









 【风力发电叶片缺陷检测】nc: 4 names: ['Burn Mark', 'Coating_defects', 'Crack', 'EROSION ']
【风力发电叶片缺陷检测】nc: 4 names: ['Burn Mark', 'Coating_defects', 'Crack', 'EROSION ']
名称:【'烧伤痕迹', '涂层缺陷', '裂缝','侵蚀'】共1095张,8:1:1比例划分,(train;876张,val:109张,test:110张标注文件为YOLO适用的txt格式。可以直接用于模型训练。
风力发电机叶片缺陷数据集 4类 1095张,8:1:1比例划分,(train;876张,val:109张,test:110张标注文件为YOLO适用的txt格式 叶片缺陷数据集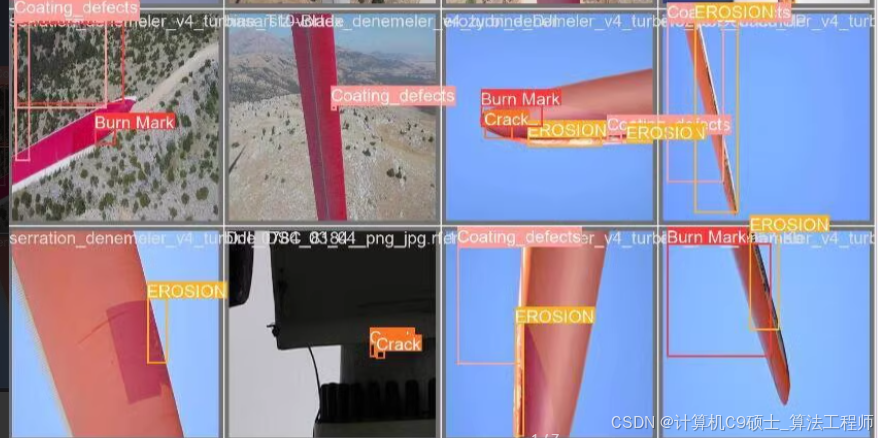
数据集2:7类
burning: 燃烧
crack: 裂缝
deformity: 变形
dirt: 污垢
oil: 油污
peeling: 剥落
rusty: 生锈

