






基于Python医疗数据分析可视化实时监控系统 采用随机森林算法进行分类预测,并使用前后端分离设计模式 构建基于Python医疗数据分析可视化实时监控系统
文章目录
采用随机森林算法进行分类预测
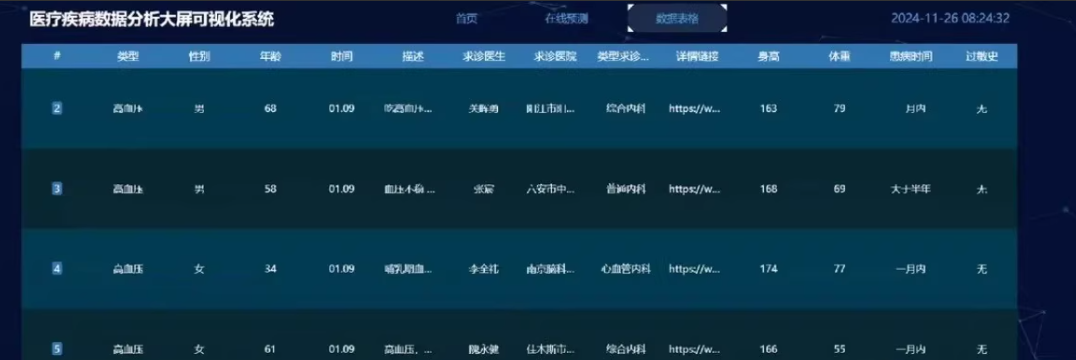
现成医疗数据,包含患者病历、诊断记录等
系统架构
本系统采用前后端分离设计模式,后端基于Python + Flask 框架,负责数据处理、机器学习训练、预测分析等核心功能;前端采用Vue 框架,提供用户交互界面及可视化展示。
后端:Flask 负责数据管理、模型训练及预测
前端:Vue + Echarts 实现数据可视化
数据库:MySQL 存储医疗文本数据,确保数据稳定
预实现功能:
数据处理与机器学习
系统从MySQL 数据库中获取医疗文本数据,包括病历记录、医生诊断报告、医学文献等,并进行以下数据处理:
文本预处理:清洗、分词、特征提取
特征工程:从文本中提取对疾病预测有用的信息
机器学习训练:基于随机森林分类算法训练预测模型
参数优化:调整模型参数,提高分类准确性
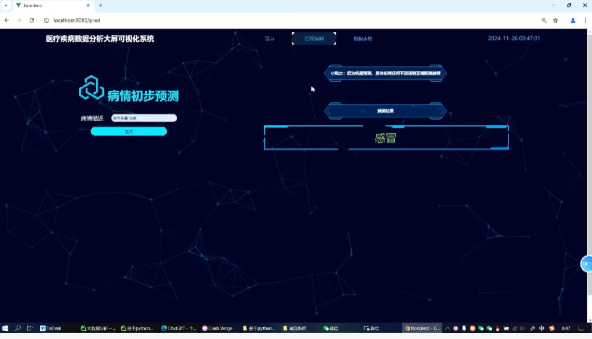
疾病预测与可视化
- 预测功能:
用户输入待分析的文本数据,系统调用训练好的随机森林模型进行疾病预测,并返回分类结果 - 数据可视化(Vue + Echarts):
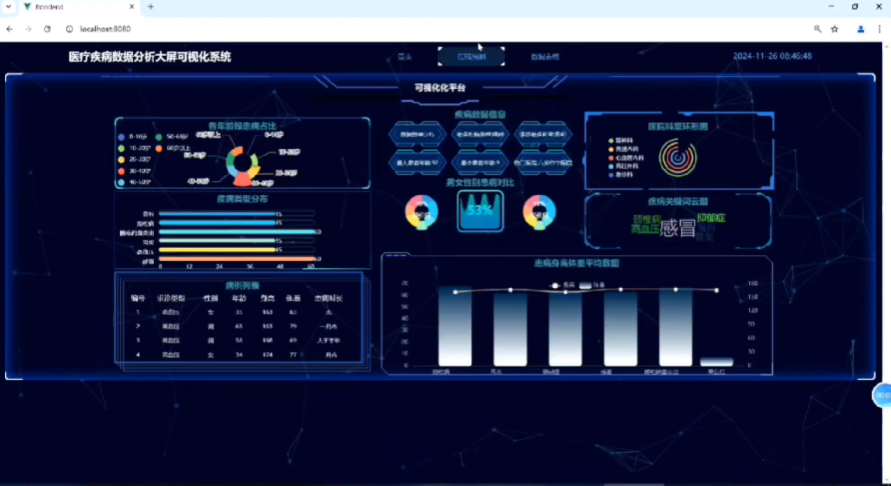
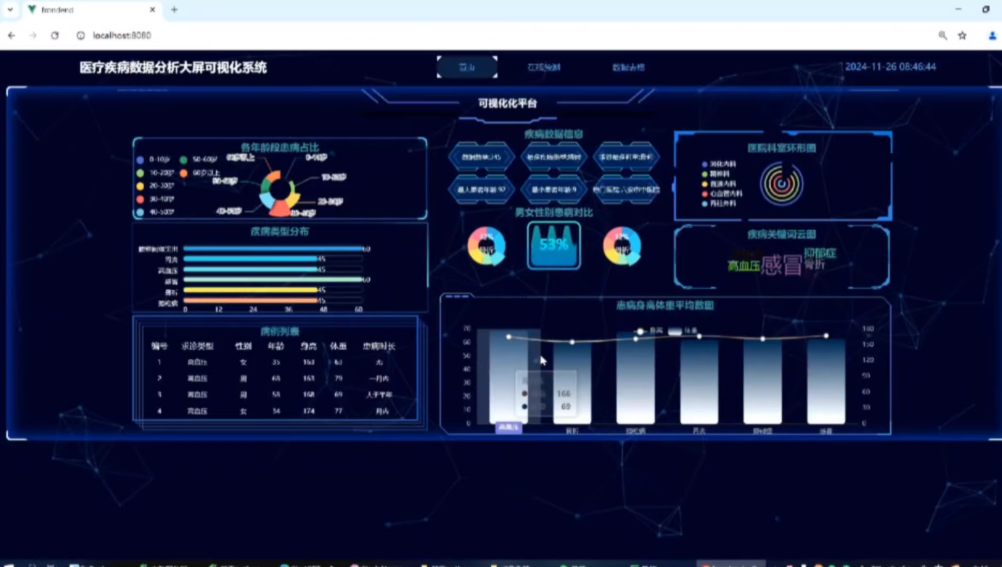
疾病趋势分析:展示不同疾病的发病率随时间变化的趋势
地域分布分析:分析不同地区的疾病分布情况
预测结果展示:可视化不同病例的预测类别及置信度
技术栈 及 方法技巧
编程语言:Python
后端框架:Flask
前端框架:Vue + Echarts
数据库:MySQL
机器学习算法:随机森林分类(Random Forest)
基于Python的医疗数据分析可视化实时监控系统,采用随机森林算法进行分类预测,并使用前后端分离设计模式,是一个复杂的项目。以下是详细的构建流程及系统代码示例。
仅供参考。
1. 系统架构与技术栈
1.1 技术栈
- 编程语言:Python
- 后端框架:Flask
- 前端框架:Vue + Echarts
- 数据库:MySQL
- 机器学习算法:随机森林分类(Random Forest)
1.2 系统架构
- 后端:负责数据管理、模型训练及预测。
- 前端:提供用户交互界面及可视化展示。
- 数据库:存储医疗文本数据,确保数据稳定。
2. 数据库设计
2.1 MySQL 数据库设计
创建一个名为 medical_data 的数据库,并包含以下表:
CREATE DATABASE medical_data;
USE medical_data;
CREATE TABLE patient_records (
id INT AUTO_INCREMENT PRIMARY KEY,
patient_id INT,
record_text TEXT,
diagnosis TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE disease_trends (
id INT AUTO_INCREMENT PRIMARY KEY,
disease_name VARCHAR(255),
incidence_rate FLOAT,
date DATE
);
CREATE TABLE geographic_distribution (
id INT AUTO_INCREMENT PRIMARY KEY,
region VARCHAR(255),
disease_name VARCHAR(255),
count INT
);
3. 后端开发 (Flask)
3.1 Flask 应用初始化
安装必要的库:
