量为存储该模型的路径
model_name_or_path: <your/path/to/PyTorch-NPU/qwen1.5_7b>
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: q_proj,v_proj
### ddp
ddp_timeout: 180000000
deepspeed: examples/deepspeed/ds_z0_config.json
### dataset
dataset: identity,alpaca_en_demo
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/Qwen1.5-7B/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 0.0001
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
### eval
val_size: 0.1
per_device_eval_batch_size: 1
evaluation_strategy: steps
eval_steps: 500四 原始模型直接推理
验证 LLaMA-Factory 在昇腾 NPU 上推理功能是否正常:
ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli webchat --model_name_or_path <your/path/to/PyTorch-NPU/qwen1.5_7b> \
--adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
--template qwen \
--finetuning_type lora注:ASCEND_RT_VISIBLE_DEVICES 为指定 NPU 卡的环境变量,可根据已有环境修改
如下图所示可正常进行对话,即为可正常推理:
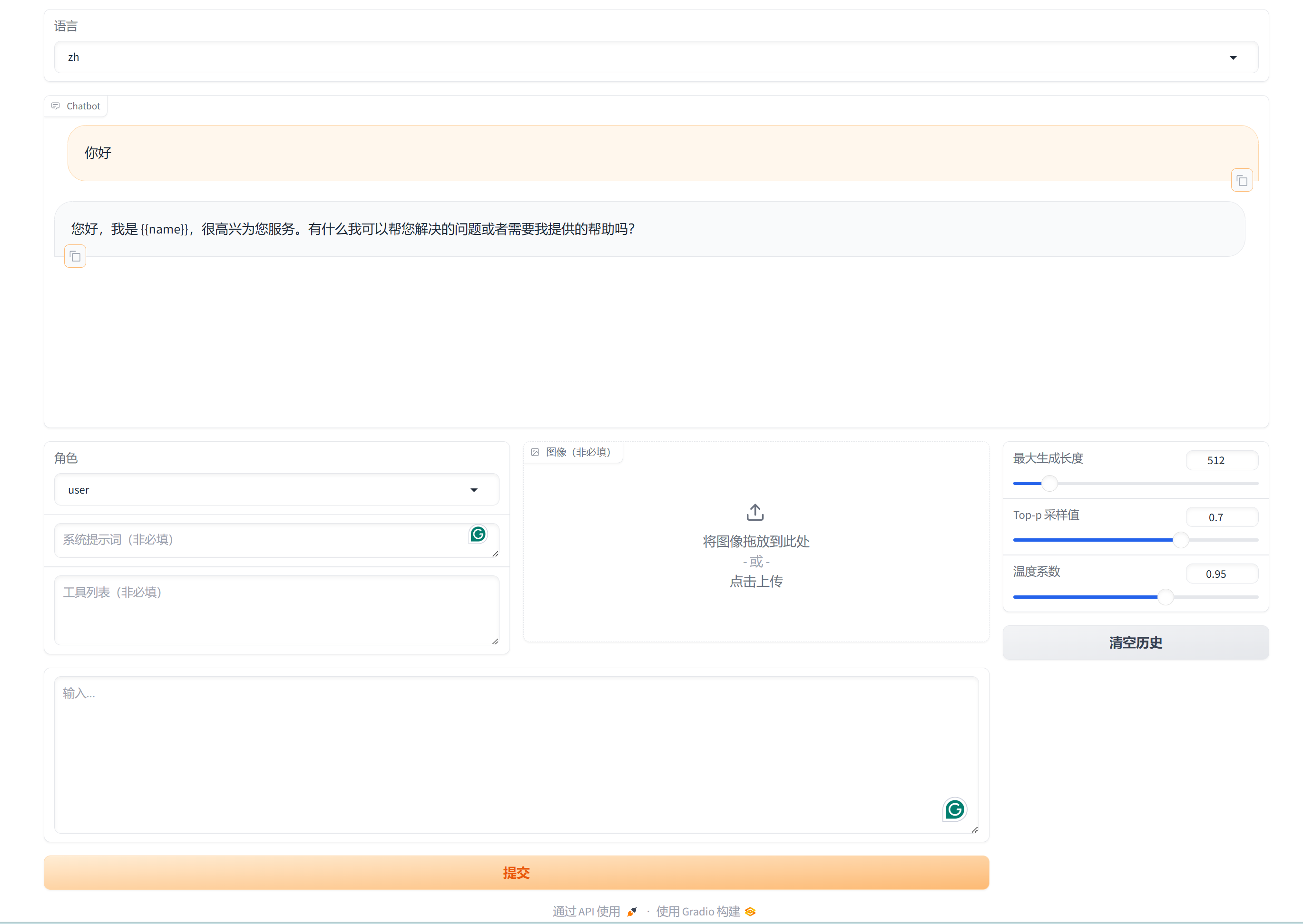
五 自定义数据集构建
本文用到的数据集为 LLaMA-Factory 自带的 identity 和 alpaca_en_demo,对 identity 数据集进行如下全局替换即可实现定制指令:
-
{{name}} 替换为Ascend-helper -
{{author}} 替换为Ascend
更多自定义数据集的构建请参考官方数据集构造指引 。
六 微调与推理
基于 LoRA 的 sft 指令微调
使用以下指令启动 Qwen1.5-7B 模型微调:
ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli train <your_path>/qwen1_5_lora_sft_ds.yaml动态合并 LoRA 的推理
使用以下指令实现动态合并 LoRA 的 Qwen1.5-7B 模型推理:
