






TensorRT优化模型过程,首先将PyTorch(或TensorFlow)等训练框架训练完成后的模型编译为TensorRT的格式,然后利用TensorRT推理引擎运行这个模型,从而提升这个模型在英伟达GPU上运行的速度,适用于对实时性要求较高的场景。那么该如何借助TensorRT优化模型推理性能呢?本文将演示模型训练编译过程,然后介绍一些TensorRT常用的模型推理性能优化建议。
阅读前提示
为了帮助您更好地理解TensorRT优化模型推理功能,建议您提前了解以下信息:
-
阅读本文前期望您了解TensorRT简介和TensorRT Cookbook源码等相关内容,以便您对TensorRT的架构和用法有一定的理解。
-
安装TensorRT还需注意CUDA的兼容性,由于TensorRT是专为英伟达GPU设计的,因此它只能在英伟达的硬件上使用,更多信息可查看TensorRT官方文档。
-
本文中使用的Nsight Systems软件,主要用于观察全局的Profiling,如核函数读写情况,核函数之间的调度情况,SM占有率,CPU和GPU之间的异步执行的情况等。
本文中加速效果取决于模型的类型和大小,也取决于我们所使用的显卡类型。
模型编译示例
-
示例拉取现有ResNet18模型进行简单的训练作为演示。您可以使用ResNet18模型跟随示例实现模型性能分析与优化的思路和技巧。
-
TensorRT版本为v8.6.1,更多版本请参考TensorRT下载。
-
PyTorch版本为2.2.0。
-
GPU卡型号为V100-SXM2-32GB,并使用英伟达官方PyTorch镜像运行代码。
Docker拉取英伟达官方PyTorch镜像:docker pull nvcr.io/英伟达/PyTorch:24.01-py3。注意启动Docker时,需为容器挂载Shm(docker run --shm-size=)和共享宿主机IPC(--ipc=host)。
-
-
训练模型并生成ONNX格式模型文件。
下面代码演示了如何拉取现有Resnet18模型并进行简单的训练,最后将模型保存为ONNX格式。
展开查看示例代码
-
保存TensorRT编译模型代码。
