






摘 要
随着信息技术的不断进步,医疗行业正经历一场深刻的变革,智能医疗技术成为
推动这一行业向前发展的关键动力。中文电子病历,作为医疗信息化进程中的重要成
就,积累了海量的医疗数据,不仅包含了丰富的医学知识,还蕴含了宝贵的临床经验。
然而,由于电子病历数据大多以非结构化文本的形式存在,如何从中快速并准确地提
取出富有价值的信息,并将其转化成易于理解和利用的知识,成为迫切需要解决的问
题。
为高效地将中文电子病历中的数据转化为结构化信息,并深度挖掘其中蕴含的丰
富诊疗知识与临床经验,本文主要研究内容包括:
(
1
)提出了一种基于
Ernie-BMAC
模型的中文电子病历命名实体识别算法。该算
法集成了
Ernie
模型的强语义理解能力和丰富的中文语言资源,同时采用
BiLSTM
实现
高效序列建模,确保了术语边界的精确识别与含义判定,并借助
CRF
实现病历文本的
精准序列标注。通过引入多头注意力机制,聚焦关键信息,提升了嵌套及复杂实体关
系识别能力。最后通过在公开数据集
CCKS2019
上进行对比实验与消融实验,证实了
本文所提出模型的有效性。
(
2
)基于命名实体识别结果,并结合网络爬取的医疗数据,进行了实体关系抽取,
生成三元组数据。随后,采用
Neo4j
图数据库构建了医疗知识图谱,以可视化的方式呈
现医疗信息,使其更加直观易懂。此外,借助知识图谱的查询功能,进一步实现了自
动问答系统。
(
3
)通过对医疗知识图谱及问答系统需求的调研,结合上述研究内容,设计并实
现了一套覆盖医疗知识图谱与智能问诊功能的一体化平台,对本文研究内容进行可视
化展示同时,为用户提供智能的医疗问答服务。
【关键词】:
命名实体识别;知识图谱;图数据库
Research and Implementation of Named Entity
Recognition and Knowledge Graph
Construction for Chinese Electronic Medical
Record
Abstract
With the continuous advancement of information technology, the medical industry is
undergoing a profound change, and intelligent medical technology has become a key driving
force for the development of this industry. Chinese electronic medical records, as an important
achievement in the process of medical informatization, have accumulated massive medical data,
which not only contains rich medical knowledge, but also contains valuable clinical experience.
However, since electronic medical record data mostly exists in the form of unstructured text,
how to quickly and accurately extract valuable information from it and transform it into
knowledge that is easy to understand and utilize has become an urgent problem that needs to be
solved.
In order to efficiently transform the data in Chinese electronic medical records into
structured information and deeply mine the rich diagnosis and treatment knowledge and clinical
experience contained in it, the main research contents of this article include:
(1) A named entity recognition algorithm for Chinese electronic medical records based on
the Ernie-BMAC model is proposed. This algorithm integrates the Ernie model's strong
semantic understanding capabilities and rich Chinese language resources. It also uses BiLSTM
to achieve efficient sequence modeling, ensuring accurate identification and meaning
determination of term boundaries, and uses CRF to achieve accurate sequence annotation of
medical record texts. By introducing a multi-head attention mechanism, it focuses on key
information and improves the ability to identify nested and complex entity relationships. Finally,
the effectiveness of the model proposed in this article was confirmed by conducting
comparative experiments and ablation experiments on the public data set CCKS2019.
III
(2) Based on the named entity recognition results and combined with the medical data
crawled from the web, entity relationships were extracted to generate triplet data. Subsequently,
a medical knowledge graph was constructed using the Neo4j graph database to present medical
information in a visual way, making it more intuitive and easy to understand. In addition, with
the help of the query function of the knowledge graph, an automatic question and answer system
is further implemented.
(3) Through the investigation of the needs of medical knowledge graphs and question and
answer systems, combined with the above research content, an integrated platform covering
medical knowledge graphs and intelligent consultation functions was designed and
implemented to visually display the research content of this article and provide Provide users
with intelligent medical question and answer services.
【
Key words
】:
Named Entity Recognition; Knowledge Graph; Graph Database
第1章 绪论
1.1 研究背景与意义
1.2
国内外研究现状
1.2.1
电子病历研究现状
电子病历作为医疗信息化的核心组成部分,已经在全球范围内成为推动医疗服务
现代化的关键力量。通过将个人健康状态和医疗保健信息以电子化形式管理,电子病
历不仅能够在医疗行业中替代传统的纸质病历作为核心的信息载体,同时也能适应诊
断、法规遵循及管理等多方面的需求。伴随着政策的大力支持和电子病历规范的不断
完善,医院电子病历系统的建设和应用迎来了空前的发展机遇。
国际上对电子病历的称谓及其内涵有着不同的理解,从电子病案、电子病历到电
子健康记录(
EHR
)和电子医疗记录(
EMR
),随着时间的推移,
EHR
和
EMR
已逐步
成为了国际上对电子病历较为一致的称谓
[2]
。在中国,根据
2021
年中国医院协会信息
管理专业委员会发布的《中国医院信息化状况调查
(2019-2020
年度
)
》报告,高达
86.14%
的医院认为电子病历系统是最关键的应用信息系统,反映出医院对医疗系统的重视程
度之高及其在未来医疗服务中不可取代的地位。
电子病历的建设不仅是满足国家卫生健康委员会电子病历评级要求的必要条件,
更是实现智慧医院建设的长期化需求。随着国家医药体制改革的不断深化和信息技术
的快速发展,医疗机构正不断加大对电子病历系统的建设和升级力度,以提升整体医
疗信息化程度,有效优化医疗资源分配格局,并进一步提高医疗服务的品质和运作效
率。电子病历系统的发展,不仅满足了现代医院发展的需求,也顺应了医疗信息化自
身发展的趋势以及患者对于高质量医疗服务的期待。
随着我国医药卫生体制的逐步深化调整及信息技术的不断进步发展,医疗机构
正着力于持续建设和革新电子病历系统,以此助推医疗信息化建设达到更高水准。
1.2.2 命名实体识别研究现状
对于命名实体的研究最早可以追溯到第七届
IEEE
人工智能应用会议上,由
Lisa F.
2
第 1 章 绪论
3
Rau
[3]
介绍了一个可以自动识别和抽取公司名的系统。而目前被大众所普遍使用的命名
实体识别(
Named Entity Recognition, NER
)
[4]
的概念是在第六届信息理解会议
(MUC-
6)
[5]
上被首次提出,其作为自然语言处理领域中的一个基础子任务,主要用于从非结构
化文本中识别出如人名、地名和各种专业术语等实体,并对这些实体进行更细致的分
类,自此实体命名识别进入快速发展期。
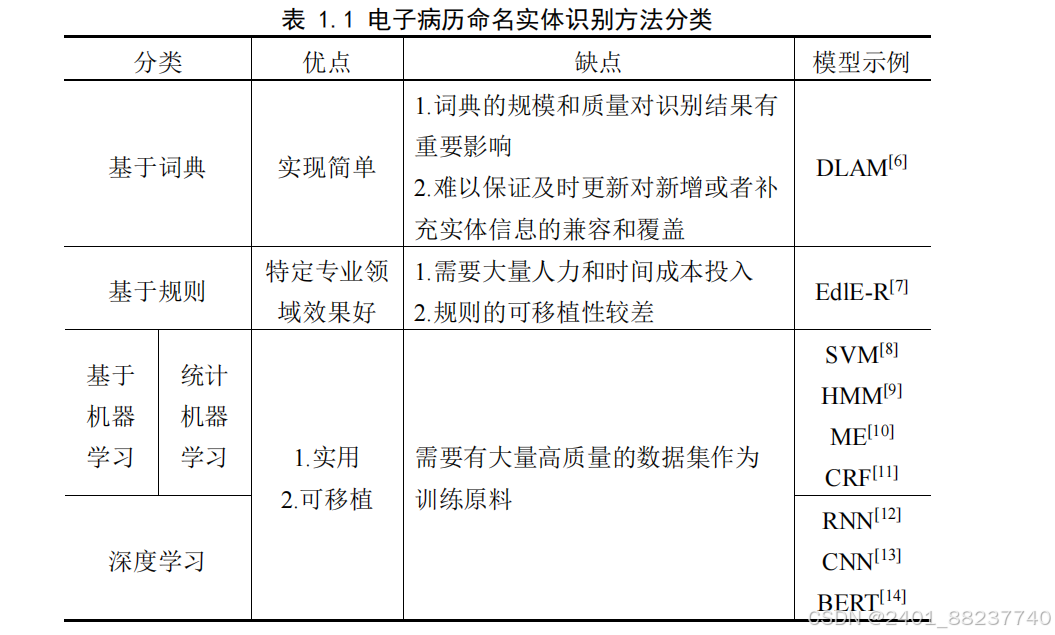
表 1.1 电子病历命名实体识别方法分类
分类
优点
缺点
模型示例
基于词典
实现简单
1.
词典的规模和质量对识别结果有
重要影响
2.
难以保证及时更新对新增或者补
充实体信息的兼容和覆盖
DLAM
[6]
基于规则
特定专业领
域效果好
1.
需要大量人力和时间成本投入
2.