风力发电叶片缺陷检测数据集介绍
数据集概述
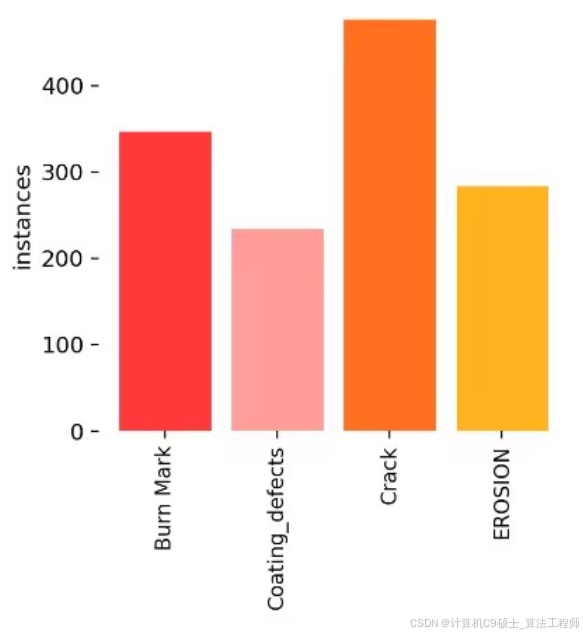
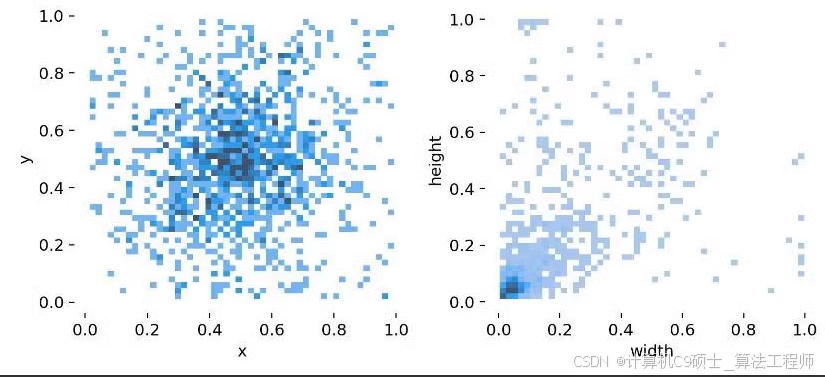
这两个数据集分别关注风力发电叶片的不同缺陷类型。第一个数据集包含四种缺陷类型:烧伤痕迹(Burn Mark)、涂层缺陷(Coating_defects)、裂缝(Crack)和侵蚀(EROSION)。第二个数据集则包含七种缺陷类型:燃烧(burning)、裂缝(crack)、变形(deformity)、污垢(dirt)、油污(oil)、剥落(peeling)和生锈(rusty)。每个数据集都按照8:1:1的比例划分为训练集、验证集和测试集,标注文件为YOLO适用的.txt格式,可以直接用于模型训练。
数据集特点
- 多类别标签:数据集涵盖了风力发电叶片常见的多种缺陷类型,有助于模型学习和识别不同的缺陷模式。
- 明确的数据划分:数据集按照标准的比例划分为训练集、验证集和测试集,便于模型训练和性能评估。
- 适用性强:YOLO格式的标注文件方便使用YOLO框架进行训练,减少了数据预处理的工作量。
数据集详情
数据集1:四类缺陷检测
- 标签:['Burn Mark', 'Coating_defects', 'Crack', 'EROSION']
- 中文名:['烧伤痕迹', '涂层缺陷', '裂缝', '侵蚀']
- 图像总数:1095张
- 划分比例:
- 训练集:876张
- 验证集:109张
- 测试集:110张
数据集2:七类缺陷检测
- 标签:['burning', 'crack', 'deformity', 'dirt', 'oil', 'peeling', 'rusty']
- 中文名:['燃烧', '裂缝', '变形', '污垢', '油污', '剥落', '生锈']
数据集内容
- 图像文件:每个数据集包含多个JPG/PNG格式的图像文件。
- 标注文件:每张图像都配有YOLO格式的
.txt标注文件。
数据集结构示例

数据集1结构示例
假设数据集1的根目录为 blade_defects_dataset1,其结构可能如下所示:
blade_defects_dataset1/
├── images/
│ ├── train/
│ │ ├── train_image_0001.jpg
│ │ ├── train_image_0002.jpg
│ │ └── ...
│ ├── val/
│ │ ├── val_image_0001.jpg
│ │ ├── val_image_0002.jpg
│ │ └── ...
│ ├── test/
│ │ ├── test_image_0001.jpg
│ │ ├── test_image_0002.jpg
│ │ └── ...
├── labels_yolo/
│ ├── train/
│ │ ├── train_image_0001.txt
│ │ ├── train_image_0002.txt
│ │ └── ...
│ ├── val/
│ │ ├── val_image_0001.txt
│ │ ├── val_image_0002.txt
│ │ └── ...
│ ├── test/
│ │ ├── test_image_0001.txt
│ │ ├── test_image_0002.txt
│ │ └── ...
└── data.yaml # 数据集配置文件数据集2结构示例
假设数据集2的根目录为 blade_defects_dataset2,其结构可能如下所示:
blade_defects_dataset2/
├── images/
│ ├── train/
│ │ ├── train_image_0001.jpg
│ │ ├── train_image_0002.jpg
│ │ └── ...
│ ├── val/
│ │ ├── val_image_0001.jpg
│ │ ├── val_image_0002.jpg
│ │ └── ...
│ ├── test/
│ │ ├── test_image_0001.jpg
│ │ ├── test_image_0002.jpg
│ │ └── ...
├── labels_yolo/
│ ├── train/
│ │ ├── train_image_0001.txt
│ │ ├── train_image_0002.txt
│ │ └── ...
│ ├── val/
│ │ ├── val_image_0001.txt
│ │ ├── val_image_0002.txt
│ │ └── ...
│ ├── test/
│ │ ├── test_image_0001.txt
│ │ ├── test_image_0002.txt
│ │ └── ...
└── data.yaml # 数据集配置文件数据集配置文件 data.yaml
数据集1的 data.yaml
# blade_defects_dataset1/data.yaml 文件
train: ../blade_defects_dataset1/images/train/
val: ../blade_defects_dataset1/images/val/
test: ../blade_defects_dataset1/images/test/
nc: 4 # number of classes
names: ['Burn Mark', 'Coating_defects', 'Crack', 'EROSION'] # class names数据集2的 data.yaml
# blade_defects_dataset2/data.yaml 文件
train: ../blade_defects_dataset2/images/train/
val: ../blade_defects_dataset2/images/val/
test: ../blade_defects_dataset2/images/test/
nc: 7 # number of classes
names: ['burning', 'crack', 'deformity', 'dirt', 'oil', 'peeling', 'rusty'] # class names关键训练代码
安装YOLOv5
如果您还没有安装YOLOv5,请按照官方文档执行以下命令:
git clone https://github.com/ultralytics/yolov5.git # clone repo
cd yolov5
pip install -r requirements.txt # install dependencies使用YOLOv5命令行训练

