






深度学习目标检测算法 区域人员计数 基于yolov5+deepsort的人流量统计系统 如何使用YOLOv5进行目标检测,并结合DeepSORT进行目标跟踪,最后统计人流量。
文章目录
基于yolov5+deepsort的人流量统计系统
1
1
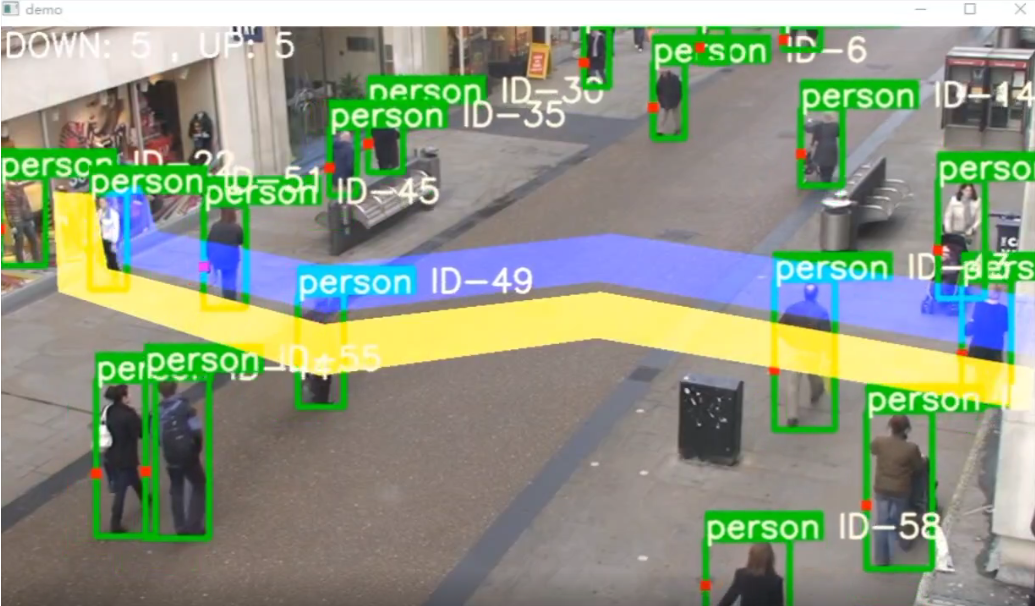
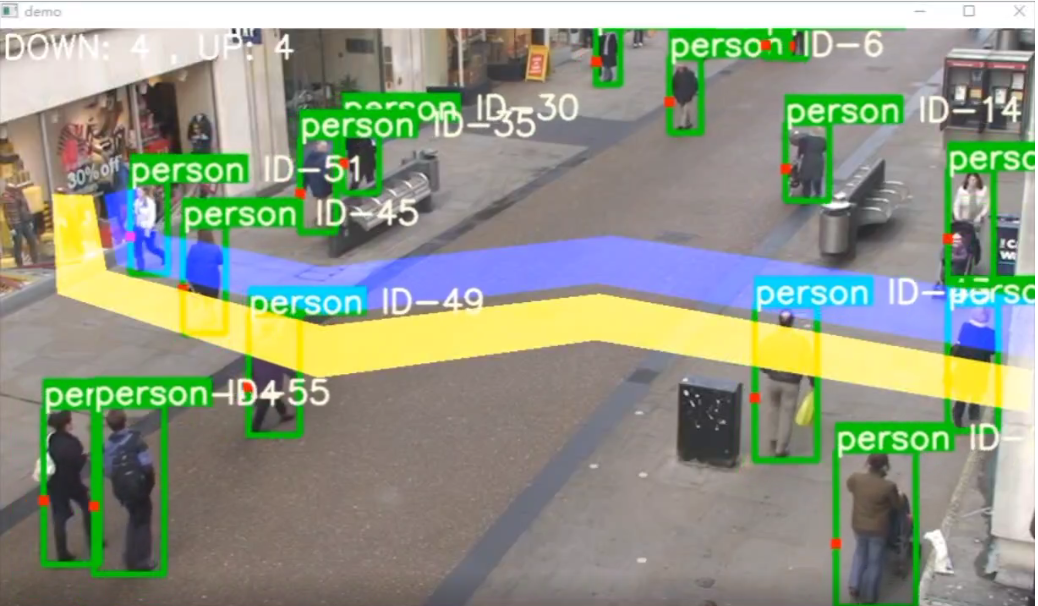
基于YOLOv5和DeepSORT的人流量统计系统,结合了目标检测、目标跟踪以及轨迹分析。代码示例,如何使用YOLOv5进行目标检测,并结合DeepSORT进行目标跟踪,最后统计人流量。
Step 1: 环境准备
为了配置CUDA和PyTorch环境,你需要确保系统上已安装了适当版本的NVIDIA驱动程序、CUDA Toolkit以及cuDNN。以下是详细的步骤和代码示例来帮助你完成环境配置:
1. 安装Miniconda
首先,你需要安装Miniconda来管理Python环境。访问Miniconda官网下载适合你的操作系统的安装包并按照指示进行安装。
2. 创建并激活Conda环境
打开命令提示符或终端,并运行以下命令来创建一个新的conda环境(这里使用Python 3.8为例):
conda create -n yolov5-env python=3.8
conda activate yolov5-env
3. 安装PyTorch与CUDA支持
根据你的CUDA版本选择合适的PyTorch安装命令。可以在PyTorch官网找到最新的安装指令。假设你的CUDA版本是11.3,可以使用以下命令安装:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
请将cu113替换为匹配你CUDA版本的标签,如cu102等。
4. 验证CUDA是否正确安装
你可以通过运行一个简单的PyTorch脚本来验证CUDA是否正确安装:
import torch
print("CUDA available:", torch.cuda.is_available())
print("CUDA version:", torch.version.cuda)
print("PyTorch version:", torch.__version__)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
x = torch.randn(5, 5).to(device)
y = x * x
print(y)
如果一切正常,你应该看到输出表示CUDA可用且正在使用的设备是GPU。
5. 安装其他依赖库
YOLOv5需要一些额外的Python库,可以通过以下命令安装:
pip install numpy opencv-python-headless matplotlib seaborn scikit-learn tqdm pyyaml scipy pillow
对于DeepSORT,你可能还需要安装一些额外的库,比如filterpy等:
pip install filterpy
6. 克隆YOLOv5仓库
现在,你已经准备好开始使用YOLOv5了。克隆官方仓库并安装必要的依赖:
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
7. 测试YOLOv5
为了测试YOLOv5是否正确安装,可以尝试运行其中一个示例脚本:
python detect.py --source 0 # 使用摄像头作为输入源
# 或者使用图片或视频文件
# python detect.py --source path/to/image.jpg
# python detect.py --source path/to/video.mp4
以上步骤应该能帮助你在Windows系统上配置好基于CUDA的PyTorch环境,并准备好使用YOLOv5。记得在执行任何步骤之前,确认你的系统满足所有先决条件,包括正确的NVIDIA驱动程序、CUDA Toolkit和cuDNN的安装。
安装了YOLOv5和DeepSORT,CUDA和PyTorch环境。
Step 2: 导入必要的库
import cv2
import numpy as np
import torch
from deep_sort import DeepSort
from yolov5.models.experimental import attempt_load
from yolov5.utils.datasets import LoadStreams, LoadImages
from yolov5.utils.general import non_max_suppression, scale_coords
