






基于深度学习的语音情绪识别基于深度学习的语音情绪识别
以下文字及代码仅供参考。
能识别出sad,happy,等7种情绪 neutral, calm, happy, sad, angry, fearful, disgusted, surprised
构建一个基于深度学习的语音情绪识别系统是一个涉及信号处理、特征提取、模型训练和评估的复杂过程
1. 环境配置
首先确保安装了必要的库:
pip install numpy pandas matplotlib seaborn librosa tensorflow keras
2. 数据集准备
我们使用RAVDESS(The Ryerson Audio-Visual Database of Emotional Speech and Song)数据集,它包含7种基本情绪:neutral, calm, happy, sad, angry, fearful, disgusted, surprised。
数据集目录结构
data/
actor_01/
03-01-01-01-01-01-01.wav
...
actor_02/
...
3. 特征提取
我们将使用MFCC(梅尔频率倒谱系数)作为音频特征。
import librosa
import numpy as np
def extract_features(file_path, mfcc=True, chroma=True, mel=True):
with open(file_path, 'rb') as f:
X, sample_rate = librosa.load(f, sr=None)
if chroma:
stft = np.abs(librosa.stft(X))
result = np.array([])
if mfcc:
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result = np.hstack((result, mfccs))
if chroma:
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
result = np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(y=X, sr=sample_rate).T, axis=0)
result = np.hstack((result, mel))
return result
4. 模型定义
我们使用Keras来定义一个简单的深度神经网络模型。
from keras.models import Sequential
from keras.layers import Dense, Dropout
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import os
import numpy as np
import pandas as pd
# 加载数据并提取特征
features = []
labels = []
for file in os.listdir('data'):
if file.endswith('.wav'):
emotion = file.split('-')[2] # 根据文件名提取情绪标签
data = extract_features(os.path.join('data', file))
features.append(data)
labels.append(emotion)
# 转换为numpy数组
X = np.array(features)
y = pd.DataFrame(labels, columns=['emotion'])
# 编码标签
le = LabelEncoder()
y = le.fit_transform(y['emotion'])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义模型
model = Sequential()
model.add(Dense(256, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(le.classes_), activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, batch_size=64)
# 评估模型
loss, acc = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {acc}')
5. 运行结果
运行上述代码后,你将得到模型在测试集上的准确率。此外,你可以绘制混淆矩阵以更直观地查看模型性能。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 预测
y_pred = model.predict_classes(X_test)
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=le.classes_, yticklabels=le.classes_)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
