






深度学习区域入侵检测 人员车辆入侵检测系统 基于yolov8的人员车辆区域目标入侵检测系统 对入侵对象进行轨迹追踪
以下文字及代码仅供参考。
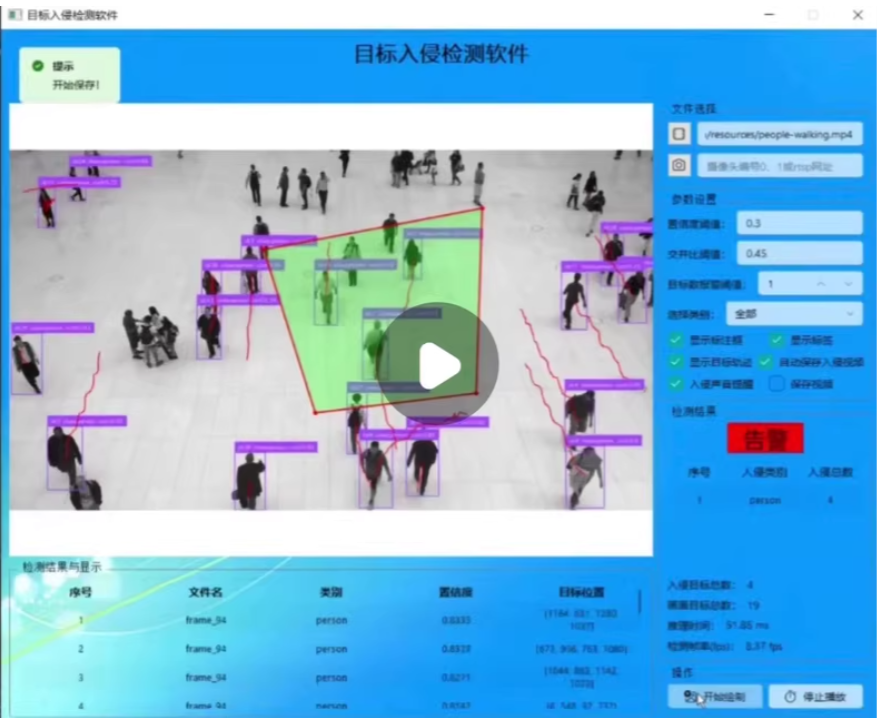
基于yolov8的目标入侵检测系统。
识别对象:人、车
环境:python3.10
内容:Python源码+pyqt5界面
预实现功能:
1.人、汽车、卡车入侵检测;
2.自定义入侵区域;
3.入侵声音与文字报警;
4.入侵对象轨迹追踪;
5.支持视频和摄像头检测;
6.入侵片段自动保存与全视频保存;
7.其它:交并比、置信度、目标数报警阈值、入侵目标数量统计、画面总目标数量统计、入侵类别切换、推理时间、检测帧率显示。
环境配置
1.安装conda
②官网:https://www.anaconda.com/download,需要注册下载
2.创建运行环境
conda create -n yolov8 python==3.10.14
3.激活运行环境
conda activate yolov8
4.安装yolov8
pip install ultralytics==8.2.61 -i https://pypi.tuna.tsinghua.edu.cn/simple
5.安装界面库
pip install PyQt5 pyqt5-tools
PyQt-Fluent-Widgets -i https://pypi.tuna.tsinghua.edu.cn/simple
6.安装cv2
pip install python-opencv==4.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
7.安装supervision
pip install supervision -i https://pypi.tuna.tsinghua.edu.cn/simple
7.安装pygame
pip install pygame -i https://pypi.tuna.tsinghua.edu.cn/simple
构建一个基于YOLOv8的目标入侵检测系统,包括人、汽车、卡车的入侵检测,并具备自定义入侵区域、报警、轨迹追踪等功能,
需要经过以下几个步骤:环境配置、数据准备、模型训练、推理代码编写以及界面开发。
代码示例:仅供参考
环境配置
1. 安装conda
访问官网 https://www.anaconda.com/download 下载并安装Anaconda。
2. 创建运行环境
conda create -n yolov8 python==3.10.14
3. 激活运行环境
conda activate yolov8
4. 安装必要的库
pip install ultralytics==8.2.61 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install PyQt5 pyqt5-tools PyQt-Fluent-Widgets -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-python==4.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install supervision -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pygame -i https://pypi.tuna.tsinghua.edu.cn/simple
数据准备
确保你的数据集已准备好,并按照以下结构组织:
invasion_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
每个标签文件包含一行信息,格式如下:class_id center_x center_y width height,所有坐标值都是相对于图像尺寸归一化的。
数据配置
创建一个名为 data.yaml 的文件来描述数据集的路径和类别信息:
train: ./invasion_dataset/images/train/
val: ./invasion_dataset/images/val/
test: ./invasion_dataset/images/test/
nc: 3 # 类别数量(person, car, truck)
names: ['person', 'car', 'truck'] # 类别名称
模型训练
使用YOLOv8进行模型训练:
yolo detect train model=yolov8n.pt data=data.yaml batch=16 epochs=100 imgsz=640 device=cuda
推理代码
编写Python脚本对新图像或视频进行推理,并实现入侵检测功能:
from ultralytics import YOLO
import cv2
import numpy as np
import supervision as sv
import pygame
# 加载训练好的模型
model = YOLO('runs/detect/train/weights/best.pt')
# 初始化pygame用于声音报警
pygame.mixer.init()
def infer_video(video_path):
cap = cv2.VideoCapture(video_path)
zone_polygon = np.array([[100, 100], [500, 100], [500, 400], [100, 400]]) # 自定义入侵区域
zone_annotator = sv.PolygonZoneAnnotator(zone=sv.PolygonZone(polygon=zone_polygon), color=sv.Color.red())
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model.predict(source=frame, imgsz=640)
for r in results:
boxes = r.boxes.xyxy.cpu().numpy()
scores = r.boxes.conf.cpu().numpy()
labels = r.boxes.cls.cpu().numpy()
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
centroid = (int((x1 + x2) / 2), int((y1 + y2) / 2))
if sv.PointZone(polygon=zone_polygon).trigger(point=centroid):
pygame.mixer.music.load("alarm.mp3")
pygame.mixer.music.play()
print(f"Alert: {r.names[int(label)]} detected in the restricted area!")
