







1 简介
DeepSeek 是由 深度求索 团队开发的大语言模型,本实验将基于 deepseek-llm-7b-chat 模型,在 EmoLLM 数据集进行微调,实现大模型能够以心理医生的口吻来回答我们的问题。
本实验基于 transformers 和 openMind 均已实现本次微调,代码均可在 github 链接上查看。
通过本次实验,你不仅能够完成多轮对话数据的微调,还能掌握这些方法,并将其迁移到其他微调实验中,独立进行高效的模型调优。
2 链接资料
作者信息:情感机器研究员 - 李馨雨
数据集: https://github.com/SmartFlowAI/EmoLLM/blob/main/datasets/data_pro.json
模型:https://modelers.cn/models/chenshaohon/deepseek-llm-7b-chat
代码地址:https://github.com/828Tina/deepseek-llm-7B-chat-lora-ft
可视化工具 SwanLab 项目地址:https://swanlab.cn/@LiXinYu/deepseek-llm-7b-chat-finetune/overview
魔乐社区:https://modelers.cn/
3 实际项目代码 + 结果演示
写在前面 本次实验同时适配 transformers 和 openMind,由于 openMind 缺少数据处理的函数,下面实验手动添加即可,其他部分和基于 transformers 的代码一致。
3.1 基本概念
- openMind Library--->Huggingface Transformers
openMind Library 类似于 transformers 的大模型封装工具,其中就有 AutoModelForSequenceClassification、AutoModelForCausalLM 等等模型加载工具以及像 TrainingArguments 参数配置工具等等,原理基本一样,不过对 NPU 适配更友好些。
openMind Library 是一个深度学习开发套件,通过简单易用的 API 支持模型预训练、微调、推理等流程。openMind Library 通过一套接口兼容 PyTorch 和 MindSpore 等主流框架,同时原生支持昇腾 NPU 处理器,同时 openMind Library 可以和 PEFT、DeepSpeed 等三方库配合使用,来加速模型微调效率。
- 魔乐社区 --->HuggingFace

魔乐社区类似于 huggingface 这种模型托管社区,里面除了 torch 的模型还有使用 MindSpore 实现的模型。transformers 可以直接从 huggingface 获取模型或者数据集,openMind 也是一样的,可以从魔乐社区获取模型和数据集。
3.2 实验环境搭建及实验代码、结果
3.2.1 环境设置
在运行代码前,需要先配置环境,由于本次实验对比各个参数结果比较多,所以对显存要求稍微高点,具体环境配置如下:
- GPU:40GB 左右
- Python:>=3.8
-
# 安装torch conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia ----------------------------------------------------------------------------------------------------------------------- # 安装transfomers框架 pip intsall transfomers -i https://pypi.tuna.tsinghua.edu.cn/simple ----------------------------------------------------------------------------------------------------------------------- # 安装openMind框架 pip intsall openmind -i https://pypi.tuna.tsinghua.edu.cn/simple ----------------------------------------------------------------------------------------------------------------------- # 安装datasets pip intsall datasets -i https://pypi.tuna.tsinghua.edu.cn/simple ----------------------------------------------------------------------------------------------------------------------- # 安装peft pip intsall peft -i https://pypi.tuna.tsinghua.edu.cn/simple ----------------------------------------------------------------------------------------------------------------------- # qlora会使用到,本文主要完成lora pip intsall bitsandbytes -i https://pypi.tuna.tsinghua.edu.cn/simple ----------------------------------------------------------------------------------------------------------------------- # 可视化工具 pip intsall -U swanlab -i https://pypi.tuna.tsinghua.edu.cn/simple3.2.2 数据预处理
本次微调目的是使得大模型能够以医生的口吻来回答我们的问题,因此需要与心理健康有关的数据集资料。
下载数据
本项目使用一个 EmoLLM - 心理健康大模型中使用的数据集(该数据集已经进行数据清洗,在保证质量的同时,通过调整阈值减少因错误匹配而丢失重要数据的风险。):
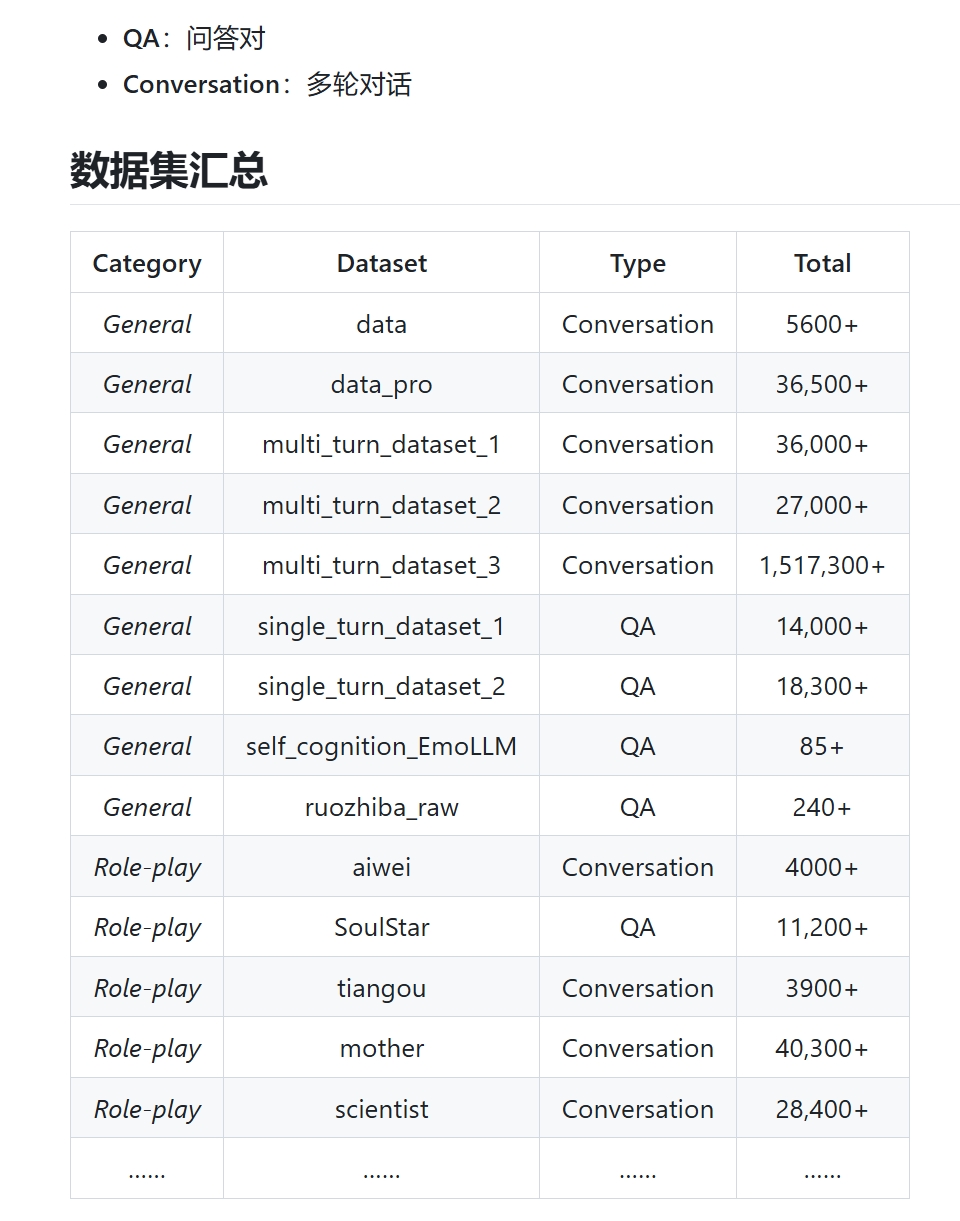
数据集内容如下:
[ { "conversation": [ { "system": "现在你是一个心理专家,我有一些心理问题,请你用专业的知识帮我解决。", "input": "医生,我最近在社交场合总是感到非常紧张和焦虑,尤其是当有很多人的时候,我甚至会出汗、心跳加速。\n\n", "output": "我理解你的感受,社交焦虑是很常见的。首先,我想告诉你,你并不孤单。请问你能告诉我,在哪些具体的社交场景中,你感到最不舒服或焦虑呢?\n\n" }, { "input": "主要是参加聚会或者需要公开发言的场合。我总是担心自己会说错话,或者别人会对我有不好的评价。\n\n", "output": "明白了。在这种情况下,我们首先要认识到,每个人都有可能说错话或遇到尴尬的情况,这是正常的。我建议你可以尝试一些放松技巧,比如深呼吸、正念冥想,或者在参加社交活动前进行一些轻松的身体活动,以减轻紧张感。\n\n" },
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