编译模型代码如下,并保存在0_build.py文件中。
展开查看示例代码
-
保存Baseline模型代码。
Baseline代码如下,保存在1_baseline.py中。
展开查看示例代码
-
执行推理优化操作并查看过程。
准备完成后,运行如下Shell代码。
python 0_build.py mkdir -pv reports nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/1_baseline \ python 1_baseline.py运行完成后,在./reports目录下,生成一个名称为1_baseline.nsys-rep文件,可导入
Nsight Systems中,Timeline如下。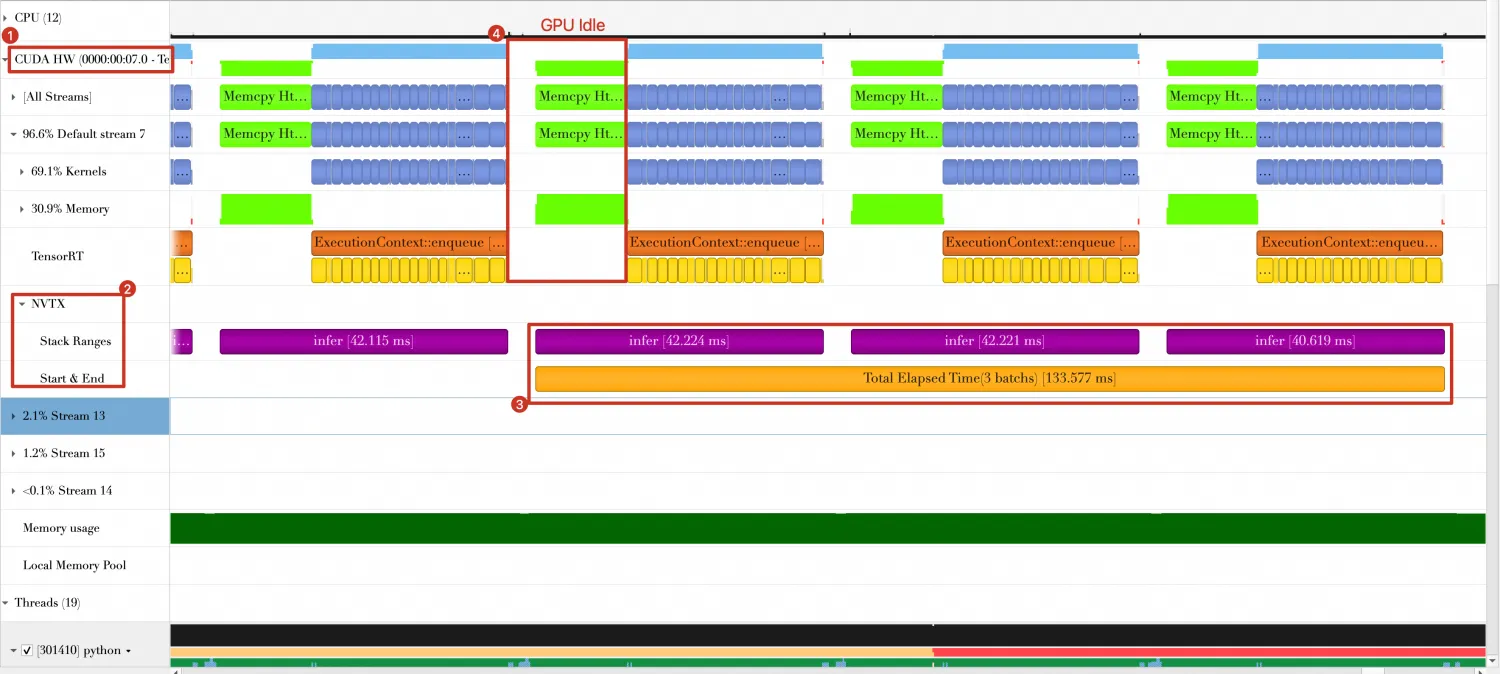
从上图中可以看到。
-
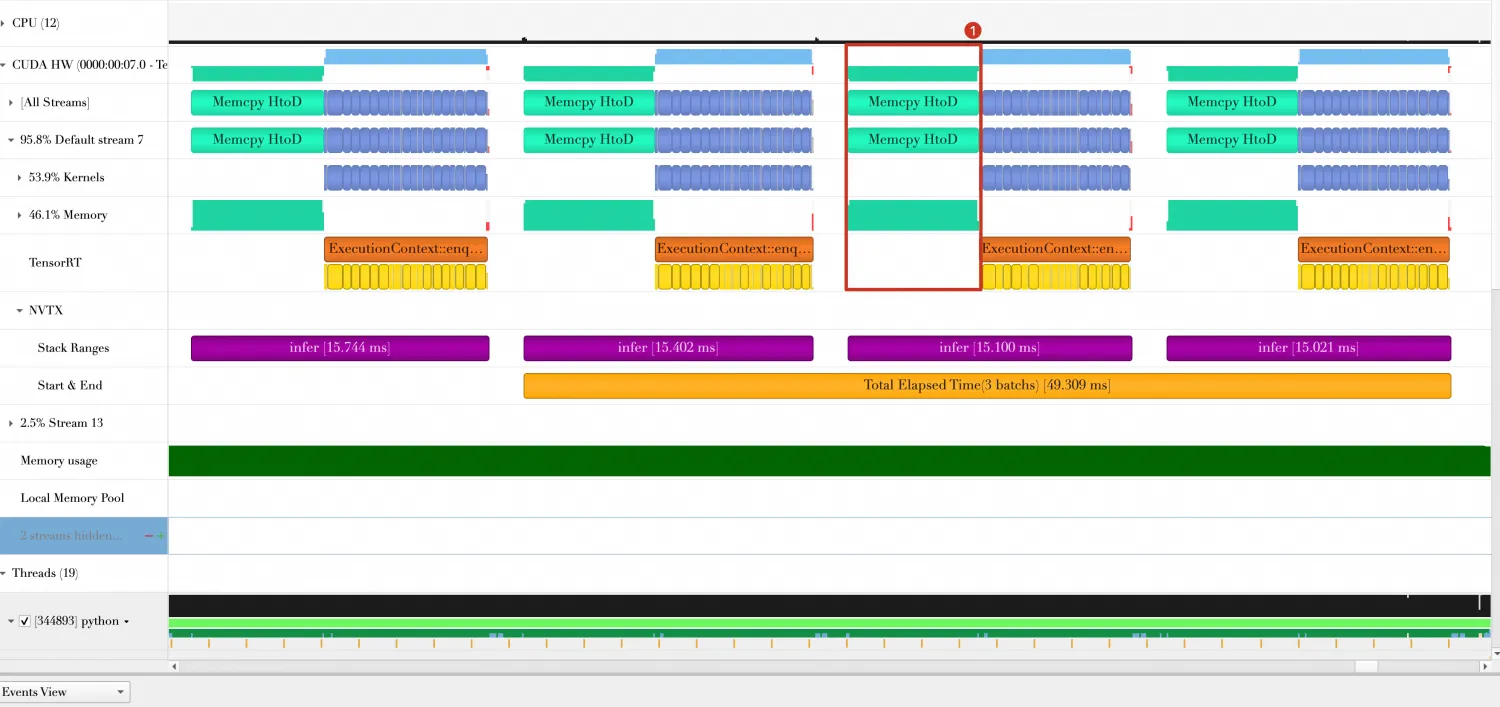
最后三个Batch总共花费时间约为133.577ms。
-
Batch与Batch之间,有一部分时间GPU处于空闲状态(图中标号4的部分),这是由Batch数据传输和Host端打印结果导致的。
-
模型优化方向
方向1: 重用已分配GPU内存
-
问题分析。
在Baseline代码中,每次Batch计算都需要重新申请内存,Batch处理完成后,都需要释放数据,GPU内存的申请和释放都是一个比较耗时的操作。
-
方案设计。
如果能够重用已分配GPU内存,将有利于缩短Batch处理时间。修改Baseline代码,在处理第一个Batch时申请GPU内存,之后的Batch处理所用到的GPU内存都将重用这部分GPU内存。
完整代码如下(注意:只对infer和infer_once做了改动,其他部分代码与Baseline一致),保存在2_reuse_buffers.py中。
展开查看完整代码
-
准备完成后,运行如下Shell代码。
nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/2_reuse-buffers \ python 2_reuse-buffers.py -
