






-
梯度下降的基本概念:
-
梯度下降是一种优化算法,用于最小化成本函数 J(w,b)。在每一步中,通过计算成本函数相对于参数 w 和 b 的梯度,并沿着梯度的反方向更新参数,来逐步接近成本函数的最小值。
-
-
Adam算法的引入:
-
Adam算法是一种改进的梯度下降算法,它能够自适应地调整每个参数的学习率。这意味着不同的参数可以有不同的学习率,而不是使用一个全局的学习率。
-
如果一个参数(如 wj 或 b)持续朝相同方向移动,Adam算法会增加该参数的学习率,以便更快地接近最小值。
-
如果一个参数持续振荡,Adam算法会减少该参数的学习率,以避免过大的步长导致不稳定。
-
-
Adam算法的实现:
-
在实际应用中,可以通过指定优化器为Adam,并设置一个初始学习率来实现Adam算法。Adam算法会根据参数的移动情况自动调整学习率,从而提高训练效率和稳定性。
-


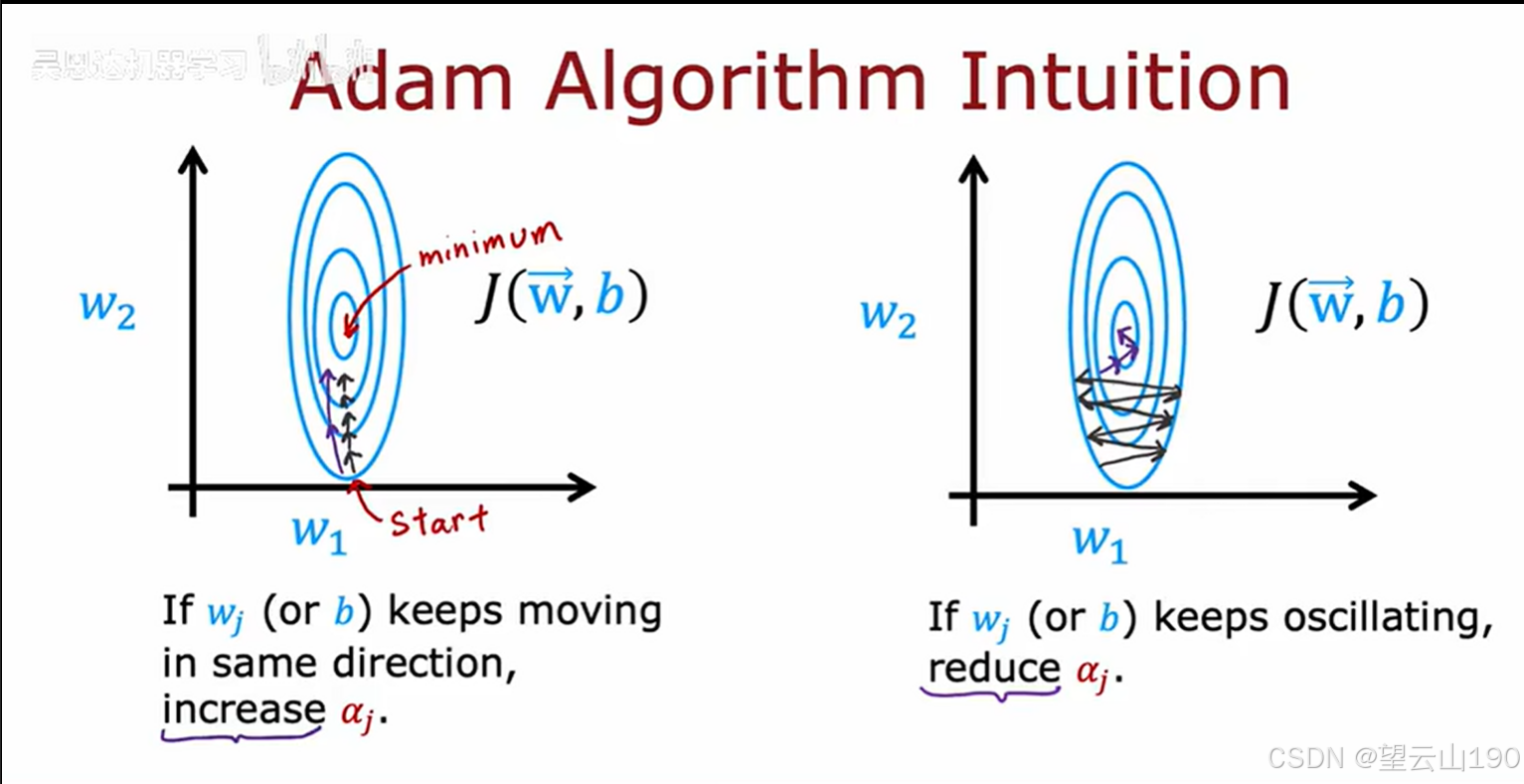

总结
这两张图片共同展示了Adam算法的核心思想:
-
自适应学习率:Adam算法为每个参数自适应地调整学习率,以便更快、更稳定地更新参数。
-
根据梯度方向调整学习率:如果参数持续朝相同方向移动,增加学习率;如果参数持续振荡,减少学习率。
通过这种方式,Adam算法能够在不同的参数更新路径上灵活调整学习率,从而提高训练效率和稳定性。

图片展示了使用TensorFlow和Keras库构建和编译一个简单的神经网络模型的代码,该模型使用Adam优化器进行训练。
-
模型构建(model):
-
使用
Sequential模型,依次添加三层全连接层(Dense)。 -
第一层和第二层各有25和15个神经元,使用
sigmoid激活函数。 -
第三层有10个神经元,使用
linear激活函数,对应MNIST数据集的10个类别。
-
-
模型编译(compile):
-
使用
model.compile方法编译模型。 -
指定优化器为
tf.keras.optimizers.Adam,其中learning_rate=1e-3(即0.001)。 -
指定损失函数为
tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),适用于多分类问题。
-
-
模型训练(fit):
-
使用
model.fit方法训练模型,输入数据为X和Y,训练100个周期(epochs)。
-
对上面照片进一步解释说明;
-
模型构建:
-
模型的结构与之前相同,但添加了Adam优化器作为编译函数的一个参数。
-
Adam优化器需要设置一个初始学习率,这里设置为
1e-3(即0.001)。
-
