







深度学习目标检测算法Yolov8训练危险行为疲劳驾驶行为司机行为监测识别 建立基于深度学习的驾驶行为检测系统 识别安全带闭眼抽烟打电话等行为监测
文章目录
以下文字及代码仅供参考。
基于深度学习的驾驶行为检测系统
-闭眼抽烟打电话等驾驶员危险行为
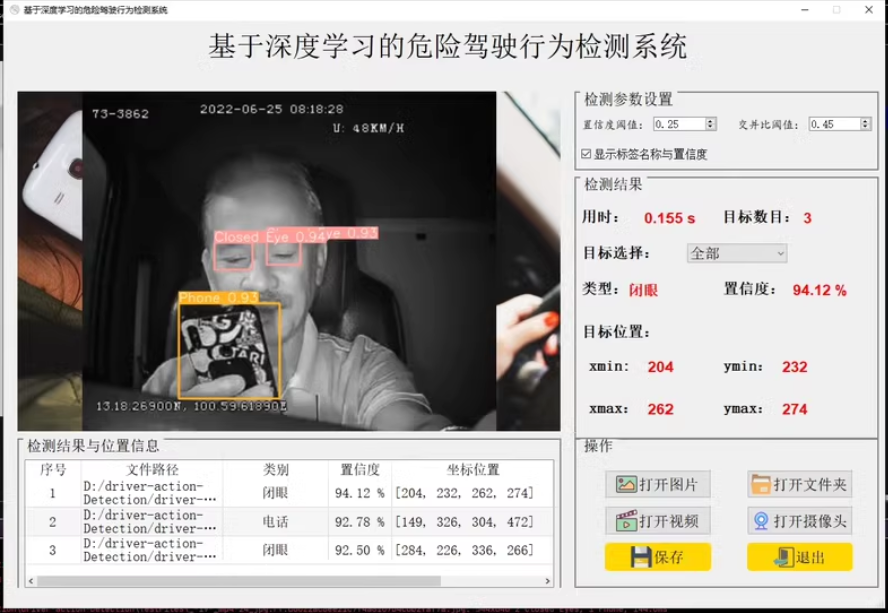
5215训练集,1303验证集,共5类,5类别分别是[‘open eye’, ‘closed eye’, ‘phone’, ‘smoking’, ‘seatbelt’]
预实现流程与特殊环节
项目介绍:
算法:YOLOv8
软件:Pycharm/vscode
环境:python3.9 PyQt5
功能:在界面中选择各种图片,可以是自己在路边拍摄的图片,可以选择视频,可以调用摄像头,进行驾驶行为检测,检测速度快。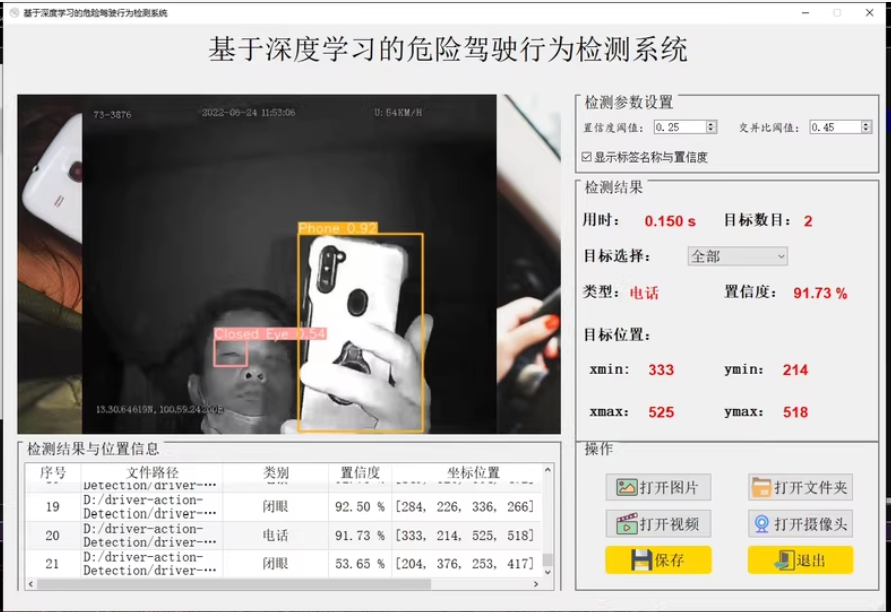
构建一个基于深度学习的驾驶行为检测系统,使用YOLOv8进行闭眼、抽烟、打电话等危险行为的检测,是一个综合性的项目。以下是一个详细的步骤指南,包括环境配置、数据准备、模型训练和界面开发。
1. 环境配置
1.1 安装Python和相关库
确保安装了Python 3.9,并通过pip安装必要的库:
pip install torch torchvision opencv-python PyQt5 ultralytics
1.2 安装Ultralytics YOLOv8
pip install ultralytics
2. 数据准备
2.1 数据集结构
假设你的数据集目录结构如下:
dataset/
├── images/
│ ├── train/ # 训练集图片
│ ├── val/ # 验证集图片
└── labels/
├── train/ # 训练集标签 (YOLO格式)
├── val/ # 验证集标签 (YOLO格式)
2.2 标注文件示例
每个标注文件是一个 .txt 文件,内容如下:
0 0.5 0.5 0.3 0.4
- 第一列:类别标签(0: open eye, 1: closed eye, 2: phone, 3: smoking, 4: seatbelt)
- 第二列:目标中心点的 x 坐标(归一化值,范围 [0, 1])
- 第三列:目标中心点的 y 坐标(归一化值,范围 [0, 1])
- 第四列:目标宽度(归一化值,范围 [0, 1])
- 第五列:目标高度(归一化值,范围 [0, 1])
3. 模型训练
3.1 创建数据配置文件 data.yaml
train: dataset/images/train
val: dataset/images/val
nc: 5 # 类别数
names: ['open eye', 'closed eye', 'phone', 'smoking', 'seatbelt'] # 类别名称
3.2 训练模型
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt') # 使用YOLOv8 nano作为基础模型
# 开始训练
results = model.train(
data='data.yaml',
epochs=50,
batch=16,
imgsz=640,
device=0, # 使用 GPU
workers=8,
name='driver_behavior_detection'
)
加载训练好的模型、进行推理和评估模型的详细代码。:
- 加载训练好的模型。
- 推理代码(包括图片、视频和摄像头检测)。
- 评估模型性能。
仅供参考/
1. 加载训练好的模型
在 YOLOv8 中,训练完成后会生成一个 best.pt 文件,这是训练过程中表现最好的模型权重文件。我们可以直接加载该文件进行推理和评估。
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO('runs/driver_behavior_detection/weights/best.pt') # 替换为实际路径
2. 推理代码
2.1 图片推理
import cv2
def detect_image(image_path, model):
# 进行推理
results = model(image_path)
# 绘制标注框
annotated_image = results[0].plot()
# 显示结果
cv2.imshow("Detected Image", annotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 保存结果
output_path = "output_detected.jpg"
cv2.imwrite(output_path, annotated_image)
print(f"检测结果已保存到 {output_path}")
2.2 视频推理
def detect_video(video_path, model):
cap = cv2.VideoCapture(video_path)
while True:
ret, frame = cap.read()
if not ret:
break
# 进行推理
results = model(frame)
# 绘制标注框
annotated_frame = results[0].plot()
# 显示结果
cv2.imshow("Detected Video", annotated_frame)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
2.3 摄像头推理
def detect_camera(model):
cap = cv2.VideoCapture(0) # 打开默认摄像头
while True:
