






综述文章论文1:A Survey on Deep Geometry Learning: From a Representation Perspective
一、研究背景:在深度学习处理二维图像取得了巨大成功,三维计算机视觉和几何深度学习收到越来越多的关注。3D形状的表示方式,基于体素的表示、基于点的表示、基于网路的表示、隐式表面表示等。
二、研究内容:从表征的角度回顾了3D几何深度学习的最新进展,总结了不同表征在不同应用中的优缺点,进一步讨论未来研究方向。早期三维图形常采用全局建模,如构造立体几何和变形超二次曲面。但是应用于识别和检索等任务时存在一些缺点。高维会加重计算负担,容易造成模型过拟合。
三、Keywords :3D representation, geometry learning,neural networks, computer graphics.
四、基本组成部分:匹配、识别和操作。
五、研究存在的困难:一些神经网络的架构已经被证明在二维图像领域很有用[48,50],可以很容易地扩展到体素形式。然而,增加一个维度意味着数据大小呈指数级增长。随着分辨率的增加,所需的内存和计算成本急剧增加,这限制了在表示3D形状时只能以低分辨率表示。
六、内容主体:体素,是2D像素概念的3D扩展。与点云和体素相比,网格可以用更少的内存和计算成本来描绘更高质量的3D形状。与点云和体素相比,网格可以用更少的内存和计算成本来描绘更高质量的3D形状。介绍多种用于三维重构的网络结构。
隐式曲面表示利用隐式场函数,如占位函数[67]和符号距离函数[116]来描述三维形状的表面。
卷积递归神经网络:单个卷积层分别处理RGB和深度图像,并通过递归网络合并特征。
Multi-View卷积神经网络:通过对CNN的第一部分对不同视图下的图像进行分别处理,然后通过视图池层对不同视图下提取的特征进行聚合,最后将合并的特征放到CNN的剩余部分。
VoNet:定义了输入层、卷积层、池化层和完全连接层。易于实现和训练,增强输入数据,在训练阶段将每个图片旋转成n个不同方向的实例,并在输出层后添加池化操作,对测试阶段n个实例的所有预测进行分组。
自动编码模型:在没有对象标记进行训练的情况下,选择均方损失或交叉损失作为重建损失函数。
TL-embedding Network:该网络结合了用于生成基于体素的表示的自编码器和用于2D嵌入的卷积神经网络。
3D-R2N2:以单张或多张图像作为输入,重构占用网格中的物体。将输入图像作为一个序列,设计了基于LSTM或GRU的三维递归神经网络。架构由:图像编码器(从2D图像中进行特征提取),3D-lstm(用于预测隐藏状态),解码器(提高图像分辨率并生成目标形状)。
3D-GAN:将生成对抗网络应用于体素数据,三维GAN学习从概率分布为P(z)的采样潜在空间向量z合成三维物体。
3D-VAE-GAN:将编码器放在3D-GAN之前,用于从输入的2D图像推断潜在向量z,并与3D-GAN的生成器共享解码。
ORION:优化网络结构思路的提出:为了提高CNN的性能。一种方法引入了一个额外的任务,即使用子体积空间预测类标签防止过拟合。另一种方法利用延长核将3D信息压缩到2D字段中,以便直接使用2D cnn。两者都使用mlpconv层来取代传统的卷积层。
FPNN:八叉树编码体素网络,降低输入数据的维数。层次表面预测(HSP)从粗到细生成八叉树形式的体素网络。
transformer原理回顾
一、解决的问题:从小模块到整体
二、注意力机制:放大重点,弱化背景
三、权重关系的计算:
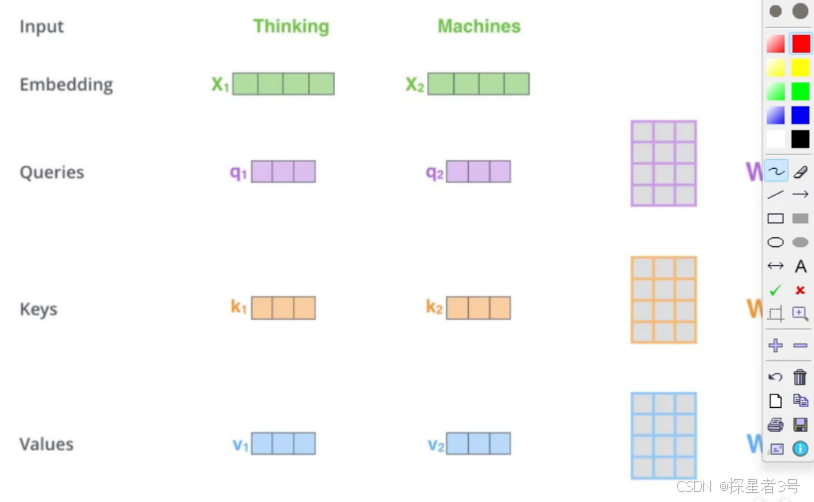
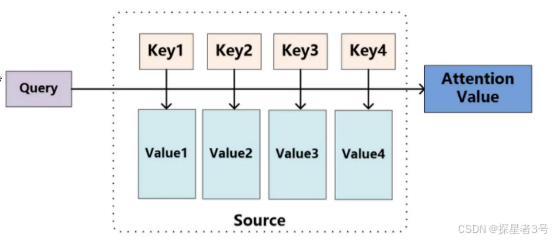
Queries向量:要去查询的,由谁出发,应用内积判断关系好坏(例如,垂直向量的内积为0,相关性为0)。
Keys向量:等着被查的,谁被问到。
Values向量:实际的特征信息,表示本身特征,把权重加权到哪里。
例如计算x1和x2的关系,q1*k2
如何得到 Q、K、V?