规则的可移植性较差
EdlE-R
[7]
(
1
)基于规则和词典的方法
最初的命名实体识别研究采用基于规则和字典的方法,这些方法需要依靠语言学
家手工制定的规则和字典,以模式或者字符串相匹配为主要手段来识别实体名。在
MUC-6
会议中提出的系统大多使用基于规则的方法来实现实体识别、关系抽取、或指
代消解等任务。如其中
Kim
等人
[15]
提出的专用于解决语音识别的命名实体识别系统即
是使用基于规则的方式实现的。早期基于规则和词典的方法呈现出较好的效果,人工
编写的词典及规则易于理解和修改,且在专业领域中呈现出良好的识别效果。然而随
着时间的推移,一些新的词汇或者未知模式的出现,使得原先的词典或规则需要不停
进行人工修改,维护成本极高,且其在不同领域中的泛化能力不强,因此发展到今日,
这种方法只适用于部分资源受限的特定领域当中。
4
(
2
)基于传统的机器学习方法
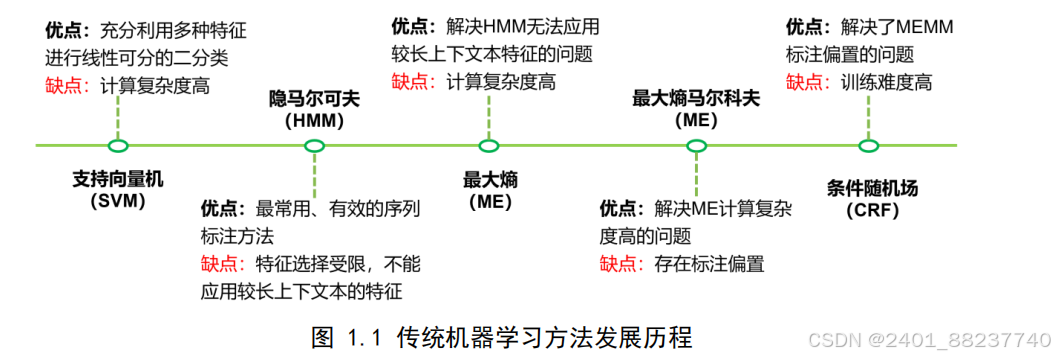
基于传统的机器学习方法将命名实体识别问题转化为分类或者序列标注问题,在
20
世纪末开始得到广泛应用。该方法基于统计概率的方法,提取文本中有用的特征,
如单词本身、词性标记、单词的语法结构、词缀信息、大小写信息等。该方法在数十
年的发展历程中涌现了不少经典的模型和方法,如:隐马尔科夫模型
[9]
(
Hidden
Markov Model, HMM
),通过建模上下文信息和序列数据,以及使用状态转移概率和观
测概率来识别文本中的实体,挖掘隐含的未知参数;最大熵模型
[10]
、是一种估计条件
概率分布模型,能够在给定的一些约束条件下估计出最符合观测数据的概率分布;以
及条件随机场
(Conditional Random Fields
,
CRF)
[11]
,是一种概率图模型,可以在模型的
输入中加入任意特征,其转化概率用特征函数替代,使用特征函数和模型参数来识别
文本中的实体。
基于传统的机器学习方法相较于基于规则和词典的方法,不需要预先设计好规则
和词典,只需要给出训练数据,分析其特征并选择模型即可完成训练,然而对于特征
的选择同样需要花费大量的时间对数据进行分析和处理,之后对于特征的组合方式同
样也是重要的一环,不同的特征组合会对识别结果造成严重的影响。这一阶段的研究
重点是如何设计有效的特征和选择合适的机器学习模型。传统机器学习方法相较于基
于规则的方法具有更好的泛化能力,但仍然依赖于繁琐的特征工程,并且对复杂语境
的处理能力有限。
图 1.1 传统机器学习方法发展历程
(
3
)基于深度学习的方法
1.3 本文研究内容
随着医疗信息化的深入推进,大量的电子病历数据积累成为医疗健康领域宝贵的
资源。然而,如何有效地从这些非结构化的病历数据中抽取出富有价值的信息,并进
一步利用这些信息支持医疗决策和研究,成为了亟待解决的问题。尤其是中文电子病
历,由于其特有的语言特性和专业术语的广泛使用,增加了信息提取的难度。
针对中文电子病历中信息提取的难点,本文提出了一种基于
Ernie-BMAC
的命名实
体识别模型,旨在提高中文电子病历文本中医疗实体的识别准确性和鲁棒性。该模型
通过
ERNIE
层提取丰富的语义信息、嵌入
BiLSTM
捕捉文本中的长距离依赖关系、并
引入多头注意力机制优化对关键信息的关注,最后通过
CRF
层优化标签序列的预测。
此外,本文设置多组对比实验和消融实验验证了其在中文电子病历实体识别任务上的
优异性能,从而证明了模型设计的有效性和合理性。
进一步地,本文整合中文电子病历实体识别结果与爬取的医疗数据资源,进行关
系抽取,获取到三元组数据,并输入到
Neo4j
图数据库中构建医疗知识图谱,同时基于
此图谱设计并实现了一套医疗知识图谱及问答系统。该系统通过需求分析、系统设计
到页面的可视化展示,全面展现了系统的实用性和交互性。
1.4
本文章节安排
本文内容主要分为以下五个章节:
第一章:绪论。首先,阐述当前电子病历研究面临的问题,及运用深度学习技术
提取中文电子病历实体的现实意义。其次,详细介绍了电子病历、命名实体识别及知
识图谱领域的国内外研究现状。最后,对本文的主要研究内容和各章节的工作安排进
行总结。
第二章:相关原理概述。对本文使用的相关理论知识进行详细介绍,包括实体识
别相关技术和知识图谱相关概念。其次对两种预训练模型进行比对研究,最后介绍本
文系统构建所涉及到的技术原理。
第三章:首先,提出一种基于
Ernie-BMAC
的中文电子病历命名实体识别模型,并
8
第 1 章 绪论
对该模型架构及每层的工作原理进行详细描述。通过在公开数据集
CCKS2019
上进行
实验,实验结果表明该模型在命名实体识别任务上的有效性。最后,设计对比实验与
消融实验,证明了
Ernie-BMAC
模型在中文电子病历命名实体识别任务上具有一定的效
果提升。
第四章:首先,将第三章中文电子病历命名实体识别结果进行实体对齐,保持实
体的一致性,同时联合网络爬取的医疗数据,实现实体关系抽取。进一步地,使用
Neo4j
图数据库对所抽取的实体及关系进行知识图谱的构建,并以可视化形式进行展示。
最后基于知识图谱实现问答架构,为第五章系统的实现提供基础。
第五章:基于第三章和第四章的研究成果,设计并开发了一套医疗知识图谱问答
系统。首先详述了该系统的功能性与非功能性需求,并对其进行概要设计,确定整体
架构。其次详细介绍系统各个模块的功能,同时设计数据库表。最后简要介绍了本系
统实现所依赖的环境,并进行前端可视化展示。
9
第 2 章 相关原
第2章 相关原理概述
2.1
实体识别相关技术
2.1.1
注意力机制
注意力机制
[34]
是一种重要的深度学习技术,最初在自然语言处理(
NLP
)领域获
得广泛应用,随后迅速扩展到计算机视觉、语音识别等其他领域。它的核心思想是在
模型的处理过程中,允许模型能够“专注”于输入数据的某些部分,而非对所有输入
赋予相同的权重。这种机制模仿了人类视觉的聚焦过程,即我们倾向于集中注意力于
视野中的某一部分细节,同时忽略其他不那么重要的信息。
在传统的神经网络模型中,每个输入都被平等对待,没有考虑到不同输入对模型
输出的贡献不同的情况。然而,在实际应用中,一些输入可能比其他输入更加重要。
以文本情感倾向分析为例,某些词语或短语可能比其他词语更能够准确反映文本的情
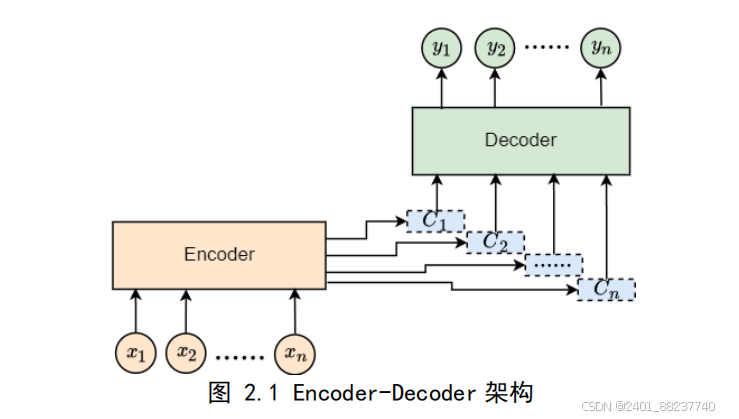
感倾向,因此应该受到更多的关注。为了解决这个问题,引入了注意力机制,它优化
了传统的
Encoder-Decoder
架构
[35]
,其中包括编码器和解码器两个环节。编码器将输入
序列转换成固定长度的向量,承载了输入序列的语义信息
[36]
。解码器接收该向量并生
成与之相关的输出序列。在引入注意力机制的编码
-
解码结构中,模型可以集中注意力
于对情感分析任务有重要意义的信息,例如文本中的关键词或短语。其框架图如图
2.1
所示:
图 2.1 Encoder-Decoder 架构
具体而言,注意力机制的工作过程主要包括以下三个步骤:
10
第 2 章 相关原理概述
第一步:计算当前词与上下文信息的相关程度,得到每个词的注意力权重。
第二步:使用前一层的输出结果进行处理,并归一化以获得文本信息的权重信息,
以此衡量每个输入位置的相对重要性。
第三步:将前一层的结果与
Value
值进行加权求和,得到最终的表示。这个加权后
的表示可用于下一层的输入,也可用于最终的输出。
通过应用
softmax
函数对计算得到的权重进行归一化处理,将权重转化为概率分布,
反映了每个词对文本分类的重要程度。概率值的大小表明了每个词在分类中的影响程
度,即概率值越大,词对分类的作用越重要。
2.1.2
长短期记忆网络
长短期记忆网络(
LSTM
)
[37]
是一种循环神经网络(
RNN
)的变体,由
Hochreiter
和
Schmidhuber
于
1997
年提出。它旨在解决标准
RNN
在处理长序列数据中遇到的长期
依赖问题。
LSTM
通过引入一种复杂的门控机制,能够在长序列中有效地保持信息,使
得网络能够学习到序列中相隔很远的依赖关系。
LSTM
的核心在于其复杂的内部架构,涉及三个关键的门控制单元:遗忘门、输入
门、输出门,以及细胞状态,这些元素协同作用,实现了对序列数据处理时信息流的
细致管理。
(
1
)遗忘门:决定哪些信息在细胞状态中应该被忽略或移除,通过分析当前的输
入和上一个时间点的输出生成一个介于
