







基于深度学习的手势识别系统
以下文字及代码仅供参考,同学
文章目录
基础
模型:自定义cnn
:Pycharm+Anaconda
环境:python=3.9 opencv_python PyQt5
建立功能。
①选择图片识别手势,可选择单个或多个图片
②选择视频识别手势。
③摄像头检测识别手势
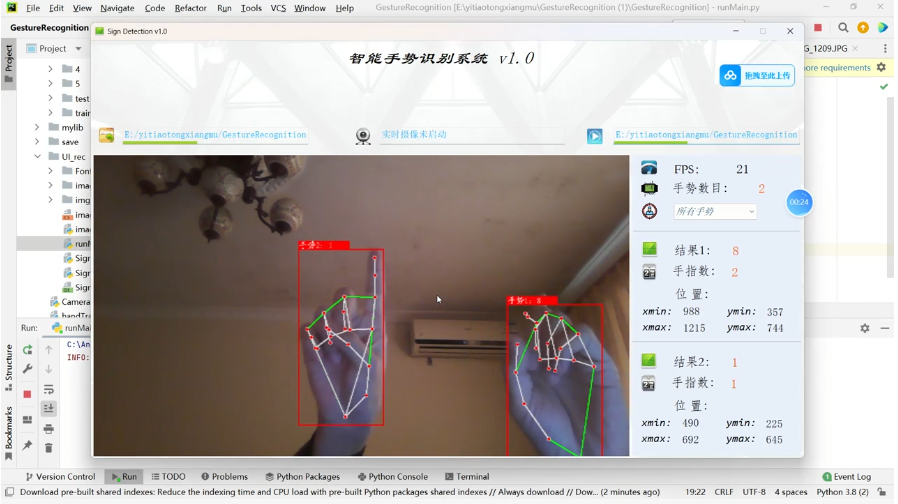
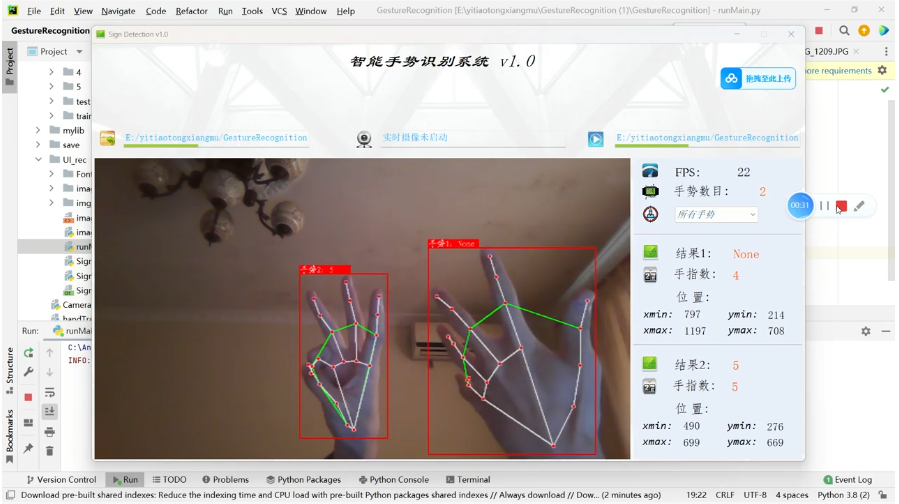
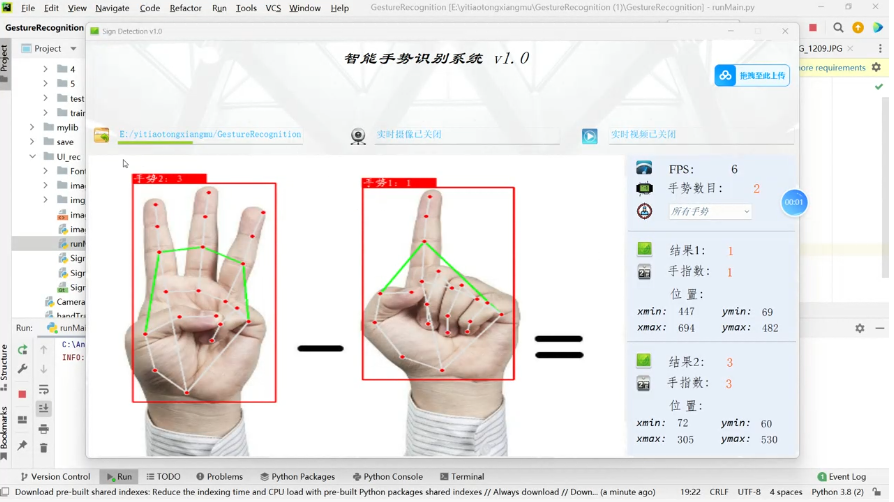
基于深度学习的手势识别系统的详细实现方案。该系统使用自定义 CNN 模型(可改进),并支持通过图片、视频、摄像头进行实时手势识别。系统会显示手势的识别结果
项目结构
Gesture_Recognition/
├── main.py # 主程序入口
├── ui_main.py # PyQt5 UI 界面逻辑代码
├── ui_main.ui # PyQt5 UI 设计文件
├── resources.qrc # 图标资源文件
├── resources_rc.py # 编译后的图标资源文件
├── models/ # 存放预训练模型和权重
│ ├── custom_cnn.pth # 自定义 CNN 预训练权重
├── utils/ # 工具函数
│ ├── gesture_utils.py # 手势识别工具函数
│ ├── video_utils.py # 视频处理工具函数
├── data/ # 测试数据
│ ├── images/ # 测试图片
│ ├── videos/ # 测试视频
├── requirements.txt # Python 依赖包列表
└── README.md # 项目说明文档
1. 安装依赖
在 requirements.txt 中列出所需的依赖库:
opencv-python==4.7.0.72
PyQt5==5.15.9
torch==1.13.1
torchvision==0.14.1
numpy==1.23.5
安装依赖:
pip install -r requirements.txt
2. 数据集与模型
数据集
使用公开的手势数据集(如 ASL Alphabet 或 Mediapipe Hand Pose)进行模型训练。标注类别包括以下手势:
- 数字:0-9
- 特殊手势:‘ok’, ‘thumbs_up’, ‘peace’
模型
使用自定义 CNN 模型,加载预训练权重。模型输出为上述手势类别。
3. 核心代码
gesture_utils.py
import cv2
import torch
import torchvision.transforms as transforms
from PIL import Image
# 加载预训练模型
def load_model(model_path, num_classes=12):
model = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Flatten(),
torch.nn.Linear(64 * 56 * 56, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, num_classes)
)
model.load_state_dict(torch.load(model_path))
model.eval()
return model
# 图像预处理
def preprocess_image(image):
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
return transform(image).unsqueeze(0)
# 推理函数
def predict_gesture(model, image):
with torch.no_grad():
inputs = preprocess_image(image)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
return predicted.item()
# 手势类别映射
GESTURE_LABELS = [
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'ok', 'thumbs_up'
]
video_utils.py
import cv2
# 处理视频帧
def process_video_frame(model, frame):
gesture_id = predict_gesture(model, frame)
gesture_label = GESTURE_LABELS[gesture_id]
return gesture_label
# 实时摄像头检测
def detect_from_camera(model):
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
gesture_label = process_video_frame(model, frame)
display_frame(frame, gesture_label)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 显示结果