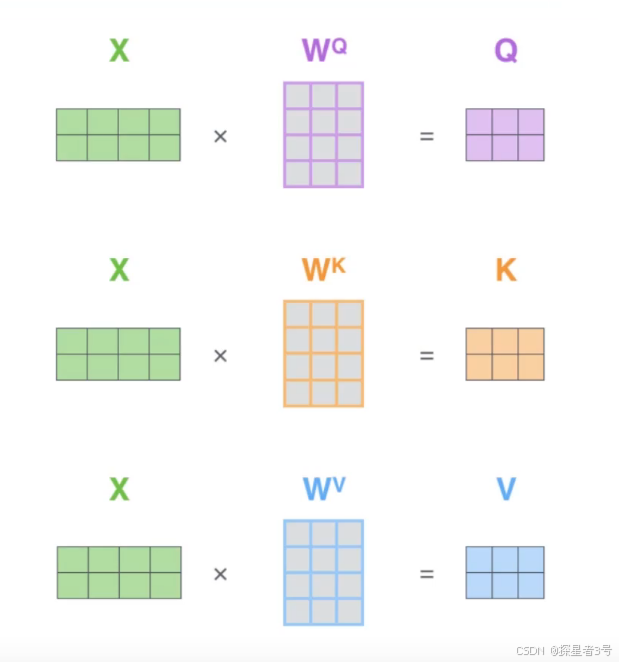
Q、K、V最开始是随机初始化的,通过同一组输入,分别乘以三个不同权重参数矩阵,训练最终得到Q、K、V最优解。
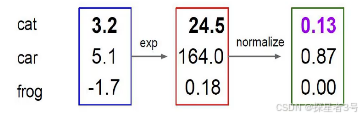
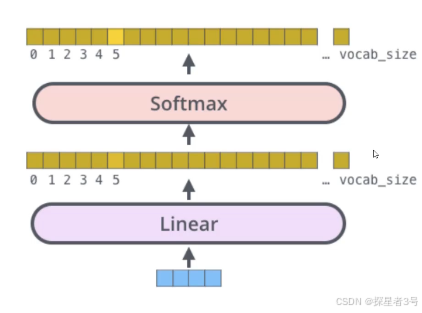
四、softmax:将分值转化为概率(当前词对于待编码词的影响程度)
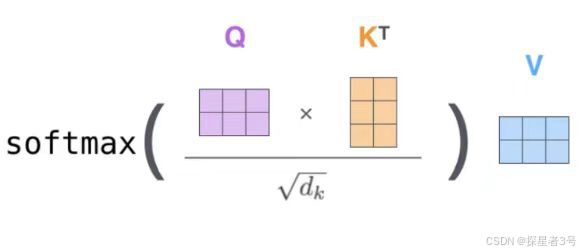
Q与K做内积,再用softmax计算得到概率值,再乘以自己的V,得到词与当前所有词序列全部的特征。

五、Multi-headed多头注意力机制:特征没有对错之分,特征叠加与集成,丰富特征。通过不同的head得到多个特征表达,一般做八个,然后再用全连接层降维。
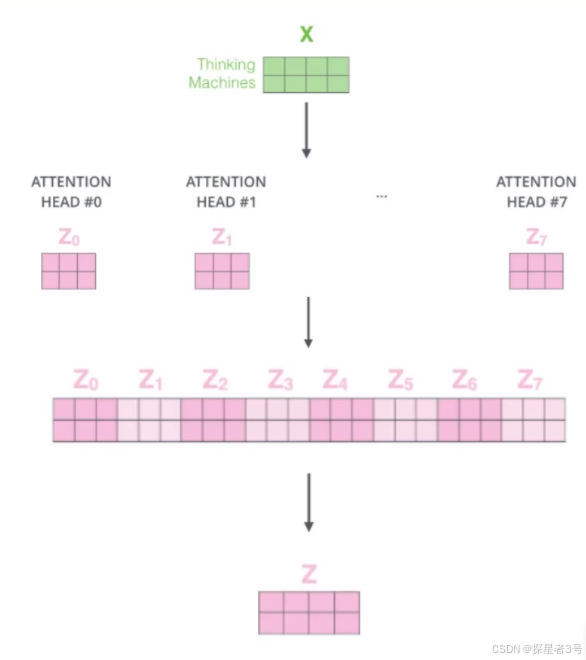
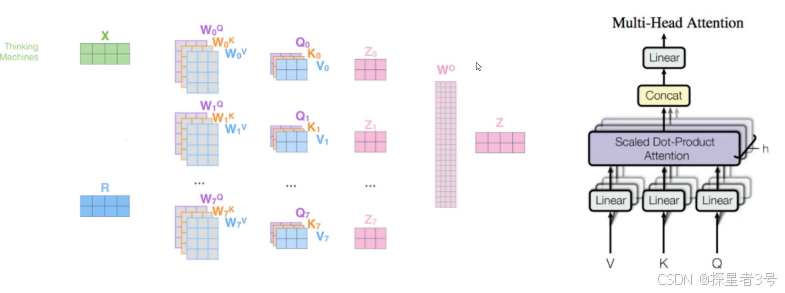
堆叠多层,每次做法相同。
位置信息编码:考虑位置关系,常见做法是加上周期信号,例如正、余弦函数。