-
Adam优化器的优势:
-
Adam优化器可以自动调整学习率,使其更加精确。
-
通过尝试不同的初始学习率(较大或较小的值),可以找到使模型最快收敛的学习率。
-
-
模型训练:
-
使用Adam优化器训练模型,可以提高训练效率和稳定性。
-
Adam优化器在训练过程中会自动调整每个参数的学习率,帮助模型更快地收敛到最优解。
-
介绍Adam
Adam算法是什么?
Adam算法是一种用于训练神经网络的优化算法。它结合了两种优化方法的优点:
动量(Momentum)和自适应学习率(Adaptive Learning Rate)。这两种方法都旨在帮助神经网络更快、更稳定地学习。
为什么需要Adam算法?
在训练神经网络时,我们的目标是找到一组参数(权重和偏置),使得网络的预测尽可能接近真实值。我们通过不断调整这些参数来实现这个目标。传统的梯度下降方法在调整参数时可能会遇到一些问题,比如:
-
学习速度慢:需要很多步骤才能找到最优参数。
-
不稳定:参数更新可能会在最优解附近来回震荡,而不是稳定地收敛到最优解。
Adam算法就是为了解决这些问题而设计的。
Adam算法如何工作?
Adam算法通过以下两个主要步骤来调整参数:
-
动量(Momentum):
-
想象一下,你在雪地上滑雪。如果你在平地上滑,可能会滑得很慢。但如果你在斜坡上滑,就会滑得更快,因为重力帮助你加速。
-
类似地,动量帮助我们在参数更新时“加速”。我们不仅考虑当前的梯度(即当前的斜率),还考虑之前的梯度。这样,如果梯度的方向一致,我们就可以更快地更新参数。
-
-
自适应学习率(Adaptive Learning Rate):
-
学习率决定了我们每次更新参数时迈出的步长。如果步长太大,我们可能会跳过最优解;如果步长太小,我们可能会收敛得太慢。
-
Adam算法根据每个参数的历史更新情况自动调整学习率。这意味着不同的参数可以有不同的学习率,这样我们就可以更灵活地调整参数。
-
Adam算法的优点
-
更快的收敛:通过结合动量和自适应学习率,Adam算法通常比传统的梯度下降方法收敛得更快。
-
更稳定的训练:自适应学习率帮助我们更稳定地更新参数,减少在最优解附近的震荡。
-
易于使用:Adam算法只需要设置几个超参数(如动量的系数和学习率的初始值),就可以在多种问题上表现良好。
总结
Adam算法是一种智能的优化算法,它通过结合动量和自适应学习率来帮助神经网络更快、更稳定地学习。它自动调整每个参数的学习率,使得训练过程更加高效和可靠。这就是为什么Adam算法在深度学习领域如此受欢迎的原因。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