from yolov5.utils.torch_utils import select_device
Step 3: 初始化模型和参数
# 加载YOLOv5模型
weights = 'yolov5s.pt' # 使用预训练的YOLOv5模型
device = select_device('') # 自动选择设备(CPU或GPU)
model = attempt_load(weights, map_location=device)
stride = int(model.stride.max())
imgsz = 640
# 初始化DeepSORT
deepsort = DeepSort('osnet_x0_25', max_dist=0.2, nn_budget=100)
# 定义计数线
count_line = [(0, 320), (640, 320)] # 水平线,可以根据实际情况调整
up_count = 0
down_count = 0
Step 4: 处理视频流
def process_video(video_path):
cap = cv2.VideoCapture(video_path)
while True:
ret, frame = cap.read()
if not ret:
break
# 预处理图像
img = letterbox(frame, imgsz, stride=stride)[0]
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 目标检测
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, 0.25, 0.45, classes=None, agnostic=False)
for i, det in enumerate(pred): # detections per image
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round()
# 进行目标跟踪
outputs = deepsort.update(det.cpu(), frame)
# 绘制边界框和ID
for output in outputs:
bbox = output[:4]
id = output[-1]
x1, y1, x2, y2 = bbox
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(frame, f"ID-{id}", (int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 统计人流量
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
if cy < count_line[0][1] and cy > count_line[1][1]:
if id not in up_ids:
up_ids.add(id)
up_count += 1
elif cy > count_line[0][1] and cy < count_line[1][1]:
if id not in down_ids:
down_ids.add(id)
down_count += 1
# 绘制计数线和统计信息
cv2.line(frame, count_line[0], count_line[1], (0, 0, 255), 2)
cv2.putText(frame, f"UP: {up_count}, DOWN: {down_count}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
# 显示结果
cv2.imshow("demo", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 调用函数处理视频
process_video('path/to/your/video.mp4')
注意事项 仅供参考
- YOLOv5模型:你需要根据你的需求选择合适的YOLOv5模型权重文件。
- DeepSORT初始化:
DeepSort类需要根据你的需求进行适当的参数调整。 - 计数线设置:
count_line变量定义了用于统计人流量的虚拟线,你可以根据实际场景进行调整。 - 性能优化:在实际应用中,可能需要对代码进行进一步的优化,以提高处理速度和准确性。
代码示例:仅供参考


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