0
和
1
之间的权重,并将该权重乘以细胞状态,
从而决定了要保留的信息量。
(
2
)输入门:选择性地整合新信息进入细胞状态,其内部结构包括一个用于确定
更新权重的
sigmoid
层,以及一个用于生成潜在新状态候选值的
tanh
层。新产生的候选
值向量经由
sigmoid
层筛选后,被加权并整合至现有的细胞状态中。
(
3
)细胞状态:细胞状态在
LSTM
中扮演着穿越整个序列的角色,它可以随时接
收新的信息并添加或将现有信息移除。这种设计使得网络能够根据需要,灵活地保留
或遗忘信息,这一点对于捕获长距离的数据依赖非常关键。
(
4
)输出门:确定下一隐藏状态的内容,该隐藏状态携带着对当前输入的相关信
息,并用于预测接下来的输出。输出门通过对当前输入与前一时刻细胞状态的综合考
量,筛选出哪些信息应当作为当前时刻的输出内容。
LSTM
的操作可以通过一系列的数学公式来描述,其中
t
用于描述当前时间步,
𝑥
𝑡
12
代表当前时刻的输入,而
ℎ
𝑡−1
和
𝐶
𝑡−1
分别对应上一时间步的隐藏状态和细胞状态,具体
公式如下:
遗忘门:
𝑓
𝑡
= 𝜎(𝑊
𝑓
∙ [ℎ
𝑡−1
, 𝑥
𝑡
] + 𝑏
𝑓
)
(2 − 1)
输入门:
𝑖
𝑡
= 𝜎(𝑊
𝑖
∙ [ℎ
𝑡−1
, 𝑥
𝑡
] + 𝑏
𝑖
)
(2 − 2)
候选细胞状态:
𝐶̃
𝑡
= 𝑡𝑎𝑛ℎ(𝑊
𝐶
∙ [ℎ
𝑡−1
, 𝑥
𝑡
] + 𝑏
𝐶
)
(2 − 3)
新细胞状态:
𝐶
𝑡
= 𝑓
𝑡
∗ 𝐶
𝑡−1
+ 𝑖
𝑡
∗ 𝐶̃
𝑡
)
(2 − 4)
输出门:
𝑜
𝑡
= 𝜎(𝑊
𝑜
∙ [ℎ
𝑡−1
, 𝑥
𝑡
] + 𝑏
𝑜
)
(2 − 5)
新隐藏状态:
ℎ
𝑡
= 𝑜
𝑡
∗ tanh (𝐶
𝑡
)
(2 − 6)
2.1.3
随机条件场
条件随机场(
Conditional Random Field
,简称
CRF
)
[11]
是一种统计模型,专用于时
间序列数据的预测与分析,特别是在自然语言处理(
NLP
)和图像处理等领域中,用
于标注和分割序列数据。
CRF
属于判别模型类别,区别于生成模型(例如隐马尔可夫
模型,
HMM
),它直接建模条件概率分布,而非建模联合概率分布。
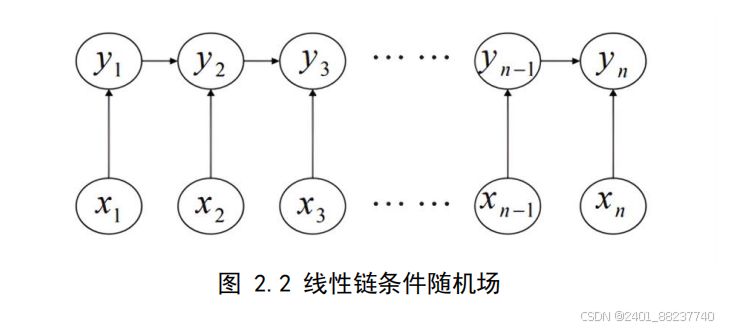
CRF
在数学上定义为一个无向图模型,其中每个顶点对应于序列中的一个输出标
签,而节点之间的连线则揭示了标签间的依赖关系。线性链条件随机场(
Linear Chain
CRF
)为最常见的表现形式中,如图
2.2
所示,模型采用线性链条状布局,每个位置上
的单元仅直接关联其前驱和后继单元,这样的构造适用于处理词性标注、命名实体抽
取等涉及顺序决策的标注任务。
图 2.2 线性链条件随机场
2.2
知识图谱概述
第 2 章 相关原理概述
知识图谱实质上是一种以图形结构组织的语义知识库,其核心目的是储存各类实
体(包括人物、地点、物品等)间的关联关系及其属性特征,并通过视觉化手段予以
展现。它通过节点(实体)和边(关系)的形式,构建起一个庞大的网络,使得计算
机和人类都能以更自然的方式理解和处理信息。接下来将从知识图谱的表示方式、存
储方式分别介绍知识图谱在构建过程中可能会涉及到的知识,以及本文使用到的
Neo4j
图数据库及知识图谱在医疗领域和其他方面的应用。
2.2.1
知识图谱的表示方式
知识图谱以图的形式来描绘和表达知识,利用节点和边来映射实体之间的多样化
关系。这种方法相较于简单图,能够描绘出更为复杂和细致的事物间联系,同时避免
了形式化逻辑带来的繁琐约束,大大简化了知识获取的过程。在将知识图谱应用于实
际场景时,不同的应用背景和需求会要求采用不同的图形表示方式。知识图谱的主要
表示方法有如下三种,分别为:属性图
[38]
、
RDF
图模型
[39]
及
OWL
本体语言
[40]
。
(
1
)属性图
属性图
[38]
是
Neo4j
图数据库中采用的一种图形化模型表示法,它构建了一种包含
节点、链接、标签、关系类型及属性元素的有向图形结构。其中,节点亦被称为实体
载体,用于承载具体实体信息;而关系或者说边,则是用于描绘实体间相互联系的纽
带,其始发点定义为源节点,终止点则为目标节点。边具有方向性,并且每条边均具
有特定类型,使得在图中能够实现双向或多向的导航和查询操作。属性则是以键值对
形式存在的附加信息,无论是节点还是边,都可以附带多个属性。在属性图中,节点
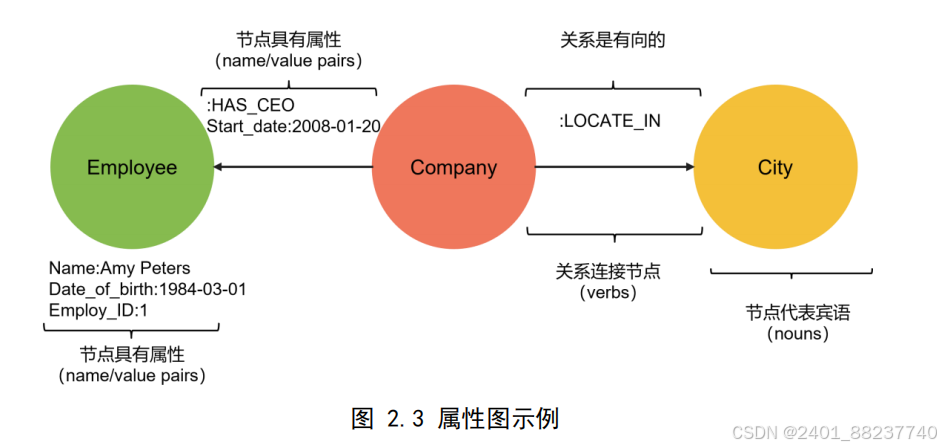
和关系构成了整个图表达的核心组成部分。如图
2.3
是属性图的一个示例。
属性图因其简洁的构造方式及便捷的实体属性与关系管理特性而受到广泛使用。
存储设计上,属性图巧妙地借助图结构进行了优化,从而显著提升了查询和计算效率。
但属性图领域目前缺少统一的标准查询语言,这使得不同系统间存在一定的兼容性难
题,同时它并不侧重于深层次语义逻辑的建模与推理支持。鉴于上述特点,属性图适
用于高度强调个性化配置和灵活应变的应用场合,例如社交网络研究、推荐算法开发
等领域。
图 2.3 属性图示例
(
2
)
RDF
图模型
RDF
(
Resource Description Framework
)
[39]
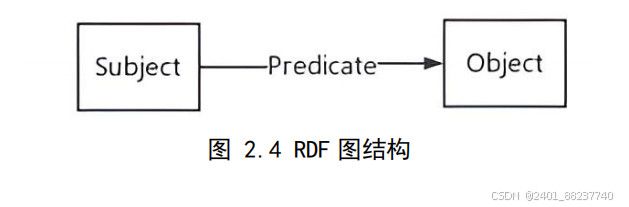
,也可称之为资源描述框架图。
RDF
图
数据模型主要由两部分关键元素构成:一是节点,二是边。节点相当于顶点,其代表
具有唯一标识符的资源实体,同样也可表示诸如字符串、数值等具象信息。另一方面,
边作为节点间的有向连接,也被视为谓词或属性指示器
[41]
,边的起点即为主语节点,
终点则为宾语节点,这样由一条边联结的两个节点共同构成了一个主语
-
谓词
-
宾语结构,
也就是所谓的
RDF
三元组。与属性图不同,在
RDF
中,扮演边角色的资源与扮演节点
角色的资源没有区别,因此一条语句中的边也可以是另一条语句中的节点。
RDF
图不同于属性图,
RDF
图有统一的标准进行约束,其技术栈的标准是由万维
网联盟
(W3C)
管理的,并且通过
URI
来唯一标识资源。因此每个支持
RDF
的数据库都
能够以同样的方式支持该模型,使得
RDF
图具有良好的跨平台和跨应用程序兼容性。
除此之外,
RDF
有一个标准的查询语言称为
SPARQL
[42]
。它既是一种功能齐全的查询
语言,又是一种
HTTP
协议
[43]
,可以通过
HTTP
将查询请求发送到端点,便于执行复杂
的查询。基于上述特点,可见
RDF
图模型适合需要强大标准化、易于数据集成和共享
的场景,如链接数据、语义
Web
应用等场景。
图 2.4 RDF 图结构
14
第 2 章 相关原理概述
15
(
3
)
OWL
本体语言
OWL
本体语言
[40]
在
2002
年由
W3C
发布,是一种用于定义和实现
Web
上的本体的
知识表示语言。本体指的是一组表示共享领域概念及其相互关系的形式化描述,它们
为特定领域的知识和信息提供了一个共同的理解框架。
OWL
本体语言更像是基于
RDF
词汇的一个扩展,添加了额外的预定义词汇,可以支持自动逻辑推理,这意味着其能
够通过逻辑推理引擎自动发现实体间的隐含关系,验证数据的一致性,并自动分类实
体到合适的类别中。同时
OWL
本体语言也继承了
RDF
图的特点,具有高度的兼容性
与可操作性,
OWL
本体能够轻松集成到现有的
Web
架构和数据中,促进了知识的共享
和重用,因此,
OWL
本体语言更适合需要复杂知识表示和逻辑推理的应用场景,如知
识管理系统、复杂决策支持系统等。但其也存在一些限制。首先,
OWL
的学习曲线相
对较高,需要对本体建模和逻辑推理有深入的理解。其次,复杂的逻辑推理可能在大
规模数据集上遇到性能瓶颈等。
2.2.2
知识图谱的存储方式
在构建和管理知识图谱时,选择合适的存储方式是至关重要的,因为它直接影响
到数据的存取效率、系统的扩展性以及未来的维护成本。目前,常见的知识图谱存储
方式主要包括图数据库和
RDF
存储,每种方法都有其独特的优势和局限性,适用于不
同的应用场景,表
2.1
对比了图数据库和
RDF
存储的不同特性。
表 2.1 RDF 与图数据库特性对比
RDF
存储
图数据库
存储三元组(
Triple
)
节点和关系可以带有属性
标注的推理引擎
没有标准的推理引擎
W3C
标准
图的遍历效率高
