






容器服务 Kubernetes 版 ACK(Container Service for Kubernetes)通过提供Slurm on Kubernetes解决方案及ack-slurm-operator应用组件,使得您能够在阿里云的ACK集群上便捷、高效地部署和管理Slurm(Simple Linux Utility for Resource Management)调度系统,以适应高性能计算(HPC)和大规模AI/ML等场景。
Slurm介绍
Slurm是一个强大的开源集群资源管理和作业调度平台,专门设计用于优化超级计算机和大型计算集群的性能与效率。其核心组件协同工作,确保系统的高效运作和灵活的管理。Slurm的工作原理如下所示。
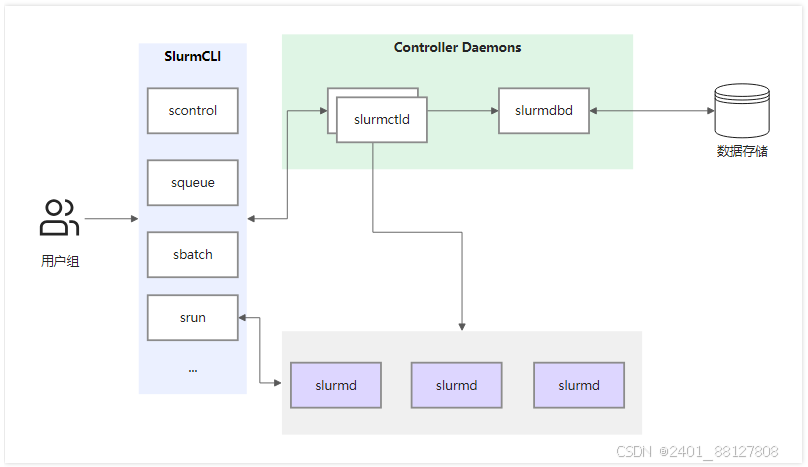
-
slurmctld(Slurm Control Daemon):作为Slurm的中央大脑,slurmctld负责监控系统资源、调度作业并管理整个集群的状态。为了增强系统的可靠性,可配置一个备用slurmctld实现高可用性,确保即使主控制器故障也不会中断服务。
-
slurmd(Slurm Node Daemon):在每个计算节点上部署,slurmd守护进程负责接收来自slurmctld的指令,执行作业任务,包括作业的启动、执行、状态报告以及准备接受新的作业。它作为与计算资源直接交互的接口,是实现作业调度的基础。
-
slurmdbd(Slurm Database Daemon):虽然是可选组件,但它能够通过维护一个集中式数据库来存储作业历史、记账信息等,这对于大规模集群的长期管理和审计至关重要。支持跨多个Slurm管理集群的数据整合,提升了数据管理的效率和便利性。
-
SlurmCLI:提供了一系列命令行工具,以便于作业管理与系统监控:
-
scontrol:用于集群管理和配置的详细控制。
-
squeue:查询作业队列状态。
-
srun:用于提交和管理作业。
-
sbatch:用于提交批处理作业的命令,可以帮助您调度和管理计算资源。
-
sinfo:查看集群的总体状态,包括节点的可用性。
-
Slurm on ACK介绍
Slurm Operator通过SlurmCluster的自定义资源,解决了Slurm集群管理需要的配置文件以及控制面管理问题,简化了部署和运维Slurm集群的复杂度。Slurm on ACK的架构如下图所示。集群管理员通过操作SlurmCluster即可轻松部署及管理Slurm集群,SlurmOperator会根据SlurmCluster在集群中创建出相应的Slurm管控组件。Slurm的配置文件可以通过共享存储的方式挂载到管控组件中,也可以通过ConfigMap挂载。
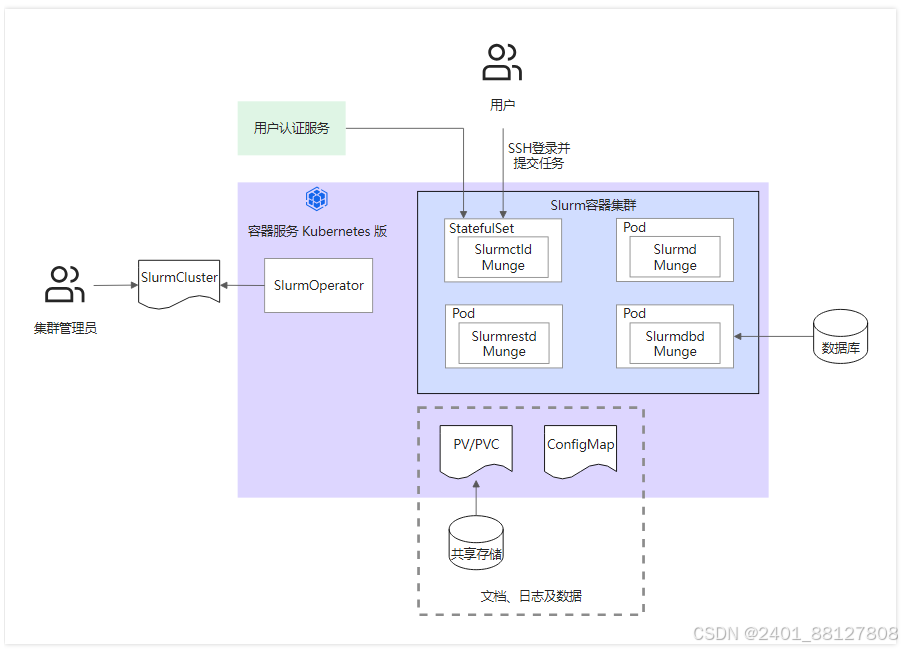
前提条件
已创建包含一个GPU节点的集群,且集群版本需为1.22及以上。具体操作,请参见创建GPU集群、升级集群。
步骤一:安装ack-slurm-operator组件
-
登录容器服务管理控制台,在左侧导航栏选择市场 > 应用市场。
-
在应用市场页面搜索并单击ack-slurm-operator卡片,然后在ack-slurm-operator的详情页面,单击一键部署,并根据页面提示完成组件配置。
配置组件时,您只需要为组件选择目标集群,其他参数配置保持默认即可。
-
组件配置完成后,单击确定。
步骤二:创建SlurmCluster
手动创建
使用Helm创建
-
为ACK集群创建用于Munge认证的Slurm Secret。
-
执行以下命令,使用OpenSSL工具生成一个密钥。该密钥用于Munge认证。
openssl rand -base64 512 | tr -d '\r\n' -
执行以下命令,创建一个Secret。该Secret用于存储上一步生成的Munge密钥。
kubectl create secret generic <$MungeKeyName> --from-literal=munge.key=<$MungeKey>-
<$MungeKeyName>需要替换为您自定义的密钥名称,例如mungekey。 -
<$MungeKey>需要替换为上一步生成的密钥字符串。
-
执行以上步骤后,SlurmCluster可以通过配置或关联此Secret来获取并使用该密钥进行Munge认证。
-
-
执行以下命令,创建SlurmCluster需要使用的ConfigMap。