6. 推理代码
使用训练好的模型进行推理:
def predict_emotion(file_path):
feature = extract_features(file_path)
feature = feature.reshape(1, -1)
prediction = model.predict(feature)
predicted_label = le.inverse_transform([np.argmax(prediction)])
return predicted_label[0]
# 示例
file_path = 'path/to/audio/file.wav'
predicted_emotion = predict_emotion(file_path)
print(f'Predicted Emotion: {predicted_emotion}')
总结
以上代码提供了一个完整的基于深度学习的语音情绪识别系统的实现。从数据预处理到特征提取,再到模型训练和评估,最后是推理代码。你可以根据实际需求调整模型架构、特征提取方法等,以提高识别准确率。
根据你提供的目录,我将为你详细阐述基于深度学习的语音情绪识别系统的相关内容。以下是每个章节的详细说明:
一、绪论
1.1 研究背景
介绍语音情绪识别在日常生活和工业应用中的重要性,如客户服务、心理健康监测、智能助手等。强调随着人工智能技术的发展,尤其是深度学习的应用,语音情绪识别的准确性和实用性得到了显著提升。
1.2 研究现状
概述当前语音情绪识别领域的研究进展,包括常用的特征提取方法(如MFCC、LPCC)、模型架构(如CNN、RNN、LSTM)以及最新的研究成果和挑战。指出现有方法的局限性和改进空间。
1.3 研究内容和研究方案
1.3.1 研究内容
明确本研究的主要目标和任务,例如:
- 设计并实现一个基于深度学习的语音情绪识别系统。
- 比较不同特征提取方法和模型架构对识别性能的影响。
- 提出一种改进的神经网络结构以提高识别准确率。
1.3.2 研究方案
描述研究的具体步骤和技术路线,包括数据收集与预处理、特征提取、模型设计与训练、实验验证与结果分析等。
1.4 论文组织结构
简要介绍论文各章节的内容安排和逻辑关系,帮助读者快速了解全文框架。
二、自然语言处理理论基础
2.1 语音信号的理论基础
2.1.1 语音信号的数字化
介绍语音信号从模拟到数字的转换过程,包括采样、量化和编码等步骤。
2.1.2 时域表示
讲解语音信号在时域上的特性,如波形、振幅、频率等,并解释其在情绪识别中的作用。
2.1.3 频谱表示
探讨语音信号在频域上的特性,如傅里叶变换、短时傅里叶变换(STFT)等,以及频谱图在情绪识别中的应用。
2.1.4 语谱图
介绍语谱图的概念及其在语音信号分析中的重要性,展示如何通过语谱图观察语音信号的情绪特征。
2.2 语音信号预处理
2.2.1 分帧和加窗
解释分帧和加窗的目的和方法,以及它们对后续特征提取的影响。
2.2.2 预加重
介绍预加重技术的作用和原理,说明其如何改善高频成分的清晰度。
2.3 语音特征值提取
详细介绍常用的语音特征提取方法,如MFCC、LPCC、零交叉率、能量等,并比较它们的优缺点。
2.4 人工神经网络
2.4.1 卷积神经网络(CNN)
讲解CNN的基本结构和工作原理,包括卷积层、激活函数、池化层等,并说明其在语音情绪识别中的应用。
2.4.2 池化层
介绍池化层的作用和常见类型(如最大池化、平均池化),解释其如何减少特征维度并保留关键信息。
三、系统分析
3.1 需求概述
明确系统需要满足的功能需求和性能指标,如实时性、准确性、鲁棒性等。
3.2 系统概述
提供系统的整体架构和模块划分,包括数据输入、特征提取、模型推理、结果输出等部分。
3.3 功能实现
3.3.1 语音信号的遍历
描述如何读取和处理语音数据,包括文件格式支持、数据清洗等。
3.3.2 卷积神经网络设计
详细介绍CNN模型的设计思路和具体参数设置,如网络层数、卷积核大小、步长等。
3.3.3 神经网络的训练并保存网络模型
讲解模型训练的过程,包括损失函数选择、优化器配置、超参数调整等,并说明如何保存训练好的模型以便后续使用。
3.3.4 神经网络的预测
介绍如何利用训练好的模型进行情绪识别,包括输入预处理、模型加载、结果解析等步骤。
四、神经网络系统改进
4.1 改进神经网络
提出针对现有模型的改进方案,如引入注意力机制、增加残差连接、优化网络结构等,并解释其背后的理论依据和预期效果。
4.2 神经网络的比较分析
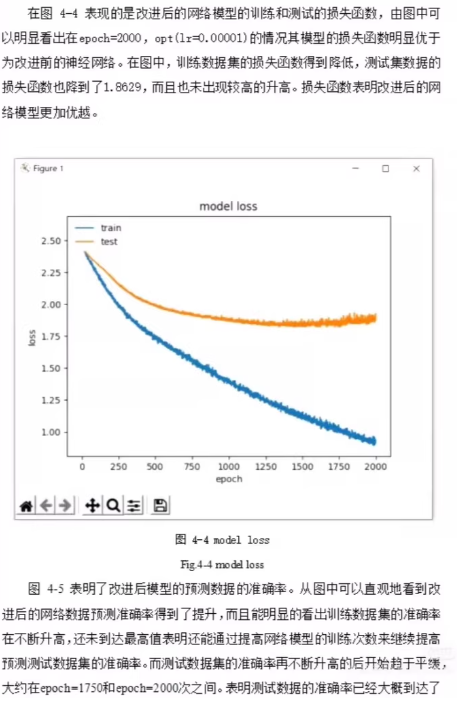
对比改进前后的模型性能,包括准确率、计算复杂度、收敛速度等方面的差异,并分析原因。
4.3 总结
总结改进工作的主要成果和贡献,指出存在的不足和未来的研究方向。
五、结果总结
总结整个研究的主要发现和结论,强调所提出的语音情绪识别系统的优点和潜在应用价值,并对未来的研究工作提出展望。
以上文字及代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