易于发布数据
事务管理
(
1
)图数据库
图数据库作为数据管理系统,旨在高效存储和处理图形化数据,采用图形范式执
行查询操作。其中的数据以节点、关联边和属性的形式被组织,并持久化保存,且其
支持对数据进行增、删、改和检索等一系列基本操作。图数据库的最大优势是能够高
效处理复杂的图遍历和路径查询,非常适用于表示和查询复杂的实体关系网络。此外,
图数据库直观的数据模型使得数据关系的表达和查询更为直接和灵活。但是,图数据
库相较于关系数据库在技术生态和社区支持方面可能稍显不足。
(
2
)
RDF
存储
又称为三元组存储,是一种专门用于存储
RDF
格式数据的存储系统。
RDF
存储的
优势在于其强大的标准化和互操作性,支持复杂的语义查询语言
SPARQL
,非常适合
于构建语义
Web
和实现数据的跨域集成。然而,
RDF
存储的学习曲线相对较高,并且
在处理非
RDF
格式数据时可能需要额外的转换工作。
2.2.3 Neo4j
图数据库
Neo4j
[44]
是一款专门针对密集关联数据优化设计的高性能非关系型数据库,它以图
的形式存储和查询数据,专为处理高度连接的数据而设计。与传统的关系数据库相比,
Neo4j
在处理复杂关系和动态网络时显示出更高的效率和灵活性。其数据以节点、关系
及属性的组合形式进行表述和存储,其中节点用于体现具体实体,关系模拟实体间的
相互关联,而属性则负责赋予节点和关系间的描述信息。其核心特性如下所示:
(
1
)
Neo4j
使用图形存储结构,通过在节点之间直接建立关系,使得深度查询和
图遍历变得十分高效。
(
2
)
Neo4j
提供了一种声明式图查询语言
Cypher
,可用直观的方式编写复杂的图
形查询和数据操作语句
[45]
。
(
3
)
Neo4j
支持完整的
ACID
事务,保证数据的一致性和完整性。
(
4
)支持主从复制和分片,确保数据的高可用性和伸缩性。
(
5
)提供了
REST API
、
Java API
等多种方式访问数据库,同时支持多种编程语言
的客户端库,如
Python
、
JavaScript
、
.NET
等。
2.2.4 知识图谱的应用
知识图谱的构建不仅只是用于将数据以图的形式进行存储,随着对知识图谱作用
的进一步挖掘,逐渐发掘出知识图谱在多个方面的应用,下面是目前几类知识图谱应
用的热门领域:
(
1
)智能问答:在智能问答系统中,知识图谱作为一种强大的信息源,能够帮助
机器理解用户的查询意图,并快速准确地提供答案。通过分析和理解知识图谱中的实
体、属性及它们之间的关系,系统能够对复杂的问题进行推理,从而提供更加精准和
16
第 2 章 相关原理概述
丰富的回答。该应用不只限于通用的问答系统,还能够扩展到专业领域,如医疗诊断、
法律咨询等。
(
2
)智能推荐:知识图谱在智能推荐系统中的应用,能够显著提升推荐的准确性
和个性化程度
[46]
。它通过分析用户的行为和偏好,结合实体间的关系,为用户推荐相
关的商品、内容或服务。例如,在电商平台上,知识图谱可以帮助系统理解商品间的
相似性和关联性,进而向用户推荐他们可能感兴趣的商品。在内容推荐方面,如新闻、
视频和音乐,知识图谱同样能够提供个性化的推荐列表,增强用户体验。
(
3
)搜索引擎优化:知识图谱为搜索引擎提供了一种理解查询意图和提升搜索结
果相关性的方法。通过分析查询与知识图谱中实体和关系的匹配度,搜索引擎能够提
供更加准确和丰富的搜索结果。此外,知识图谱还支持语义搜索,即理解查询的深层
含义而非仅依赖关键词匹配,从而显著提高用户的搜索满意度。
(
4
)物联网(
IoT
):在物联网领域,知识图谱的应用为管理和分析庞大的设备数
据提供了强有力的支持。通过将设备、传感器和它们产生的数据以及相互之间的关系
建模为知识图谱,可以更有效地实现设备管理、状态监控、故障预测和维护策略制定。
此外,知识图谱还可以支持更复杂的应用场景,如智能家居、智能城市和工业
4.0
,通
过深度理解设备间的相互作用和环境因素,实现更加智能和高效的运营管理。
2.3
预训练模型
2.3.1 Bert
模型
在自然语言处理领域,
Bert
[47]
(
Bidirectional Encoder Representations from Transform
ers
)作为一种前沿的预训练模型技术,由
Google
的研究团队于
2018
年提出。模型首先
通过在海量文本数据上进行预训练,学习到丰富的语言表示,随后可以针对具体的自
然语言处理任务进行微调,因此能够在多个应用场景中展现出优异的表现。
Bert
模型
结构如图
2.5
所示,其中
𝐸
𝑖
代表输入向量,由三部分组合而成,分别是词向量嵌入、分
隔嵌入和位置嵌入,中间的
Trm
代表
Transformer
的处理单元,
T
则代表输出。
图 2.5 Bert 结构图
Bert
模型采用双向
Transformer
编码器,这是一种基于注意力机制的架构,用于理
解文本数据中的复杂上下文关系。其次它采用了掩码语言模型(
MLM
)和下一句预测
(
NSP
)这两种预训练方式
[48]
。在
MLM
任务中,
Bert
通过随机隐藏输入文本中的一些
词汇,并尝试预测被掩盖的词汇,从而使模型学习到词语之间深层次的双向上下文关
系。而
NSP
任务通过判断两个句子是否顺序相连来训练模型,有助于提升模型理解句
子间逻辑联系方面的能力。为优化模型对句子辨识的效果,在输入模型前,首句起始
处添加
[CLS]
标识,句尾处加入
[SEP]
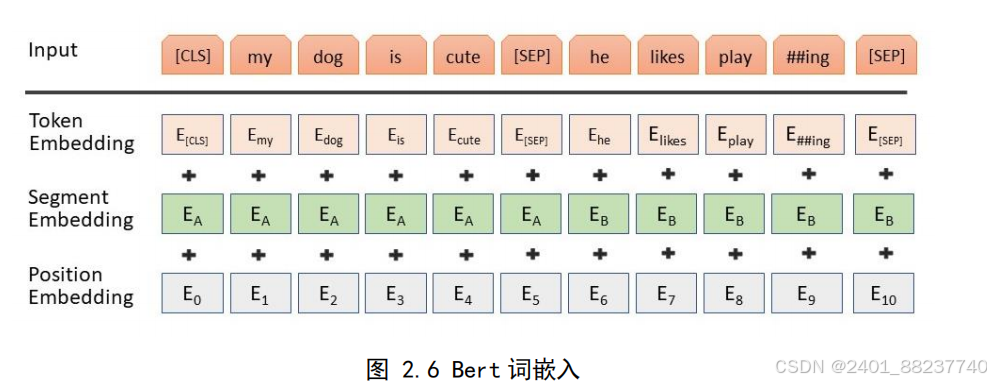
标识。每个句子经过字符嵌入(
Token Embedding
)、
句子嵌入(
Sentence Embedding
)、位置嵌入(
Positional Embedding
)处理后融入各标识。
字符嵌入描绘了单个字符的向量化表示,句子嵌入明确了句子的序号,位置嵌入则记
录了字符在句中的具体位置,具体嵌入表示如图
2.6
所示。
图 2.6 Bert 词嵌入
通过这种预训练和微调的策略,
Bert
能够在自然语言处理任务上达到较好的实现
18
第 2 章 相关原理概述
效果,包括但不限于文本分类、情感分析、问答和命名实体识别。这种性能的提升归
功于
Bert
能够捕捉到的深层次的双向上下文信息,这些信息对于理解语言的复杂性至
关重要。
Bert
模型的成功不仅体现在它在各种评测任务上取得的突破性成绩,同时也因为
它开辟了使用大规模预训练模型来改进自然语言处理性能的新途径。自
Bert
问世以来,
众多基于类似思想的模型相继被提出,如
RoBERTa
、
Albert
和
Ernie
等,它们在不同方
面对
Bert
的基本架构进行了改进和优化。这些发展表明,预训练模型已经成为提升自
然语言处理任务性能的关键技术之一,为未来的研究和应用开辟了新的方向。
2.3.2 Ernie
与
Bert
模型对比
Ernie
(
Enhanced Representation through Knowledge Integration
)模型
[49]
是
2019
年由
百度提出的一种自然语言处理预训练技术,该模型通过整合丰富的外部知识,比如实
体、关系和属性等信息,来增强模型对文本的理解能力。尽管
Ernie
与
Bert
都是基于
Transformer
的预训练语言模型,但
Ernie
在知识整合、预训练任务及掩码策略上都略有
不同。
Ernie
的特点之一就是其将外部知识(如知识图谱中的实体和关系)整合到模型中。
这种方法使
Ernie
能够理解更丰富的语义信息和实体间的逻辑关系,特别是在需要广泛
背景知识的任务上表现更佳。而
Bert
主要依赖于文本本身的信息,通过大规模语料库
上的预训练学习语言的深层次特征,但没有直接整合外部知识。在预训练任务方面,
Ernie
模型除了使用类似
Bert
的掩码语言模型(
MLM
)和下一句预测(
NSP
)任务外,
还引入了知识相关的预训练任务,如实体级的掩码任务,这有助于模型更好地学习和
理解实体及其属性。
掩码方式是
Ernie
模型与
Bert
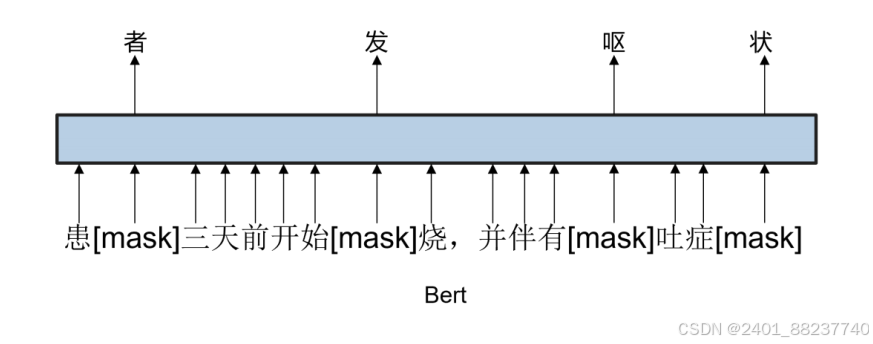
模型的最大区别,在处理中文文本时,由于缺乏明确
的分词符号,
Bert
仅能对单个汉字进行掩码,这限制了其对于更广泛上下文的学习
[50]
。
相反,
Ernie
引入了一种动态掩码机制,这一机制不仅识别单个字,还能识别并遮蔽完
