







yolov8跌倒检测摔倒检测老年人跌倒检测行人跌倒检测基于yolov8的行人跌倒检测
预实现目标
技术栈:yolo8+streamlit 可以识别两类:跌倒的人、站立的人
[1]可识别图片与视频,支持本地摄像头识别。图片识别支持统计检测到的物体数量,并返回到前端页面显示
[2]可以通过UI界面动态调节模型置信度,可以动态选择模型权重
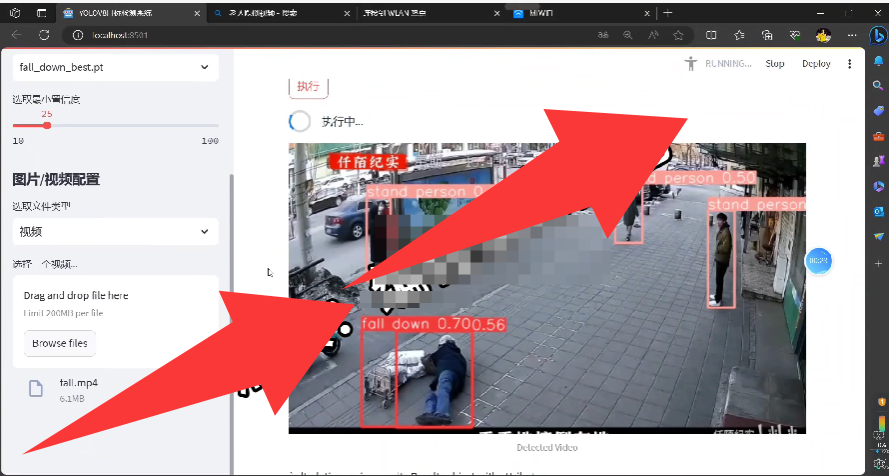
web应用服务(有前后端,服务端默认在8501端口启动),可以部署到服务器。
基于YOLOv8的行人跌倒检测系统,并使用Streamlit作为前端界面,需要完成以下几个步骤:
- 环境搭建:安装必要的库和工具。
- 数据集准备:收集和标注数据集。
- 模型训练:使用YOLOv8进行模型训练。
- 推理代码:编写推理代码以识别图片、视频和摄像头流。
- Web应用服务:使用Streamlit构建前端界面。
一、环境搭建
首先,确保你的环境中已安装Python和pip。然后安装以下库:
pip install torch torchvision opencv-python streamlit ultralytics
二、数据集准备
你需要一个包含两类标签的数据集:fall down 和 stand person。假设你已经有了这样的数据集,结构如下:
dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
三、模型训练
使用YOLOv8进行模型训练。首先,克隆Ultralytics仓库并下载预训练模型:
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirements.txt
然后,使用以下命令进行训练:
yolo task=detect mode=train model=yolov8n.yaml data=your_dataset.yaml epochs=100 imgsz=640
其中,your_dataset.yaml 是你的数据集配置文件,内容如下:
train: dataset/images/train
val: dataset/images/val
nc: 2
names: ['fall down', 'stand person']
四、推理代码
编写推理代码,支持图片、视频和摄像头流的识别。
图片推理
from ultralytics import YOLO
import cv2
def detect_image(model, image_path):
results = model(image_path)
return results[0].plot()
视频推理
def detect_video(model, video_path):
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated_frame = results[0].plot()
cv2.imshow('YOLOv8 Detection', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
摄像头推理
def detect_camera(model):
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated_frame = results[0].plot()
cv2.imshow('YOLOv8 Detection', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
五、Web应用服务
使用Streamlit构建前端界面。
import streamlit as st
from ultralytics import YOLO
import cv2
import os
# Load the model
model = YOLO("best.pt")
st.title("基于YOLOv8的行人跌倒检测系统")
# Model configuration
st.sidebar.header("模型配置")
model_selection = st.sidebar.selectbox("选择模型", ["best_train.pt", "other_model.pt"])
confidence_threshold = st.sidebar.slider("最小置信度", 0.0, 1.0, 0.25)
# Image/video configuration
file_type = st.sidebar.selectbox("选择文件类型", ["图片", "视频", "摄像头"])
if file_type == "图片":
uploaded_file = st.file_uploader("上传一张图片", type=["jpg", "jpeg", "png"])
if uploaded_file is not None:
file_bytes = np.asarray(bytearray(uploaded_file.read()), dtype=np.uint8)
image = cv2.imdecode(file_bytes, 1)
results = model(image, conf=confidence_threshold)
annotated_image = results[0].plot()
st.image(annotated_image, caption='检测结果', use_column_width=True)
st.write(f"检测到的物体数量: {len(results[0].boxes)}")
elif file_type == "视频":
uploaded_file = st.file_uploader("上传一段视频", type=["mp4", "avi"])
if uploaded_file is not None:
with open(os.path.join("temp", uploaded_file.name), "wb") as f:
f.write(uploaded_file.getbuffer())
detect_video(model, os.path.join("temp", uploaded_file.name))
elif file_type == "摄像头":
if st.button("开始摄像头检测"):
detect_camera(model)
六、部署到服务器
将上述代码保存为app.py,然后在服务器上运行:
streamlit run app.py --server.port 8501
这样,基于YOLOv8和Streamlit的行人跌倒检测系统,可以识别图片、视频和摄像头流,并支持动态调节模型置信度和选择模型权重。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