视觉中的Attention:将图像按顺序展开
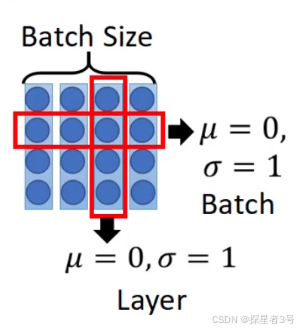
六、Layer:归一化,模型稳定
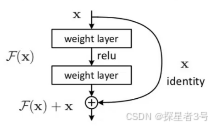
七、基本残差连接方式:同等映射,体现两条路径,在层数堆叠的过程中,保证最终的损失值最小。
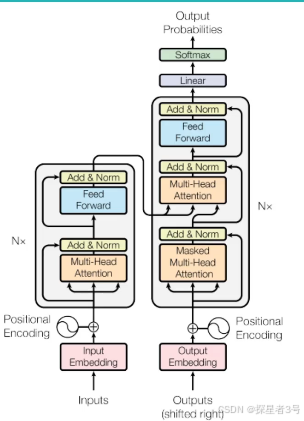
八、整体结构:

Decoder:
BERT的Attention计算不同,加入了MASK机制
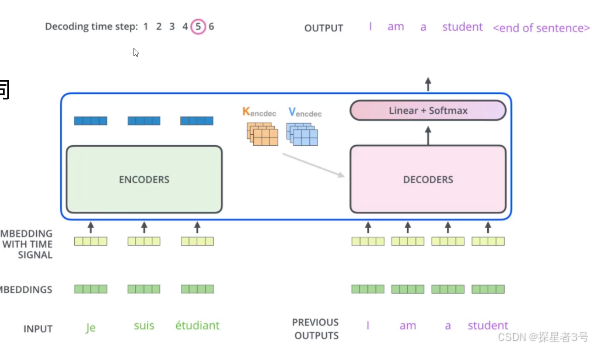
最终输出结果:
九、BERT(Bidirectional Enocoder Representations from Transformers):BERT是基于Transformer的预训练语言模型,自然语言处理通用解决方案。
传统的word2verc表示向量的问题?
同一个词在不同的语境中的向量表示相同。静态词向量,语义理解不准确。
Seq2Seq网络,输入序列,输出序列。
传统RNN网络计算的问题?