pip install flask flask_sqlalchemy pandas scikit-learn mysqlclient
创建 app.py 文件:
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://username:password@localhost/medical_data'
db = SQLAlchemy(app)
class PatientRecord(db.Model):
id = db.Column(db.Integer, primary_key=True)
patient_id = db.Column(db.Integer)
record_text = db.Column(db.Text)
diagnosis = db.Column(db.String(255))
created_at = db.Column(db.DateTime)
# 初始化TF-IDF向量化器和随机森林分类器
vectorizer = TfidfVectorizer()
clf = RandomForestClassifier()
@app.route('/train_model', methods=['POST'])
def train_model():
# 从数据库获取数据
records = PatientRecord.query.all()
data = [(r.record_text, r.diagnosis) for r in records]
df = pd.DataFrame(data, columns=['record_text', 'diagnosis'])
# 文本预处理和特征提取
X = vectorizer.fit_transform(df['record_text'])
y = df['diagnosis']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测和评估
y_pred = clf.predict(X_test)
report = classification_report(y_test, y_pred)
return jsonify({'report': report})
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
text = data['text']
X = vectorizer.transform([text])
prediction = clf.predict(X)[0]
return jsonify({'prediction': prediction})
if __name__ == '__main__':
app.run(debug=True)
4. 前端开发 (Vue + Echarts)
4.1 Vue 项目初始化
安装 Vue CLI 并创建项目:
npm install -g @vue/cli
vue create medical-dashboard
cd medical-dashboard
npm install axios echarts
4.2 Vue 组件开发
在 src/components 目录下创建 DiseaseTrend.vue 和 GeographicDistribution.vue 文件。
DiseaseTrend.vue:
<template>
<div>
<h2>疾病趋势分析</h2>
<div id="disease-trend-chart" style="width: 600px; height: 400px;"></div>
</div>
</template>
<script>
import * as echarts from 'echarts';
export default {
mounted() {
this.initChart();
},
methods: {
initChart() {