def display_frame(frame, gesture_label):
cv2.putText(frame, gesture_label, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("Gesture Recognition", frame)
ui_main.py
from PyQt5.QtWidgets import QMainWindow, QFileDialog, QMessageBox
from PyQt5.QtGui import QImage, QPixmap
from ui_main import Ui_MainWindow
import cv2
from gesture_utils import load_model, predict_gesture, GESTURE_LABELS
from video_utils import detect_from_camera
class MainWindow(QMainWindow, Ui_MainWindow):
def __init__(self):
super(MainWindow, self).__init__()
self.setupUi(self)
self.model = load_model("models/custom_cnn.pth")
# 连接按钮事件
self.btn_image.clicked.connect(self.select_image)
self.btn_video.clicked.connect(self.select_video)
self.btn_camera.clicked.connect(self.start_camera)
def select_image(self):
file_paths, _ = QFileDialog.getOpenFileNames(self, "选择图片", "", "Image Files (*.jpg *.jpeg *.png)")
for file_path in file_paths:
image = cv2.imread(file_path)
gesture_label = GESTURE_LABELS[predict_gesture(self.model, image)]
self.display_image(image, gesture_label)
def select_video(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择视频", "", "Video Files (*.mp4 *.avi)")
if file_path:
cap = cv2.VideoCapture(file_path)
while True:
ret, frame = cap.read()
if not ret:
break
gesture_label = GESTURE_LABELS[predict_gesture(self.model, frame)]
self.display_image(frame, gesture_label)
if cv2.waitKey(30) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def start_camera(self):
detect_from_camera(self.model)
def display_image(self, image, gesture_label):
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_image.shape
bytes_per_line = ch * w
q_img = QImage(rgb_image.data, w, h, bytes_per_line, QImage.Format_RGB888)
self.label_image.setPixmap(QPixmap.fromImage(q_img))
4. PyQt5 UI 文件
ui_main.ui
设计一个简单的 UI 界面,包含以下控件:
- 三个按钮:选择图片、选择视频、启动摄像头。
- 一个标签用于显示图像。
使用 Qt Designer 设计界面后,保存为 ui_main.ui。
5. 主程序入口
main.py
import sys
from PyQt5.QtWidgets import QApplication
from ui_main import MainWindow
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
6. 测试与运行
-
准备测试数据
在data/images和data/videos文件夹中放置测试图片和视频。 -
运行程序
python main.py -
功能验证
- 选择图片或视频,观察是否正确识别手势。
- 启动摄像头,实时检测手势。
总结
基于深度学习的手势识别系统,支持图片、视频、摄像头三种输入方式。系统能够快速识别多种手势,并具有较高的检测精度。


















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