无法做并行计算。
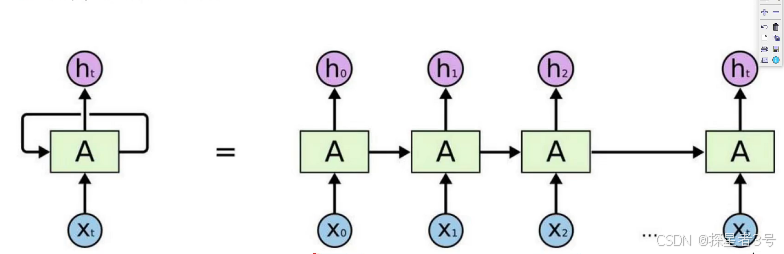
Self-Attetion机制来并行计算,在输入和输出都相同。
输出结果是同时被计算出来的,基本上已经取代RNN。
训练BERT的方法:
方法1:选择15%的词汇被随机mask掉。交给模型预测,
方法2:预测两个句子之间是否应该连接在一起。
论文2:Per-Pixel Classification is Not All You Need for Semantic Segmentation
一、论文的核心思想:通常将将分割任务当作逐像素点分类,语义分割制定为per-pixel classification任务,而实例分割则使用mask classification来处理。而mask分类任务能够做语义和实例分割,MaskFormer的mask分类任务:关注点的放大,从一个点变成一个区域。在类别比较多的情况下,MaskFormer的效果比逐像素点分割的效果要好,有监督,可以做全局和语义分割。
二、MaskFormer包含三个模块:
(1)像素级模块:用于提取图像特征的backbone和用于生成per-pixel嵌入的像素级解码器。基于 FPN 架构的轻量级像素解码器。 在 FPN 之后,对解码器中的低分辨率特征图进行 上采样,并将其与来自主干的相应分辨率的投影特征图(投影是为了与特征图维度匹配,通过1×1 卷积层+GroupNorm实现)相加。 然后通过一个额外的 3×3 卷积层+GN+ReLU将串联特征融合。 重复这个过程,直到获得最终特征图。最后,应用单个 1×1 卷积层来获得peri-pixel嵌入。
(2)Transformer模块:使用堆叠的Transformer解码器层计算N个per-segment嵌入。6 个 Transformer 解码器层和 100 个查询,并且在每个解码器之后应用 DETR 相同的损失。
(3)分割模块:从上述两个embeddings生成预测结果的概率-掩码对。
论文3:Masked-attention Mask Transformer for Universal Image Segmentation --2022年
一、论文核心思想:通用图像分割,Masked-attention Mask Transformer (Mask2Former)处理任何图像分割任务(全景、实例或语义)的新架构。
二、关键组成部分:masked attention
三、传统图像分割:研究的是像素分类问题,不同的语义分组像素导致不同类型的分割任务,如全景、实例或语义分割。基于全卷积网络(FCNs)的逐像素分类架构用于语义分割,而掩码分类架构[5,24]预测一组与单个类别相关的二进制掩码,主导实例级分割。尽管这种专门的架构[6,10,24,37]已经推进了每个单独的任务,,缺乏推广到其他任务的灵活性,例如,基于FCN的体系结构在实例分割方面存在困难,导致实例分割与语义分割的不同体系结构的演变。
四、Mask2Former:首次在多个数据集上的三个研究分割任务上优于最佳的专业架构。
通用体系架构没有取代专门化架构?
通用体系架构的缺点:
1.性能差,尽管现有的通用体系结构足够灵活,可以处理任何分段任务,但是在实践中,性能要低于最佳的专用体系结构。
2.训练困难,例如,训练MaskFormer需要300次epoch才能达到40.1 AP,并且它只能在具有32G内存的GPU中容纳单个图像。
相比之下,专用的swwin - htc仅在72个epoch中获得更好的性能。
五、Mask2Former中的改进点:在Mask2Former的基础上,在Transformer解码器中使用屏蔽注意力,与标准Transformer解码器中使用的交叉注意(关注图像中的所有位置)相比,屏蔽注意可以更快地收敛并提高性能;多尺度高分辨率特征,帮助模型分割小物体/区域;提出了切换自关注和交叉关注的顺序、使查询特征可学习、去除dropout等优化改进。少量随机采样点计算掩码损失,节省了3倍的训练内存。这些改进不仅提高了模型的性能,而且大大简化了训练,使通用架构更容易被计算能力有限的用户使用。
六、性能评估:使用四种流行的数据集(COCO[35]、cityscape[35]、ADE20K[65]和Mapillary远景)来评估Mask2Former在三种图像分割任务(全景、实例和语义分割)上的性能。

















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









