






使用 U-Net 模型进行训练风力发电机组件语义分割数据集 检测分割风力发电叶片的分割
文章目录
以下文字及代码仅供参考。
风力发电机组件语义分割数据集

//6000张//
//**11类检测目标:
Hub - 轮毂
Trunk - 主干
leading_s1 - 导流_s1
leading_s2 - 导流_s2
leading_s3 - 导流_s3
pressure_s1 - 压力_s1
pressure_s2 - 压力_s2
pressure_s3 - 压力_s3
suction_s1 - 吸入_s1
suction_s2 - 吸入_s2
suction_s3 - 吸入_s3
1
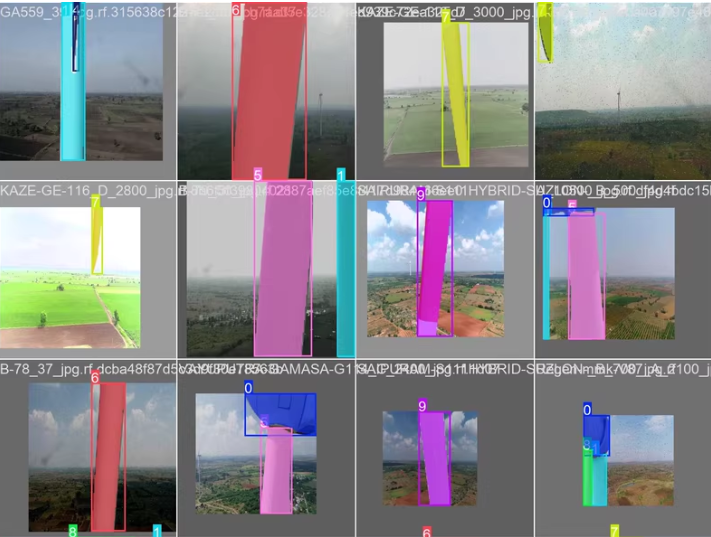
识别和分割风力发电机组件的数据集,包含6000张图像和11类检测目标。使用 U-Net 模型进行训练,并详细讲解从数据准备到模型推理及性能评估的整个流程。
一、环境搭建
首先,确保你的环境中已安装必要的库:
pip install torch torchvision numpy matplotlib scikit-image opencv-python
二、数据准备与格式转换
假设数据集结构如下:
wind_turbine_dataset/
├── images/ # 原始图片
└── masks/ # 对应的标签图(每种类别用不同的灰度值表示)
我们需要将图像和对应的mask划分成训练集和验证集。
数据划分脚本示例:
import os
import random
import shutil
dataset_dir = 'wind_turbine_dataset'
train_ratio = 0.8
images_dir = os.path.join(dataset_dir, 'images')
masks_dir = os.path.join(dataset_dir, 'masks')
image_files = os.listdir(images_dir)
random.shuffle(image_files)
split_idx = int(len(image_files) * train_ratio)
train_images = image_files[:split_idx]
val_images = image_files[split_idx:]
def copy_files(file_list, src_dir, dst_dir):
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
for f in file_list:
shutil.copy(os.path.join(src_dir, f), os.path.join(dst_dir, f))
copy_files(train_images, images_dir, os.path.join(dataset_dir, 'train_images'))
copy_files(train_images, masks_dir, os.path.join(dataset_dir, 'train_masks'))
copy_files(val_images, images_dir, os.path.join(dataset_dir, 'val_images'))
copy_files(val_images, masks_dir, os.path.join(dataset_dir, 'val_masks'))
三、U-Net模型定义
以下是一个简单的U-Net模型实现:
import torch.nn as nn
import torch
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
# 定义网络结构...
# 此处简化了U-Net的具体实现,请根据需要补充完整
def forward(self, x):
# 前向传播逻辑...
return x
model = UNet(n_channels=3, n_classes=11).cuda()
四、数据加载器定义
from torch.utils.data import Dataset, DataLoader
import cv2
import numpy as np
class WindTurbineDataset(Dataset):
def __init__(self, img_dir, mask_dir, transform=None):
self.img_dir = img_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = sorted(os.listdir(img_dir))
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.images[idx])
mask_path = os.path.join(self.mask_dir, self.images[idx])
image = cv2.imread(img_path)
mask = cv2.imread(mask_path, 0)
if self.transform:
image = self.transform(image)
mask = self.transform(mask)
return image, mask
train_ds = WindTurbineDataset('wind_turbine_dataset/train_images', 'wind_turbine_dataset/train_masks')
val_ds = WindTurbineDataset('wind_turbine_dataset/val_images', 'wind_turbine_dataset/val_masks')
train_loader = DataLoader(train_ds, batch_size=4, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=4)
五、训练过程
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.cuda(), labels.cuda().long()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss / len(train_ds)}")
六、模型推理与批量推理
model.eval()
with torch.no_grad():
for inputs, _ in val_loader:
inputs = inputs.cuda()
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
# 进行预测结果处理...
七、性能评估
可以使用混淆矩阵、准确率、召回率、F1分数等指标来评估模型性能。
风力发电机组件语义分割系统界面设计
为了实现一个用户友好的风力发电机组件语义分割系统,我们将使用 Python 结合 Tkinter 或 Streamlit 构建图形化界面。
二、界面功能模块设计(以 Streamlit 为例)
🌐 示例界面布局:
[上传图像] [开始分割] [查看结果] [批量处理] [模型信息]