运行完成后,在./reports目录下,生成一个名称为2_reuse-buffers.nsys-rep文件,导入
Nsight Systems中,Timeline如下。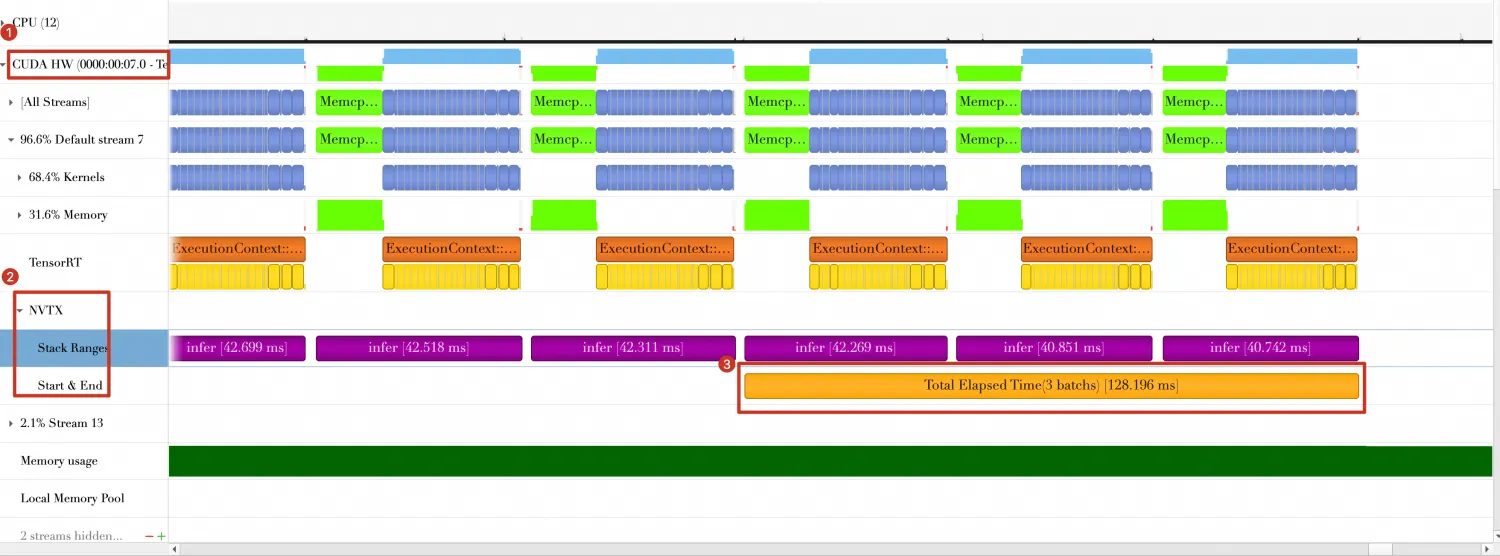
从上图中可以看到:最后三个Batch总共花费时间约为128.196ms,比Baseline中减少133.577ms - 128.196ms = 5.381ms。
方向2: 使用Pin Memory
-
问题分析。
在方向1的基础上,继续寻找可优化的部分。从方向1的Timeline中可以看到,数据由Host端传入GPU端时(耗时约为13ms左右),GPU处于空闲状态,未做任何计算操作,那么缩短数据传输时间将有助于减少Batch的处理时间。
-
方案设计。
在传输数据时,尝试使用Pin Memory,在生产随机数据时,使用Pin Memory保存数据(由函数data_generation_with_pin_memory完成),main函数需做一定修改,其他代码基本不变,代码保存在3_use-pin-memory.py中。
展开查看完整代码
-
准备完成后,运行如下Shell代码。
nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/3_use-pin-memory \ python 3_use-pin-memory.py -
运行完成后,在./reports目录下,生成一个名称为3_use-pin-memory.nsys-rep文件,将其导入
Nsight Systems中,Timeline如下。从上图中可以看到:
-
最后三个Batch总共花费时间约为108.348ms,时间缩短128.196ms - 108.348ms = 19.848ms。
-
Batch传输时间由13.429ms缩短为6.912ms。
-
方向3: 使用FP16(或INT8)精度
-
问题分析。
在优化方向2的Timeline中,计算每个Batch时间约为27.230ms,内存消耗4.7GB。
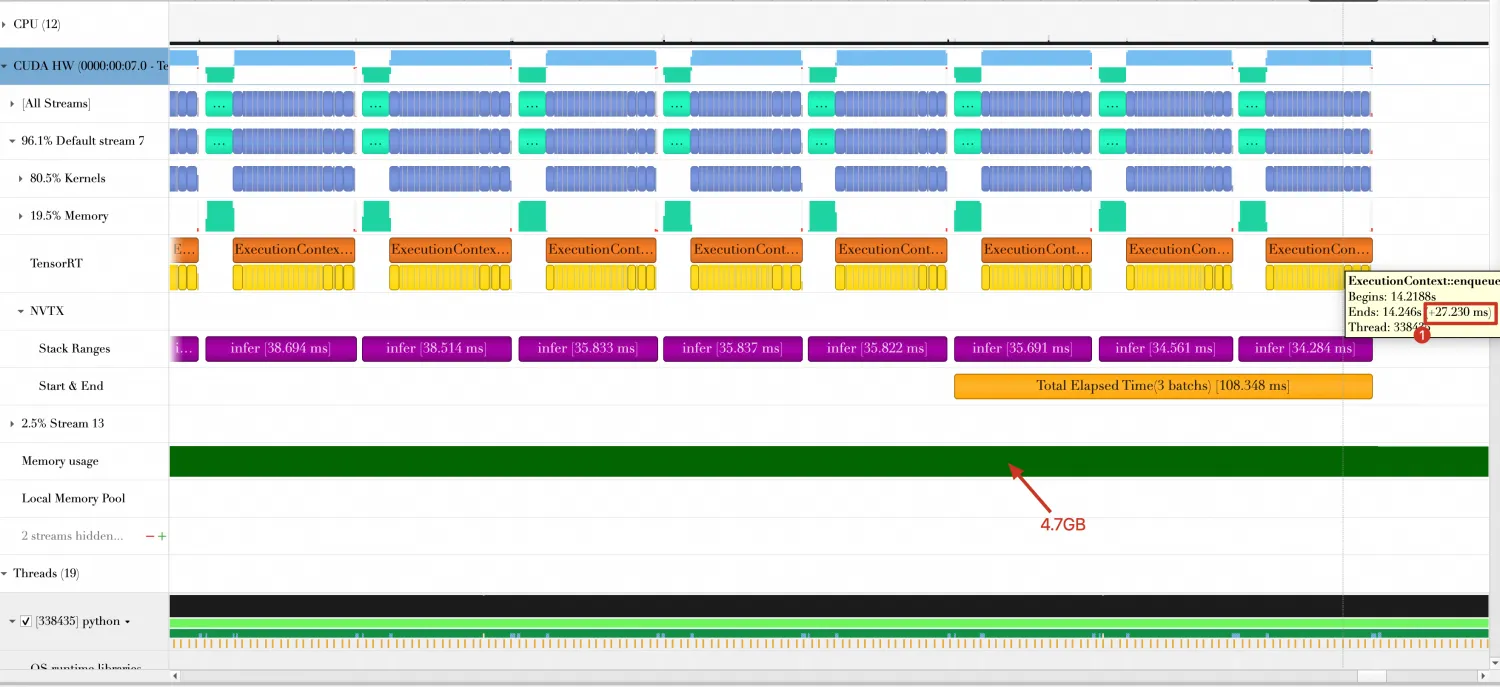
-
方案设计。