整的短语或实体。这种方法使
Ernie
能够在理解文本的过程中,吸收短语和实体级的知
识,从而捕捉到文本的全面语义。如图
2.7
所示,
Bert
关注于单字之间关系,对“发”,
“呕”等字进行遮蔽,而
Ernie
则进行字掩码、词掩码和实体掩码三种级别的掩码,能
够遮蔽如
“
发烧
”
、
“
呕吐
”
等完整的语义实体,使模型能够理解整个概念的语义含义。这
种精细化的掩码方法让
Ernie
在理解文本语义时具有更深层次的理解能力。
1
20
图 2.7 Bert 与 Ernie 掩码策略对比 2.4 系
统相关技术 2.4.1 Vue 框架
统相关技术 2.4.1 Vue 框架
Vue
框架设计遵循自下而上的模块化扩展原则,使其不仅能够有力支撑复杂单页应
用的构建,还利于嵌入已有的项目环境中。此外,
Vue
凭借其易学的特性和轻量化架构,
大大加快了开发者的学习曲线,使得开发者能迅速熟悉并有效地投入实际项目开发工
作中。其核心库专注于视图层的精炼设计,更是方便开发者快速掌握
Vue
的核心要领,
加速项目的启动与迭代过程。
Vue
的优点主要有以下几个方面:
(
1
)响应式系统:
Vue
的响应式机制具备自动检测数据并在数据变动时即时刷新
视图的能力,这一特点让开发者能够采用声明式的方式来控制
DOM
的更新操作。
(
2
)组件化:
Vue
鼓励通过可复用的组件来构建应用界面,每个组件都有自己的
视图和数据逻辑,这有助于提升项目的可维护性和复用性。
(
3
)虚拟
DOM
:
Vue
使用虚拟
DOM
来优化
DOM
操作,只对发生变化的部分进
行实际的
DOM
更新,从而提高应用性能
[51]
。
第 2 章 相关原理概述
(
4
)指令系统:
Vue
提供了一系列内置的指令(如
v-if
、
v-for
、
v-bind
、
v-model
等),简化了
HTML
模板中的动态行为的实现。
(
5
)过渡效果:
Vue
提供了一套系统化的过渡效果解决方案,使得开发者能够便
捷地为组件添加进出页面时的过渡动画以及列表项的动画效果。
考虑到
Vue
框架所提供的众多优势,包括其易于上手的学习曲线、高效的数据处
理能力、渐进式的架构特性、活跃的社区支持以及出色的性能和优化机制,本文第五
章的系统决定采用
Vue
框架进行前端开发实现。
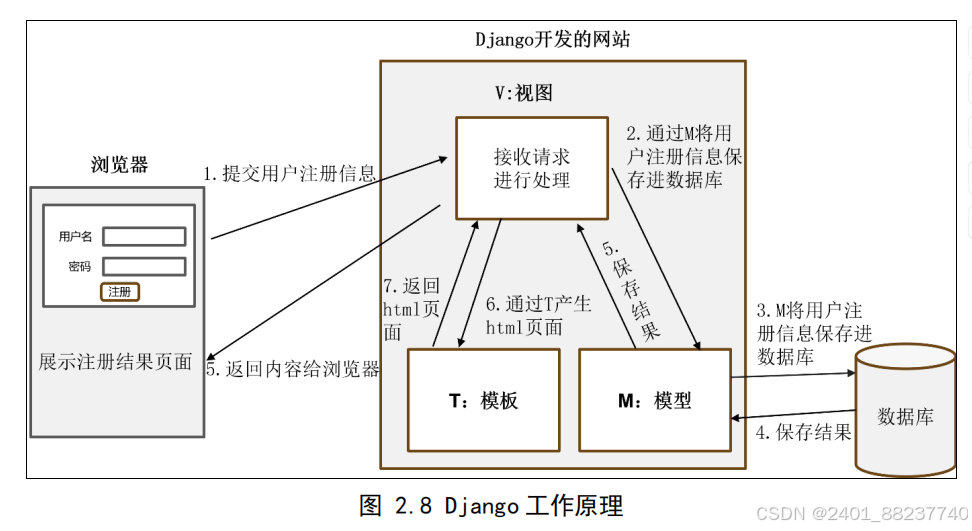
2.4.2 Django
框架
Django
是一个建立在
Python
之上的
Web
开发框架,它使得开发者通过编写较少的
代码,轻松实现正式网站所需的大多数功能,并且可以进一步扩展为完整
Web
服务功
能的应用。
在当前广泛使用的
Python Web
框架中,
Django
与
Flask
颇受欢迎。相比之下,
Django
自带众多功能组件,极大简化了开发流程;同时,
Django
还内置了对象关系映
射(
ORM
)系统,这使得开发者可以用面向对象的方法直接操作数据库,无需手写
SQL
语句。
Django
的
ORM
支持多种数据库类型,并提供数据库迁移工具,简化了数据
库变更的管理过程。而
Flask
默认不包含
ORM
功能,通常需要借助
SQLAlchemy
或第
三方
ORM
工具来实现。
Django
采用
MVT
(模型
-
视图
-
模板)设计模式,虽与常见的
MVC
(模型
-
视图
-
控
制器)架构有所类似,但二者在实现上存在区别
[52]
。在这种设计模式下,模型(
Model
)
承担着数据处理和数据库交互的职责,与
MVC
架构中的模型角色一致;视图(
View
)
层接收并处理用户请求,执行业务逻辑,并返回适当的响应,这在某种程度上类似于
MVC
中的控制器;而模板(
Template
)负责呈现数据,通过渲染
HTML
,起到了
MVC
中视图的作用。这种划分确保了代码的高内聚性和低耦合性,使得开发和维护工作变
得更加高效和直观。以用户注册行为为例
Django
的工作原理如图
2.8
所示。
图 2.8 Django 工作原理
2.5 本章小结
本章主要介绍本文所设计到技术的相关原理,首先介绍在电子病历实体命名识别
任务中的相关技术,其次介绍了知识图谱的一系列概念,从其基本概念逐步深入到其
表示方式、存储结构及其在不同领域的应用等;随后介绍了两种预训练模型,并对二
者进行对比;最后介绍本文所构建系统所需的前端及后端框架。

第3章 基于 Ernie-BMAC 的电子病历实体命名识别算法
3.1
引言
随着人工智能技术的迅猛发展,自然语言处理(
NLP
)在医疗健康领域的应用愈
加广泛,尤其体现在电子病历的信息提取与处理方面。电子病历作为记录患者健康信
息的重要文档,包含了丰富的医疗数据,如症状、诊断、治疗过程等,对于疾病诊断、
医疗决策支持及临床研究具有极高的价值。尽管目前中文电子病历实体命名识别算法
在实际应用中取得了一定的进展,但仍面临诸多问题,如:嵌套实体抽取困难,中文
边界不清等,限制了命名实体识别技术的效率和准确性,进而影响了医疗数据的进一
步应用。
针对上述问题,本文提出了一种名为
Ernie-BMAC
的算法。该方法利用
Ernie
模型
在中文文本处理方面的优势,更好地理解文本的语义,确定中文实体边界。同时其动
态掩码机制能够捕捉完整的短语或实体,更好的捕捉上下文关系。通过综合考虑上下
文语义和利用
BiLSTM
的序列建模能力,模型能够更准确地确定术语的边界并选择正
确的含义。此外,引入了
CRF
模型,将实体抽取任务视为序列标注问题,并考虑了标
签之间的依赖关系。这种综合上下文信息和标签依赖性的方法有助于提高中文实体边
界的准确性。为了更好地捕捉嵌套实体之间的关系,算法引入多头注意力机制,使模
型能够同时关注不同层次的语义信息。
本章将详细阐述所提出的模型在中文电子病历命名实体识别任务中的实现流程、
实验环境的搭建、数据处理方法以及实验结果的详细分析,以验证该模型的有效性和
实用性。
3.2
模型设计
本节将详细介绍
Ernie-BMAC
模型,并对其主要组成部分进行分析,其模型架构如
图
3.1
所示:
输入层:以句子为单位将样本输入到模型中;
嵌入层:使用
Ernie
预训练模型表示输入句子,以获得包含丰富隐式信息的基于上
下文的词向量;
编码层:通过双向长短期记忆网络来捕捉序列数据的依赖性,并选择高阶特征进
行集成;
注意力层:对序列中的不同部分赋予不同的权重,使模型能够聚焦于当前任务中
最为核心的信息部分;
解码层:对序列中的标签进行解码,考虑相邻标签间的依赖关系,优化整个序列
的标注结果;
输出层:输出最终的标签序列。
图 3.1 Ernie-BMAC 模型架构图
3.2.1
嵌入层
Ernie
模型是一种基于
Transformer
的预训练语言模型,特别针对中文语言处理进行
了优化。在中文电子病历命名实体识别任务中,
Ernie
通过融合丰富的语言和世界知识,
24
第 3 章 基于 Ernie-BMAC 的电子病历实体命名识别算法
25
为文本提供深层次的语义表示。
本层首先接收分词后的输入(
token
序列)。对每个
token
,模型通过词嵌入将其转
换为向量表示,并加上位置编码以保留序列中的顺序信息,表示为
X = {𝑥
1
, 𝑥
2
, … , 𝑥
𝑛
}
,
其中
X
是加上位置向量后的输入向量序列,
𝑥
𝑖
代表序列中第
𝑖
个
token
的向量表示。接着
将
X
通过三组不同的权重矩阵转换为查询(
Q
)、键(
K
)和值(
V
)
:
𝑄 = 𝐸W
Q
,𝐾 = 𝐸W
K
, 𝑉 = 𝐸W
V
(3 − 1)
计算自注意力权重并应用到值(
V
)上
:
Attention(𝑄,𝐾, 𝑉) = softmax ( 𝑄𝐾
𝑇
√𝑑
𝑘
) 𝑉
(3 − 2)
将上述公式的结果加上输入向量进行残差连接,并进行层归一化,能够避免在深
层网络中梯度消失或爆炸的问题,并且使得不同层之间的学习更加独立:
H = LayerNorm(E + Attetion(𝑄,𝐾, 𝑉))
(3 − 3)
上述公式中的输出
H
接下来被送入前馈神经网络,每个位置的向量都独立地通过
相同的网络:
𝐹𝐹𝐻(ℎ) = max(0, ℎ𝑊
1
+ 𝑏
1
)𝑊
2
+ 𝑏
2
(3 − 4)
通过上述流程,
Ernie
能够获取每个词与文本中其他词之间的关系,提供丰富的上
下文相关的词向量,该能力使
Ernie