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"{r.names[int(label)]} {score:.4f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
zone_annotator.annotate(scene=frame)
cv2.imshow("Inference Result", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 测试视频路径
infer_video('path/to/test/video.mp4')
构建用户界面
我们可以使用PyQt5库来构建一个简单的GUI,用于选择图像或视频进行检测:
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QVBoxLayout, QWidget, QLabel, QFileDialog, QTextEdit
from PyQt5.QtGui import QImage, QPixmap
import cv2
from ultralytics import YOLO
class InvasionDetectionApp(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("目标入侵检测软件")
self.setGeometry(100, 100, 800, 600)
self.model = YOLO('runs/detect/train/weights/best.pt')
self.cap = None
self.running = False
self.initUI()
def initUI(self):
layout = QVBoxLayout()
self.image_label = QLabel(self)
layout.addWidget(self.image_label)
self.create_button("选择图片", self.select_image)
self.create_button("选择视频", self.select_video)
self.create_button("打开摄像头", self.open_camera)
self.create_button("开始检测", self.start_detection)
self.create_button("暂停检测", self.pause_detection)
self.create_button("结束检测", self.stop_detection)
self.log_text = QTextEdit(self)
layout.addWidget(self.log_text)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
def create_button(self, text, command):
button = QPushButton(text, self)
button.clicked.connect(command)
return button
def select_image(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Image Files (*.jpg *.png)")
if file_path:
self.image_path = file_path
self.show_image(file_path)
def show_image(self, image_path):
image = QImage(image_path)
pixmap = QPixmap.fromImage(image)
self.image_label.setPixmap(pixmap)
def select_video(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择视频", "", "Video Files (*.mp4 *.avi)")
if file_path:
self.video_path = file_path
def open_camera(self):
self.cap = cv2.VideoCapture(0)
def start_detection(self):
if hasattr(self, 'image_path'):
self.infer_image(self.image_path)
elif hasattr(self, 'video_path'):
self.infer_video(self.video_path)
elif self.cap is not None:
self.running = True
self.detect_from_camera()
def pause_detection(self):
self.running = False
def stop_detection(self):
self.running = False
if self.cap is not None:
self.cap.release()
self.cap = None
def infer_image(self, image_path):
results = self.model.predict(source=image_path, imgsz=640)
for r in results:
boxes = r.boxes.xyxy.cpu().numpy()
scores = r.boxes.conf.cpu().numpy()
labels = r.boxes.cls.cpu().numpy()
image = cv2.imread(image_path)
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, f"{r.names[int(label)]} {score:.4f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow("Inference Result", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
def infer_video(self, video_path):
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = self.model.predict(source=frame, imgsz=640)
for r in results:
boxes = r.boxes.xyxy.cpu().numpy()
scores = r.boxes.conf.cpu().numpy()
labels = r.boxes.cls.cpu().numpy()
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"{r.names[int(label)]} {score:.4f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow("Inference Result", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def detect_from_camera(self):
if self.running and self.cap is not None:
ret, frame = self.cap.read()
if ret:
results = self.model.predict(source=frame, imgsz=640)
for r in results:
boxes = r.boxes.xyxy.cpu().numpy()
scores = r.boxes.conf.cpu().numpy()
labels = r.boxes.cls.cpu().numpy()
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"{r.names[int(label)]} {score:.4f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow("Camera Detection", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
self.stop_detection()
self.update()
self.root.after(10, self.detect_from_camera)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = InvasionDetectionApp()
window.show()
sys.exit(app.exec_())
构建一个基于YOLOv8的目标入侵检测系统了



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