如果可以在编译模型时开启FP16精度(或INT8精度)等方式,则可缩短Batch计算时间。开启FP16只需在BuilderConfig中添加如下一行。
config.set_flag(trt.BuilderFlag.FP16) -
在0_build.py脚本中,已指定一个选项(--fp16)用于编译时开启FP16模式,同时复制一份3_use-pin-memory.py并命名为4_use-fp16.py,执行如下Shell脚本。
python 0_build.py --fp16 # 开启FP16模式 nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/4_use-fp16 \ python 4_use-fp16.py -
运行完成后,在./reports目录下,生成一个名称为4_use-fp16.nsys-rep文件,导入
Nsight Systems中,Timeline如下。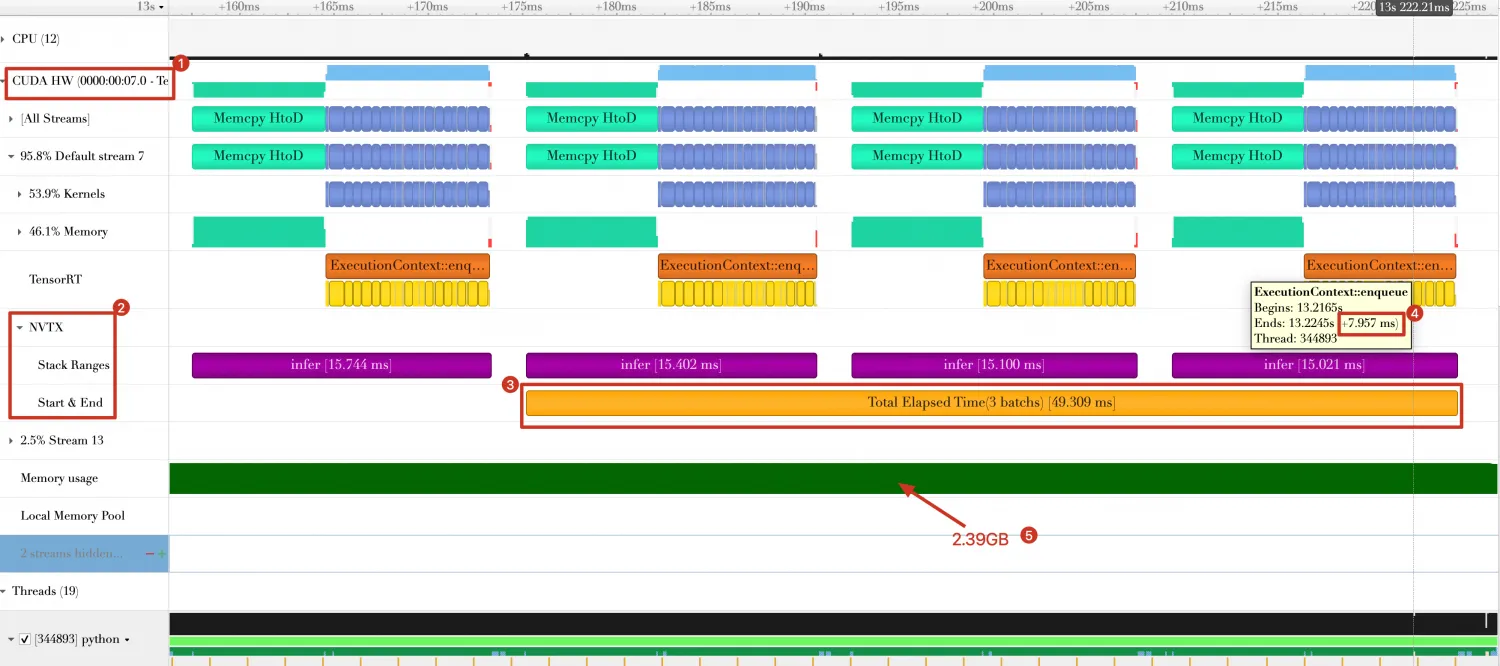
从图中可以看到:
-
三个Batch总的消耗时间由108.348ms 缩短为49.309ms。
-
Batch计算时间由27.230ms缩短为7.957ms。
-
GPU内存使用量由4.7GB减少为2.39 GB。
重要
生产实践中,还需要有一个校准过程,以保证模型量化后的结果正确性,具体请参考TensorRT官方文档。
-
方向4: 使用重叠数据传输和数据计算
-
问题分析。
当我们进行量化操作后,数据传输时间相比于数据计算时间已变得不可忽略。此时,单纯的缩短数据传输时间已经不可行了。
-
方案设计。
要完成数据传输和数据计算重叠的目标,需要借助CUDA Stream。
在代码中修改添加:
-
创建3个cuda stream,一个用于数据从Host到Device传输操作,一个用于数据计算和结果返回操作。
-
创建3个cuda event,用于cuda stream之间以及GPU与Host的同步操作。
-
预先传输第一个Batch的数据,然后在第一个Batch计算时,同时传输第二个Batch的数据,以此类推,当计算第二个Batch时,同时传输第三个Batch数据。
下面是完整代码,保存在5_multi-streams.py。