在处理语义复杂度高的文本时尤其有效。在中文电
子病历
NER
任务中,
Ernie
的预训练语义表示能够有效地捕捉医疗术语和专业表达的细
微差异,以及其在特定上下文中的意义。对于准确识别和分类电子病历文本中的医疗
实体至关重要。相比于传统的词向量方法,
Ernie
能够提供更加精细、语义丰富的特征
表示,从而显著提高实体识别的准确率和效率。
3.2.2
编码层
作为一种特殊化的循环神经网络(
RNN
)变体,双向长短期忆(
BiLSTM
)网络专
用于对序列数据进行有效处理,通过考虑序列中每个元素的上下文信息捕获长期依赖
关系。
长短期记忆(
LSTM
)单元包含三个特殊设计的门(输入门、遗忘门和输出门),
用于按顺序控制信息传输,能够克服传统
RNN
在训练阶段遇到的梯度消失与梯度爆炸
的问题,并展现出卓越的序列建模性能,更加出色地捕捉并建模远距离依赖关系
[53]
。
BiLSTM
则包括正向和反向两个
LSTM
网络,分别捕获前向和后向的上下文信息,其最
终输出为两个方向上的隐藏状态的拼接。使得模型能够同时考虑到每个词前面和后面
的信息,为序列中的每个词提供一个全面的上下文表示。
BiLSTM
层在
NER
标注中充当序列编码器,将输入
𝑥 = {𝑥
1
, 𝑥
2
, … , 𝑥
𝑛
}
句子的词向量
序列输入到
BiLSTM
网络中进行特征提取。输出标签序列
𝑦 = {𝑦
1
, 𝑦
2
, … , 𝑦
𝑛
}
对应每个
token
的概率,
n
为标签的个数。具体来说,
ERNIE
的词向量序列输出使用
BiLSTM
网
络进行编码。正向
LSTM
网络获取正向隐藏状态(历史特征),反向
LSTM
网络获取反
向隐藏状态(未来特征)。
BiLSTM
网络隐藏层的输出表示为:
ℎ = 𝐿𝑆𝑇𝑀 ⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗( ⃗⃗𝑥 ⃗⃗⃗) + 𝐿𝑆𝑇𝑀 ⃖⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗⃗( ⃗⃗𝑥 ⃗⃗⃗) ⃗
(3 − 5)
在中文电子病历
NER
任务中,
BiLSTM
能够有效地处理医疗文本的序列特性,特
别是在捕获长距离依赖关系方面表现出色,对于理解复杂的医疗术语和实体在文本中
的使用上下文极为重要。通过
BiLSTM
编码,模型得以更准确地界定实体边界,获取
实体间关系,进而增强了实体识别的精度与召回效果。
3.2.3
注意力层
尽管编码层中的
BiLSTM
能够捕捉句子的上下文信息,但却不足以强调上下文中
的关键要素。为了解决
BiLSTM
在上下文信息加权方面的局限性,引入了多头注意力
机制。多头注意力机制(
Muti-Attention
)是对单一注意力机制(
Attention
)的扩展。
它将注意力机制分成多个头,每个头在不同的表示子空间中学习输入的不同部分。通
过上述方式,模型能够同时在多个表示子空间中提取信息,从而增加了信息使用效率
和模型的解释力。多头注意力机制由单一注意力机制而成,其实现流程如下述公式所
示:
ℎ𝑒𝑎𝑑
𝑖
= 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄𝑊
𝑖 𝑄
,𝐾𝑊
𝑖 𝐾
, 𝑉𝑊
𝑖 𝑉
)
(3 − 6)
𝑀𝑢𝑡𝑖𝐻𝑒𝑎𝑑(𝑄, 𝐾, 𝑉) = 𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑒𝑎𝑑
1
, ℎ𝑒𝑎𝑑
2
, … , ℎ𝑒𝑎𝑑
𝑛
)𝑊
𝑂
(3 − 7)
其中
𝐶𝑜𝑛𝑐𝑎𝑡
用于表示连接操作,
𝑊
𝑂
为可学习的权重矩阵,用于将多头的输出整合
成一个统一的表示。
依托多头注意力机制,模型能够自动识别并关注那些对实体识别最为重要的词汇
和句子成分,如医疗术语或症状描述,忽略相对不重要的信息。该能力对处理长文本
和复杂句子结构的电子病历数据,有着显著的性能,提高了实体识别的准确率和效率。
第 3 章 基于 Ernie-BMAC 的电子病历实体命名识别算法
27
3.2.4
解码层
条件随机场(
Conditional Random Field, CRF
)是一种用于数据标注任务的统计建
模方法。
CRF
层通常被应用于模型的输出层,用于学习序列中元素的依赖关系,优化
整个序列的标注结果。
尽管编码层与解码层能够处理远距离文本信息并获得更多用于实体分类的关键特
征,但相邻标签之间的依赖关系没有得到有效处理。上层整合的特征表示被传递到
CRF
层,在此层中,序列中每个元素的特征表示被用来计算在标签空间中的位置,同
时考虑到了序列中标签的转移概率。
CRF
层输出的分数矩阵
𝑃
与转移分数矩阵
A
结合,
共同决定了最终的标签序列
𝑦
。
CRF
层的输出过程可以用下面的公式表示:
𝑆𝑐𝑜𝑟𝑒(𝑦|𝑥) = ∑ 𝐴
𝑦
𝑖
,𝑦
𝑖+1
+
𝑛 𝑖=0
∑ 𝑃
𝑖,𝑦
𝑖
𝑛 𝑖=1
(3 − 8)
其中
𝑃
为
𝑡 ∗ 𝑛
维的矩阵,
𝑡
指代句子中词的个数,
𝑛
代表标签的总数。矩阵的元素
𝑃
𝑖,𝑗
用于表示句子中第
𝑖
个词对应第
𝑗
个标签的得分
[54]
,这些得分反映了模型认为某个词
属于某个标签的可能性有多高。用
𝐴
𝑖,𝑗
记录从标签
𝑖
转移到标签
𝑗
的得分,
𝑦
0
标志句子的
开始标签,
𝑦
𝑛+1
为结束标签,这意味着模型不仅预测句子中每个词的标签,还特别用
两个标签标记句子的开始和结束。因此,转移得分矩阵
𝐴
的大小是
2𝑛 + 2
,以包含这两
个额外的标签。
CRF
模型为每个元素分配最合适的标签,从而在全局范围内优化序列标注的一致
性和准确性。同时,
CRF
层的引入使得模型在输出标签序列时,不仅仅考虑单个词的
特征,还考虑了标签之间的约束关系,如
BIO
(
Begin, Inside, Outside
)标注规则。这种
全局优化策略,对于准确识别电子病历中的复杂实体和嵌套实体结构尤为重要,显著
提升了实体识别的精度和鲁棒性。
3.3
实验设置与结果分析
本节主要介绍基于
Ernie-BMAC
模型的中文电子病历命名实体识别方法的实验部分。
首先对数据集进行数据预处理,并对实验环境和部分实验参数设置进行说明;其次通
过对比实验和消融实验,分析了该模型在中文电子病历命名实体识别任务中的性能。
28
本模型的实验环境设置如表
3.1
所示:
表 3.1 实验环境
实验环境名称
配置
处理器(
CPU
)
Intel(R) Xeon(R) @ 2.10GHz
图形处理器(
GPU
)
RTX 4090(24GB)
内存
24GB
Python
3.8
Pytorch
1.10.0
操作系统
Ubuntu 20.04
3.3.2
实验数据集及序列标注
实验采用
CCKS2019
中面向中文电子病历实体识别测评任务的数据集,
CCKS
是由
中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议,其中实体识
别任务的数据集由清华大学知识工程实验室联合医渡云北京科技有限公司组织进行数
据标注,并进行严格脱敏处理
[55]
。该数据集共含有已标注样本
1379
条,分为
1000
条训
练样本和
379
条测试样本,涵盖六种不同的实体类型。其中各类别实体的数量统计如表
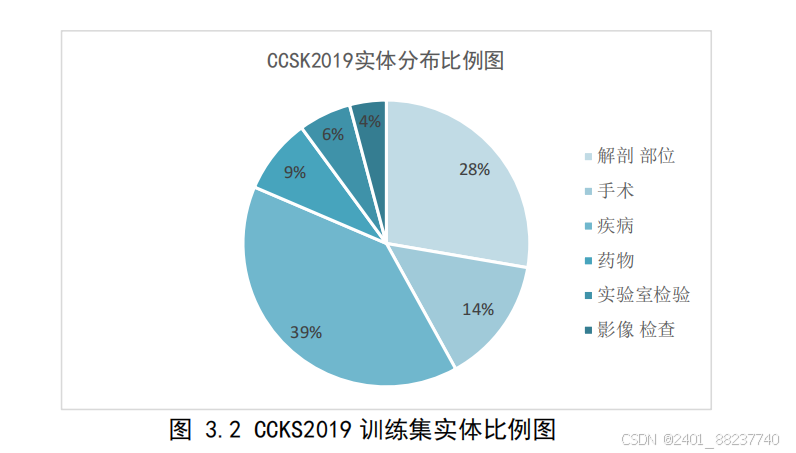
3.2
所示,各实体数量在训练集总数中所占比例如图
3.2
所示:
表 3.2 CCKS2019 实体数量统计
数据集
解剖
部位
手术
疾病和
诊断
药物
实验室
检验
影像
检查
总计
训练集
1486
765
2116
456
318
222
5363
测试集
447
140
682
263
193
91
1816
总计
1933
905
2798
719
511
313
7179
各实体含义定义如下:
(
1
)疾病和诊断(
disease
):在医学领域内界定的各种病态及医师在日常诊疗活
动中对疾病原因、生理变化、分类及阶段的评估。
(
2
)影像检查
(examination)
:包括但不限于
X
射线、计算机断层扫描(
CT
)、磁
共振成像(
MRI
)、以及正电子发射断层摄影与计算机断层扫描结合技术(
PET/CT
)在
内的多种非侵入性影像学诊断方式,连同造影技术与超声检查均在讨论范围内
[56]
。值
