






使用YOLOv8训练在SODA10M车辆行人数据集上进行车辆和行人检测 建立基于深度学习卷积神经网络的车辆行人检测识别
以下文字及代码仅供参考。
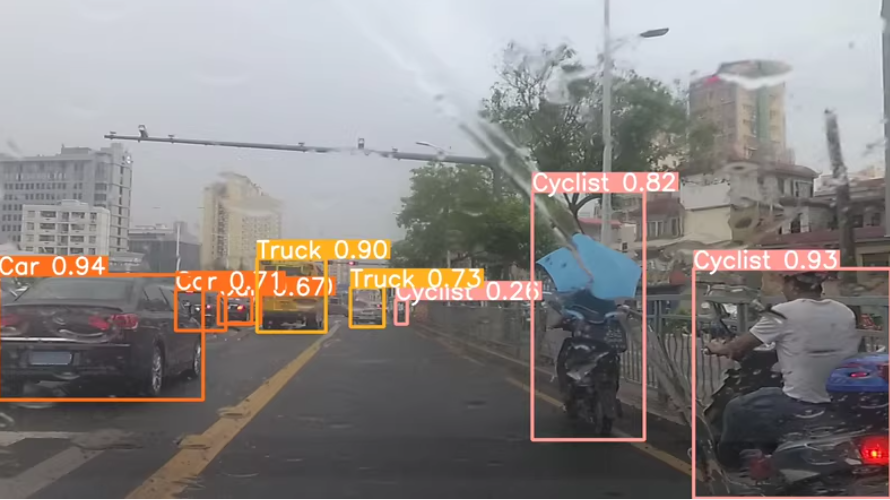
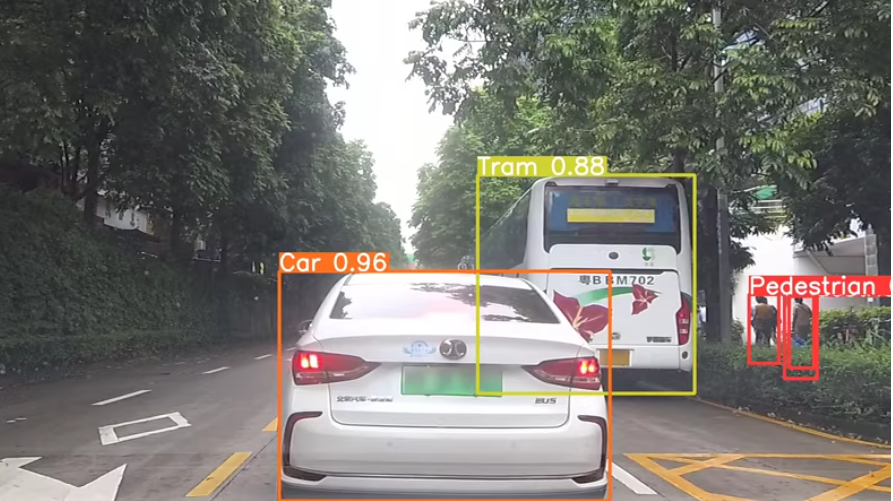
SODA101M车辆行人检测数据集
数据集概述:
-YOLO格式标注,直接适用于YOLO模型训练
-样本数量:训练集:5000,验证集:5000测试集 10000未标注
-目标类别:行人、骑自行车的人、汽车、卡车、有轨电车、三轮车
-‘Pedestrian’, ‘Cyclist’, ‘Car’, ‘Truck’, ‘Tram’, ‘Tricycle’

为了使用YOLOv8在SODA10M数据集上进行车辆和行人检测,我们将从安装依赖项开始,然后是环境配置、准备数据集、配置YOLOv8模型、训练和评估模型,。以下是详细的步骤和代码。
1. 安装依赖
首先,确保你的环境中安装了必要的库。这包括PyTorch、YOLOv8以及其他可能需要的库。
pip install torch torchvision torchaudio
pip install ultralytics
2. 环境配置
确保你已经正确配置了Python环境,并且能够顺利运行上述命令安装所需的包。如果遇到任何问题,请检查是否满足所有依赖项的要求。
3. 准备数据集
下载并解压SODA10M数据集到本地目录。根据YOLO格式要求组织数据集,通常包括images文件夹(存放图片)和labels文件夹(存放标注文件)。同时,创建一个.yaml文件来描述数据集的路径和类别信息。

假设数据集目录结构如下:
soda10m/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
创建soda10m.yaml文件:
train: ./soda10m/images/train/
val: ./soda10m/images/val/
test: ./soda10m/images/test/
nc: 6 # 类别数量
names: ['Pedestrian', 'Cyclist', 'Car', 'Truck', 'Tram', 'Tricycle'] # 类别名称
4. 配置YOLOv8
YOLOv8是一个非常灵活的框架,可以直接通过CLI或编程方式调用。这里我们以编程方式为例。
from ultralytics import YOLO
# 加载预训练的YOLOv8模型
model = YOLO('yolov8n.yaml') # 使用'n'代表nano规模,你可以选择更大的模型如's', 'm', 'l', 'x'
# 或者加载已有的权重
# model = YOLO('yolov8n.pt')
5. 训练模型
使用准备好的数据集和配置文件开始训练模型。
results = model.train(data='soda10m.yaml', epochs=100, imgsz=640) # 根据实际情况调整参数
6. 评估模型
训练完成后,可以对验证集进行评估,查看模型性能。
metrics = model.val() # 在验证集上评估模型
print(metrics.box.map) # 输出mAP值作为评估指标之一
7. 构建GUI应用程序
使用tkinter库快速构建一个简单的GUI应用来显示检测结果。
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
import cv2
import numpy as np
def detect_image():
path = filedialog.askopenfilename()
if not path:
return
# 执行检测
results = model.predict(source=path)
# 显示结果
for result in results:
image = result.orig_img
for box in result.boxes:
x1, y1, x2, y2 = map(int, box.xyxy)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
label = f"{result.names[int(box.cls)]} {box.conf:.2f}"
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
img = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
img = ImageTk.PhotoImage(img)
panel.configure(image=img)
panel.image = img
root = tk.Tk()
panel = tk.Label(root)
panel.pack(pady=10)
btn = tk.Button(root, text="选择图片", command=detect_image)
btn.pack(side="bottom", fill="both", expand="yes", padx="10", pady="10")
root.mainloop()
8. 运行
请注意同学们,,以上代码段旨在提供参考,实际操作时可能需要根据具体情况做出适当调整。例如,模型训练过程中可能需要更细致地调整超参数,或者在构建GUI时考虑更多用户交互细节等。
仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