const chartDom = document.getElementById('disease-trend-chart');
const myChart = echarts.init(chartDom);
const option = {
title: {
text: '疾病发病率趋势'
},
tooltip: {
trigger: 'axis'
},
xAxis: {
type: 'category',
data: ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
},
yAxis: {
type: 'value'
},
series: [{
name: '发病率',
type: 'line',
data: [120, 132, 101, 134, 90, 230, 210, 180, 190, 200, 150, 160]
}]
};
myChart.setOption(option);
}
}
}
</script>
GeographicDistribution.vue:
<template>
<div>
<h2>地域分布分析</h2>
<div id="geographic-distribution-chart" style="width: 600px; height: 400px;"></div>
</div>
</template>
<script>
import * as echarts from 'echarts';
export default {
mounted() {
this.initChart();
},
methods: {
initChart() {
const chartDom = document.getElementById('geographic-distribution-chart');
const myChart = echarts.init(chartDom);
const option = {
title: {
text: '疾病地域分布'
},
tooltip: {},
legend: {
data: ['数量']
},
xAxis: {
data: ["Region A", "Region B", "Region C", "Region D", "Region E"]
},
yAxis: {},
series: [{
name: '数量',
type: 'bar',
data: [5, 20, 36, 10, 10]
}]
};
myChart.setOption(option);
}
}
}
</script>
4.3 主页面集成
在 src/App.vue 中集成上述组件:
<template>
<div id="app">
<h1>医疗疾病数据分析大屏可视化系统</h1>
<DiseaseTrend />
<GeographicDistribution />
</div>
</template>
<script>
import DiseaseTrend from './components/DiseaseTrend.vue';
import GeographicDistribution from './components/GeographicDistribution.vue';
export default {
components: {
DiseaseTrend,
GeographicDistribution
}
}
</script>
5. 运行与测试
5.1 启动后端服务
python app.py
5.2 启动前端服务
npm run serve
访问 http://localhost:8080 查看前端页面。
总结
以上代码涵盖了从数据库设计到后端模型训练、前端数据可视化的完整流程。你可以根据实际需求调整代码,例如修改数据处理逻辑或优化模型参数。
仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