本示例通过在CR(Custom Resource)中指定slurmConfPath的方式将如下Configmap配置文件挂载到Pod中,这样可以确保即使Pod因任何原因被重新创建,配置也能自动恢复到预期状态。
代码中的
data参数为配置文件示例。如果您需要生成配置文件,推荐使用Easy Configurator或Full Configurator工具生成。展开查看命令详情
预期输出:
configmap/slurm-test created预期输出表明,ConfigMap已创建成功。
-
提交SlurmCluster CR。
-
复制并粘贴如下内容,用于创建slurmcluster.yaml,代码示例如下。
说明
示例中使用的镜像是使用Ubuntu制作的包含了CUDA 11.4以及Slurm 23.06版本的镜像,其中包含了自研的支持Cloud Node(集群中状态为Cloud的节点)动态扩缩容功能的组件。如果您需要自定义镜像,您可以自行进行镜像制作以及上传。
展开查看YAML示例
使用以上SlurmCluster CR将会创建出带有1个Head Node和4个Worker的SlurmCluster(SlurmCluster作为Pod运行在ACK集群中)。需要注意的是,SlurmCluster CR中指定的mungeConfPath以及slurmConfPath需要与HeadGroupTemplate以及各WorkerGroupTemplate中相关文件的挂载路径相同。
-
执行以下命令,部署slurmcluster.yaml到集群
kubectl apply -f slurmcluster.yaml预期输出:
slurmcluster.kai.alibabacloud.com/slurm-job-demo created -
执行以下命令,查看已创建出的SlurmCluster是否正常运行。
kubectl get slurmcluster预期输出:
NAME AVAILABLE WORKERS STATUS AGE slurm-job-demo 5 ready 14m输出结果表明SlurmCluster已成功部署,并且有5个节点均处于就绪状态。
-
执行以下命令,查看名为slurm-job-demo的SlurmCluster中的Pods是否处于Running状态。
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE slurm-job-demo-head-x9sgs 1/1 Running 0 14m slurm-job-demo-worker-cpu-0 1/1 Running 0 14m slurm-job-demo-worker-cpu-1 1/1 Running 0 14m slurm-job-demo-worker-cpu1-0 1/1 Running 0 14m slurm-job-demo-worker-cpu1-1 1/1 Running 0 14m输出结果表明SlurmCluster中的1个Head Node和4个Worker均正常运行。
-
步骤三:登录SlurmCluster
Kubernetes集群管理员
由于集群管理员拥有Kubernetes集群的操作权限,SlurmCluster对于Kubernetes集群管理员来说是一个运行在集群中的Pod,因此Kubernetes集群管理员可以使用kubectl命令行工具登录到集群中任意SlurmCluster的任意Pod上,且将自动拥有SlurmCluster的Root用户的权限。
执行以下命令,可以登录到SlurmCluster的任意Pod上。
# 将slurm-job-demo-head-x9sgs替换成您集群中具体的Pod名。
kubectl exec -it slurm-job-demo-xxxxx -- bashSlurmCluster普通用户
SlurmCluster的管理员或SlurmCluster的普通用户可能没有kubectl exec命令的权限,在使用集群时需要通过SSH登录的方式登录到已创建的SlurmCluster中。
-
通过Service的ExternalIP登录Head Pod是更持久和可扩展的方案,适合需要长期稳定访问的场景。通过负载均衡器和External IP,可以从内网的任何位置访问到SlurmCluster。
-
通过Port-forward转发请求是临时性的解决方案,适用于短期运维或调试需求,因为它依赖于持续运行的
kubectl port-forward命令。
通过Service的External IP登录Head Pod