展开查看完整代码
-
-
准备完成后,执行如下Shell代码。
python 0_build.py --fp16 nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/5_multi-streams \ python 5_multi-streams.py -
结果在的Timeline中展示如下。
从图中可以获得如下信息:
-
3个Batch总耗时由49.309ms缩短为29.650ms。
-
在优化方向3的Timeline中,数据传输(Host端到GPU端,图中"Memcpy HtoD")与数据计算(图中蓝色部分)是串行执行的,而在上图中数据传输和数据计算是并行执行的(图中标号3)。
-
Batch与Batch之间还存在一定的空隙,从图中可以看出,这个是由print_result函数引起的。
-
方向5: 使用多线程处理输出结果
-
问题分析。
在方向4的Timeline中,Batch与Batch之间还存在一定的间隙,这些间隙是由print_result函数引起的,它在打印输出结果时,GPU是处于空闲状态的。
-
方案设计。
可以使用Python多线程另起一个单独的线程处理输出结果,主线程继续执行。
修改infer函数,创建一个线程执行print_result函数,完整代码如下,保存在6_multi-threads.py中。
展开查看完整代码
-
准备完成后,执行如下Shell代码。
python 0_build.py --fp16 nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/6_multi-threads \ python 6_multi-threads.py -
在的Timeline显示结果如下,可以看到print_result函数与GPU计算与数据传输重叠,并不是串行执行的。
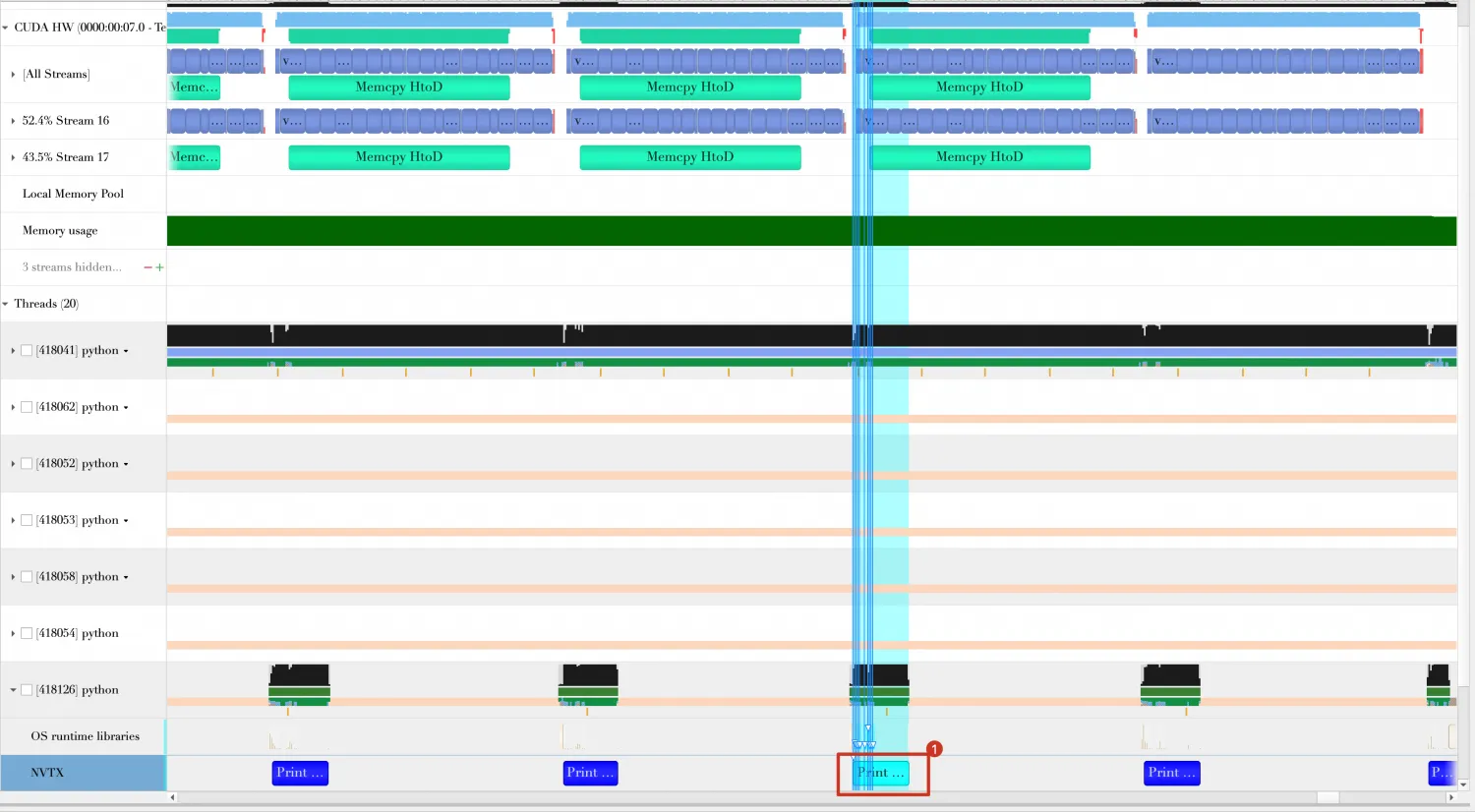
同时,最后三个Batch的耗时缩短29.650ms - 26.787ms = 2.86ms。
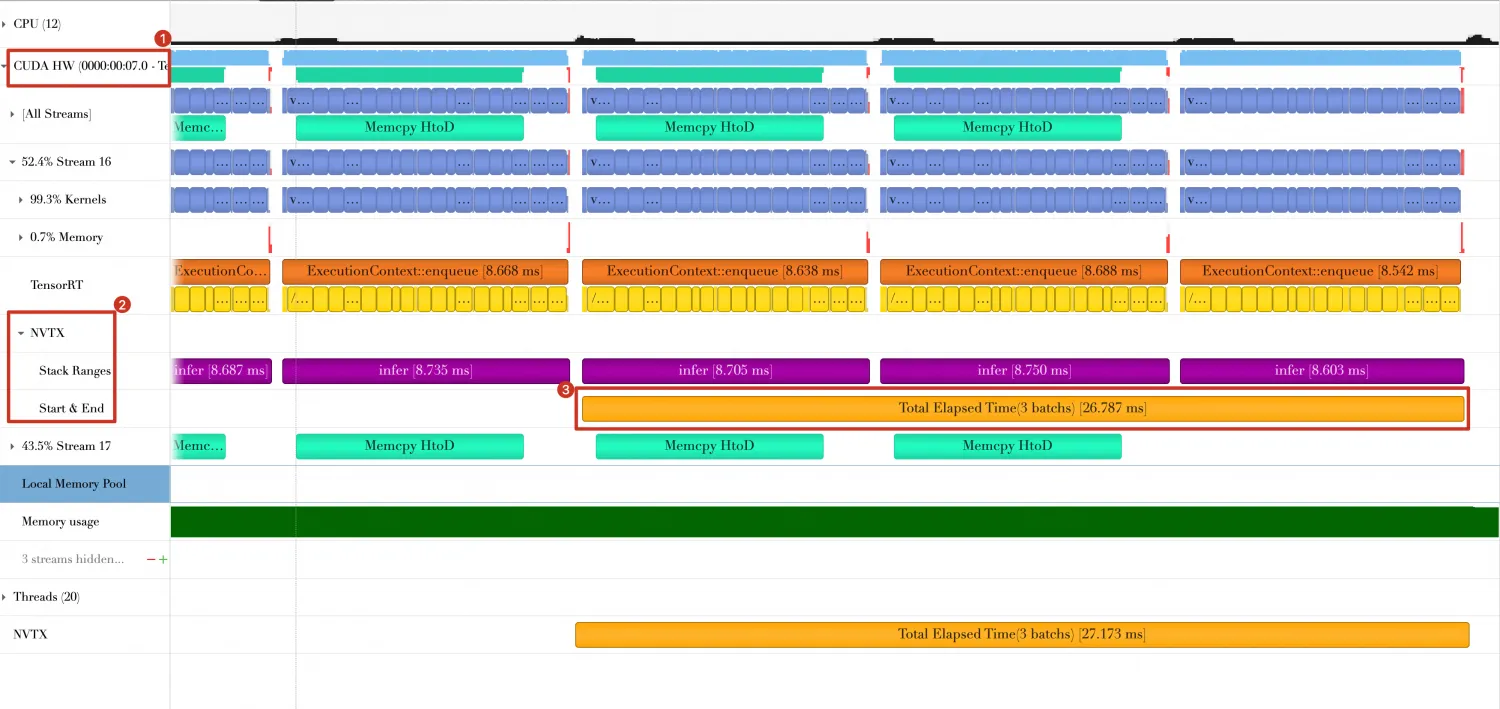
方向6: 使用CUDA Graph