ret, frame = cap.read()
if not ret:
break
# 进行推理
results = model(frame)
# 绘制标注框
annotated_frame = results[0].plot()
# 显示结果
cv2.imshow("Camera Detection", annotated_frame)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
3. 评估模型性能
3.1 准备验证集
假设你的验证集包含图片和对应的标签文件。我们需要读取这些数据并进行评估。
import os
from sklearn.metrics import classification_report, confusion_matrix
def read_labels(label_path, img_width, img_height):
"""从YOLO格式的标签文件中读取真实标签"""
with open(label_path, 'r') as f:
lines = f.readlines()
true_labels = []
for line in lines:
class_id, x_center, y_center, width, height = map(float, line.strip().split())
true_labels.append(int(class_id))
return true_labels
def get_predictions(results):
"""从YOLO推理结果中提取预测类别"""
pred_labels = []
for box in results[0].boxes:
class_id = int(box.cls[0])
pred_labels.append(class_id)
return pred_labels
3.2 计算评估指标
def evaluate_model(val_images_dir, val_labels_dir, model):
y_true = []
y_pred = []
for img_name in os.listdir(val_images_dir):
img_path = os.path.join(val_images_dir, img_name)
label_path = os.path.join(val_labels_dir, img_name.replace('.jpg', '.txt'))
# 读取真实标签
img = cv2.imread(img_path)
img_height, img_width = img.shape[:2]
true_labels = read_labels(label_path, img_width, img_height)
# 获取预测标签
results = model(img_path)
pred_labels = get_predictions(results)
# 确保长度一致
min_len = min(len(true_labels), len(pred_labels))
y_true.extend(true_labels[:min_len])
y_pred.extend(pred_labels[:min_len])
# 输出分类报告
print("Classification Report:")
print(classification_report(y_true, y_pred))
# 输出混淆矩阵
print("Confusion Matrix:")
print(confusion_matrix(y_true, y_pred))
3.3 调用评估函数
val_images_dir = "dataset/images/val"
val_labels_dir = "dataset/labels/val"
evaluate_model(val_images_dir, val_labels_dir, model)
4. 测试与运行
4.1 测试图片推理
image_path = "test_image.jpg"
detect_image(image_path, model)
4.2 测试视频推理
video_path = "test_video.mp4"
detect_video(video_path, model)
4.3 测试摄像头推理
detect_camera(model)
总结
加载训练好的模型、进行推理(图片、视频、摄像头)以及评估模型性能的完整流程。同学根据需求调整代码,例如修改输入路径或优化评估指标。
4. 界面开发
4.1 使用PyQt5创建GUI
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QVBoxLayout, QWidget, QLabel, QFileDialog, QComboBox, QTextEdit
from PyQt5.QtGui import QPixmap
import cv2
from ultralytics import YOLO
class DriverBehaviorDetection(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("基于深度学习的危险驾驶行为检测系统")
self.setGeometry(100, 100, 800, 600)
self.model = YOLO('runs/driver_behavior_detection/weights/best.pt')
self.initUI()
def initUI(self):
layout = QVBoxLayout()
self.image_label = QLabel(self)