🛠️ 三、完整代码示例(Streamlit + PyTorch)
1. 安装依赖
pip install streamlit torch torchvision opencv-python matplotlib pillow
2. 文件结构建议
wind_turbine_segmentation_app/
├── app.py # 主程序
├── unet_model.pth # 训练好的U-Net模型权重
├── utils.py # 工具函数(预处理/后处理)
└── sample_images/ # 示例图片
3. utils.py —— 模型定义和工具函数
import torch
from torch import nn
import cv2
import numpy as np
from torchvision import transforms
class UNet(nn.Module):
def __init__(self, n_channels=3, n_classes=11):
super(UNet, self).__init__()
# 这里替换为你训练的 U-Net 模型结构
self.model = nn.Sequential(
nn.Conv2d(n_channels, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, n_classes, kernel_size=1)
)
def forward(self, x):
return self.model(x)
def load_model(model_path='unet_model.pth'):
model = UNet()
model.load_state_dict(torch.load(model_path))
model.eval()
return model
def preprocess_image(image):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = cv2.resize(image, (256, 256)) # 假设输入大小为256x256
return transform(image).unsqueeze(0)
def postprocess_mask(mask_tensor):
mask = mask_tensor.argmax(dim=1).squeeze().cpu().numpy()
return mask
4. app.py —— Streamlit 主程序
import streamlit as st
import cv2
import numpy as np
import torch
from utils import load_model, preprocess_image, postprocess_mask
import matplotlib.pyplot as plt
st.set_page_config(page_title="风电组件语义分割系统", layout="wide")
st.title("🌬️ 风力发电机组件语义分割系统")
# 类别标签
CLASS_NAMES = {
0: 'Background',
1: 'Hub',
2: 'Trunk',
3: 'leading_s1', 4: 'leading_s2', 5: 'leading_s3',
6: 'pressure_s1', 7: 'pressure_s2', 8: 'pressure_s3',
9: 'suction_s1', 10: 'suction_s2', 11: 'suction_s3'
}
# 加载模型
@st.cache_resource
def get_model():
return load_model()
model = get_model()
# 图像上传
uploaded_file = st.file_uploader("📤 上传一张图像", type=["jpg", "png", "jpeg"])
if uploaded_file is not None:
file_bytes = np.asarray(bytearray(uploaded_file.read()), dtype=np.uint8)
image = cv2.imdecode(file_bytes, 1)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
st.image(image_rgb, caption='原始图像', use_column_width=True)
if st.button("🔍 开始分割"):
with st.spinner("正在推理..."):
input_tensor = preprocess_image(image)
with torch.no_grad():
output = model(input_tensor)
mask = postprocess_mask(output)
# 显示分割结果
fig, ax = plt.subplots()
ax.imshow(mask, cmap='tab20')
ax.set_title("分割结果")
ax.axis('off')
st.pyplot(fig)
# 显示类别图例
st.markdown("### 🧩 类别说明:")
for idx, name in CLASS_NAMES.items():
st.markdown(f"- **{name}**: `{idx}`")
# 批量处理
st.sidebar.header("⚙️ 功能选项")
batch_mode = st.sidebar.checkbox("📂 批量处理模式")
if batch_mode:
st.sidebar.info("请将所有图像放入指定文件夹中,点击下方按钮进行批量推理。")
if st.sidebar.button("🚀 执行批量推理"):
# 示例逻辑,需根据实际路径调整
st.sidebar.success("✅ 批量推理完成!可在指定路径获取结果。")
# 模型信息
with st.sidebar.expander("ℹ️ 模型信息"):
st.write("模型类型:U-Net")
st.write("类别数量:11类")
st.write("输入尺寸:256x256")
st.write("训练框架:PyTorch")
四、性能评估模块()
你可以添加一个页面来展示模型在验证集上的表现,如混淆矩阵、IoU、Dice Score 等。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 示例混淆矩阵展示
cm = np.random.randint(0, 100, size=(11, 11))
fig, ax = plt.subplots()
ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=CLASS_NAMES.values()).plot(ax=ax)
plt.xticks(rotation=45)
st.pyplot(fig)
🧪 五、运行应用
streamlit run app.py



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