-
问题分析。
在方向5的Timeline中,每次Batch计算都会出现25次Kernel Launch,每次Kernel Launch都会消耗一定的时间。
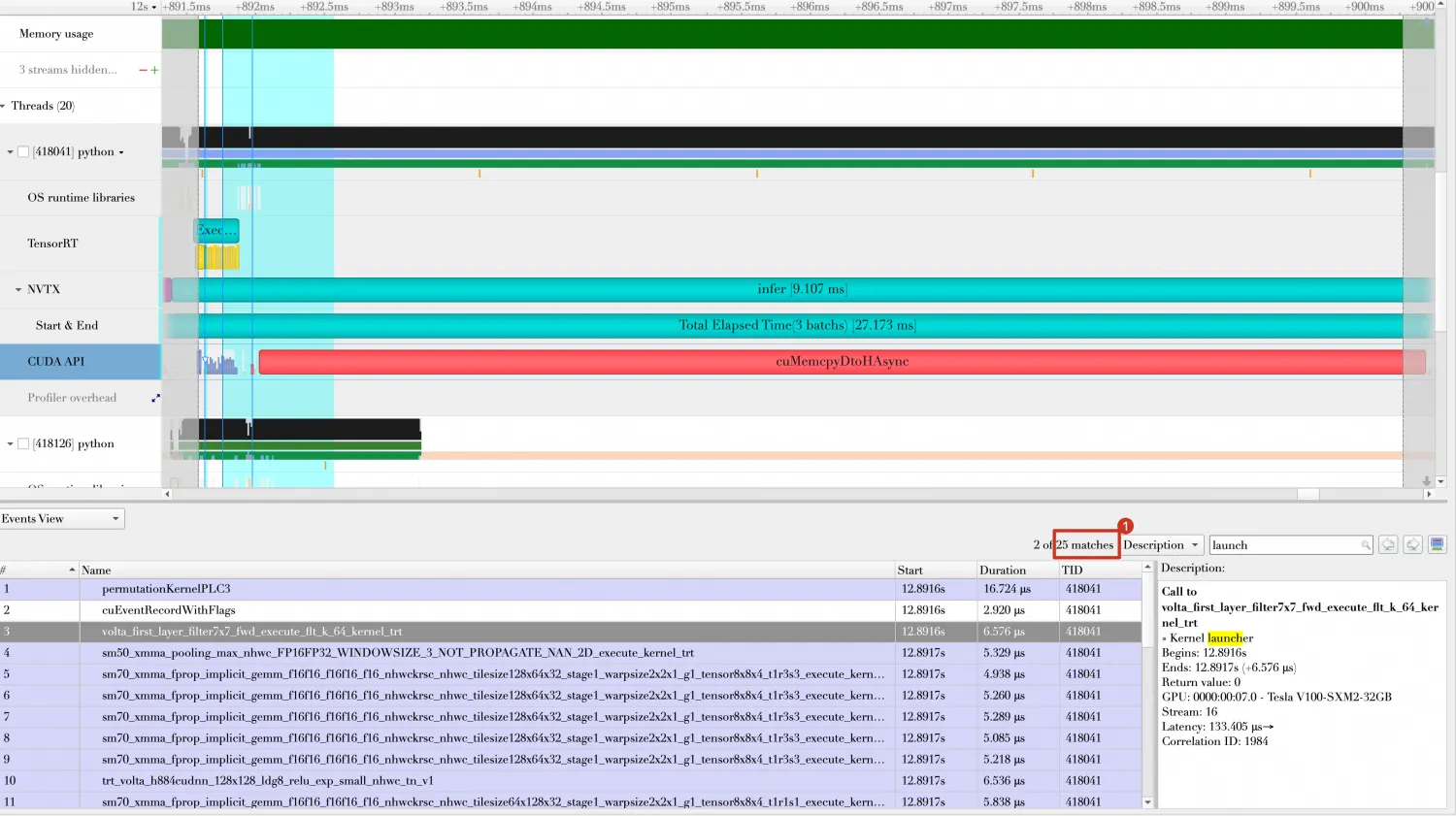
-
方案设计。
CUDA Graphs 是 CUDA 10.0 中引入的一个特性,它允许开发者捕获一系列CUDA操作(如内存传输和核函数执行),并将它们组织成一个被称为“graph”的有向无环图。这个图可以被看作是在不同CUDA流上执行的一系列操作的“快照”,一旦捕获,就可以多次执行,而无需CPU介入,从而减少了CPU与GPU之间的交互,提高了整体的执行效率。可以利用CUDA Graph来捕获TensorRT引擎执行推理所需要的一系列CUDA操作,包括内存拷贝、核函数执行等。这样可以减少CPU参与的推理调度开销,尤其是在执行重复推理任务时,可以显著提高推理性能。
重要
请注意CUDA Graphs的使用可能具有一定的复杂性,通常需要对CUDA编程有一定的了解,以及对如何在TensorRT中配置和执行推理过程有深入的理解。此外,CUDA Graphs的有效性也取决于应用场景,不是所有的应用都能从中获益,因为有些CUDA 操作不一定支持CUDA Graph。本文涉及到的模型就是一个例子,无法使用CUDA Graph,因为模型中存在不支持CUDA Graph的操作。
在TensorRT中使用CUDA Graph的示例如下,修改infer_once函数。
展开查看完整代码
-
执行代码后,报如下错误,估计是模型中存在不支持图捕获的CUDA操作。

关于cuda graph例子,可以参考Cuda Graph。
方向7: 使用多CPU线程多Context
-
问题分析。
上述的优化方向演示的都是单个Context处理Batch数据,单个Context无法并行处理多个Batch,原因在于每个Context都存在推理时的中间结果缓存,而这些缓存同一时间只能为一个Batch提供服务。
-
方案设计。
那么,有没有可能Host端有多个CPU线程提交Batch处理请求,并且TensorRT能够并行处理这些Batch数据呢?答案是可以的,TensorRT支持创建多个Context,各个Context之间不互相影响。