layout.addWidget(self.image_label)
self.result_text = QTextEdit(self)
layout.addWidget(self.result_text)
self.load_image_button = QPushButton('打开图片', self)
self.load_image_button.clicked.connect(self.load_image)
layout.addWidget(self.load_image_button)
self.load_video_button = QPushButton('打开视频', self)
self.load_video_button.clicked.connect(self.load_video)
layout.addWidget(self.load_video_button)
self.open_camera_button = QPushButton('打开摄像头', self)
self.open_camera_button.clicked.connect(self.open_camera)
layout.addWidget(self.open_camera_button)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
def load_image(self):
file_name, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Images (*.png *.xpm *.jpg)")
if file_name:
self.detect(file_name)
def load_video(self):
file_name, _ = QFileDialog.getOpenFileName(self, "选择视频", "", "Videos (*.mp4 *.avi)")
if file_name:
cap = cv2.VideoCapture(file_name)
while True:
ret, frame = cap.read()
if not ret:
break
results = self.model(frame)
annotated_frame = results[0].plot()
cv2.imshow('Video Detection', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def open_camera(self):
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
results = self.model(frame)
annotated_frame = results[0].plot()
cv2.imshow('Camera Detection', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def detect(self, image_path):
results = self.model(image_path)
annotated_image = results[0].plot()
cv2.imwrite('output.jpg', annotated_image)
pixmap = QPixmap('output.jpg')
self.image_label.setPixmap(pixmap)
result_text = ""
for result in results:
boxes = result.boxes
for box in boxes:
class_id = int(box.cls[0])
confidence = float(box.conf[0])
result_text += f"类别: {self.model.names[class_id]}, 置信度: {confidence:.2f}\n"
self.result_text.setText(result_text)
if __name__ == '__main__':
app = QApplication(sys.argv)
window = DriverBehaviorDetection()
window.show()
sys.exit(app.exec_())
5. 测试与评估
5.1 测试图片和代码
你可以使用测试图片来验证系统的准确性。将测试图片放在指定路径,并调用 load_image 方法进行检测。
5.2 性能评估
使用验证集评估模型性能,计算精度、召回率、F1 分数等指标。
from sklearn.metrics import classification_report
# 获取预测结果和真实标签
y_true = []
y_pred = []
for img_path, label_path in zip(val_images, val_labels):
true_labels = read_labels(label_path)
results = model(img_path)
pred_labels = get_predictions(results)
y_true.extend(true_labels)
y_pred.extend(pred_labels)
print(classification_report(y_true, y_pred))
总结
从环境配置到模型训练、界面开发和测试评估的完整流程。你可以根据需求调整模型参数和界面设计你来优化系统性能和用户体验。学生可参考学习,



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