通过Port-forward转发请求
-
创建一个LoadBalancer类型的Service,用于流量转发(使集群内部服务可由外部访问)。具体操作,请参见通过使用已有负载均衡的服务暴露应用或通过使用自动创建负载均衡的服务公开应用。
-
Service需使用私网CLB。
-
需要为该Service设置标签
kai.alibabacloud.com/slurm-cluster: ack-slurm-cluster-1和kai.alibabacloud.com/slurm-node-type: head,以便它能够路由到正确的Pod。
-
-
执行以下命令,获取LoadBalancer类型Service的External IP。
kubectl get svc -
执行以下命令,通过SSH登录到服务对应的Head Pod。
# $YOURUSER请替换为实际Pod中的用户名,$EXTERNAL_IP请替换为从Service获取的外部IP地址。 ssh $YOURUSER@$EXTERNAL_IP
步骤四:使用SlurmCluster
以下介绍如何在SlurmCluster中实现节点间的用户同步、节点间的日志共享以及集群自动扩缩容配置。
节点间的用户同步
由于Slurm本身不提供集中化的用户认证服务,当使用sbatch提交作业至SlurmCluster时,如果目标节点上没有与提交作业用户对应的账户,作业可能无法执行。为解决该问题,您可以通过为SlurmCluster配置LDAP(Lightweight Directory Access Protocol)进行用户管理,利用LDAP作为一个集中认证的后端,让Slurm能够依托此服务验证用户身份。具体操作如下所示:
-
拷贝以下YAML内容至ldap.yaml文件中,创建一个基础的LDAP服务实例,用于存储和管理用户信息。
ldap.yaml文件定义了一个LDAP后端Pod和对应的Service。Pod包含LDAP服务的容器,而Service则暴露了LDAP服务,使其在网络中可访问。
展开查看LDAP后端Pod和对应的Service
-
执行以下命令,部署LDAP后端服务。
kubectl apply -f ldap.yaml预期输出:
deployment.apps/ldap created service/ldap-service created secret/ldap-secret created -
(可选)拷贝以下YAML内容至phpldapadmin.yaml文件中,部署一个前端Pod和Service,用于配置前端界面以提升管理效率。
展开查看LDAP前端Pod和对应的Service
执行以下命令,部署LDAP前端服务。
kubectl apply -f phpldapadmin.yaml -
按照步骤三的操作登录到SlurmCluster的具体Pod中,执行以下命令,安装LDAP客户端软件包。
apt update apt install libnss-ldapd -
安装完libnss-ldapd软件包后,在Pod中配置SlurmCluster的网络认证服务。
-
执行以下命令,安装vim软件包,用于后续编辑脚本和文件。
apt update apt install vim -
在/etc/ldap/ldap.conf文件中编辑如下参数,配置LDAP客户端。
... BASE dc=example,dc=org # 替换为您的LDAP基础DN。 URI ldap://ldap-service # 替换为您的LDAP服务器地址。 ... -
在/etc/nslcd.conf文件中编辑如下参数,定义连接到LDAP服务器。
... uri ldap://ldap-service # 替换为实际的LDAP服务器地址。 base dc=example,dc=org # 应根据你的LDAP目录结构进行设置。 ... tls_cacertfile /etc/ssl/certs/ca-certificates.crt # 指定CA证书文件的路径,用于验证LDAP服务器的证书。 ...
-
日志共享与访问
默认情况下,使用sbatch生成的作业日志直接被保存在执行任务的节点上,给查看日志带来了不便。为了方便查看日志,您可以通过创建NAS文件系统,将所有的作业日志统一存储在一个可访问的位置。这样即使计算任务在不同的节点上执行,它们产生的日志都能被统一收集和保存,从而提升了日志管理的便利性。具体操作如下所示。
-
创建一个NAS文件系统,这个文件系统将用于存储和共享各节点的日志。具体操作,请参见创建文件系统。