使用以下命令开始训练模型(以数据集1为例):
cd yolov5
python train.py --img 640 --batch 16 --epochs 300 --data ../blade_defects_dataset1/data.yaml --weights yolov5s.pt --cache自定义训练脚本
如果需要更详细的控制,可以编写一个Python脚本来执行训练过程。以下是一个简单的脚本示例(以数据集1为例):
import torch
from utils.datasets import LoadImagesAndLabels # 导入数据加载器
from models.experimental import attempt_load # 导入模型加载器
from utils.torch_utils import select_device # 导入选用设备的函数
from utils.general import check_dataset # 导入检查数据集的函数
def main():
device = select_device('') # 选择设备,自动选择GPU/CPU
data_yaml = '../blade_defects_dataset1/data.yaml'
train_images_folder = '../blade_defects_dataset1/images/train/'
train_labels_folder = '../blade_defects_dataset1/labels_yolo/train/'
val_images_folder = '../blade_defects_dataset1/images/val/'
val_labels_folder = '../blade_defects_dataset1/labels_yolo/val/'
# 加载数据集
train_set = LoadImagesAndLabels(train_images_folder, train_labels_folder)
val_set = LoadImagesAndLabels(val_images_folder, val_labels_folder)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_set, batch_size=16, shuffle=True, num_workers=4)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=16, shuffle=False, num_workers=4)
# 加载预训练模型
model = attempt_load('yolov5s.pt', map_location=device) # 加载预训练权重
model.to(device)
# 设置损失函数和优化器
criterion = torch.nn.BCEWithLogitsLoss() # 适用于多标签分类
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
epochs = 300
for epoch in range(epochs):
model.train()
for images, targets, _, _ in train_loader:
images = images.to(device)
targets = [t.to(device) for t in targets]
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
torch.save(model.state_dict(), 'trained_model.pt')
print('Training complete.')
if __name__ == '__main__':
main()注意事项
- 确保
data.yaml文件中的路径是正确的,并且数据集的结构与上面描述的一致。 - 调整批量大小、学习率、迭代次数等超参数以适应您的计算资源和任务需求。
- 如果数据集很大,您可能需要更多的计算资源和时间来完成训练。
- 这个脚本仅作为一个起点,您可能需要根据实际情况做进一步的修改。
测试模型

在训练完成后,您可以通过以下命令测试模型的性能(以数据集1为例):
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.4 --source ../blade_defects_dataset1/images/test/总结
这个示例展示了如何使用YOLOv5框架训练一个基于风力发电叶片缺陷检测的数据集。您可以根据自己的需求调整脚本中的参数和逻辑。通过使用这些数据集和相应的训练代码,您可以有效地训练出一个能够在多种条件下识别叶片缺陷的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