ASCEND_RT_VISIBLE_DEVICES=0 llamafactory-cli chat --model_name_or_path <your/path/to/PyTorch-NPU/qwen1.5_7b> \
--adapter_name_or_path saves/Qwen1.5-7B/lora/sft \
--template qwen \
--finetuning_type lora通过询问大模型是谁检验 sft 指令微调的成果,如下图,大模型回答自己是 Ascend-helper 说明 sft 成功,如失败,可返回微调阶段增加训练轮数重新训练。
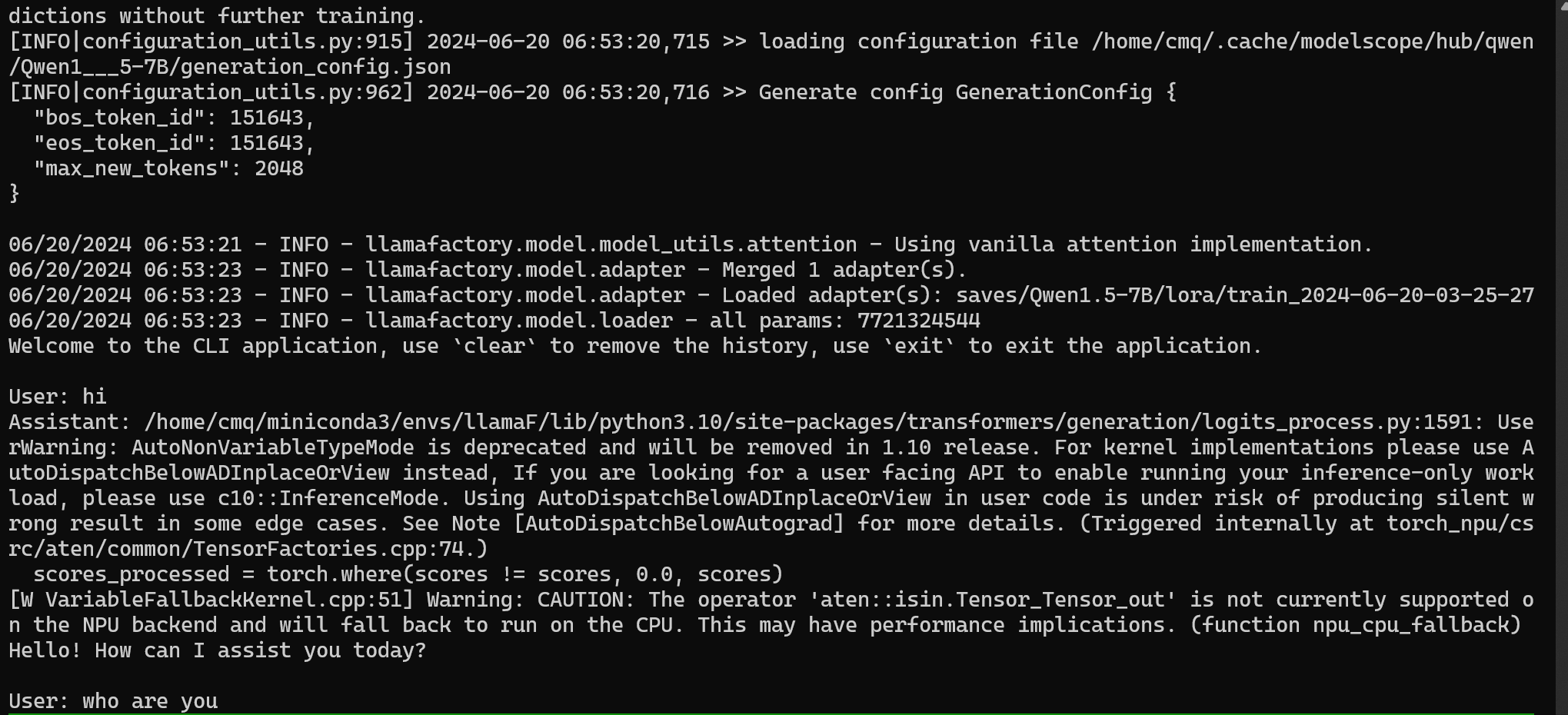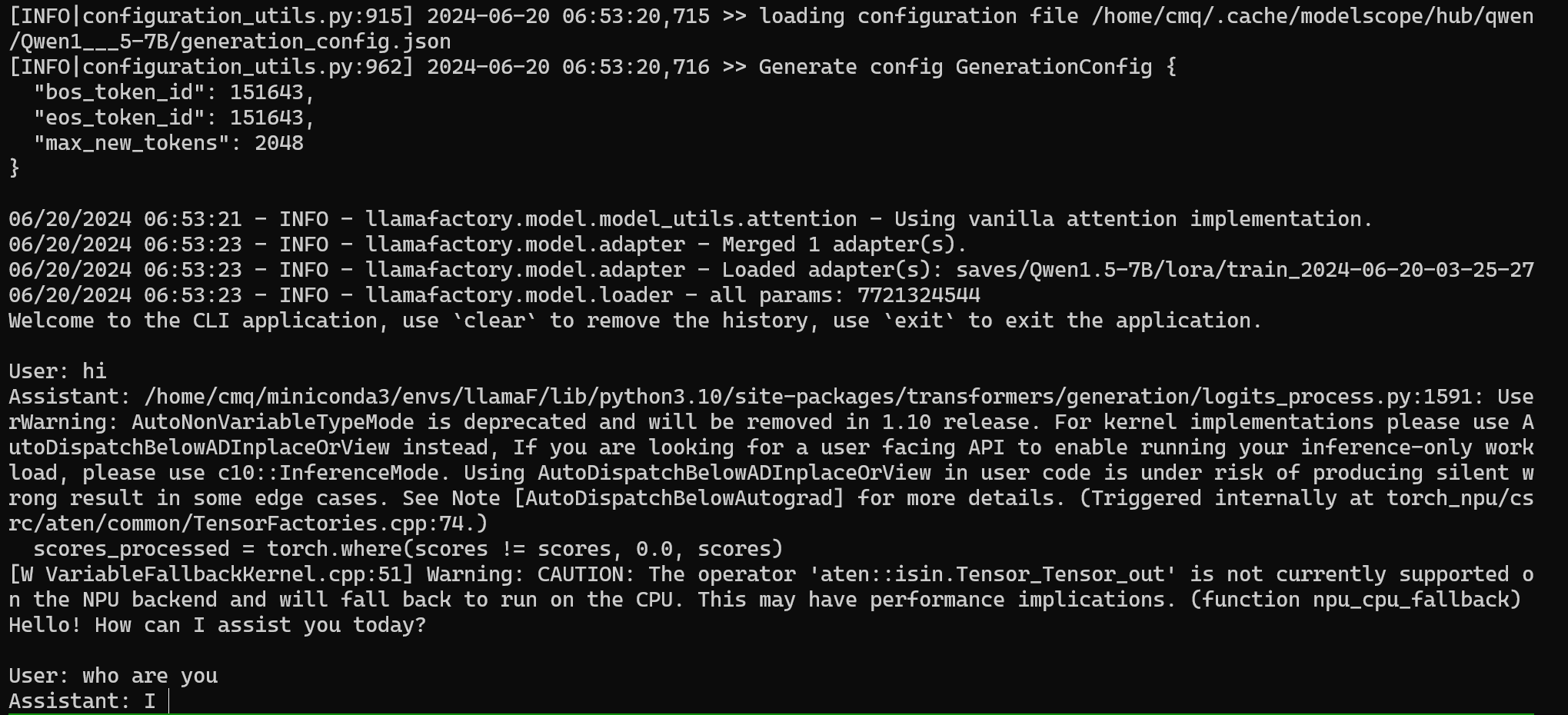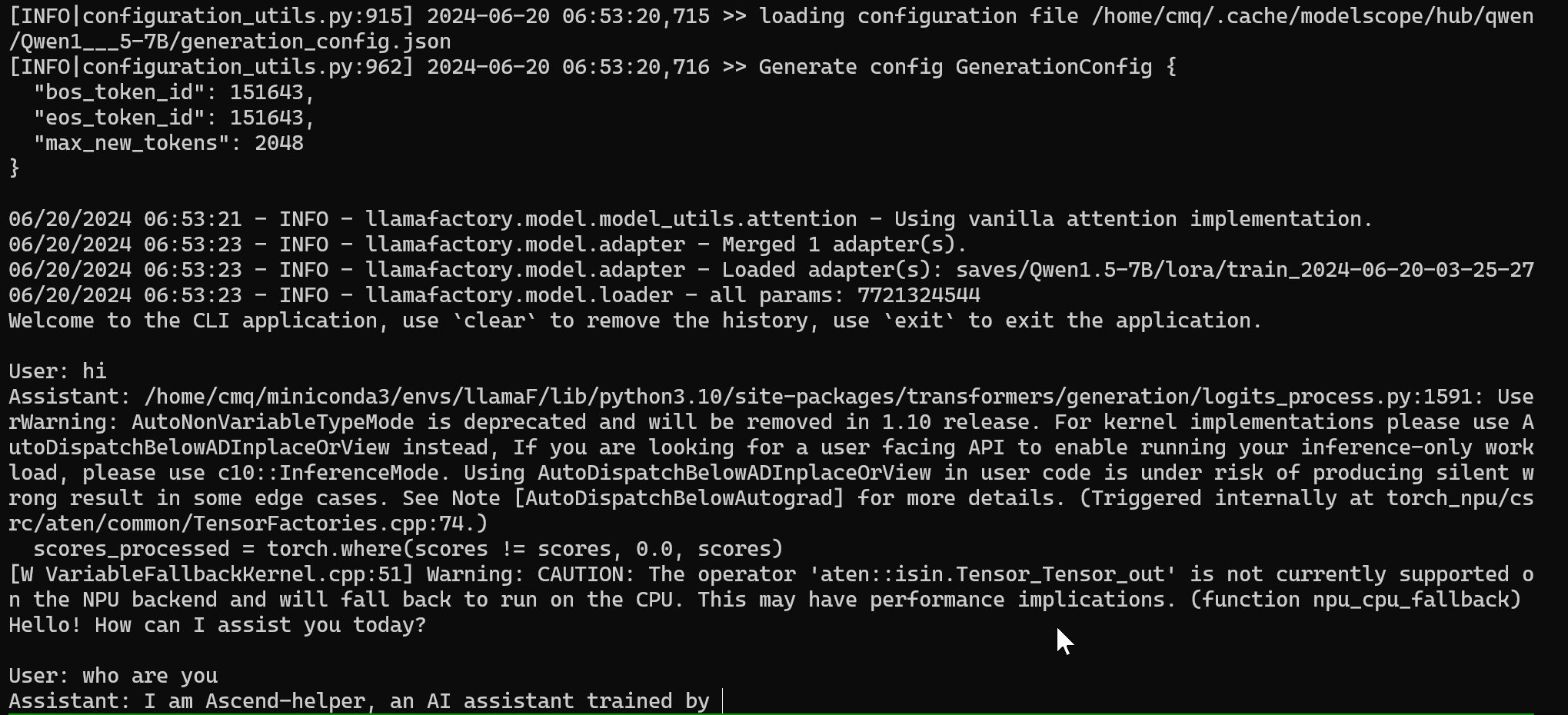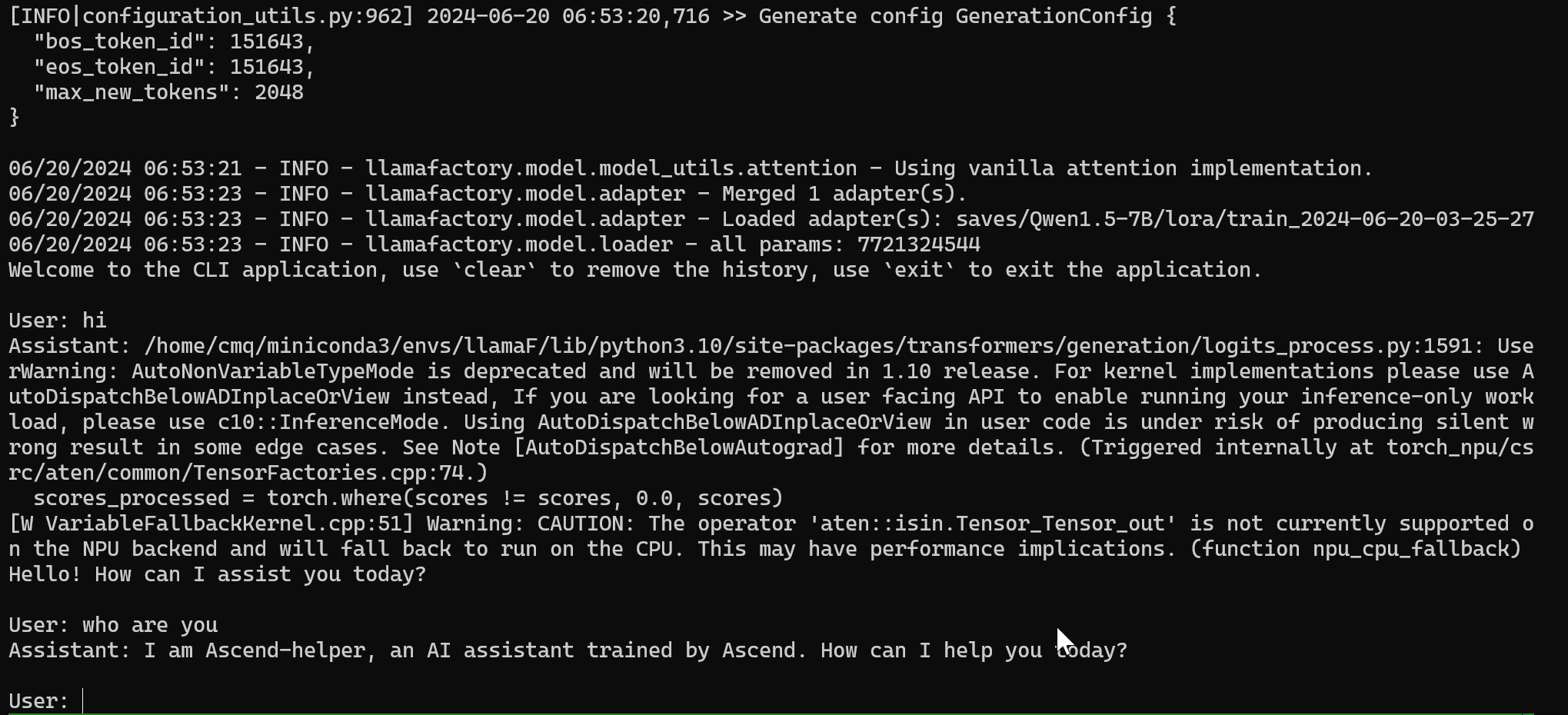
七 总结
应用使能套件 openMind 为广大大模型开发者提供了高效简洁的工具,魔乐则托管了大量各领域主流模型及以 CPU 和昇腾 NPU 为基础算力的 space app,同时,越来越多的开源三方软件开始原生支持昇腾 NPU,广大开发者可以在魔乐社区体验更多强大的 AI 大模型及有趣的 app,欢迎一起探索!
相关链接
- openMind Library介绍:https://modelers.cn/docs/zh/openmind-library/overview.html
- openMind Hub Client介绍:https://modelers.cn/docs/zh/openmind-hub-client/overview.html
- 更多如模型导出、webui使用、模型评测等进阶功能可参阅原生支持文档:https://ascend.github.io/docs/sources/llamafactory/example.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