-
登录容器服务管理控制台,创建NAS的相关PV(Persistent Volume)和PVC(Persistent Volume Claim)。具体操作,请参见使用NAS静态存储卷。
-
修改SlurmCluster CR。
对
headGroupSpec和每个workerGroupSpec添加volumeMounts和volumes参数配置引用已创建的PVC,将其挂载到/home目录下。示例如下:headGroupSpec: ... # 新增对于/home的挂载。 volumeMounts: - mountPath: /home name: test # 这里为引用PVC的volume名称。 volumes: # 添加PVC的定义。 - name: test # 这里需要与volumeMounts中的name匹配。 persistentVolumeClaim: claimName: test # 这里替换实际PVC的名称。 ... workerGroupSpecs: # ... 对于每个workerGroupSpec重复上述volume和volumeMounts的添加过程。 -
执行以下命令,部署SlurmCluster CR资源。
重要
如果SlurmCluster CR资源部署失败,请执行
kubectl delete slurmcluster slurm-job-demo命令删除CR资源,然后重新部署即可成功。kubectl apply -f slurmcluster.yaml部署后即可在不同的工作节点中拥有相同的文件系统。
集群自动扩缩容
在默认提供的Slurm镜像的根路径下包含slurm-resume.sh、slurm-suspend.sh以及slurmctld-copilot等可执行文件和脚本,它们负责与slurmctld交互以进行集群的扩缩容。
基于CloudNode的Slurm集群自动扩缩容原理
-
Local Nodes:指直接连接到集群管理器、物理存在的计算节点。
-
Cloud Nodes:逻辑上存在的节点,代表可通过云服务提供商按需创建和销毁的虚拟机实例。
Slurm on ACK自动扩缩容原理
操作步骤
-
配置自动扩缩容权限(Helm安装时会自动创建Slurmctld的扩容权限,该步骤可以跳过)。
自动扩缩容需要从Head Pod中可以访问并更新SlurmCluster CR,因此建议您在使用该能力时通过RBAC给Head Pod配置相关权限。配置相关权限包括以下两步:
首先需要创建Slurmctld需要的ServiceAccount、Role以及RoleBinding。假设您的SlurmCluster的Name为
slurm-job-demo,Namespace为default。首先在文件中保存以下内容,假设文件名为rbac.yaml:apiVersion: v1 kind: ServiceAccount metadata: name: slurm-job-demo --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: slurm-job-demo rules: - apiGroups: ["kai.alibabacloud.com"] resources: ["slurmclusters"] verbs: ["get", "watch", "list", "update", "patch"] resourceNames: ["slurm-job-demo"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: slurm-job-demo subjects: - kind: ServiceAccount name: slurm-job-demo roleRef: kind: Role name: slurm-job-demo apiGroup: rbac.authorization.k8s.io保存到文件中之后通过
kubectl apply -f rbac.yaml的方式提交该资源清单。第二步为给Slurmctld的Pod赋予该权限。首先通过
kubectl edit slurmcluster slurm-job-demo修改slurmcluster,将.Spec.Slurmctld.Template.Spec.ServiceAccountName中设置为刚刚创建的ServiceAccount。apiVersion: kai.alibabacloud.com/v1 kind: SlurmCluster ... spec: slurmctld: template: spec: serviceAccountName: slurm-job-demo ...之后重建管理slurmctld的statefulset应用刚刚的修改。您可以通过