第 3 章 基于 Ernie-BMAC 的电子病历实体命名识别算法
29
得注意的是,本阐述特指无需进行身体侵入的操作,因而像胃镜或肠镜这类内窥镜检
查并不在此列。
(
3
)实验室检验(
check
):具体指代在临床实践中,由检验科室实施的标本化验
工作,这一范畴不涵盖免疫组化等更广泛定义下的实验室检测项目。
(
4
)手术
(operation)
:医师对患者特定身体部位实施的切割、缝合等物理治疗行
为,为外科治疗的核心手段。
(
5
)药物
(medicine)
:指用于治疗疾病的具体化学制剂。
(
6
)解剖部位
(body)
:指疾病、症状和体征发生的人体解剖学部位
[57]
。
图 3.2 CCKS2019 训练集实体比例图
本研究使用
BIO
(
B-
表示开始,
I-
表示内部,
O-
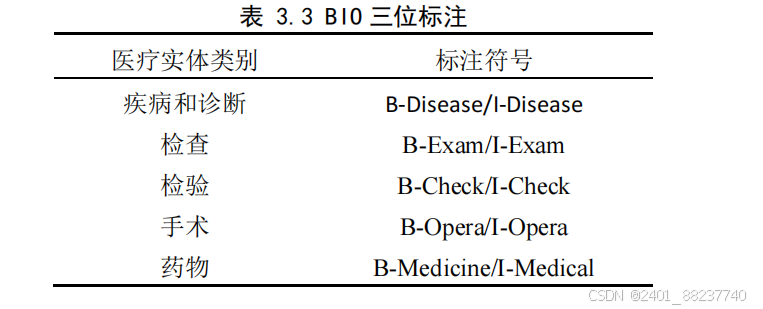
表示外部)标注方法对文本数据进
行了注解
[58]
。在此方案中,
B-X
用于标识命名实体
X
的起始部分,
I-X
用于指示命名实
体的中间或末尾部分,而
O
则用来表示那些不属于任何命名实体类别的文本部分,即
非实体内容。本研究数据共有
13
种待预测标签,如“
B-Disease
”
,
“
I-Disease
”
,
“
O
”
等,具体标注类别及符号如表
3.3
所示:
表 3.3 BIO 三位标注
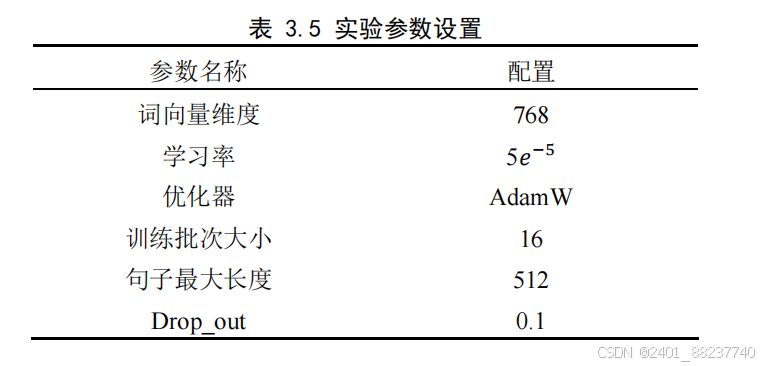
0.1
表
3.6
展示了所提模型在
CCKS2019
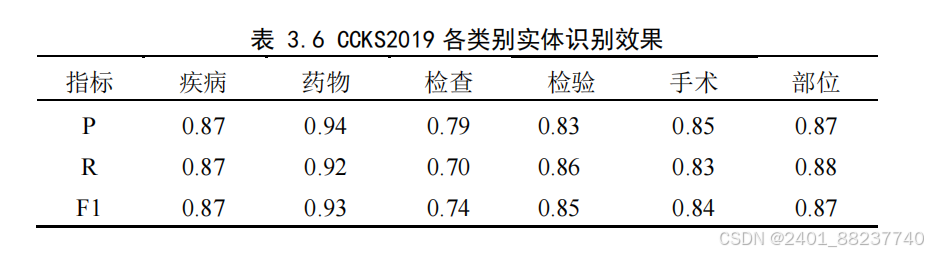
数据集上对各类实体的识别效果,从表中数据
可以看出,不同类别的实体识别结果差异较大。其中“影像检查”的
𝐹
1
值最低,原因
是检查类实体在数据集中比例较少,且检查类别在真实医疗场景记录下表达方式可能
更加多样化和复杂。如“
CT
扫描”可能被记录为“计算机断层成像”、“
CT
”、“头部
CT
”等多种变体,此种表达上的多样性增加了实体识别的难度。同时,结果的表述
(如数值、单位、正负性等)在文本中的多样性和不规范性将增加实体识别难度;药
物实体的识别效果最优,因为药物实体通常具有较为固定和规范的命名方式,如药品
名称、剂量单位等,上述特征较为明显,易于通过规则或学习模型进行识别。
表 3.6 CCKS2019 各类别实体识别效果
指标
图
3.3
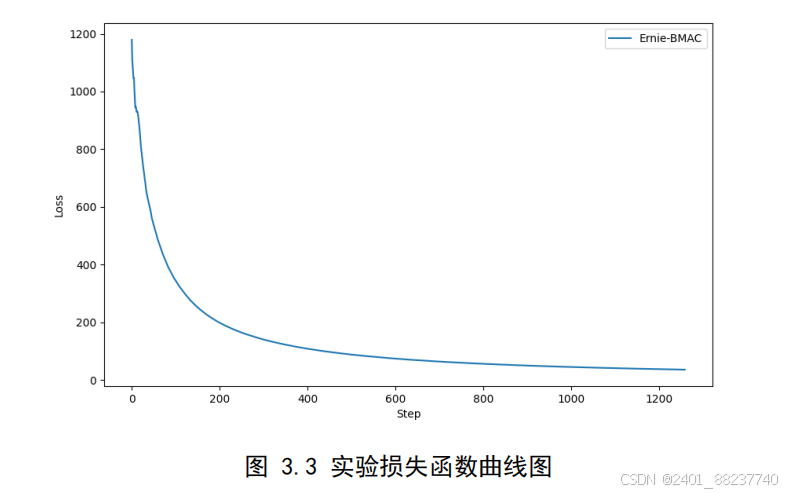
为本实验的损失函数曲线图,图像在训练初期快速下降且后期开始平缓下降
并在最后区域平缓,说明本模型有效地学习训练数据中的规律,参数优化方向正确,
且达到了一定的泛化能力。


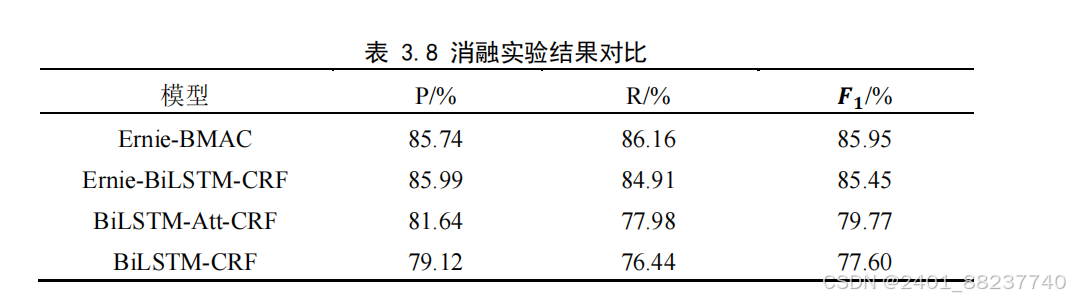
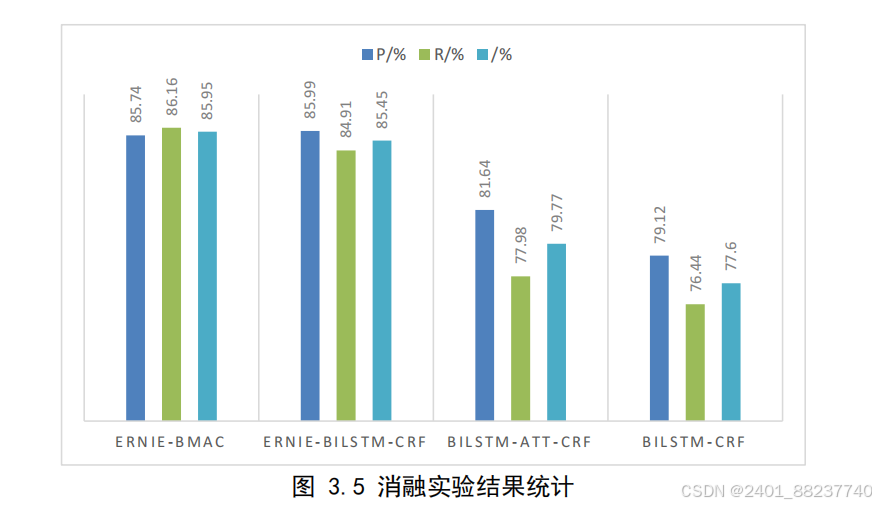
通过表
3.8
和图
3.5
能够看出,
BiLSTM-Att-CRF
模型对比本文模型,消除“
Ernie
”
模块后,各项指标均有降低。因为通过在大量文本数据上进行预训练,
Ernie
模型能够
学习到更为丰富和强大的特征表示,超越了传统
BiLSTM
模型从零开始学习的能力,
显著优化了实体识别任务的模型性能。而
Ernie-BiLSTM-CRF
在消除注意力机制模块后,
各类别的指标仅有小幅降低,表明
Ernie
能够提供更为丰富和全面的语境信息,以及更
好的语言理解能力。虽然多头注意力机制能够帮助模型集中资源处理关键信息,但在
没有足够的上下文理解和背景知识的情况下,其提升效果受到限制。相比之下,
Ernie
等预训练语言模型通过利用大量的预训练知识,能够更深入地理解文本,提供更准确
的语义表示。而同时消除这两部分模块后,对比本研究提出的模型在性能上大幅降低,
充分证明了所引入模块在中文电子病历实体识别任务上的有效性和优势。
3.4
本章小结
本章提出了一种基于
Ernie-BMAC
的电子病历命名实体识别算法,介绍了具体的算
法结构及该算法在中文电子命名实体识别过程中的处理流程。同时设置相同的数据及
实验环境对该模型设计了对比实验及消融实验,以验证本文所提出模型的有效性。
第4章 关系抽取与医疗知识图谱构建
第三章通过对中文电子病历的识别,得到了不同类别的病历实体结果。本节将在
上述实验结果的基础上,进行实体关系抽取,构建三元组,为构建知识图谱奠定基础。
同时,为了获取更加全面和丰富的医疗数据,采用网络爬虫技术获取了医疗相关数据,
包括疾病、症状、治疗方法、药物及检查项目等。经过清洗、处理和结构化整理,网
络数据与电子病历数据相结合,进一步扩充和完善关系抽取数据集。在完成数据收集
和处理后,采用
Neo4j
数据库进行数据存储,以实现数据的结构化。最终,借助所构建
的知识图谱,实现一个问答架构,为第五章系统的部分功能提供支撑。
4.1
关系抽取
由于中文电子病历文本中对于患者病情的描述多以疾病为主体展开,因此本节中
的关系抽取将以疾病实体为主要实体关系对象,构建疾病实体与其他相关实体之间的
关系。同时为了确保关系抽取的准确性和全面性,本节将采用基于规则与人工处理相
结合的方式进行关系抽取。基于规则的方法能够系统地捕捉特定模式或规律,自动化
地提取出一部分关系;而人工处理则能够在规则匹配的基础上进行进一步的校验和补
充,确保关系的准确性和完整性。本节将从实体对齐及关系构建两个步骤依次描述关
系抽取的过程。
4.1.1
实体对齐
由于不同医生在对患者病情进行记录时,可能会使用不同的术语和描述方式,导
致同一疾病或药物在电子病历文本中出现多种不同的表达形式。为了获取统一的实体
并避免数据冗杂,本节将采用实体对齐技术来处理这一问题。实体对齐的目标是将不
同的描述形式统一为一个标准的实体表示,以确保数据的一致性和可比性。通过余弦
距离计算实体间的相似度来进行实体对齐。操作步骤如图
4.1
所示:
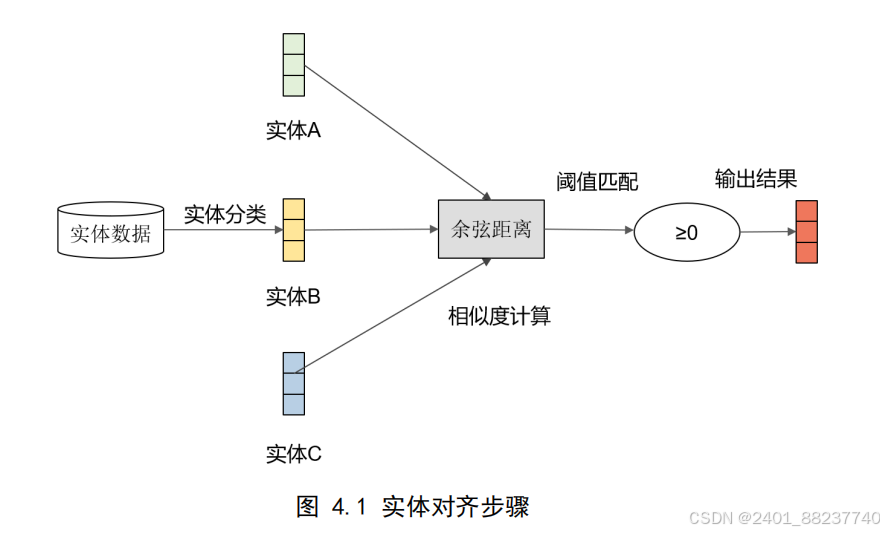
根据上一节中实体识别的结果,将同一类别的实体提取出来。首先,通过代码判
断两个实体是否存在包含关系,若存在包含关系,则两实体被认为完全相似。若不存
在包含关系,则使用余弦距离进行相似度计算,最终得到统一化的实体。具体计算公
式如式
4-1
所示。
4.1.2
关系构建
为获取更加丰富的实体间关系,本文爬取了医疗相关网站数据对原有数据进行扩
充。由于网络数据与实体识别数据在结构上不同,因此对于关系的构建分原有的实体
识别数据及爬取的数据两部分进行,并在最后对其进行融合。
(
1
)对于上述实体识别后的数据,本文采用基于规则的方式进行关系抽取。以
“疾病与检查”的关系为例,构建模版:(疾病和诊断,所需检查,影像检查)。通过
对原病历文本进行遍历,以正则表达式
`f"{disease}.*{ examination }|{test}.*{ examinatio
n }"`
在文本中搜索匹配模式,以确定两个实体之间是否存在关系。若判断存在关系,
则以模板输出并添加到实体关系列表中。最后为保证数据的可靠性,采用人工的方式
对抽取后的关系进行校验,删除少部分不合理关系。
(
2
)图
4.2
展示了爬取的部分数据,可以看到这部分数据为
json
格式,其中存在
(
3
)基于上述关系抽取内容,对两部分数据进行融合,其具体步骤包括:首先统
一命名,由于抽取出的实体类别名称与爬取数据的命名并不一致,例如,同样是对疾
病命名,抽取出的实体命名为“疾病和诊断”,现将其统一命名为“疾病”;接着,在
整合前,对两个来源的关系数据执行去重操作,消除重复记录,维护数据集的精简性
与准确性,避免冗余信息干扰知识图谱的构建。通过融合最后共抽取出
10
类实体间的
关系,具体的关系描述将在下节中进行展示。
4.2
知识图谱构建
基于上一节完成的数据处理与关系构建工作,本节将利用已提取的三元组数据来
构建医疗知识图谱。首先定义实体、实体间关系及实体属性,随后利用 Neo4j 数据库
4.2.1 Schema
构建
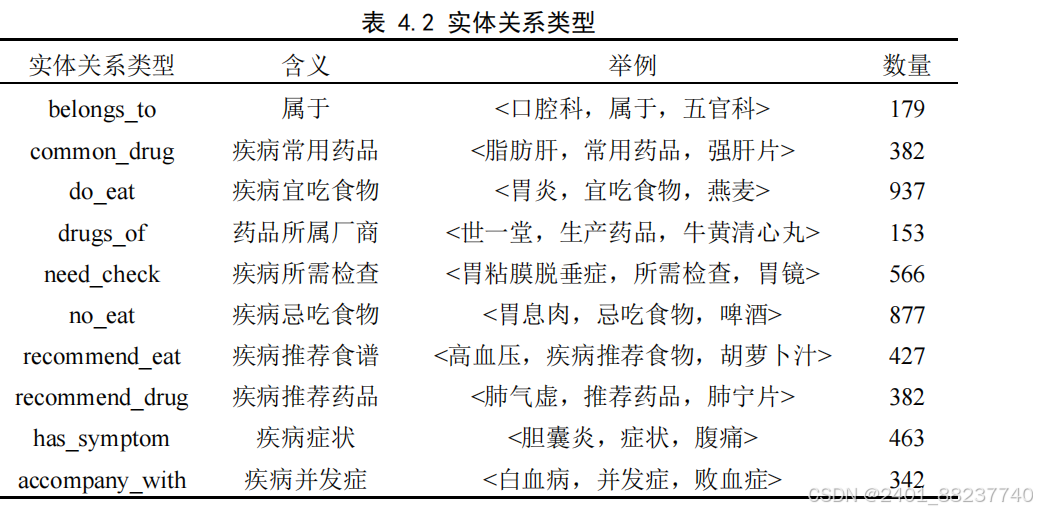
根据上述抽取出三元组的整理及对医疗问答实际应用场景的分析,将医疗知识图
谱的实体共分为七类,分别为:疾病(
Disease
)、症状(
Symptom
)、药物(
Drug
)、医
疗科室(
Department
)、医疗检查(
Check