下面的例子将创建两个Context(两个Context使用同一个Profile,需要在编译模型时开启共享Profile的选项),然后产生的10个Batch数据分成两组,每组5个Batch数据。每个Context处理一组Batch。
完整代码如下,保存在8_multi_cpu-threads.py。
展开查看完整代码
-
在上述代码中,启动两个Python线程,每个线程处理5个Batch,每个线程将创建一个Context,执行各自的推理。准备完成后,执行如下Shell脚本。
python 0_build.py --fp16 --share-profile # 开启共享Profile模式 nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/8_multi-context \ python 8_multi-context.py -
在Timeline中显示结果如下。
可以得到如下结论:
-
GPU计算在两个Stream(Stream 19和Stream 16)中并行执行。
-
每个Stream中最后3个Batch的消耗时间约为50ms左右,最后三个Batch平均使用时间约为50 / 2 = 25ms,每个Batch计算时间约为13ms。与单个Batch相比计算时间有所增加,说明GPU资源是充分利用,但有可能造成计算任务过载的问题。
-
GPU内存使用量是单个Context执行推理时的2倍左右。
-
方向8: 使用Dynamic Shape多重配置文件
-
问题分析。
使用动态形状(Dynamic Shape)来提高内核的灵活性,从而可以处理不同大小的输入数据。然而,在实际使用中,我们可能需要为不同的输入大小或其他条件编译多个版本的内核,这就是多Profile(多重配置文件)。多Profile可以通过在编译内核时添加多个编译选项来实现。例如,我们可以为不同的输入大小使用不同的线程块大小或其他优化参数。某些场景下,Dynamic Shape模式在min-opt-max跨度较大时,性能下降比较明显。
-
方案设计。
解决办法就是使用多个OptimizationProfile,对应多个min-opt-max,并且缩小min-opt-max跨度。