kubectl get sts slurm-job-demo的方式查看到当前管理slurmctld pod的statefulset,并通过kubectl delete sts slurm-job-demo删除该statefulset,slurmoperator会重建该statefulset并应用新的配置。 -
配置自动扩缩容文件/etc/slurm/slurm.conf。
通过共享存储文件管理配置文件
通过Configmap手动管理配置文件
通过Helm管理配置文件
# 以下设置为使用CLOUDNODE时的必填项。 # SuspendProgram与ResumeProgram为自研功能 SuspendTimeout=600 ResumeTimeout=600 # 当节点上没有任务时,将节点自动挂起的时间间隔 SuspendTime=600 # 设定每分钟能够扩容或缩容的节点数量 ResumeRate=1 SuspendRate=1 # NodeName的格式必须为${cluster_name}-worker-${group_name}-。需要在这一行中声明节点的资源量,否则Slurmctld会 # 将Node视为仅有 1c 资源。这里声明的资源请尽量与workerGroup中声明的资源量相同,否则可能发生资源的浪费。 NodeName=slurm-job-demo-worker-cpu-[0-10] Feature=cloud State=CLOUD # 以下为固定配置,保持不变即可 CommunicationParameters=NoAddrCache ReconfigFlags=KeepPowerSaveSettings SuspendProgram="/slurm-suspend.sh" ResumeProgram="/slurm-resume.sh" -
应用新的配置
假设您提交的slurmcluster的Name为
slurm-job-demo,您可以通过kubectl delete sts slurm-job-demo应用新的slurmctld的Pod的配置。 -
将slurmcluster.yaml文件中的工作副本数调整为0,方便后续查看节点的扩缩容。
手动管理
通过Helm管理
假设提交的slurmcluster的Name为
slurm-job-demo。通过kubectl edit slurmcluster slurm-job-demo将slurmcluster中的workerGroup的workerCount调整为0。即可将工作节点副本数调整为0。 -
提交一个sbatch任务。
-
执行以下命令,创建一个Shell脚本。
cat << EOF > cloudnodedemo.sh在命令提示符后输入以下内容:
> #!/bin/bash > srun hostname > EOF -
执行以下命令,查看执行的脚本内容是否正确。
cat cloudnodedemo.sh预期输出:
#!/bin/bash srun hostname脚本输出内容无误。
-
执行以下命令,将脚本提交给SlurmCluster进行处理。
sbatch cloudnodedemo.sh预期输出:
Submitted batch job 1预期输出表明任务已成功提交并分配了一个作业ID。
-
-
查看集群扩缩容情况。
-
执行以下命令,查看SlurmCluster的伸缩日志。
cat /var/log/slurm-resume.log预期输出:
namespace: default cluster: slurm-demo resume called, args [slurm-demo-worker-cpu-0] slurm cluster metadata: default slurm-demo get SlurmCluster CR slurm-demo succeed hostlists: [slurm-demo-worker-cpu-0] resume node slurm-demo-worker-cpu-0 resume worker -cpu-0 resume node -cpu-0 end日志输出结果表明SlurmCluster根据工作负载需求自动扩容了一个计算节点来应对提交的作业需求。
-