)、食疗食物(
Food
),具体信息如表
4.1
所示:

由于该图谱构建主要是围绕各种疾病来构建各类关系的,因此对图谱中定义了一
些与疾病有关的属性,如疾病的易感人群(
easy_get
)等,具体的属性定义如表
4.3
:
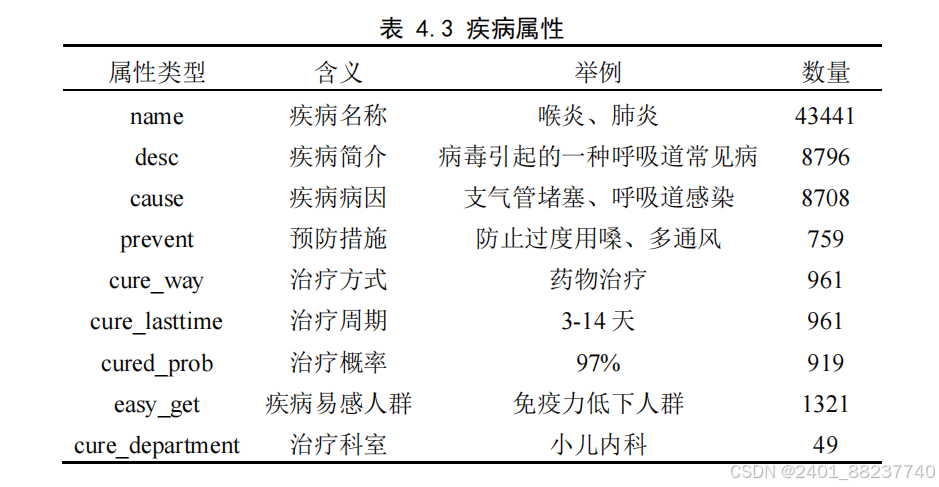
4.2.2
图谱实现
在知识图谱的构建过程中,合理选择技术和工具不仅对提升构建效率至关重要,
而且深刻影响着知识图谱的结构完整度、数据准确性和未来应用的效果。众多的图数
据库如
Neo4j
、
OrientDB
、
HugeGraph
等各有其技术特点,为知识图谱的构建提供了丰
富的选择。
Neo4j
,作为业界较早推出的图数据库之一,凭借其友好的用户界面、详尽
的技术文档资源,以及处理复杂关系网络数据的强大效能,赢得了广泛的认可。同时,
Neo4j
兼容
Cypher
查询语言,这种声明式的查询语言设计使得数据查询逻辑清晰,易
于编写和理解,同时保障了查询执行的高性能。鉴于这些优点,本文选择
Neo4j
作为构
建知识图谱的数据库平台。
Neo4j
提供了多样化的数据导入选项,包括:利用
CREATE
或
MERGE
指令在
Cypher
查询中直接添加数据,适合小量数据的手动输入;通过
LOAD CSV
指令,可实
现从
CSV
格式文件中批量导入数据;借助
Neo4j
的客户端接口(例如
Python
的
py2neo
、
Java
的
neo4j-java-driver
、
JavaScript
的
neo4j-driver
等),能够自定义脚本以解析
JSON
文件,并利用
Cypher
指令完成数据的批量导入。综合对上述三种方式特点的考虑,本
文使用
Python
的
py2neo
库进行数据导入工作。以“科室”实体为例,查询前
25
个科
室节点返回的科室图谱如图
4.4
所示:
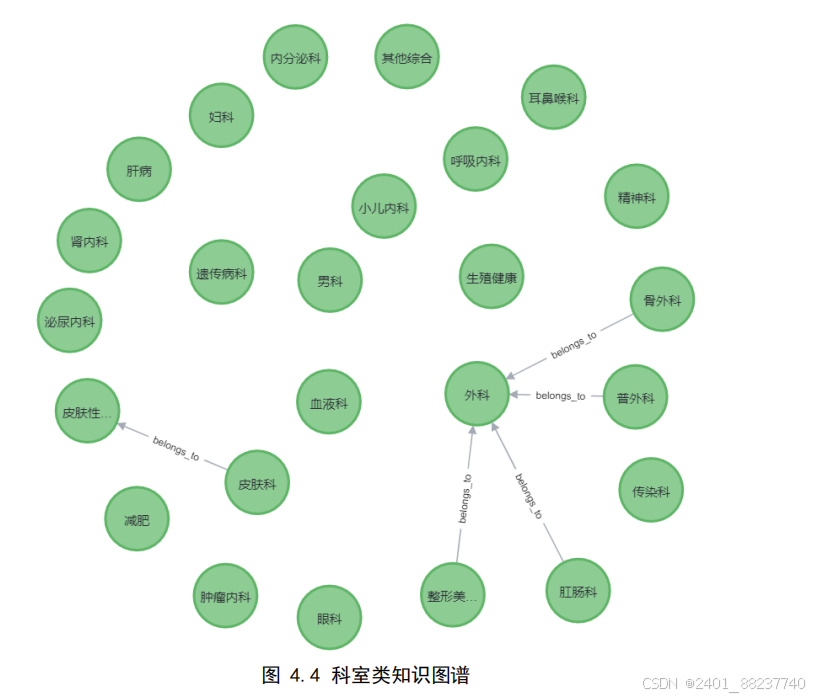
图
4.4
为单个类别实体的图谱关系,
Neo4j
采用了多样化的颜色方案以便对不同类
型的实体加以区分标识,本图谱中,橘色表示疾病、红色表示药物、粉色表示症状、
绿色表示医疗科室、紫色表示医疗检查、黄色表示食物、蓝色表示药企,不同颜色节
点间的关系不同,以“中耳炎”为例各个类别实体间的关系如图
4.5
所示:
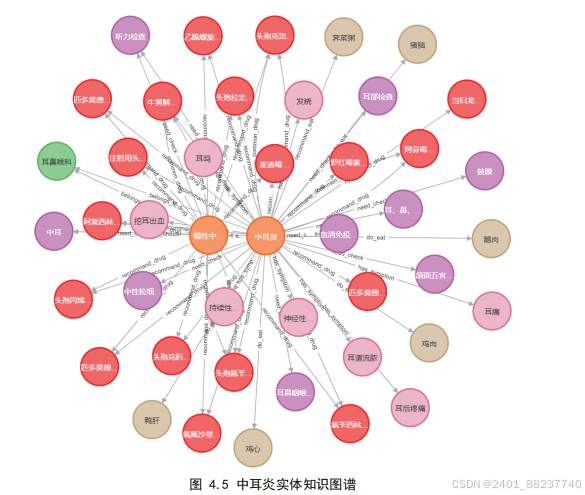
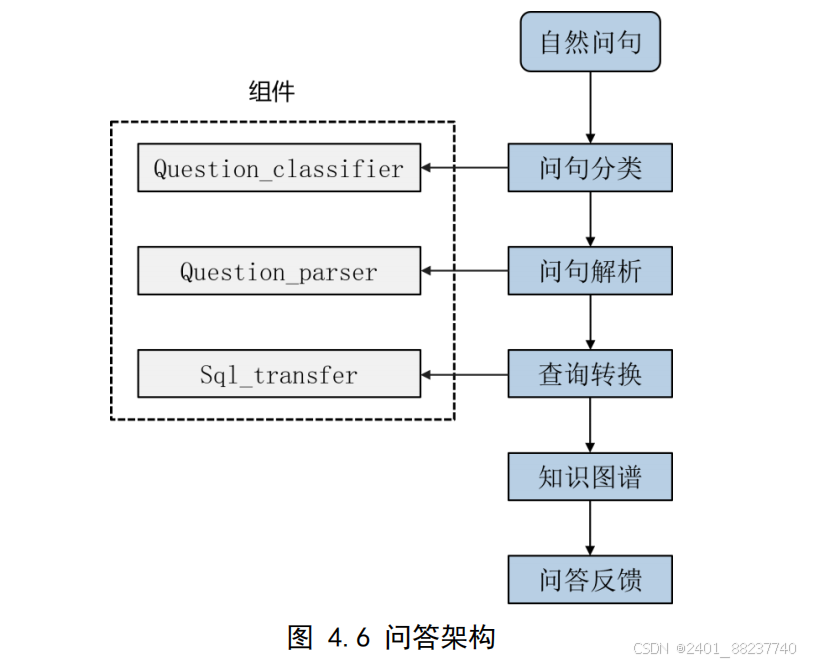
(1)问句分类:通过实现
Question_classifier
类,对问句进行自动分类。该过程主
要基于问句中的特征词进行,根据不同的特征词将问句归类为预先定义的类型。例如,
将包含“什么是”、“如何治疗”等特征词的问句归类为“疾病描述”、“治疗方法”等
类型,问句分类有助于初步识别问句的意图,从而确定后续解析和处理的方向。
(
2
)特征词分类:在分类问句时,需要识别并收集问句中涉及的实体类型,并根
据实体类型区分问句类别。特征词分类有助于确定问句的焦点,如症状、疾病、药物
等,更好地帮助理解问句的意图。
(
3
)问题解析:通过
Question_paser
类解析分类后的问题。首先构建实体节点,
然后基于特征词进行分类,收集问句中的实体类型。解析的主要目的是将自然语言问
题转换成结构化查询,以便在知识图谱中进行检索。解析过程中,需要识别出问句中
的关键实体和关系,并将其映射到知识图谱中的相应节点和边。
(
4
)实体类型收集:对于不同的问题类型(如症状、疾病描述等),根据问句中
的特征词和实体类型,采取不同的处理策略。如未找到相关信息,则提供疾病描述信
息。例如,对于问句“腹痛是什么原因”,系统需要识别“腹痛”作为症状,并查找其
可能的疾病原因。
(
5
)解析主函数:根据问题的类型,将问题转换成相应的查询语句。对于不同的
问题类型,采用不同的处理方式。解析主函数通过调用不同的解析方法,将自然语言
问题解析为结构化查询。例如,对于“颈椎病需要做什么检查”,系统需要生成查询检
查类型的语句;对于“什么是腹痛”,则生成查询症状描述的语句。
(
6
)构建字典:将问句中的实体和类型构建成字典形式,为生成查询语句做准备。
字典包含实体名称和类型,例如:
{"
实体名称
": "
腹痛
", "
实体类型
": "
症状
"}
。构建字典
有助于规范化实体,并为后续的查询转换提供基础数据结构。
(
7
)查询语句转换:根据问题类型和实体,生成相应的查询语句。如查询疾病原
因、疾病应检查等。查询语句转换过程中,需要结合实体字典和预定义的关系模版,
将自然语言问句映射为
Cypher
查询语句。
4.3
本章小结
本章在第三章实验结果的基础上进一步研究,通过对实体识别结果及网上爬取的
医疗数据进行关系抽取,得到三元组数据。进而使用
Neo4j
数据库构建中文电子病历医
疗知识图谱。同时,在构建知识图谱的基础上,进一步实现了自动问答架构,为第五
章的系统提供理论支撑。
总结与展望
在信息技术日益发达的今天,医疗行业正处于前所未有的转型期,智能医疗成为
推动行业进步的重要力量。中文电子病历作为医疗信息化的重要成果,积累了大量的
医疗数据,其中蕴含了丰富的医学知识和临床经验。然而,医疗数据大多以非结构化
文本形式存在,如何高效、准确地从中抽取有用信息,并将其转化为易于理解和利用
的知识,成为了亟待解决的关键问题。对此,本文对中文电子病历数据进行了实体命
名识别任务,在此研究的基础上融合医疗数据实现了医疗知识图谱,并设计实现了基
于电子病历知识图谱的医疗知识问答平台。本文的主要工作和成果如下:
(
1
)对国内外电子病历实体命名识别方法进行了相关的技术调研,选择合适的算
法模块进行改进,在此基础上提出一种基于
Ernie-BMAC
模型的命名实体识别算法,同
时通过对比实验证明本文模型效果高于中文电子病历命名实体识别领域常用模型效果,
也通过消融实验证明各模块的有效性。
(
2
)采用
Neo4j
数据库构建了以电子病历和医疗数据为支撑的知识图谱,同时通
过知识图谱的查询功能,搭建问答模块,在此基础上通过对当前医疗知识图谱问答系
统需求的调研,实现了中文电子病历医疗知识图谱及问答系统。
然而,本文的研究成果仍存在需要改进的地方,后续的研究将从下面几个方面进
行考虑:
(
1
)本研究中构建医疗知识图谱的数据来源于公开的医疗知识图谱库,准确性较
高,但在时效性和丰富性上存在不足。在后续的研究中,可以考虑融合更多来源的医
疗数据和知识,如最新的医学研究成果、临床指南等,以增强知识图谱的覆盖面和深
度。
(
2
)电子病历中包含大量的非文本信息,例如图像和视频数据,该数据具有丰富
的医疗信息,能够为疾病诊断和治疗提供重要线索。未来的研究可以将图像和视频数
据与文本信息相结合,进一步提升医疗知识图谱的信息完整性和应用价值。
致 谢
行文至此,我即将完成我毕业论文的撰写,但落笔的这一刹那,也意味着我为期二十多年的学
生生涯即将结束了。回首这漫长而又充实的求学之旅,心中涌起万般情愫,有即将离别的不舍,亦
有对过去岁月的感激。
首先要感谢我研究生期间的导师曾张帆老师,他十分博学多才,在平日的聊天中,除了与我们
进行学术上的交流外,时常通过历史人文故事引出许多哲理,也会通过话语描述带我们领略祖国的
山河地貌。同时他也十分负责,尽管近期十分繁忙,但仍然不辞辛劳将每位同学论文修改了一遍又
一遍。 我的家人是我求学路上坚强的后盾。在很多同龄人已经开始赚钱回馈家人的时候,我的家人告
诫我多读书,不需要考虑经济问题。在我遇到困难时,他们又会给予温暖的陪伴。家人的爱就像一
张无形的网,在你向上攀登时托举你给予你动力,在你跌落时却又能稳稳将你拖住。
在研究三年中我同样认识了许许多多的同门和伙伴。学生时代的友谊最为真挚,却也在离别时
最为不舍。在 1208 和 1210,我们一起早出晚归,一起谈天说地,一起克服学习难题;又在景德镇 的瓷瓶中,婺源的油菜花田里留下了欢快的笑声。愿大家都可前路灿灿。
落幕的只是我的研究生生活,而我依然有着千万种可能的人生。今日是春天中的一个晴日,我
流连于这个春日的盎然,同样也会毅然决然的去迎接属于我的春夏秋冬。


















 1538
1538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