为了演示多Profile的使用过程,代码将基于Baseline的代码做简化修改。
首先修改0_build.py代码,需要在编译阶段构建两个Profile,并为每个Profile设置min-opt-max shape,保存在9_multi-profiles-build.py。
展开查看完整代码
-
然后准备执行推理的代码,保存在9_multi-profiles.py。在代码中准备了两个数据集(data0和data1),shape分别为[16,3,224,224]和[128,3,224,224]。如果不开启多Profile,那么每次都需要为数据分配新的GPU内存。
展开查看完整代码
-
准备完成后,执行如下Shell脚本。
python 9_multi-profiles-build.py --output resnet18-multi-profiles.plan nsys profile -w true \ -t cuda,nvtx,osrt,cudnn,cublas \ --cuda-memory-usage=true \ --cudabacktrace=all \ --cuda-graph-trace=node \ --gpu-metrics-device=all \ -f true \ -o reports/9_multi-profiles \ python 9_multi-profiles.py -
将结果导入
Nsight Systems中,效果如下。可以看到,前面10个Batch的shape为[16,3,224,224]。
后面10个Batch的shape为[128,3,224,224]。
关于dynamic shape更多的用法,可以参考TensorRT Cookbook。
总结
经过上述一系列的优化技巧取得了性能的提升,我们成功地将3个Batch的处理时间由133.577ms缩短为25ms左右。更多关于TensorRT的高级功能和优化技巧,可参考TensorRT Cookbook。

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