执行以下命令,查看集群中Pod的情况。
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE slurm-demo-head-9hn67 1/1 Running 0 21m slurm-demo-worker-cpu-0 1/1 Running 0 43s输出结果表明slurm-demo-worker-cpu-0为新加入的集群的Pod,即提交任务已触发集群的扩容。
-
执行以下命令,查看集群节点信息。
sinfo预期输出:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 10 idle~ slurm-job-demo-worker-cpu-[2-10] debug* up infinite 1 idle slurm-job-demo-worker-cpu-[0-1]输出结果表示slurm-demo-worker-cpu-0是刚刚拉起的节点,而Cloud Code中还有1-10总共10个节点可以扩容。
-
执行以下命令,查看刚刚执行的任务信息。
scontrol show job 1预期输出:
JobId=1 JobName=cloudnodedemo.sh UserId=root(0) GroupId=root(0) MCS_label=N/A Priority=4294901757 Nice=0 Account=(null) QOS=(null) JobState=COMPLETED Reason=None Dependency=(null) Requeue=1 Restarts=0 BatchFlag=1 Reboot=0 ExitCode=0:0 RunTime=00:00:00 TimeLimit=UNLIMITED TimeMin=N/A SubmitTime=2024-05-28T11:37:36 EligibleTime=2024-05-28T11:37:36 AccrueTime=2024-05-28T11:37:36 StartTime=2024-05-28T11:37:36 EndTime=2024-05-28T11:37:36 Deadline=N/A SuspendTime=None SecsPreSuspend=0 LastSchedEval=2024-05-28T11:37:36 Scheduler=Main Partition=debug AllocNode:Sid=slurm-job-demo:93 ReqNodeList=(null) ExcNodeList=(null) NodeList=slurm-job-demo-worker-cpu-0 BatchHost=slurm-job-demo-worker-cpu-0 NumNodes=1 NumCPUs=1 NumTasks=1 CPUs/Task=1 ReqB:S:C:T=0:0:*:* ReqTRES=cpu=1,mem=1M,node=1,billing=1 AllocTRES=cpu=1,mem=1M,node=1,billing=1 Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=* MinCPUsNode=1 MinMemoryNode=0 MinTmpDiskNode=0 Features=(null) DelayBoot=00:00:00 OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null) Command=//cloudnodedemo.sh WorkDir=/ StdErr=//slurm-1.out StdIn=/dev/null StdOut=//slurm-1.out Power=输出结果中的NodeList=slurm-demo-worker-cpu-0代表任务执行在刚刚扩容出的节点上。
-
等待一段时间后,执行以下命令,查看节点缩容信息。
sinfo预期输出:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 11 idle~ slurm-demo-worker-cpu-[0-10]可以看到可扩容节点又回到0-10,总共11个节点,即完成了自动缩容。
-

















 2067
2067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









